 夜雨聆风
夜雨聆风





AI工程化演进:从指令优化到系统治理的三级范式
在人工智能技术快速落地的进程中,一个根本性的范式转变正在发生。2026年初,OpenAI发布的一份技术报告揭示了令人震撼的数字:三名工程师在五个月内通过约1500个拉取请求(Pull Request)完成了百万行生产级代码的产出——没有一行是手工编写的。这一成就并非源于某种未公开的“神秘模型”,而是基于一套系统化的工程方法论的胜利。
这标志着AI应用开发正从早期的“提示词技巧”阶段,演进为成熟的“系统工程”阶段。本文将深入解析Prompt Engineering、Context Engineering与Harness Engineering这三个递进的技术范式,揭示它们如何共同构建了现代AI应用的完整工程体系。
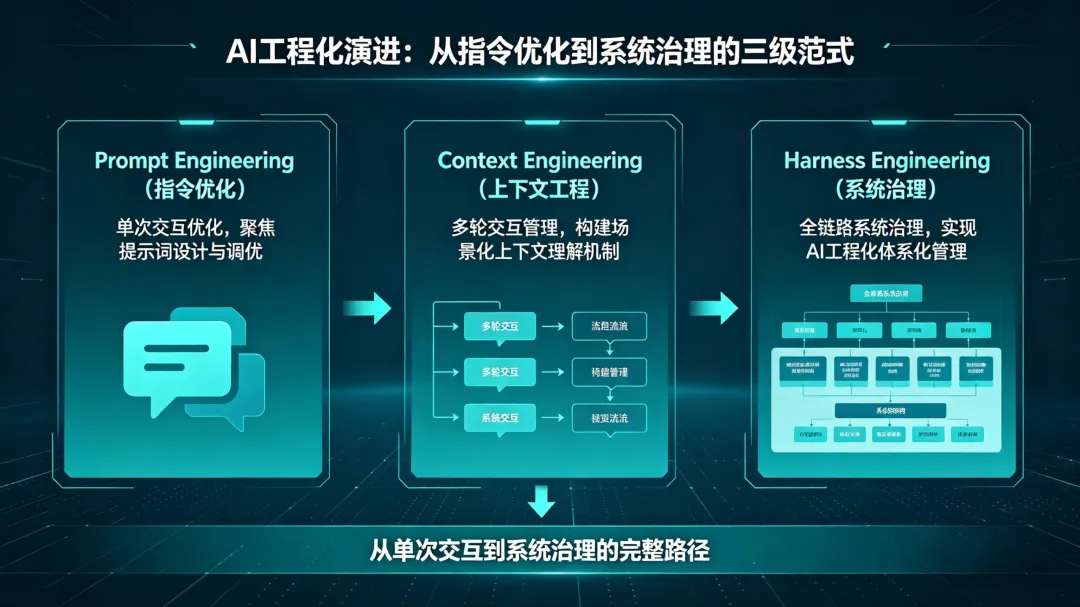
一、范式演进:从交互优化到系统设计的三级跃迁
1.1 Prompt Engineering:指令表达的精确性艺术(2024年主导范式)
Prompt Engineering解决的核心问题是如何与模型有效沟通。在这一阶段,从业者关注的是如何通过精确的措辞、结构化的指令和恰当的约束条件,从模型中“诱导”出理想的输出。
典型实践:
-
角色设定:“你是一位资深软件架构师…”
-
任务分解:“请按照以下三个步骤分析这个问题…”
-
格式约束:“以Markdown表格形式输出,包含以下列…”
-
风格指导:“使用专业但平实的语气,避免技术黑话…”
价值与局限:Prompt Engineering显著提升了单次交互的质量,但其本质仍是临时的、无状态的会话优化。当面对需要多步骤协作、长期记忆保持或复杂决策的复杂任务时,单纯的Prompt优化显得力不从心。
1.2 Context Engineering:上下文编排的系统科学(2025年成为焦点)
Context Engineering的关注点从“如何提问”转向“如何喂料”。2025年6月,前OpenAI联合创始人Andrej Karpathy在社交平台明确提出了这一概念,将其定义为“工业级LLM应用的核心——精心编排上下文窗口,确保模型在每一步都能获取恰到好处的信息”。
核心机制:
信息输入流水线:原始任务 → 检索相关文档 → 注入历史案例 → 提供参考模板 → 执行具体操作技术实现:
-
检索增强生成(RAG):从知识库中动态检索相关信息
-
思维链(Chain-of-Thought):引导模型展示推理过程
-
少样本学习:通过示例建立输出模式
-
动态上下文管理:根据任务阶段调整信息密度
关键突破:Context Engineering认识到,模型的表现不仅取决于提问方式,更取决于在正确时机提供的背景信息。这标志着从“对话技巧”向“信息系统设计”的转变。
1.3 Harness Engineering:系统可靠性的工程范式(2026年成为共识)
当复杂任务仍然难以可靠完成时,行业意识到需要更根本的解决方案。2026年2月,HashiCorp联合创始人Mitchell Hashimoto正式命名了“Harness Engineering”,其核心理念是:
“每当你发现智能体犯错,就工程化一个解决方案,确保这个错误永远不会再次发生。”
这不是优化提示词,而是通过代码、配置和自动化将约束永久固化到系统中。
范式对比:
|
维度 |
Prompt Engineering |
Context Engineering |
Harness Engineering |
|---|---|---|---|
|
核心目标 |
优化单次输出质量 |
优化信息输入策略 |
构建可靠执行系统 |
|
时间尺度 |
单次会话 |
任务周期 |
系统生命周期 |
|
技术手段 |
语言表达优化 |
信息检索与编排 |
工程约束与自动化 |
|
类比 |
学习提问技巧 |
学习资料整理方法 |
建立工厂生产流程 |
范式关系:三者是包含而非替代关系。Hugging Face工程师Philipp Schmid的精辟比喻是:AI模型是CPU,上下文窗口是RAM,Harness则是完整的操作系统。没有操作系统的CPU无法可靠运行复杂程序,同理,缺乏Harness的AI系统难以胜任生产级任务。
二、Harness Engineering的四维支柱体系
基于OpenAI、Anthropic及业界领先团队的实践,Harness Engineering可归纳为四个相互支撑的核心支柱。
2.1 支柱一:代码库即真相源——项目的“行军指南”
问题:智能体每次会话都“从零开始”,需要反复学习项目规范、技术栈和约束条件。
解决方案:在项目根目录创建标准化的配置文件(CLAUDE.md/AGENTS.md),作为智能体的“启动手册”。
最佳实践:
-
精炼而非全面:控制在100行左右,作为导航目录而非百科全书
-
增量式演进:每条规则对应一个真实发生的智能体错误
-
结构化引用:核心文件指向详细文档,按需检索而非全量加载
Hashimoto的维护哲学极具启发性:“配置文件中的每一行都对应一个过去的智能体错误行为,且几乎完全解决了所有这些问题。”这种“错误驱动”的演进方式,比事前设计的“完美规范”更贴合实际需求。
2.2 支柱二:机械化架构约束——编码的“物理定律”
核心洞见:配置文件是“建议”,而自动化钩子(Hooks)是“法律”。
钩子类型与应用:
hook_system:pre_execution_hooks: # 执行前钩子- 安全策略检查- 资源配额验证- 输入格式校验execution_hooks: # 执行中钩子- 危险操作拦截- 性能监控与限流- 合规性审计post_execution_hooks: # 执行后钩子- 结果验证- 状态清理- 通知触发
反直觉的洞见:更多约束常带来更高质量的输出。当解空间被合理收窄(“使用React组件,遵循命名规范,通过Service层调用”),智能体在受限但明确的空间中反而更容易找到正确解决方案。这与经验丰富的开发团队观察一致:明确的编码规范通常产生比“自由发挥”更高质量的代码。
2.3 支柱三:多层级反馈循环——持续的“质量飞轮”
智能体如同轮班工程师,若无交接记录,可能重复工作或延续错误。有效的反馈循环确保每个“班次”都清楚进度、质量和后续方向。
四层反馈体系:
-
即时反馈:工具调用前后的格式、安全、语法检查
-
构建反馈:提交时的CI/CD流水线验证
-
运行时反馈:部署后的监控与日志分析
-
评审反馈:功能完成后的独立评估
GAN式三智能体架构:受生成对抗网络启发,Anthropic提出的架构包含:
-
规划者:将模糊需求扩展为可执行规格
-
生成者:实现具体功能
-
评估者:独立评估产出质量
关键发现:当AI评估自身工作时,会表现出不合理的“自信宽容”。独立评估角色解决了这一根本问题。更有趣的是,在持续评估压力下,生成者在第10轮迭代时主动放弃了前9轮的设计,提出了全新的创意方案——良好的约束反而激发了创造力。
2.4 支柱四:熵管理——对抗渐进式系统衰变
核心问题:AI生成的代码引入了一种新型质量问题——渐进式系统衰变,而非传统意义上的bug。
衰变模式:
-
文档漂移:代码变更但注释未更新,形成“知识债务”
-
架构侵蚀:约束被逐步绕过,架构一致性被破坏
-
风格不一致:不同会话产生不同编码风格,增加认知负荷
OpenAI的解决方案:将“品味”编码为可执行的规则。团队对代码质量的判断标准被转化为linter规则,自动扫描并指导修复。正如他们总结的:“品味捕获一次,强制执行无限次。”人类的审美判断是稀缺资源,通过工程化可无限复用。
重要原则:Harness必须设计为“可删除的”。今天需要复杂流水线完成的任务,明天可能只需简单提示。Vercel移除80%工具后效果更好,LangChain一年内重构三次,Manus团队六个月内重构五次——这些经验都指向同一原则:从简单开始,为删除而设计。
三、数据验证:Harness优化的显著收益
2026年3月,LangChain进行的控制变量实验提供了关键数据支持:
实验设计:在Terminal Bench 2.0基准测试中,保持模型不变,仅调整:
-
系统提示词优化
-
工具配置精细化
-
中间件钩子增强
实验结果:排名从30名外跃升至前5,性能提升13.7个百分点。
对比基准:同期仅通过更换更强模型通常可获得约6.8个百分点的提升。
核心结论:优化Harness的效果是单纯升级模型的两倍。这彻底颠覆了“性能不足就换更大模型”的直觉,明确了对于大多数团队:
产出质量 = 模型能力 × Harness设计水平
模型能力常受限于预算和可用性,而Harness设计水平完全在团队控制范围内,且投资回报率显著更高。
四、行业实践:五种典型实施模式
4.1 OpenAI Codex团队:工程化极致
-
团队规模:3人
-
核心原则:五大核心原则 + 六层分级约束
-
关键机制:自动“垃圾回收”维护代码库健康
-
核心启示:Harness是Agent-First开发的基石,而非附加项
4.2 Stripe Minions:企业级集成典范
-
工作流程:Slack中表情触发 → 自动生成代码/测试/文档 → CI/CD验证 → 提交PR → 人工审查
-
规模:近500个MCP工具,每周1300+ PR
-
创新:Blueprint机制——AI先提供实现计划,人工批准后执行
-
价值:证明了大范围AI集成与严格人工审查的可并存性
4.3 LangChain:开源社区的最佳实践
-
核心贡献:Doom Loop检测中间件
-
工作机制:当AI反复修改同一文件却无法通过测试时,自动介入并提示重新评估
-
方法论:数据驱动优化,公开基准测试结果
4.4 GStack by Garry Tan:极简流程设计
-
创建者:Y Combinator总裁
-
核心理念:“流程优先于工具集”
-
实现:28个角色按Sprint顺序运行,全Markdown实现
-
成果:60天60万行代码,创作者同时全职管理YC
-
适合场景:个人开发者与小型团队
4.5 Peter Steinberger:高信任度模式
-
工作方式:最小约束,深度理解项目
-
产出:月均6600次代码提交
-
前提条件:对项目有极深理解,能快速判断AI产出质量
-
警告:高门槛,不适用于多数团队
选型建议:
-
个人/小团队:GStack(低门槛,纯Markdown)
-
企业协作:Stripe Minions(CI/CD集成,严格审查)
-
方法论研究:LangChain(数据驱动,透明优化)
-
理解上限:OpenAI Codex(Agent-First的天花板)
五、工程师角色的范式转移
Mitchell Hashimoto描述了自己的角色演变:“我是软件项目的架构师,仍负责代码结构、数据流和状态管理,但具体编码越来越多地委托给AI。”
类比转变:
-
过去:厨师亲自烹饪每道菜
-
现在:主厨设计菜单、培训团队、制定标准、检查出品
能力要求转变:
-
从编码到系统设计:重点从“如何实现”转向“如何设计可实现的环境”
-
从调试到约束定义:从修复具体bug到定义防止bug的规则
-
从执行到治理:从亲自编写到确保系统可靠产出
复杂度并未消失,而是从“编写代码的复杂度”转移至“设计环境的复杂度”。这个新领域更契合人类在抽象思维、系统设计和质量判断方面的优势。
六、当前局限与未来挑战
在兴奋于潜能的同时,必须清醒认识当前局限:
6.1 验证缺口
Harness擅长确保代码“合规”(风格、结构、类型安全),但对“正确性”(业务逻辑是否符合预期)的验证仍不足。静态检查可捕获格式问题,但难以验证业务逻辑正确性。
6.2 存量系统挑战
当前成功案例多始于新项目。对于已有大量遗产代码的系统,如何设计安全有效的Harness仍缺乏验证方法。这对大多数拥有存量系统的企业是关键障碍。
6.3 领域适用性差异
-
软件开发:已大规模验证,最为成熟
-
内容创作:前景明确,但仍在探索最佳实践
-
高风险领域(医疗、法律):验证缺口被放大,当前适用性有限
6.4 概念成熟度
Harness Engineering正式命名仅数月,框架和工具仍在快速演进。宣称其“解决所有问题”为时过早,但它提供了目前最系统的解决路径。
七、实施路径:从最小可行开始
启动Harness Engineering无需复杂系统。最小可行起点:
# AGENTS.md - 项目启动指南## 技术栈- 语言:Python 3.9+- Web框架:FastAPI- 数据库:PostgreSQL- 测试:pytest## 常用命令- 启动开发服务器:uvicorn app.main:app --reload- 运行测试:pytest tests/ -v- 代码检查:black . && isort .## 绝对禁区- 不要直接修改 database/migrations/ 下的迁移文件- 不要将密钥硬编码在源码中- 不要绕过repository层直接查询数据库
演进策略:从这不足100行的文件开始,每次智能体犯错,就将相应规则补充进去。这种“错误驱动”的增量演进,比试图预先设计完美规范更有效、更贴近实际需求。真正的障碍从来不是技术复杂性,而是思维范式的转变——从“如何提出好问题”转向“如何设计好的工作环境”。在模型能力快速民主化的当下,这种思维转变的能力,正成为区分卓越与平庸团队的关键分水岭。