 夜雨聆风
夜雨聆风





我熬夜3天剪的视频,AI用3分钟搞定了——这个开源神器让我怀疑人生
我熬夜3天剪的视频,AI用3分钟搞定了——这个开源神器让我怀疑人生
你有没有过这种感觉:明明脑子里有一万个视频创意,但一想到要写脚本、找素材、配音、剪辑……最后什么都没做。
我上个月差点放弃做短视频。
事情是这样的。老板在周会上拍桌子:”咱们产品账号每周至少更3条视频!”我当时心想,3条?我上个月花了整整一周才磨出来1条,还是那种配乐和画面各玩各的、旁白像在读课文的作品。
转折发生在某个凌晨2点。我在GitHub上漫无目的地刷,一个项目的slogan像一巴掌扇在我脸上——“零门槛,零剪辑经验,让视频创作成为一句话的事”。
一句话?我笑了。然后我试了一下,没笑出来。
30分钟后,一条完整的人文纪实短视频躺在我的output文件夹里:暖色调画面、节奏舒适的旁白、BGM卡点精准、分镜过渡丝滑。我盯着屏幕看了三遍,心里只剩一个念头——我之前那3天到底在干嘛?

从”一句话”到”一条片”:这个引擎到底做了什么?
这个项目叫Pixelle-Video,来自AIDC-AI团队,GitHub上已经1.5k星。它的核心逻辑极其暴力——你只管说人话,剩下的全交给AI。
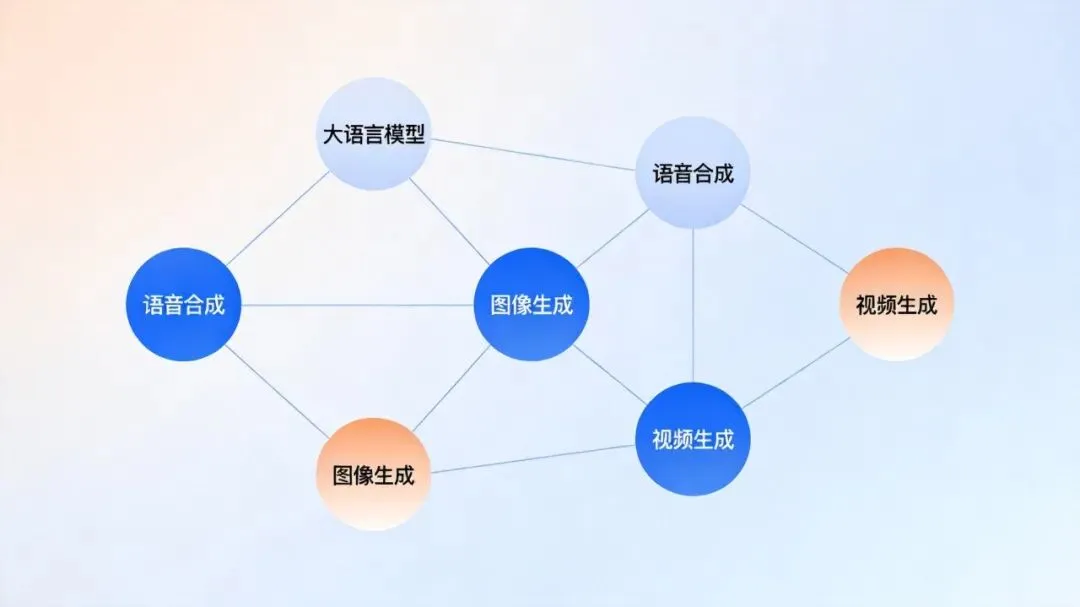
具体来说,你输入一个主题(比如”为什么我们还没找到外星文明”),Pixelle-Video会自动完成以下5件事:
-
写文案:调用大模型(GPT/通义千问/DeepSeek/Ollama),根据主题自动生成完整的视频解说词,分好段落和分镜 -
画配图:基于ComfyUI工作流,为每一段文案生成匹配的AI插图,风格你说了算 -
配声音:支持Edge-TTS、Index-TTS等多种语音引擎,甚至支持上传参考音频做声音克隆 -
加BGM:内置背景音乐,也可以自己扔MP3进去 -
合成视频:把文案、图片、语音、音乐按模板拼装,输出成片
整个过程,你只需要动一次手指,输入那句话。
我为什么被它打动了?因为”视频创作”这件事的痛点,它全踩中了
坦白讲,做短视频最折磨人的从来不是”没有创意”,而是创意和成品之间横亘的那座大山。
痛点一:写脚本是体力活
你要考虑开头钩子、信息密度、节奏感、每句话的时长控制……写完一篇3分钟的脚本,脑子已经空了,后面还有一堆活等着你。Pixelle-Video直接把这一步交给LLM,而且生成的文案结构化程度很高——不是那种AI味的口水话,而是自带分镜编号、场景描述、时长标注的”可直接使用”的脚本。
痛点二:找素材是噩梦
版权图库太贵,免费图库太丑,AI生图又不统一。Pixelle-Video的解法是每一帧都用AI画,而且所有图片共享同一个视觉风格——你可以在提示词前缀里定义风格,比如”极简黑白线条画”或”赛博朋克霓虹风”,所有分镜就会自动保持一致。
痛点三:配音不专业
自己录音?麦克风一开,声音就变了。请人配音?一条视频的配音费比视频本身还贵。Pixelle-Video内置了Edge-TTS,几十种音色随便选,还能上传自己的录音做声音克隆——对,就是那种”让AI用你的声音说话”的黑科技。
痛点四:剪辑太耗时
把素材往时间线上一条条拖,调整时长、对齐音频、加转场……一条3分钟的视频,剪辑环节至少占60%的时间。Pixelle-Video直接按模板合成,零手工操作。
拆解Pixelle-Video:它的设计哲学比功能更值得看
用了一周之后,我发现这个项目真正厉害的地方不是”功能多”,而是架构设计上的克制和灵活。
架构核心:原子能力 + 自由组合
Pixelle-Video没有把所有东西焊死成一个黑盒,而是基于ComfyUI架构做了一组原子能力:
| 原子能力 | 默认方案 | 可替换为 |
|---|---|---|
| 文案生成 | 通义千问/GPT | DeepSeek、Ollama(本地免费) |
| 图片生成 | FLUX模型 | 任意ComfyUI兼容模型 |
| 视频生成 | WAN 2.1 | 其他AI视频生成模型 |
| 语音合成 | Edge-TTS | Index-TTS、ChatTTS、声音克隆 |
| 视频模板 | 内置9套 | 自定义HTML模板 |
这意味着什么?每一个环节你都可以换成自己喜欢的东西。觉得FLUX出图太慢?换成SDXL。觉得Edge-TTS的声音太机械?换成Index-TTS做声音克隆。这个”乐高式”的设计让Pixelle-Video不是一个工具,而是一个视频创作的操作系统。
模板系统:三种形态覆盖所有场景
Pixelle-Video的模板命名非常有规律,一看就懂:
-
static_*.html:静态模板,纯文字+排版,不需要AI生成媒体,适合知识科普、金句类内容 -
image_*.html:图片模板,用AI生成的图片作为背景,适合人文纪实、知识讲解类 -
video_*.html:视频模板,用AI生成的动态视频作为背景,适合氛围感强、视觉冲击力要求高的内容
每种模板都支持竖屏(9:16)、横屏(16:9)、方形(1:1)三种比例。如果你懂HTML,还能自己写模板扔进templates/文件夹——这基本等于你在定义自己的视频风格语言。
脚本分割:让节奏可控
这个细节我很喜欢。Pixelle-Video支持三种脚本分割方式:
-
按段落:适合叙事感强的内容,每段一个完整画面 -
按句子:适合快节奏的科普类,一句话一个分镜 -
按行:适合诗歌、金句类,一行一帧,留白即力量
这个看似简单的功能,实际上解决了”AI生成的视频节奏全靠运气”的老大难问题。
实战体验:我用Pixelle-Video做了什么?
说再多不如看效果。过去两周我测试了几个不同主题,记录下真实的体验。
案例一:知识科普——”为什么我们还没找到外星文明”
-
配置:通义千问 + FLUX生图 + Edge-TTS + 默认图片模板(竖屏) -
耗时:约4分钟 -
分镜数:5段 -
感受:文案逻辑清晰,从费米悖论讲到德雷克方程再到大过滤器理论,比我自己写的还专业。配图是深空宇宙风,每帧都能当壁纸。唯一的问题是Edge-TTS的中文语调稍显平淡,换Index-TTS后会好很多。
案例二:个人成长——”如何提升自己”
-
配置:DeepSeek + FLUX + Index-TTS(上传了自己的一段录音做声音克隆)+ 默认模板 -
耗时:约6分钟(声音克隆需要额外处理时间) -
感受:克隆出来的声音相似度有80%,个别字咬字不太自然,但在短视频场景下完全够用。关键是——我用自己声音做了一期视频,而我全程没有开口说过一句话。这个体验非常赛博朋克。
案例三:历史解说——”资治通鉴启示录”
-
配置:GPT-4o + WAN 2.1视频生成 + 电影模板(横屏) -
耗时:约12分钟(AI视频生成比图片慢得多) -
感受:这个效果最惊艳。每一帧不是静态图片而是3-5秒的动态视频片段,配合电影模板的暗角和字幕,看起来像一部迷你纪录片。缺点是WAN 2.1生成速度慢,5个分镜等了快10分钟,但成片质量确实值这个等待。

上手指南:3种方式,从零到出片
讲真,Pixelle-Video的安装方式对新手很友好,尤其是Windows用户。
方式一:Windows一键整合包(推荐新手)
-
去Releases页面[1]下载整合包 -
解压,双击 start.bat -
浏览器自动打开 localhost:8501 -
在”系统配置”里填上LLM的API Key -
输入主题,点”生成视频”
**整个过程不需要安装Python、不需要装ffmpeg、不需要碰命令行。**这就是”零门槛”的真实含义。
方式二:源码安装(macOS/Linux用户)
# 克隆项目
git clone https://github.com/AIDC-AI/Pixelle-Video.git
cd Pixelle-Video
# 用uv一键启动(自动装依赖)
uv run streamlit run web/app.py
前提是你得先装好uv和ffmpeg,项目文档里有各系统的安装指引,照着做就行。
方式三:Docker部署(适合服务器/团队共享)
docker compose up -d
一条命令,容器里跑,适合团队内部共享或者长期挂着用。
费用问题:能不能白嫖?
**完全可以。**Pixelle-Video支持纯本地方案:
| 方案 | LLM | 图片生成 | 语音 | 总费用 |
|---|---|---|---|---|
| 全免费 | Ollama本地 | ComfyUI本地 | Edge-TTS | 0元 |
| 性价比 | 通义千问 | ComfyUI本地 | Edge-TTS | 约0.01元/次 |
| 省心版 | GPT-4o | RunningHub云端 | Index-TTS | 约0.5-2元/次 |
本地有显卡的,直接Ollama + ComfyUI,一分钱不花。没显卡的,通义千问的API调用成本极低,基本可以忽略。

进阶技巧:让Pixelle-Video从”能用”变成”好用”
基础玩法大家都会,但有几个细节,是我踩了一堆坑之后总结出来的。
1. 提示词前缀是风格控制器
很多人忽视了这个字段,但其实它是决定视频”长相”的关键。比如:
-
极简风: Minimalist black-and-white matchstick figure style illustration, clean lines -
国风: Chinese ink wash painting style, elegant brush strokes, traditional aesthetic -
科技感: Futuristic cyberpunk neon lights, dark background, glowing circuits
这个前缀会被加到每一帧的生图提示词前面,相当于给整条视频定了一个视觉基调。一定要填,而且一定要用英文。
2. 自定义素材:让AI”理解”你的照片
v0.1.8之后新增了”自定义素材”功能——你可以上传自己的照片和视频,AI会分析素材内容,然后围绕这些素材来写脚本和生成分镜。这意味着你可以做带自己照片的Vlog风格视频,而不只是纯AI生成的内容。
3. 声音克隆的正确姿势
上传参考音频时,选一段10-30秒的干净人声(无背景音乐、无环境噪音),效果最好。我自己试过用手机录的一段读书音频,克隆出来的声音相似度明显比用微信语音条录的高。
4. 模板预览功能
选模板之前,先点”预览模板”看看效果。不同模板的信息密度差异很大——有些一屏只放一句话(适合氛围感),有些一屏塞三段文字(适合知识密集型)。选对模板,比调其他任何参数都重要。
冷静分析:Pixelle-Video的局限在哪?
吹了这么多,必须公平地说说它目前的问题。
**第一,AI视频生成的速度是瓶颈。**如果选了视频模板(用WAN 2.1生成动态视频而非静态图片),5个分镜可能要等10-15分钟。图片模板就快得多,通常3-5分钟搞定。如果你的场景对时效性要求高,建议先用图片模板。
**第二,文案质量依赖LLM。**通义千问和GPT-4o生成的脚本明显比小模型好,结构更完整、节奏更自然。用Ollama跑本地7B模型的话,文案质量会打折扣,偶尔出现逻辑跳跃。建议至少用14B以上的模型。
**第三,声音克隆还不完美。**Index-TTS的克隆效果大约80%相似度,长句的语调偶尔不自然,而且对参考音频质量要求比较高。如果你追求播音级效果,还是得真人录音。
**第四,模板自定义需要前端能力。**虽然项目鼓励用户自己写HTML模板,但这对大多数内容创作者来说门槛不低。希望未来能出可视化的模板编辑器。
我的判断:这东西会改变什么?
说一个我自己的观察:短视频创作的核心成本不是拍摄,而是”从想法到成片”这条路径上的每一个手工环节。
Pixelle-Video做的事情,本质上是用AI把这条路径上的每一个手工环节都自动化了。你不再需要写脚本、找素材、配音、剪辑——你只需要一个想法。
这让我想起2015年前后,Markdown编辑器出现时,写博客的人不再需要折腾排版和样式,只管写内容就行。Pixelle-Video对视频创作做的,是同一件事——把创作者从”制作”中解放出来,让他们只做”创作”。
当然,目前的AI视频在精致度上还比不上专业团队手工打磨的作品。但对于绝大多数短视频场景——知识科普、个人IP、产品介绍、读书笔记——3分钟自动生成的80分视频,已经完胜3天手工磨出来的90分视频,因为前者你能一天出10条,后者一个月出3条都费劲。
内容赛道从来不是比谁单条视频最好,而是比谁持续输出的能力最强。Pixelle-Video解决的恰恰是这个问题。
最后
如果你是短视频创作者,或者一直想做视频但被制作门槛劝退的人,我建议你今晚就试一下Pixelle-Video。Windows用户下载整合包,5分钟就能跑起来。先别管效果好不好,就输入一个你最想做的主题,点一下”生成视频”,然后等3分钟。
那种看着AI一步步把你的想法变成一条完整视频的感觉——我第一次体验的时候,真的有点起鸡皮疙瘩。
项目地址:github.com/AIDC-AI/Pixelle-Video[2]
文档站点:aidc-ai.github.io/Pixelle-Video/zh[3]
记住,你离一条视频的距离,只差一句话。
本文基于 Pixelle-Video v0.1.11 版本体验撰写,项目持续更新中,以 GitHub 最新版本为准。
引用链接
[1]Releases页面: https://github.com/AIDC-AI/Pixelle-Video/releases/latest
[2]github.com/AIDC-AI/Pixelle-Video: https://github.com/AIDC-AI/Pixelle-Video
[3]aidc-ai.github.io/Pixelle-Video/zh: https://aidc-ai.github.io/Pixelle-Video/zh