 夜雨聆风
夜雨聆风





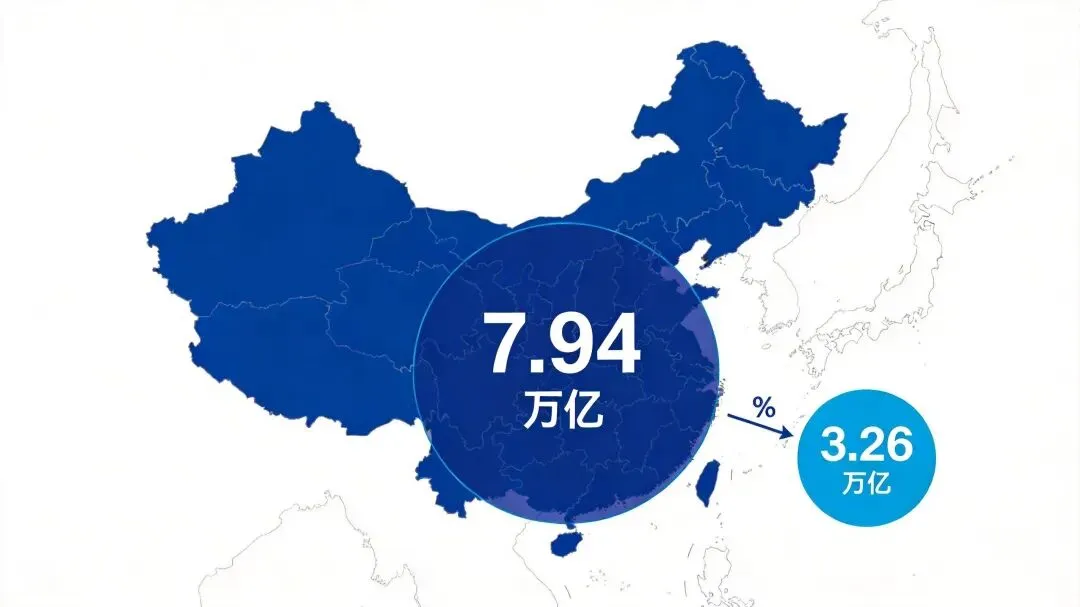
7.94万亿!中国AI调用量首超美国,差距还在继续拉大
【导语】 这不是一个普通的数字。7.94万亿Token——这是中国AI大模型一周的调用量,比美国多了整整2.4倍。当我们还在讨论”中国AI能不能追上美国”的时候,答案已经悄然改写。

上周,一组数据刷屏了整个科技圈。
根据最新统计,中国AI大模型的 周调用量达到7.94万亿Token ,环比暴涨81.7%。而在大洋彼岸的美国,同期仅有3.26万亿,还同比下滑了34.6%。
这意味着什么?
意味着中国第一次在AI大模型的核心指标上,实现了真正意义上的”碾压式”超越。而且这个差距,还在以肉眼可见的速度继续拉大。
一、7.94万亿,到底是个什么概念?
先给大家做个科普。Token,你可以简单理解为AI处理文字时的”基本单位”——大约相当于4个英文字符或1个中文汉字。
7.94万亿Token,如果换算成书籍,大约相当于:
-
2000万本《三国演义》 -
或者把整个中国国家图书馆的藏书来回调用8遍
这还只是一周的量。
有人可能会问:为什么突然涨这么多?
答案很简单: 用得起,用得值。
过去一年,国产大模型的能力快速提升,价格却持续腰斩。DeepSeek V4的API定价只有OpenAI的十分之一,而混元、Kimi等国产模型的能力,已经可以和GPT-4o掰掰手腕。企业发现,用国产模型,成本降了三分之二,效果却差不多——换你是老板,你选谁?
二、国产模型集体爆发:混元、Kimi杀到全球前二
如果说数据只是结果,那背后的驱动力更值得关注。
在最新的全球大模型评测榜单上, 腾讯混元Hy3 Preview和月之暗面Kimi K2.6双双登顶,分列全球前二 。这是国产模型从未达到过的高度。
这两者的崛起路径很有意思:
混元 背靠腾讯生态,把AI能力无缝接入了微信、QQ、腾讯文档等十几亿用户的产品里。你可能已经在不知不觉中用过它——比如微信读书的AI问答,或者腾讯会议的智能助手。
Kimi 则走的是”长文本”路线,200万字的上下文窗口,让它可以一口气读完一整部《三体》然后跟你讨论细节。这种能力,在处理长篇小说、法律合同、医学报告等专业场景时,简直是降维打击。
更重要的是,这两款模型都跑在国产算力上。
三、芯片破局:国产份额首破41%,英伟达神话不再

说到算力,就不得不提一个被很多人忽视的转折点: 国产AI芯片的市占率,第一次突破了41%。
要知道,就在两年前,这个数字还不到10%。那时候,说到AI训练,大家第一反应就是英伟达的GPU。一块H100显卡被炒到几十万还一卡难求,国内厂商只能”等米下锅”。
现在呢?
英伟达在中国市场的份额,从巅峰期的95%,一路跌到了55%。 寒武纪、华为昇腾、燧原等国产玩家,正在快速填补这个空白。
资本市场的反应最诚实:
- 寒武纪
一季度营收暴涨159.56%,股价单日涨幅高达25.69% - 科创人工智能ETF
单日涨近8% -
整个AI算力板块,成为今年A股最靓的仔
有人开玩笑说:”以前买英伟达是’确定性’,现在买寒武纪才是’政治正确’。”
当然,国产芯片和英伟达的差距还在,生态建设、工具链成熟度、软件适配都还需要时间追赶。但方向已经明确: 用市场换时间,用应用促迭代。
四、DeepSeek V4:华为昇腾原生适配,定价只有OpenAI的1/10
如果说芯片是”硬实力”,那模型就是”软实力”。这两个领域同时突破,才是这一波爆发的核心逻辑。
DeepSeek V4 是其中一个标志性事件。
这款模型完成了对 华为昇腾950PR 的原生适配——不是普通的”能用”,而是深度优化到可以发挥硬件100%性能的级别。这意味着什么?
打个比方:同样一辆车,普通适配像是换了套脚垫,原生适配则是发动机、变速箱、底盘全都重新调校过。开着能一样吗?
更重要的是价格。DeepSeek V4的API定价,只有OpenAI的 十分之一 。
这意味着,同样的预算,以前只能调用100万次,现在可以调用1000万次。中小企业和个人开发者,终于也能用得起顶级AI能力了。
五、政策加速:工信部”模数共振”覆盖20大制造业
技术突破之外,政策层面的推动同样关键。
工信部推进的” 模数共振 “行动,正在把AI大模型落地到20个重点制造业行业。从汽车装配到纺织品检测,从钢铁冶炼到药品研发,AI正在渗透到产业链的每一个毛细血管。
简单解释一下”模数共振”:就是让大模型”学会”工业生产的专业术语和生产流程,然后反过来指导生产。
效果已经开始显现:有工厂引入AI质检后,不良率从3%降到了0.5%,一年省下上千万的返工成本。
这种大规模落地应用,反过来又为国产模型提供了海量的真实数据和反馈,形成了一个”越用越好用、越好用越用”的正向循环。
六、写在最后:领先只是开始

看到这里,你可能会问:中国AI这次是真的”弯道超车”了吗?
我的答案是: 阶段性领先,但远未到终点。
芯片制造、底层算法、基础研究,美国依然有优势。但AI这个赛道的特殊之处在于: 它不只是技术的竞争,更是应用、场景、数据、迭代速度的综合较量。
中国有全球最大的互联网用户群,有最丰富的应用场景,有最活跃的开发者生态,有最完善的制造业基础。这些因素叠加在一起,正在形成一种”规模效应”——用的人越多,模型越好用,模型越好用,用的人越多。
7.94万亿Token,不是终点,而是新的起点。
你怎么看这次中国AI的”逆袭”?
-
你觉得国产AI和ChatGPT还有哪些差距? -
你自己在工作和生活中用AI吗?感受如何?
评论区聊聊,点赞、关注是对我最好的支持~