 夜雨聆风
夜雨聆风





当AI开始“吃”自己产出的“粮食”,一场隐形危机正在逼近
一个真实的案例我用AI整理一幅古画的背景资料时,AI不仅给出了作者和年代,还讲了一个关于这幅画创作过程的完整故事。这个故事很生动,但它是虚构的——历史上并没有相关记载。幸好我之前对这位画家有一定了解,质疑了它的真实性并及时纠正了它的错误。但是,假如我对此没有了解,把这个故事发到网上,它就可能被其他AI当作真实信息学习。一个虚构的内容,就这样进入了数字世界的知识库。这不是AI偶尔出现的“幻觉”,而是一个正在系统性地发生的问题。《Nature》的发现:模型崩溃如开头的视频所引用的,2024年7月,顶级学术期刊《Nature》发表了一项研究,标题是《AI模型在递归生成的数据上训练时会崩溃》。研究人员发现了一个令人警惕的现象:当AI模型越来越多地使用自己或其他AI生成的数据进行训练时,模型会逐渐失去对真实世界的理解能力,最终变得不可用。他们将此称为“模型崩溃”。为了直观理解,研究者做了两组实验:第一组是手写数字生成。用真实的人类手写数据训练AI后,第一代模型能写出很像样的数字。但当研究者用AI自己生成的内容反复训练20代后,输出的数字开始变得模糊、细节丢失。到第30代时,所有数字都变成了同一个无法辨认的形状。第二组是生成狗脸图像。仅仅迭代了4代,原本清晰的狗脸就已经严重扭曲,无法辨认。
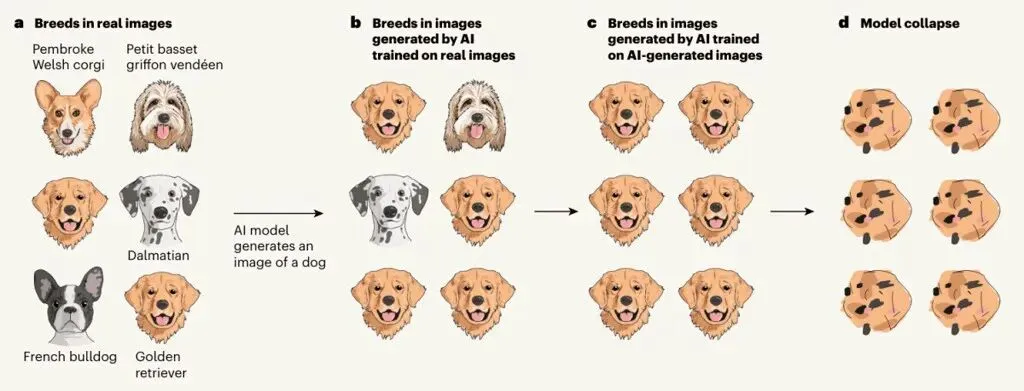
这个过程的本质并不复杂:AI需要新鲜、真实的数据来维持能力。当训练数据中掺入越来越多AI生成的内容,错误就会被逐步放大和固化。“哈布斯堡AI”的比喻研究者给这个现象起了一个名字,叫“哈布斯堡AI”。哈布斯堡王朝是中世纪欧洲最具影响力的王室之一,但由于长期近亲通婚,整个家族逐渐走向衰落。AI面临类似的问题。当它只能学习自己或同类产出的“二手知识”时,信息的多样性和准确性都会下降。这不是一夜之间发生的崩溃,而是一个缓慢、持续、难以察觉的退化过程。为什么这个问题值得关注目前,这个问题正通过以下三条路径逐步变成现实:第一,高质量的人类数据即将耗尽。 据研究机构Epoch AI的预测,互联网上高质量的人类写作内容,大约在2026年至2032年间就会被AI全部学完。第二,AI生成的内容正在迅速填满互联网。 每天有大量的AI生成文章、图片、评论被发布到网上。未来的AI在学习时,会不可避免地摄入大量“二手数据”。第三,人类的使用习惯正在发生变化。 当AI能快速给出答案时,人们提问的深度和独立思考的频率可能会下降。我们输出到网上的原创内容,也可能在减少。这三条路径相互叠加,形成一个反馈循环:AI生成的内容越来越多——新AI学习这些内容——质量下降——人类更依赖AI——更少的原创内容产出——AI更缺乏新鲜数据。普通人可以做四件事解决这个问题需要技术层面的努力,比如数据溯源、内容标注、算法优化等。但作为普通用户,也有一些具体的事情可以做。第一,对AI给出的信息进行基本核查。
保持对信息的敏感与质疑精神。尤其面对具体的人名、时间、数据等关键信息,用传统的搜索引擎快速核对一下。把AI的答案当作参考线索,而不是标准答案。第二,在提问时引导AI明确边界。
由于AI语言模型的本质不是“查找事实”,而是完成指令。所以当用户问“这幅画有什么具体故事?” 时,模型无法回答“没有”,只能根据画作的风格、作者生平、时代背景等信息,编织一个最符合语言概率和上下文逻辑的“故事”。
因此,可以在指令中加上“如果你不知道,请直接说不知道”这样的提示词。这能减少AI强行编造的情况。第三,保持自己的独立思考习惯。
在需要深度思考的任务上,先自己尝试整理思路、列出框架,再用AI辅助完善润色。比如这篇文章,就是这样生成的。
日常的阅读、写作和讨论,保留一部分完全不依赖AI的机会,体会虽然粗糙,但自己完成的快乐感。第四,在发布原创内容时适当标注。
如果你写的内容完全是自己的思考和表达,可以加上类似“人类原创”或“非AI生成”的标注。这有助于未来的数据筛选者识别内容来源。结语AI是一个强大的工具,但它需要高质量的人类数据作为基础。我们每一次不经核查的转发、每一次允许AI强行编造答案、每一次放弃独立思考而直接使用AI的现成回答,都在参与塑造未来AI的学习环境。保持清醒、保持核查、保持自己的思考和表达习惯。这不仅是为了让自己不被工具同化,也是在保护人类共同的知识基础。