 夜雨聆风
夜雨聆风





OpenClaw为什么能让AI“动手干活”?—核心原理深度拆解
当你对OpenClaw说“帮我整理桌面”时,它背后发生了什么?为什么它能打开浏览器、写入文件、运行代码,而ChatGPT只能给你一个文本建议?
这一期,我带你钻进OpenClaw的“身体”,用最直观的方式,拆解它的核心工作原理。
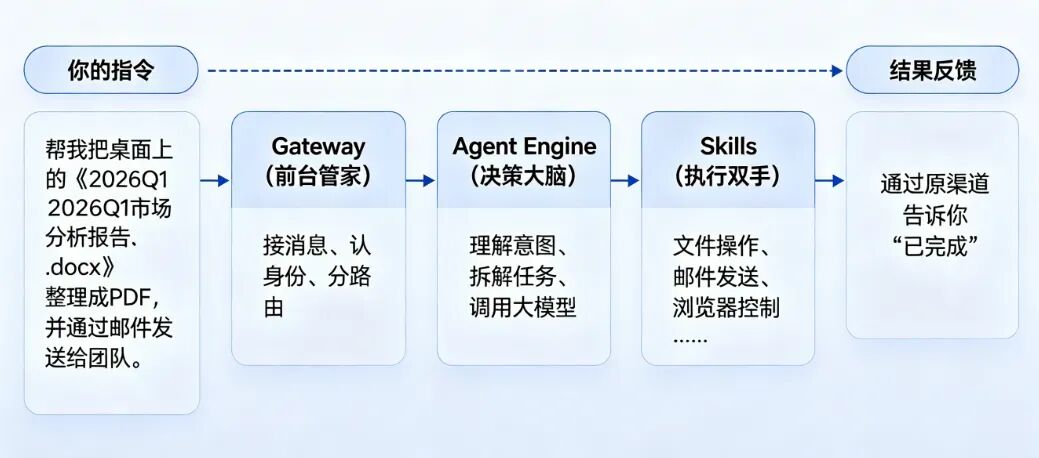
OpenClaw的工作流程可以用一句话概括:
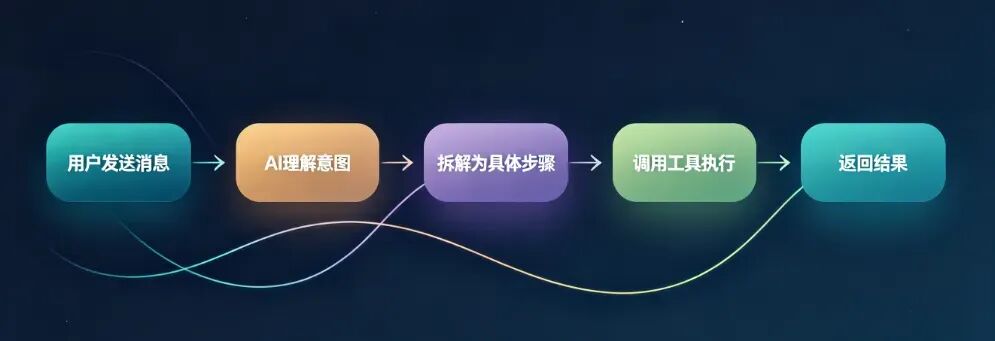
看起来很简单?但每一步背后,都有一套精密的工程架构在运行。
我们来走一遍完整流程——
假设你在飞书上给它发了一条消息:
接下来,OpenClaw是这样工作的👇
🛠️ 三层解耦架构:它是怎么“分工”的?
OpenClaw的架构可以用一个三层模型来理解:

Gateway是整个系统的神经中枢,你可以把它想象成一个超级高效的“前台管家”:
-
消息接收:它同时连接着微信、飞书、Telegram、钉钉等20多个消息渠道。不管你在哪个聊天软件上发消息,它都能收到。
-
身份认证:它先确认“你是谁”——是公司管理员还是普通员工?权限范围是啥?
-
消息路由:识别消息后,它把任务分给对应的Agent(智能体)。比如市场部的人发出的请求,路由给“市场分析Agent”。
-
会话管理:它确保每个对话上下文连续——你上一次说的“继续刚才的”,它知道“刚才”是什么。
Agent Engine是OpenClaw的思想中枢。它不直接操作电脑,而是——调用大语言模型(LLM)进行推理和任务规划。
当“帮我整理报告并发送邮件”这条消息到达Agent Engine时,它会:
-
调用大模型理解意图:把用户指令喂给GPT/Claude/DeepSeek等模型,模型解析出“需要完成两个子任务:转PDF和发邮件”。
-
生成执行计划:
任务:整理报告并发送邮件├── 步骤1:定位文档 → 调用文件系统Skill├── 步骤2:转换PDF → 调用Office转换Skill└── 步骤3:发送邮件 → 调用邮件Skill
决策与执行循环:Agent Engine采用ReAct(Reason + Act)模式——思考→行动→观察→再思考→再行动,直到任务完成。
核心要点:Agent Engine不绑定特定大模型。你可以用GPT-4o、Claude、DeepSeek、甚至本地模型(通过Ollama),它就是一个“模型适配器”,让你自由切换。 第3层:Skills(执行层)—真实世界的“双手和工具” Skills是OpenClaw真正干活的部分。每一个Skill都是一个“能力包”——告诉AI如何完成某一类具体操作。
比如,执行“转PDF”任务时,Agent Engine会调用文档处理Skill。这个Skill的文件里写着:
---name: document-convertdescription: 将文档转换为PDF格式---步骤:1. 使用libreoffice命令行工具转换文档2. 检查输出文件是否存在3. 返回转换后的文件路径目前ClawHub社区已有超过16,000个技能,覆盖文件操作、浏览器自动化、邮件处理、数据分析等30多个领域。
🛠️ 三大核心能力拆解 说完了宏观架构,我们来深入看看OpenClaw的“看家本领”。
能力一:消息驱动交互——为什么“发消息=下指令”? OpenClaw最聪明的设计之一是:把聊天软件变成AI的控制界面。
你不需要学任何新软件。打开飞书→找到一个叫“小龙虾”的机器人→发消息→它干活。就这么简单。
为什么这是革命性的?
传统AI产品需要你打开特定网站或App;传统自动化工具(如按键精灵、RPA)需要你配置复杂的触发器。而OpenClaw用你每天都在用的聊天软件作为入口——
零学习成本:谁不会发消息?
全平台覆盖:手机、电脑、平板都能用
异步交互:你发完指令可以关掉聊天窗口,它干完了会主动通知你
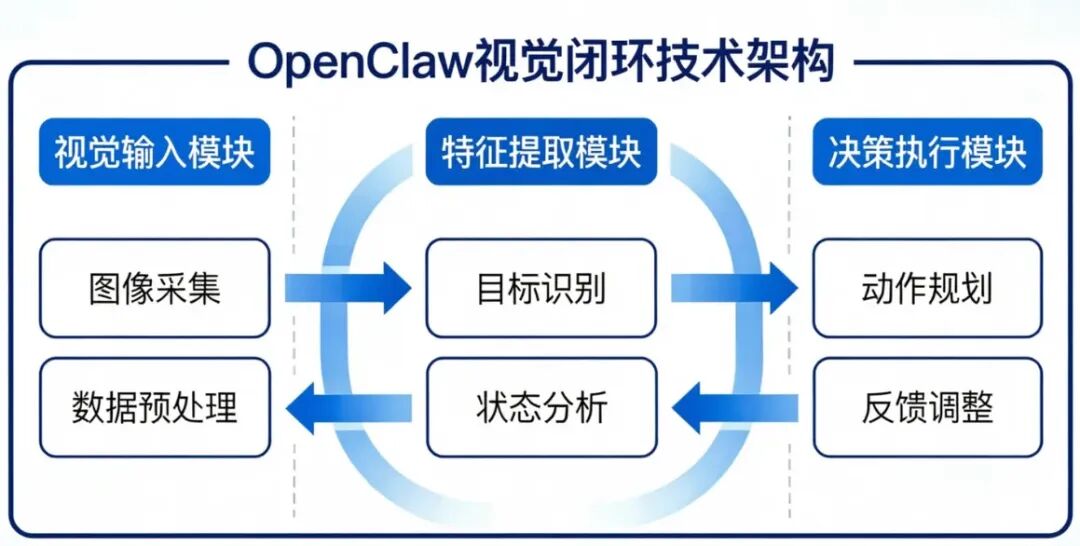
一句话总结:“消息即操作”(Message-as-Command),这是OpenClaw降低使用门槛的核心设计哲学。 能力二:视觉驱动+键鼠模拟—怎么“看”和“点”屏幕 这个功能堪称OpenClaw的“黑科技”——它能让AI“看见”你的电脑屏幕,并像人类一样操作。
视觉闭环的工作流程:
截取屏幕截图 → 多模态AI分析画面 → 识别按钮/文本框/图标 → 确定操作坐标 → 模拟鼠标点击或键盘输入 → 再次截图确认结果 举个具体例子: 你想让它填一个网页表单。
OpenClaw截取屏幕 → 当前看到的是Chrome浏览器中的一个登录页面
多模态LLM分析截图 → 识别出三样东西:输入框(用户名)、输入框(密码)、登录按钮
识别按钮/文本框/图标:文本输入框、按钮、图标
确定坐标:用户名输入框位于 (x₁, y₁),密码输入框在 (x₂, y₂),登陆按钮在 (x₃, y₃)
执行操作:依次模拟鼠标点击这些坐标,并输入文本
校验结果:再次截图,确认已经成功登陆
关键突破:它不依赖特定API或HTML结构,只要有屏幕,就能操作任何软件。老系统、没接口的软件、甚至虚拟机界面,全都能用。 能力三:持久化记忆系统—越用越懂你的“学习能力” AI最怕什么?– “记不住”。
以前你跟ChatGPT/Qwen/DeepSeek等大模型说“我喜欢简洁回复”,下一轮对话它就忘了。
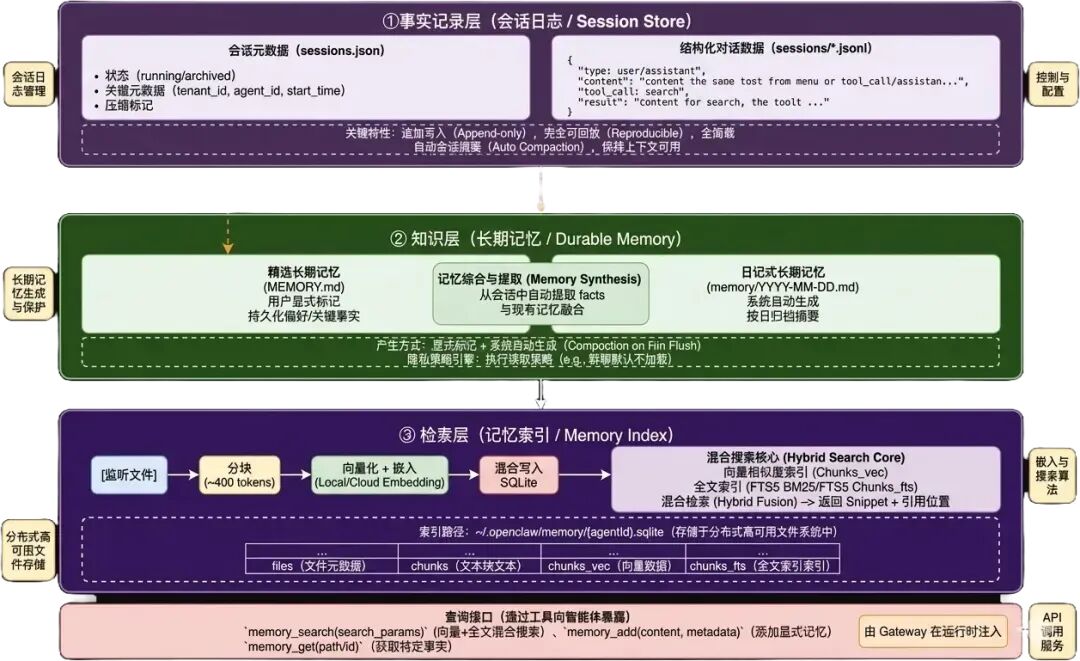
OpenClaw 所代表的应用,其对“记忆(Memory)”的定义是:持久存储在磁盘上的结构化信息。因此,只要有足够的存储空间,记忆就可以无限增长,能够跨会话保留,在使用时按需检索,且存储成本几乎为零。更为关键的是,这种记忆能够支持语音搜索,也就意味着不需要把所有历史信息都塞进上下文,只需要检索当前任务相关的片段。所以,可以将上下文理解成 AI 的“工作台”,决定当下能处理什么,而记忆则是 AI 的“知识库”,决定长期能积累什么。
OpenClaw的解决方案是双层记忆架构:
|
特性 |
MEMORY.md |
memory/*.md |
|
用途 |
核心长期记忆 |
按时间组织的会话记忆 |
|
定位 |
轻量索引 |
按需深度检索 |
|
内容类型 |
用户偏好、重要信息、工作流程等 |
具体会话的摘要和细节 |
|
更新方式 |
用户手动维护为主 |
系统自动生成为主 |
|
命名规则 |
固定为 MEMORY.md |
YYYY-MM-DD(-{slug}).md |
|
检索优先级 |
平等,由向量相似度决定 |
为什么这很重要?
因为有了持久记忆,你每和它多聊一次,它就更了解你一点。长期下来:
-
它知道你的沟通风格 —— 回复越来越精准
-
它记住你的偏好 —— 不用反复交代
-
它能跨会话延续 —— 今天说的,明天还记得
实测效果:使用记忆系统后,Token消耗降低了约88%——不需要每次都重读全部历史,只在需要时精准检索片段。
这是OpenClaw最“反直觉”的设计——它不是只能被动等待指令,而是设置了主动“心跳”。
(1)心跳(Heartbeat)机制
你可以想象成:OpenClaw每30分钟“醒”一次,检查有没有需要主动做的事。
比如:
-
每天早上8点:心跳触发 → 读取HEARTBEAT.md → 发现要生成晨间简报 → 自动整理今日待办、天气、股票行情 → 推送至你的微信
-
每4小时:心跳触发 → 检查服务器磁盘空间 → 如果超过80% → 发送告警并建议清理
工程实现:Gateway内部集成了Cron调度器,所有定时任务持久化到
~/.openclaw/cron/jobs.json,即使重启也不丢失。
(2)这个心跳机制所带来的质变
传统AI是“用户驱动”——你问,它答。
OpenClaw是“目标驱动”+“事件驱动”——你设定规则,它在后台自动检查、自动执行、自动汇报。
就像雇了一个24小时的“值班经理”:
-
你不需要操心它什么时间干活
-
你只需要告诉它“什么情况下要做什么事”
-
剩下的全部由它自主完成
让我们回到开头的例子——整理报告并发送邮件,走完OpenClaw的完整循环:
|
步骤 |
发生了什么 |
涉及模块 |
|---|---|---|
|
① 触发 |
你在飞书上发消息 |
消息渠道层 |
|
② 接收 |
Gateway收到消息,识别你的身份,路由到Agent |
Gateway网关 |
|
③ 计划 |
Agent调用大模型理解意图,拆解为“转PDF+发邮件”两个子任务 |
Agent Engine → LLM |
|
④ 执行转PDF |
调用文件操作Skill,找到文档 → 调用文档转换工具,生成PDF |
Skills层 |
|
⑤ 执行发邮件 |
调用邮件Skill,获取收件人列表 → 附上PDF → 通过SMTP发送 |
Skills层 |
|
⑥ 结果反馈 |
Agent确认两个子任务都完成 → 生成回复文本 |
Agent Engine |
|
⑦ 回复推送 |
Gateway把结果“已完成,已发送给团队”推送回到你的飞书 |
Gateway → 消息渠道 |
全程不需要你动手,你只需要发一条消息,然后等待结果就可以。
我们看上述示例在OpenClaw中的执行流程, 我们就可以看出OpenClaw的工作原理。
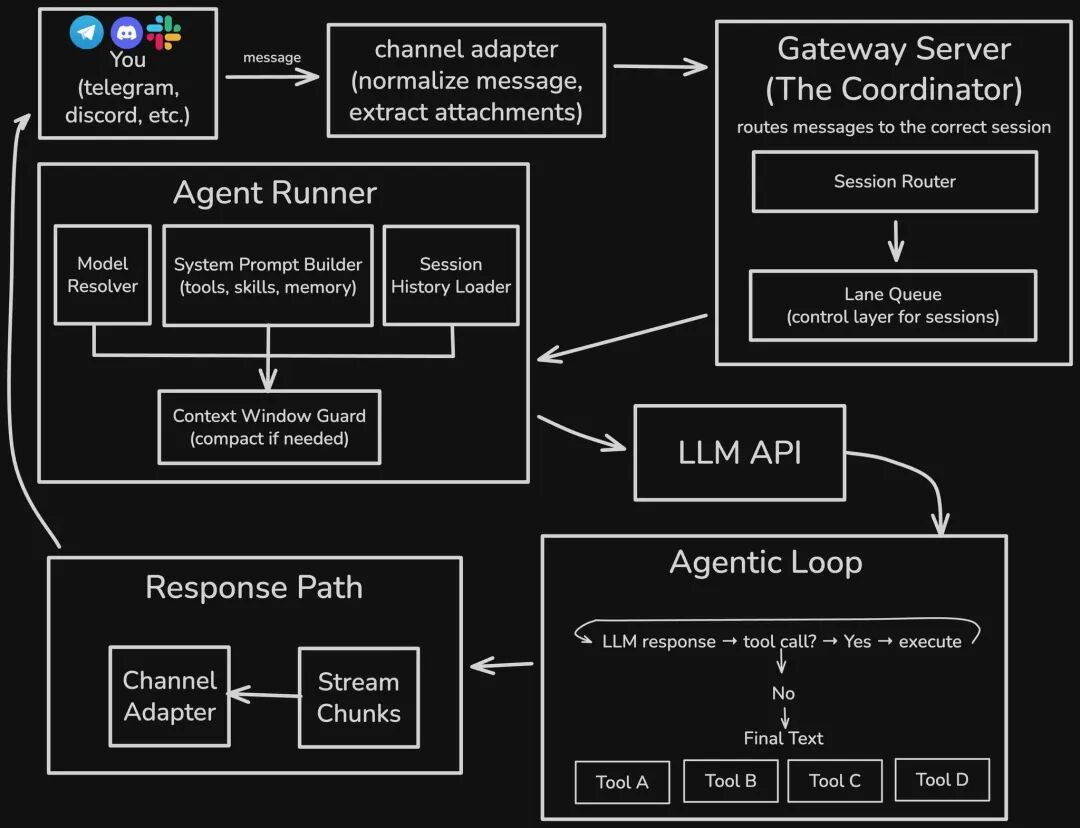
OpenClaw的每一层都可替换、可扩展:
|
层级 |
可替换性 |
示例 |
|---|---|---|
|
消息渠道 |
支持20+ |
微信、飞书、Telegram、Discord |
|
大模型 |
模型无关 |
GPT、Claude、DeepSeek、本地模型(ollama) |
|
技能 |
16,000+社区贡献 |
文件操作、邮件、浏览器、数据分析 |
|
记忆 |
纯文本可编辑 |
MEMORY.md可直接用记事本修改 |