 夜雨聆风
夜雨聆风





OpenAI GPT-5.5 Instant 上线:ChatGPT 默认模型换代,AI 助手终于开始少说废话
OpenAI GPT-5.5 Instant 上线:ChatGPT 默认模型换代,AI 助手终于开始少说废话
OpenAI 这次没有只把“更强”写在参数表上,而是直接动了 ChatGPT 的默认体验:GPT-5.5 Instant 开始面向所有 ChatGPT 用户推出,并在 API 中以 chat-latest 形态提供。对普通用户来说,这是一次每天都会感知到的模型换代;对开发者来说,它意味着默认轻量模型的事实性、图像理解、个性化和搜索决策能力都被重新抬高。

OpenAI 官方发布的 GPT-5.5 Instant 配图。
更新摘要
默认模型替换:GPT-5.5 Instant 正在替代 GPT-5.3 Instant,成为 ChatGPT 的默认日常模型。OpenAI 把这次更新描述为“更聪明、更准确、更清晰,也更贴近用户”。
事实性大幅改善:OpenAI 称,在医学、法律、金融等高风险提示词上,GPT-5.5 Instant 相比 GPT-5.3 Instant 的幻觉声明减少 52.5%;在用户曾标记为事实错误的困难对话中,不准确声明减少 37.3%。
多模态和搜索判断增强:新模型在照片和图片上传分析、STEM 问答,以及何时调用网页搜索方面都有提升。也就是说,它不是只会“答得更像”,而是更会判断什么时候需要补证据。
个性化更可控:GPT-5.5 Instant 会更好地利用过去聊天、文件和已连接 Gmail 中的上下文,同时推出 memory sources,让用户看到本次回答参考了哪些记忆或上下文来源,并可以删除或修正。
这次最值得关注的不是“又一个新模型”,而是 OpenAI 把改进压到了最常用的 Instant 层。过去模型发布往往聚焦旗舰推理模型,强是强,但很多人日常打开 ChatGPT 时接触到的还是默认模型。默认模型一旦提升,影响范围比少数高阶用户调用 Pro 模型更大。
OpenAI 给出的例子很直观:面对一道手写数学题,旧模型能发现候选答案不对,却容易停在“无解”;新模型会回头检查代数步骤,定位真正错误,再重新求解。这个变化听起来细,但它对应的是模型是否具备“发现自己刚才走偏了,并继续追因”的能力。
另一处变化是回答风格。OpenAI 明确提到,新模型会减少冗长、过度格式化、不必要追问和无意义装饰。对公众号读者来说,这句话可以翻译成更实际的判断:AI 助手的竞争不再只是能不能答,而是能不能用更少噪音交付可用结果。
OpenAI 用手写数学题展示新旧 Instant 模型在纠错链路上的差异。
个性化部分同样关键。GPT-5.5 Instant 不只是“更会记住你”,还开始把记忆来源展示出来。过去长期记忆的最大问题是黑箱:用户感觉模型记得一些东西,却不知道它从哪里拿来的。memory sources 的意义在于把个性化从神秘能力变成可审计的产品机制。
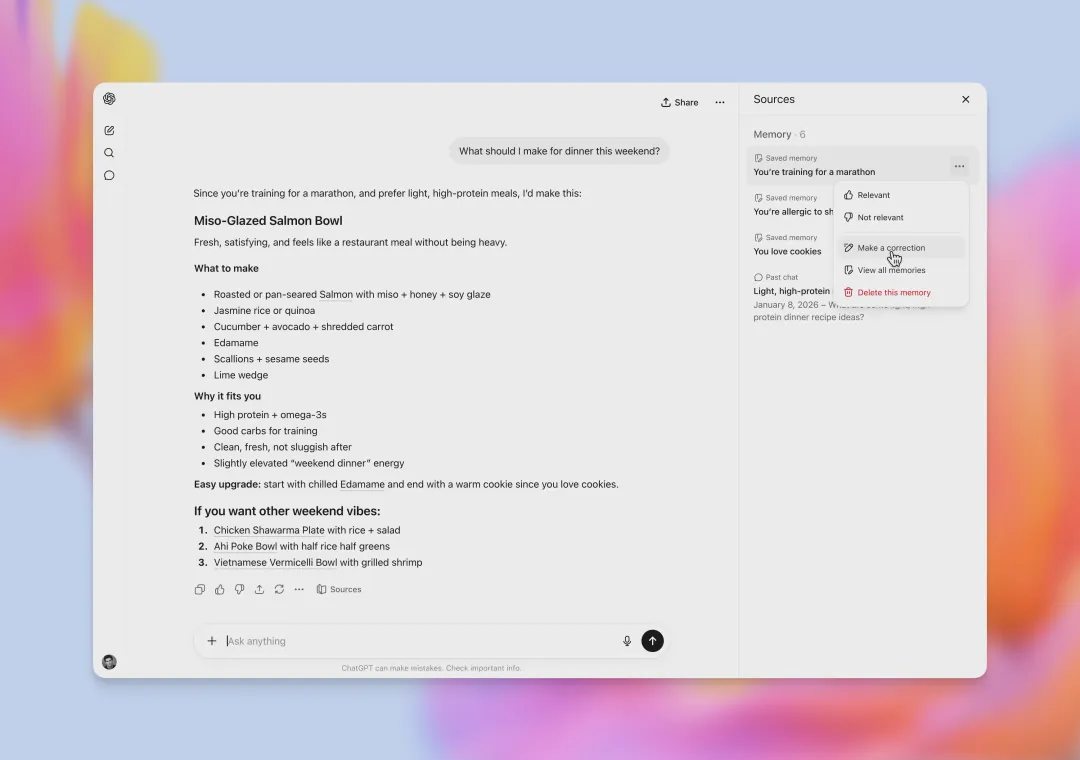
memory sources 让用户看到个性化回答引用了哪些记忆来源。
影响分析
第一,ChatGPT 的默认体验会更像一个成熟助手,而不是一个“能答很多但需要反复校对”的聊天模型。事实性下降的幅度如果能在真实使用中稳定体现,会直接改变用户对默认模型的信任阈值。
第二,开发者要重新理解 chat-latest 这个入口。它不只是便宜或通用的默认项,而是 OpenAI 希望持续滚动升级的体验层。对客服、教育、办公助手、轻量搜索增强应用来说,默认模型的稳定性提升,往往比旗舰模型的极限分数更有商业价值。
第三,个性化正在进入“可解释阶段”。未来 AI 产品要想长期使用用户上下文,不能只强调记忆强,还必须说明记忆从哪里来、是否可删、是否会被分享。OpenAI 这次把 memory sources 推出来,本质上是在为长期个性化建立信任界面。
这次更新最值得咂摸的一点是:AI 助手开始从“更会说”转向“更少打扰”。当默认模型能更准确、更简洁、更懂上下文时,用户真正感受到的不是技术参数,而是少一次追问、少一轮纠错、少一点信息噪音。模型竞争的终局,可能不是谁说得最多,而是谁最懂什么时候闭嘴。
参考来源
https://openai.com/index/gpt-5-5-instant/