 夜雨聆风
夜雨聆风





赛博夜校|AI是怎么"学习"的
如果你没断网,你最近肯定看到很多的AI相关新闻以及各种暴论。
什么AI不会替代人类,AI只会替代不会使用AI的人。来深圳干AI,三个月买房。离职做OPC(一个人公司的概念)月入百万。
看到这些让人震惊的信息。说实话,我很震惊,也很慌。
作为一个正处于职业危机+中年危机时间节点上的人。我有些不安了。是那种对未来不确定性的迷茫和恐慌。就像是达摩克利斯之剑,你永远不知道它什么时候会落下。那种感觉就是,面对强大的AI,人类自身太弱小了,面对一个完全看不懂的东西,除了慌,什么都做不了。
所以秉承着知己知彼百战不殆的思想。我决定去了解一下AI,咱也不是专家。太深度的也不懂。那就用普通人的视角来拆解一下AI这个神秘的东西。
讲到AI就离不开一个概念:机器是怎么”学习”的?
“机器学习”这个词最早是1959年Arthur Samuel提出的。他写了个下棋程序,不是教机器每一步怎么走,而是让它自己跟自己下了几万盘,越下越强。他给这件事下了个定义:让机器不用被明确编程就能学会某种能力。这个思路到今天没变过——不写规则,给数据,让机器自己找规律。
嗯。。是不是讲得很好,那是什么意思呢,没事,先复制给AI。看看AI怎么说。AI吐了一大段。。。我看了几十遍,近视又加深了不少,总算是总结出来了一些东西。
首先是准备工作。程序员用一段Python代码在GPU上面布置了一个神经网络模型,这个模型是一个多层矩阵。可以想象成是多个表格摞在一起。只不过这个表格非常大,具体的大小取决于Python代码中设定的size。当然了这么大的表格,一个GPU肯定是放不下的,所以会把模型分成小块,分别放在多个GPU上,再把GPU连在一起。为了便于理解,还是可以把这个模型想象成一摞表格。
下一步就是给这个表格中的每一个单元格,随机填上一个数字。每个格子里的数字就是一个”权重”——你可以理解为一个旋钮,控制着信号传递的强弱。现在这些旋钮全是随便拧的,所以此时的模型什么都不会,输出全是乱码。
现在万事俱备,就可以开始训练了。训练总共分六步。一、把大象装进冰箱。。。搞错了。。。
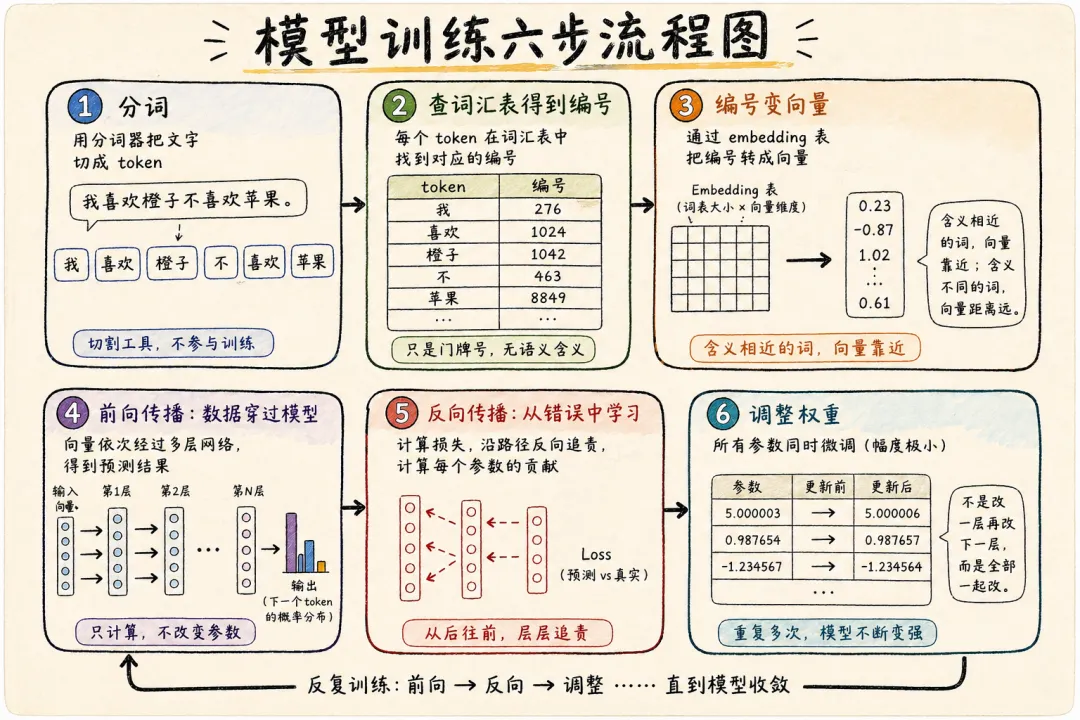
第一步:分词
模型不认识字。直接塞字进去肯定是行不通的。所以第一件事是用分词器(tokenizer)把文字切碎。切完后的东西就是我们常说的token。需要注意的是,不是按字切,也不是按词切,而是按”子词”切——常见的词保持完整,少见的词拆成碎片。比如:我喜欢橙子不喜欢苹果。就可以拆成【我】、【喜欢】、【橙子】、【不】、【喜欢】、【苹果】6个token。
分词器是一个预设好的规则。不参与训练,不会被改变。它就是个切割工具。
第二步:查词汇表得到编号
每个token在词汇表里对应一个编号。”苹果”可能是8849,”橙子”可能是1042。这个编号没有任何含义,不代表重要性,不代表相似度,相邻编号的词也没有任何关系。它就是一个门牌号,唯一的作用是让系统能找到这个token
就这???我学之前以为AI处理语言有多高深,不就是拆分和查询么,谁不会呢。
第三步:编号变向量
重点来了。这也是最难理解部分。
编号不能直接参与计算——它只是个单一数字,没有信息量。所以需要把编号转化成向量。向量是一组几千维的数字,比如 [0.23, -0.87, 1.02, …],长度可能是12288个数字。模型里有一张embedding表,大小是”词表数量 × 向量维度”(比如10万 × 12288)。每个token的编号就是在这张表里查对应那一行,取出来的就是它的向量。
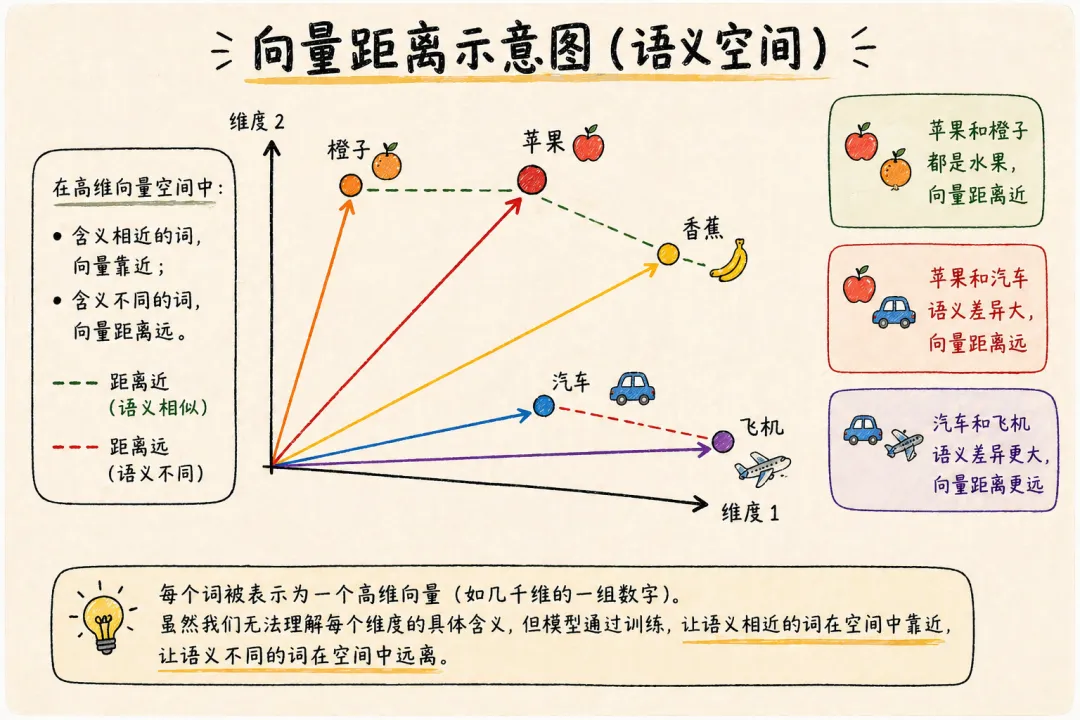
向量编码的是这个词的”语义特征”。你不需要知道12288个数字里每一个具体代表什么——这些维度是模型自己训练出来的,大多数没有人类能命名的含义。你只需要知道结果:含义相近的词,向量靠近;含义不同的词,向量距离远。苹果和橙子都是水果,向量距离近。苹果和汽车,距离远。
到这里,文字就变成了模型能”算”的东西。
说实话,我在理解向量这个概念的时候卡了很久。当时我一直认为向量的每个维度都代表一个具体的语义,比如颜色、形状、口味。后来才搞明白,这些维度初始就是随机的数字,embedding表在训练过程中会跟着一起被调整。训练完成后,这些数字本身依然没有人类能理解的含义——但含义相近的词,数字会自动靠近。模型不需要”懂”,它只需要算。embedding干的事情本质上就是:把文字变成一排数字,让计算机能做数学题。就这么朴素。
第四步:前向传播——数据穿过模型
向量准备好了,接下来就是让它穿过那一摞表格。第一层矩阵拿到向量,做一次运算(本质就是乘法和加法),输出一组新的数字,传给第二层。第二层再算,传给第三层。一层一层往前走,一直走到最后一层。GPT级别的模型有96层,就是穿过96张表格。
最后一层输出的是一个概率分布——词表里每个token出现在”下一个位置”的可能性各是多少。概率最高的那个,就是模型的预测。
整个过程中,表格里的数字一个都不会变。前向传播只是在”用”现有的参数算结果,不是在学习。
是的,你没听错。穿过96层表格,一个数字都没变。可能你会想那学习到底发生在哪一步?
第五步:反向传播——从错误中学习
学习发生在这一步。
模型预测了下一个词,但训练数据里有正确答案。把预测和答案一比,就能算出差距有多大,这个差距叫loss。
然后关键操作来了:沿着刚才前向的路径,倒着往回走。从第96层开始,一层一层往回追问:”这个错误,你这一层的哪些数字要负多少责任?”一直追到第1层。每一层的每一个格子,都会被算出一个值:”你对这次犯错贡献了多少。”
很抽象对吧,模型犯错也要追责。
第六步:调整权重
追责完毕,所有格子同时微调。不是改一层再改下一层,是全部一起改。调整幅度极小——不是5变成6,而是5变成5.000003。具体改多少,由一个叫”学习率(Learning rate)”的参数控制。学习率就是这模型每次调整的步长,大了容易产生震荡,小了又会学的慢。
你可能会说,5变成5.000003。就改了这么点?对,就这么点。但是几万亿个格子同时改这么一点点,累积起来模型的行为就变了。然后下一批数据进来,再走一遍前向→反向→调整。几万亿个词,反复喂,反复调。训练几个月,那些最初随机填入的数字,就被数据一点一点雕刻成了蕴含规律的参数。
至此,一个模型就训练出来了。
现在回到开头。是不是觉得模型没那么神秘了?那些满天飞的名词——tokenizer、vocabulary、embedding、forward pass、backward propagation——拆开看,不过就是切词、编号、查表、算数、纠错。每一步都是朴素的数学,没有任何魔法。
当然为了便于理解,有很多概念没有讲到。比如实际模型训练中的多头注意力、残差连接等。不是不想讲,是我也没学到那呀。这只是最基础的机器学习概念。但理解了机器学习就像学会了武功心法,后面学习招式就容易很多了。
写在最后
在整个学习的过程中,我脑海里一直有一个人物形象。《一人之下》里的丁嶋安。他因为自身的弱小和不安,不断学习和磨炼自己,最终成为了两豪杰之一。
在AI来临的这个时代,我们普通人何尝不都是弱小的丁嶋安呢。但说真的,上面这些内容,都是我跟AI对话一步一步弄懂的。AI带来了焦虑,但也把学习的门槛压到了前所未有的低。
写完这篇文章那天晚上,我又打开AI问了一个新问题:什么是注意力机制?
它回了一大段。我看了两遍,没看懂。
但这次我不再震惊、也不再慌张了。
PS:学习的过程中,我让AI问了我5个问题,检测一下学习成果。看看你能不能答对。

汇报一下目前正在学习第二部分:神经网络。等我弄懂了就写出来。
欢迎评论交流想法,如果觉得有意思请关注、点赞、转发吧!!