 夜雨聆风
夜雨聆风





【技术解码】文档智能解析:从非结构化内容到结构化数据的完整技术链路
本文聚焦文档智能解析技术——深入解析 OCR、表格识别、版面分析、视觉大模型等核心原理,探讨从 PDF/扫描件中提取结构化信息的技术架构与工程实践,结合银行业文档处理场景提供落地指南。
一、为什么文档智能是数据治理的关键基础设施
1.1 银行业面临的“文档困境“
在银行日常运营中,大量的业务文档以非结构化形式存在:
• 信贷业务:贷款合同、抵押文件、征信报告、财务报表
• 运营管理:内部审批单据、影像资料、会议纪要
• 监管合规:反洗钱报告、监管报送材料、审计底稿
• 客户服务:开户资料、交易凭证、邮件往来
据行业估算,超过 80% 的银行数据资产以非结构化文档形式存在,但传统模式下,这些文档的利用率极低——要么堆在档案室里落灰,要么需要人工逐份录入系统。
1.2 从“电子化“到“智能化“的跨越
|
阶段 |
核心能力 |
局限性 |
|
扫描电子化 |
纸质文档→ PDF 图片 |
不可检索、不可分析 |
|
基础 OCR |
图片→ 文本 |
准确率低、结构丢失、表格乱码 |
|
智能解析 |
文档→ 结构化数据 |
技术门槛高、工程复杂度大 |
文档智能解析(Intelligent Document Processing, IDP)正是解决“最后一公里”的关键技术——它不仅识别文字,更理解文档的语义结构和版面布局,将非结构化内容转化为机器可处理的结构化数据。
1.3 技术定位:数据治理的技术支撑
从DAMA数据管理知识体系视角看,文档智能解析是数据集成与互操作(第8章)、文件与内容管理(第9章)的重要技术支撑。它解决的问题是:
如何高效地将散落在各类文档中的业务数据,转化为可治理、可分析的数据资产?
二、核心技术原理:从传统 OCR 到多模态大模型
2.1 传统 OCR 技术架构
2.1.1 三阶段流水线
传统 OCR 采用经典的”检测→ 识别 → 后处理“三阶段架构:
第一阶段:文本检测(Text Detection)
在图像中定位文本区域的位置,将文本从背景中“切割”出来。
|
算法 |
特点 |
代表模型 |
|
CTPN |
基于 RNN 的水平文本检测 |
早期开源方案 |
|
EAST |
实时场景文字检测 |
速度快,精度一般 |
|
DBNet |
可微分二值化 |
轻量高效,主流选择 |
|
CRAFT |
字符级检测 |
弯曲文本效果好 |
// python# DBNet 文本检测核心逻辑(伪代码)def detect_text_regions(image): # 1. 特征提取 backbone features = backbone(image) # FPN/ResNet # 2. 预测概率图 probability_map = decoder(features) # 3. 可微分二值化 binary_map = differentiable_binarize(probability_map) # 4. 轮廓提取得到文本框 boxes = contour_extraction(binary_map) return boxes
第二阶段:文本识别(Text Recognition)
对检测到的文本区域进行字符识别,将图像转换为文本。
|
算法 |
特点 |
代表模型 |
|
CRNN+CTC |
卷积+循环+CTC |
端到端训练,主流方案 |
|
Attention-based |
引入注意力机制 |
精度更高,速度较慢 |
|
SVTR |
纯 Transformer 方案 |
2022 年新架构 |
// python# CRNN + CTC 文本识别架构class CRNN_CTC(nn.Module): def __init__(self): self.cnn = CNNBackbone() # 特征提取 self.rnn = nn.LSTM() # 序列建模 self.fc = nn.Linear(hidden, num_classes) # 分类 def forward(self, x): # x: [batch, channels, height, width] conv_features = self.cnn(x) # [B, C, 1, W] # 转为序列 [B, W, C] seq = conv_features.squeeze(2).permute(0, 2, 1) # RNN 编码 rnn_out, _ = self.rnn(seq) # [B, W, hidden] # CTC 解码 output = self.fc(rnn_out) # [B, W, num_classes] return output # 经过 CTC loss 训练
第三阶段:后处理(Post-processing)
对识别结果进行语言模型校正、格式规范化等处理。
// python# 语言模型后处理示例def post_process(text, lang_model): # 1. 去除噪声字符 text = clean_noise(text) # 2. 语言模型校正 candidates = lang_model.correct(text) text = select_best_candidate(candidates) # 3. 格式规范化 text = normalize_format(text) # 金额、日期、编号等 return text
2.1.2 PaddleOCR:国产 OCR 标杆方案
百度飞桨开源的 PaddleOCR 是目前较为成熟的国产OCR套件,其PP-OCRv3模型在中英文识别场景下达到产业级SOTA:
|
指标 |
PP-OCRv3 轻量版 |
PP-OCRv3 高精度版 |
|
模型大小 |
8.6 MB |
149 MB |
|
中文识别率 |
~96% |
~99% |
|
推理速度(GPU) |
50 img/s |
15 img/s |
核心技术创新:
1. 文本检测:LK-PAN 大感受野骨干网络 + DML 数据增强
2. 文本识别:SVTR 轻量级视觉序列建模 + GTC 字符级注意力
3. 方向分类:超轻量 MobileNetV3 分类器
// python# PaddleOCR 快速调用示例from paddleocr import PaddleOCRocr = PaddleOCR(use_angle_cls=True, lang=’ch’, use_gpu=True)result = ocr.ocr(‘bank_statement.jpg’)for line in result: box, (text, confidence) = line print(f”{text}: {confidence:.2f}”)
2.2 表格识别技术:难点中的难点
表格是文档解析的地狱级难题,原因在于:
• 表格结构多样:无线表、有线表、合并单元格、跨页表格
• 边界判断模糊:如何区分“表格”和”列表”?
• 行列关系复杂:合并单元格、斜线表头
• 数据类型多样:文本、数字、公式、图像
2.2.1 两阶段 vs 端到端
两阶段方案(先结构后内容):
表格检测→ 表格结构识别 → 单元格检测 → 单元格内容识别 → HTML/Excel 输出
|
模块 |
技术方案 |
代表模型 |
|
表格检测 |
目标检测 |
Faster R-CNN, YOLO |
|
结构识别 |
序列标注/图网络 |
TableMaster, SLANet |
|
单元格检测 |
实例分割 |
Mask R-CNN |
端到端方案(一步到位):
表格图像→ 直接输出 HTML/Excel(视觉编码 + 序列解码)
代表模型:TableFormer(NeurIPS 2021)、ViT-based Table Extraction
2.2.2 PaddleOCR 表格识别 v2 架构
百度最新的 PP-TableMagic 方案采用”表格分类 + 结构识别 + 单元格检测“三模块串联:
// python# PP-TableMagic 表格识别流程from paddleocr import PPStructurev2table_engine = PPStructurev2( layout_model=’pp-structured’, # 版面分析 table_model=’SLANet_plus’, # 表格结构识别 show_log=True)result = table_engine.predict(img)# 输出:{‘table_html’: ‘<table>…</table>’, ‘table_cells’: […]}
SLANet 核心技术:
1. 轻量骨干:PP-LCNet(CPU 友好)
2. 特征融合:CSP-PAN(高低层特征融合)
3. 位置对齐:SLA Head(结构+位置信息对齐)
|
模型 |
精度 |
GPU 延迟 |
CPU 延迟 |
模型大小 |
|
SLANet |
59.52% |
23.96 ms |
43.12 ms |
6.9 MB |
|
SLANet_plus |
63.69% |
23.43 ms |
41.80 ms |
6.9 MB |
|
SLANeXt_wired |
69.65% |
85.92 ms |
501.66 ms |
351 MB |
2.3 版面分析:理解文档的“骨骼“
版面分析(Layout Analysis)是识别文档中不同区域的功能类型(标题、段落、表格、图片、脚注等),这是让机器“看懂”文档的关键。
2.3.1 基于深度学习的版面分析
|
方法 |
原理 |
优缺点 |
|
目标检测 |
将各区域作为目标检测 |
精度高,依赖标注数据 |
|
语义分割 |
像素级区域分类 |
边界更精确,计算量大 |
|
混合方法 |
检测+分割结合 |
精度与效率平衡 |
主流模型:
• LayoutLM(微软):文档预训练模型,融合文本+布局+图像
• PaddleDetection:百度开源的版面分析套件
• DeepLayout(开源):基于 EfficientNet 的方案
// python# LayoutLM 版面分析示例from transformers import LayoutLMForTokenClassification, LayoutLMv3Processorprocessor = LayoutLMv3Processor.from_pretrained(“microsoft/layoutlmv3-base”)model = LayoutLMForTokenClassification.from_pretrained(“microsoft/layoutlmv3-base”)# 文档图像 + OCR 结果 → 版面分析inputs = processor(images, ocr_result, return_tensors=”pt”)outputs = model(**inputs)
2.3.2 金融文档特有挑战
银行文档的版面分析面临特殊挑战:
1. 印章遮挡:红色印章覆盖在文字上,影响检测
2. 手写体混排:签字、手写金额
3. 复杂表格:信贷报表、监管报表格式多样
4. 双栏排版:部分文件采用双栏排版
2.4 视觉大模型(VLM):下一代文档理解
2023 年以来,多模态大模型的崛起彻底改变了文档解析的技术路线。
2.4.1 端到端 VLM 解析
传统方案:PDF → 图片渲染 → OCR → 版面分析 → 后处理(多步骤,误差累积)
VLM 方案:PDF → 图片渲染 → VLM 直接输出结构化 Markdown(端到端)
代表项目:
|
项目 |
特点 |
GitHub Stars |
|
MinerU(上海 AI 实验室) |
精度最高,支持公式/表格 |
20K+ |
|
Marker |
开源方案,基于 Surya OCR |
持续更新 |
|
DocOwl(阿里) |
专用文档理解 VLM |
商业化成熟 |
|
GOT-OCR2.0 |
通用 OCR 理论框架 |
新兴方案 |
2.4.2 MinerU 核心技术解析
MinerU 被认为是当前精度最高的开源文档解析方案,其技术亮点:
1. 混合文档理解策略
// python# MinerU 多级解析流程class DocumentParser: def parse(self, pdf_path): # 1. 页面渲染 pages = self.render_pages(pdf_path) # 2. 页面级理解(VLM) for page in pages: if page.is_complex(): # 表格/公式密集 page.structure = self.vlm_parse(page) # VLM 精修 else: page.structure = self.fast_parse(page) # 轻量方案 # 3. 跨页内容合并 doc = self.merge_pages(pages) return doc
2. 公式识别(LaTeX 输出)
金融文档中大量存在数学公式(利率计算、风险模型等),MinerU 支持:
• 行内公式:$E = mc^2$
• 行间公式:$$\int_0^1 f(x) dx$$
3. 表格结构恢复
支持合并单元格、跨页表格的完整结构重建,输出标准 HTML/JSON。
2.4.3 VLM vs 传统 OCR:关键取舍
|
维度 |
传统 OCR |
VLM 方案 |
|
精度 |
90-95% |
95-99% |
|
速度 |
快(~100ms/页) |
慢(~5-10s/页) |
|
成本 |
低(CPU 可运行) |
高(需 GPU) |
|
表格处理 |
需专门模块 |
原生支持 |
|
公式处理 |
不支持 |
原生支持 |
|
部署复杂度 |
低 |
高 |
工程建议:
• 混合架构:简单页面用 OCR 兜底,复杂页面用 VLM 精修
• 分级策略:根据文档复杂度自动选择处理路径
三、文档智能解析技术架构
3.1 完整技术架构图
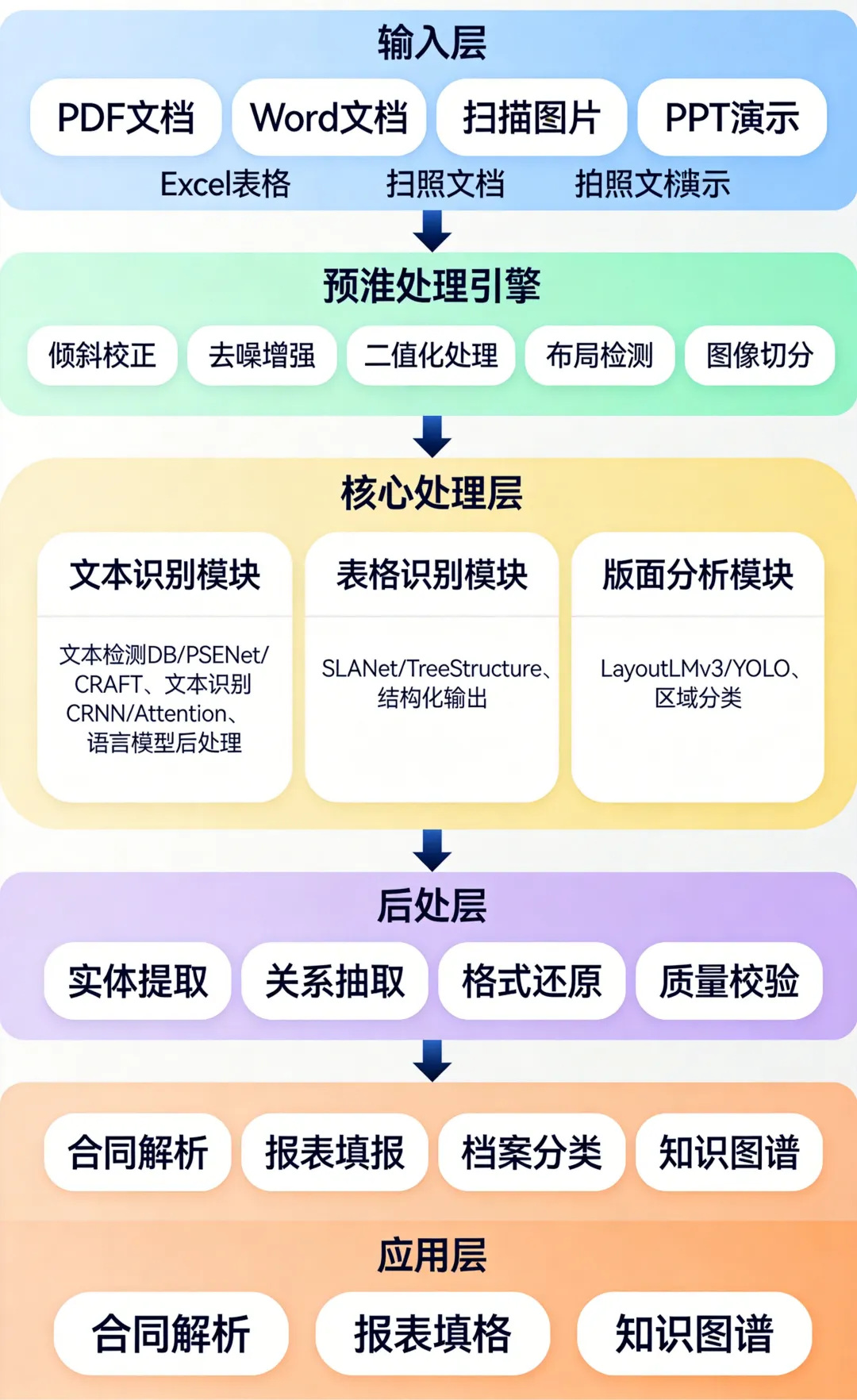
3.2 五层架构详解
**输入层**:多源异构文档接入
|
格式类型 |
特点 |
预处理策略 |
|
原生 PDF |
矢量文字,可提取文本 |
直接解析文本层 |
|
扫描 PDF |
图片,需 OCR |
全流程处理 |
|
Word/Excel |
结构化文档 |
库解析 + OCR 兜底 |
|
图片拍照 |
复杂噪声 |
增强 + 校正 |
**预处理层**:图像质量优化
// pythonclass ImagePreprocessor: “””文档图像预处理流水线””” def process(self, image): # 1. 倾斜校正(Deskew) image = self.deskew(image) # 2. 去噪增强(DENOISE) image = self.denoise(image) # 3. 二值化处理(Adaptive Threshold) image = self.binarize(image) # 4. 布局检测(Layout Detection) regions = self.detect_layout(image) # 5. 图像切分(Page Splitting) crops = self.crop_regions(image, regions) return crops
**核心处理层**:三大处理模块
文本识别模块:
• 文本检测:DB/PSENet/CRAFT
• 文本识别:CRNN + CTC / Attention
• 语言模型后处理:纠错、规范化
表格识别模块:
• 表格检测:目标检测
• 结构识别:SLANet / TableMaster
• 单元格定位 + 内容识别
文档理解模块:
• 印章/签名检测:目标检测
• 视觉大模型:LayoutLMv3 / Qwen-VL
• 关键信息抽取(KIE)+ 实体识别(NER)
**后处理层**:数据融合与校验
// pythonclass PostProcessor: “””多模态结果融合与校验””” def merge(self, text_result, table_result, doc_result): # 1. 多模态融合 merged = self.fuse(text_result, table_result, doc_result) # 2. 规则校验 validated = self.rule_validate(merged) # 3. LLM 语义校验(可选) if self.use_llm: validated = self.llm_correct(validated) # 4. 结构化输出 return self.format_output(validated)
**应用层**:行业场景落地
|
场景 |
核心需求 |
技术重点 |
|
RAG 知识库 |
文档切片、语义检索 |
版面分析、Markdown 输出 |
|
合同解析 |
条款提取、风险识别 |
KIE、NER、合同模板 |
|
财报分析 |
表格数据提取、趋势分析 |
表格识别、数据校验 |
|
表单录入 |
字段提取、自动填表 |
表单理解、结构化输出 |
|
档案数字化 |
全量文档电子化 |
批量处理、质量控制 |
四、技术选型对比分析
4.1 开源框架横评
|
框架 |
开发者 |
表格支持 |
VLM 支持 |
部署难度 |
适用场景 |
|
PaddleOCR |
百度 |
★★★★☆ |
★★☆☆☆ |
低 |
通用 OCR、表格识别 |
|
EasyOCR |
JK/Jag |
★★★☆☆ |
★☆☆☆☆ |
低 |
多语言 OCR |
|
Tesseract |
|
★★☆☆☆ |
★☆☆☆☆ |
低 |
基础 OCR |
|
MinerU |
上海 AI Lab |
★★★★★ |
★★★★★ |
高 |
高精度文档解析 |
|
Marker |
开源社区 |
★★★★☆ |
★★★★☆ |
中 |
开源 VLM 方案 |
|
Unstructured |
Unstructured.io |
★★★★☆ |
★★★☆☆ |
低 |
企业知识库 |
4.2 商业云服务对比
|
服务商 |
产品 |
优势 |
劣势 |
|
阿里云 |
OCR/表格识别 |
中文优化、本地化部署 |
价格较高 |
|
腾讯云 |
OCR/卡证识别 |
微信生态集成 |
表格支持一般 |
|
百度智能云 |
文字识别 |
PP-OCRv3、表格识别 |
复杂文档处理一般 |
|
Azure |
Form Recognizer |
多语言、版式丰富 |
国内访问慢 |
|
AWS |
Textract |
与 AWS 生态集成 |
价格高 |
4.3 选型决策树
文档类型?├── 原生数字文档(Word/Excel/PDF文字层)│ └── 推荐:库直接解析(python-docx/openpyxl) + 轻量 OCR 兜底│├── 扫描文档/图片(简单排版)│ ├── 低精度要求 → PaddleOCR(PP-OCRv3)│ └── 高精度要求 → PaddleOCR + 后处理│├── 扫描文档(复杂表格/公式)│ ├── 追求精度 → MinerU(VLM 方案)│ └── 平衡成本 → PaddleOCR PP-Structurev2│└── 企业级知识库└── 推荐:Unstructured.io(多格式支持好)
五、行业应用场景:银行业的落地实践
5.1 场景一:贷款合同智能解析
业务痛点:
• 信贷审查需人工阅读大量合同条款
• 关键要素(金额、期限、利率、担保条款)提取耗时
• 合同版本多,条款差异难以发现
技术方案:
// pythonclass ContractParser: “””贷款合同解析器””” def parse(self, contract_pdf): # 1. 文档解析 doc = self.doc_parser.parse(contract_pdf) # 2. 条款提取(基于模板 + NER) extracted = { ‘borrower’: self.extract_entity(doc, ‘借款人’), ‘amount’: self.extract_entity(doc, ‘借款金额’), ‘rate’: self.extract_entity(doc, ‘年利率’), ‘term’: self.extract_entity(doc, ‘借款期限’), ‘guarantee’: self.extract_clause(doc, ‘担保条款’), } # 3. 风险点识别 risks = self.detect_risks(doc) # 4. 合同比对(版本差异检测) diff = self.compare_versions(doc, reference_doc) return {‘extracted’: extracted, ‘risks’: risks, ‘diff’: diff}
实施效果(某股份制银行案例):
• 单份合同解析时间:45 分钟 → 3 分钟
• 要素提取准确率:98.5%
• 风险条款识别率:96.2%
5.2 场景二:监管报表自动填报
业务痛点:
• 月报/季报涉及 100+ 张表格
• 数据来源分散:核心系统、信贷系统、财务系统
• 人工填报易出错,核查工作量大
技术方案:
1. 数据源识别:自动识别不同系统的报表格式
2. 跨表关联:建立表间数据映射关系
3. 一致性校验:自动核对数据逻辑一致性
4. 异常预警:发现数据异常时自动标记
// python# 监管报表自动生成流水线class ReportGenerator: def generate(self, report_template, data_sources): # 1. 模板解析 template = self.parse_template(report_template) # 2. 数据抽取 for field in template.fields: value = self.extract_from_sources(field, data_sources) field.value = value field.confidence = self.get_confidence(field) # 3. 自动填报(高置信度) for field in template.fields: if field.confidence > 0.95: self.auto_fill(field) else: self.mark_for_review(field) # 4. 生成报告 return self.compile_report(template)
5.3 场景三:影像档案智能分类
业务痛点:
• 柜面业务产生大量影像资料
• 人工分类效率低、易出错
• 后续检索困难
技术方案:
// pythonclass ImageClassifier: “””影像资料智能分类””” def classify(self, image): # 1. 版面分析 layout = self.layout_analyzer.analyze(image) # 2. 图像特征提取 features = self.extract_features(image) # 3. 多标签分类 labels = self.model.predict(features) # 4. 置信度阈值 if max(labels.prob) < 0.8: return {‘label’: labels.top1, ‘confidence’: labels.prob, ‘review’: True} return {‘label’: labels.top1, ‘confidence’: labels.prob, ‘review’: False}
实施效果:
• 分类准确率:97.3%
• 自动分类占比:85%
• 人力节省:60%
六、实施建议与技术难点
6.1 项目实施路线
Phase 1:基础能力建设(3-6 个月)
|
里程碑 |
内容 |
交付物 |
|
M1 |
OCR 能力搭建 |
PaddleOCR 部署、基础识别 API |
|
M2 |
表格识别试点 |
2-3 种常用表格识别模型 |
|
M3 |
版面分析集成 |
文档分类 + 区域定位能力 |
Phase 2:场景深化(6-12 个月)
|
里程碑 |
内容 |
交付物 |
|
M4 |
核心场景落地 |
合同解析/报表填报等 3-5 个场景 |
|
M5 |
VLM 能力引入 |
复杂文档解析精度提升 |
|
M6 |
智能化升级 |
LLM 语义校验、知识抽取 |
Phase 3:规模化推广(12-18 个月)
|
里程碑 |
内容 |
交付物 |
|
M7 |
全场景覆盖 |
80%+ 文档类型覆盖 |
|
M8 |
运营体系建立 |
持续优化、长尾问题处理 |
6.2 关键技术难点与应对策略
难点一:扫描件质量参差不齐
|
问题 |
应对策略 |
|
光照不均 |
自适应图像增强 |
|
倾斜/旋转 |
倾斜校正算法 |
|
模糊/污损 |
超分辨率重建 + 多帧融合 |
|
印章遮挡 |
印章检测 + 文字修复 |
难点二:复杂表格结构
|
问题 |
应对策略 |
|
合并单元格 |
图结构建模 + 跨行推理 |
|
跨页表格 |
跨页检测 + 内容合并 |
|
无线表 |
结构推理 + 语义理解 |
|
嵌套表格 |
递归解析 |
难点三:模型冷启动
|
问题 |
应对策略 |
|
标注数据不足 |
合成数据 + 主动学习 |
|
长尾样本 |
数据增强 + 难例挖掘 |
|
领域适配 |
迁移学习 + 微调 |
难点四:精度与效率平衡
|
策略 |
适用场景 |
|
分级处理 |
简单文档快处理,复杂文档精处理 |
|
模型蒸馏 |
轻量模型替代重型模型 |
|
缓存复用 |
相同文档只处理一次 |
6.3 工程化要点
1. 批处理与流处理结合
// python# 异步批处理架构class DocumentProcessingPipeline: def __init__(self): self.queue = asyncio.Queue() self.workers = [asyncio.create_task(self.worker()) for _ in range(4)] async def process(self, doc): future = asyncio.Future() await self.queue.put((doc, future)) return await future async def worker(self): while True: doc, future = await self.queue.get() result = await self.process_single(doc) future.set_result(result)
2. 质量控制机制
• 置信度阈值:低置信度结果自动进入人工复核
• 交叉校验:多模型结果相互验证
• 黄金数据集:定期评估模型精度
• 灰度发布:新模型逐步放量
3. 运维监控体系
• 识别准确率实时监控
• 处理延迟告警
• 模型版本管理
• A/B 测试框架
七、总结与展望
7.1 核心技术要点回顾
|
层级 |
关键技术 |
成熟度 |
选型建议 |
|
文本识别 |
PP-OCRv3、CRNN+CTC |
★★★★★ |
生产首选 |
|
表格识别 |
SLANet、TableMaster |
★★★★☆ |
复杂表格用端到端 |
|
版面分析 |
LayoutLM、PaddleDetection |
★★★★☆ |
金融文档需定制 |
|
视觉大模型 |
MinerU、Marker |
★★★☆☆ |
复杂文档场景 |
7.2 未来技术趋势
短期(1-2 年):
• VLM 解析精度持续提升,成本下降
• 端到端方案逐步替代传统流水线
• 专用领域模型(金融/法律/医疗)成熟
中期(3-5 年):
• 原生数字文档直接 API 输出结构化数据
• AI Agent 自主处理文档任务
• 实时文档理解成为标配
7.3 给银行业数据从业者的建议
1. 从小切口切入:选择 ROI 明确的场景(如合同要素提取、报表自动填报)优先落地
2. 重视数据治理:文档解析质量依赖输入数据质量,扫描规范化是关键
3. 建立评估体系:量化文档解析的准确率、效率提升,作为持续优化依据
4. 关注技术演进:VLM 方案快速迭代,保持技术敏感度,择机引入