 夜雨聆风
夜雨聆风





谁懂啊安卓本地跑Gemma4零后端
在Android上运行Gemma 4:E2B:一个极简Kotlin应用
无需后端,无需API——仅需一个2.5GB的模型本地运行(以及实现这一切的完整过程)
在Android上运行一个基于Gemma 4:E2B的聊天机器人
不是通过API调用,不是靠后端服务,也不是封装云服务,我要让模型完全本地运行,在一个用Kotlin编写的小型Android应用里实现:搭配简单的聊天界面、本地推理、还能支持Markdown格式的回复(毕竟Gemma 4本身就会输出Markdown格式的回复)。
本文会一步步介绍我是如何搭建它的、做了哪些配置、哪些环节很顺利、哪些坑我踩了好久。
项目目标
我的目标是:
- 用Kotlin创建一个极简应用
- 搭建类聊天机器人的交互界面
- 本地运行Gemma 4:E2B模型
- 应用完全离线可用
- 美观展示模型的回复,包括Markdown格式渲染
这听起来很简单,但这句话背后藏着好几个需要解决的模块:
- Android UI界面
- 模型运行时
- 模型文件本身
- 对话生命周期管理
- 回复内容渲染
我发现只要其中任何一个环节出点小问题,整个应用就会变得非常脆弱。
分步实现方案
步骤1:创建Android应用
我先在Android Studio新建了项目,选择了:
- Empty Activity(空Activity模板)
- Kotlin 语言
- Jetpack Compose UI框架
这是最省心的基础配置,因为用Compose搭基础聊天UI速度非常快。
应用的第一个版本只有三个部分:
- 消息列表
- 文本输入框
- 发送按钮
数据模型我故意做的非常精简:
data classChatMessage( val text: String, val isUser: Boolean )
UI部分就是一个用来展示对话的LazyColumn,加上一个OutlinedTextField和一个Button。
这部分是整个项目最顺利的环节。就算你只会一点Compose(我当时其实不太会),也能很快搭出一个极简的聊天界面。
步骤2:选择正确的模型格式
这是第一个容易搞混的地方。
我找到了好几种模型文件和格式,包括:
.task.web.task.litertlm
乍一看这些格式差不多,好像可以通用,但其实完全不行。对于这个Android项目,正确的模型文件是:
gemma-4-E2B-it.litertlm
我是从HuggingFace的litert-community仓库下载到的这个文件:
litert-community/gemma-4-E2B-it-litert-lm(main分支)
我们致力于通过开源和开放科学推动人工智能的发展与普及。
这一点非常重要,因为我用的运行时是LiteRT-LM,它只支持.litertlm格式的模型。
步骤3:安装模型
下载到正确的模型文件之后,我需要把它放到Android应用能访问到的位置。
开发阶段我用adb命令把模型传到模拟器/真机上:
adb shell mkdir -p /data/local/tmp/llm/ adb push gemma-4-E2B-it.litertlm /data/local/tmp/llm/gemma-4-E2B-it.litertlm
这就足够开始开发了。
这里有个惊喜:我用Android模拟器的CPU后端就能跑通模型。很多端侧模型的讨论大多聚焦在真机上,但对于开发和迭代来说,模拟器+CPU完全够用,这让整个开发流程顺畅了很多。
步骤4:给应用添加模型运行时
下一步就是集成能加载、执行模型的Android运行时。
在app/build.gradle.kts里添加LiteRT-LM的依赖:
implementation("com.google.ai.edge.litertlm:litertlm-android:latest.release")
同步Gradle之后,我就可以导入模型运行时的类,构建模型配置了。
核心的配置代码如下:
val config = EngineConfig( modelPath ="/data/local/tmp/llm/gemma-4-E2B-it.litertlm", backend = Backend.CPU(), cacheDir = context.cacheDir.absolutePath )
然后初始化引擎:
val engine = Engine(config) engine.initialize()
再创建一个对话实例:
val conversation = engine.createConversation()
这是第一个真正的里程碑:现在应用有了UI、模型已经安装、运行时也能正常识别模型了。
步骤5:配置应用与模型的交互逻辑
为了保持代码整洁,我把运行时的逻辑封装到了一个小型的管理器类里。
这个管理器负责:
- 创建引擎实例
- 创建对话实例
- 发送提示词
- 页面销毁时释放资源
简化后的代码如下:
classGemma4Manager(private val context: Context) { private var engine: Engine?= null private var conversation: Conversation?= null suspend fun initialize() { if (conversation != null) returnif (engine == null) { val config = EngineConfig( modelPath ="/data/local/tmp/llm/gemma-4-E2B-it.litertlm", backend = Backend.CPU(), cacheDir = context.cacheDir.absolutePath ) val newEngine = Engine(config) newEngine.initialize() engine = newEngine } if (conversation == null) { conversation = engine!!.createConversation() } } fun reply(prompt: String): String { val currentConversation = conversation ?: error("Conversation not initialized") return currentConversation.sendMessage(prompt).toString() } fun close() { conversation?.close() conversation = null engine?.close() engine = null } }
我大部分时间都在修和对话生命周期相关的bug:有段时间我一直碰到A session already exists(会话已存在)的错误。原因说起来简单但很隐蔽:我重复创建了对话实例。
解决办法就是把对话当成有状态的对象对待:
- 只创建一次
- 反复复用
- 只有页面销毁或者聊天显式重置时才关闭
这是让应用稳定运行最关键的一点。
步骤6:从UI发送消息
管理器写好之后,把UI和逻辑打通就非常简单了。
用户点击发送按钮时:
- 把用户消息加到消息列表
- 显示一个临时的“思考中…”消息
- 在后台线程调用模型
- 拿到模型回复后加到消息列表
发送逻辑的代码如下:
scope.launch { val reply = withContext(Dispatchers.IO) { try { gemmaManager.initialize() gemmaManager.reply(userMessage) } catch (e: Exception) { "模型错误: ${e.message}" } } messages.add(ChatMessage(reply, false)) isLoading = false }
这里我故意没有做流式输出。
我确实试过流式输出、实时展示模型的“思考过程”,但这带来了大量额外复杂度:要处理Flow<Message>、输出解析、还有更多生命周期问题。对于极简应用来说,阻塞式的sendMessage()方案要可靠得多。
这又是一个非常有用的经验:**先跑通最简单的可用路径。
步骤7:CPU vs GPU 后端选择
一开始我尝试用GPU加速运行应用。
结果非常不顺利。
我碰到了和OpenCL相关的错误:
Can not find OpenCL library on this device
解决办法很简单,直接切换成:
backend = Backend.CPU()
CPU确实更慢,但在我的场景里要可靠得多,而且还支持模拟器测试。
所以虽然GPU听起来是“更优解”,但CPU其实是快速搭建稳定原型的更实用的选择。
你也可以参考我在Kaggle上写的关于在CPU上运行Gemma 4:E2B的Notebook:
在CPU上测试Gemma 4:E2B
使用Kaggle Notebook探索并运行机器学习代码 | 数据来自Gemma 4
步骤8:将模型回复按Markdown格式渲染
应用跑通之后,下一个问题就是展示效果。
Gemma的回复用Markdown格式展示会好看很多,但Jetpack Compose自带的Text()组件不支持渲染Markdown格式。
所以我引入了Markwon库。
在app/build.gradle.kts里添加依赖:
implementation("io.noties.markwon:core:4.6.2")
然后我没有用普通的Text来展示助手的消息,而是用AndroidView把传统Android的TextView嵌入到Compose里,再通过Markwon渲染Markdown内容。
Markdown消息气泡的代码如下:
@Composable fun AgentMessageBubble(markdown: String) { val context = LocalContext.current val markwon = remember(context) { Markwon.create(context) } Row( modifier = Modifier.fillMaxWidth(), horizontalArrangement = Arrangement.Start ) { Icon(Icons.Default.SmartToy, contentDescription ="Gemma") Spacer(modifier = Modifier.width(6.dp)) Box( modifier = Modifier .background(Color(0xFFEAEAEA), RoundedCornerShape(16.dp)) .padding(12.dp) ) { AndroidView( factory = { ctx -> TextView(ctx) }, update = { tv -> markwon.setMarkdown(tv, markdown) } ) } } }
然后在聊天列表里:
- 用户消息用普通气泡
- 助手消息用
MarkdownMessageBubble(...)
这样不用重写整个UI,就能让模型的回复展示效果好很多。
应用效果展示
几张应用截图,展示模型的部分能力:
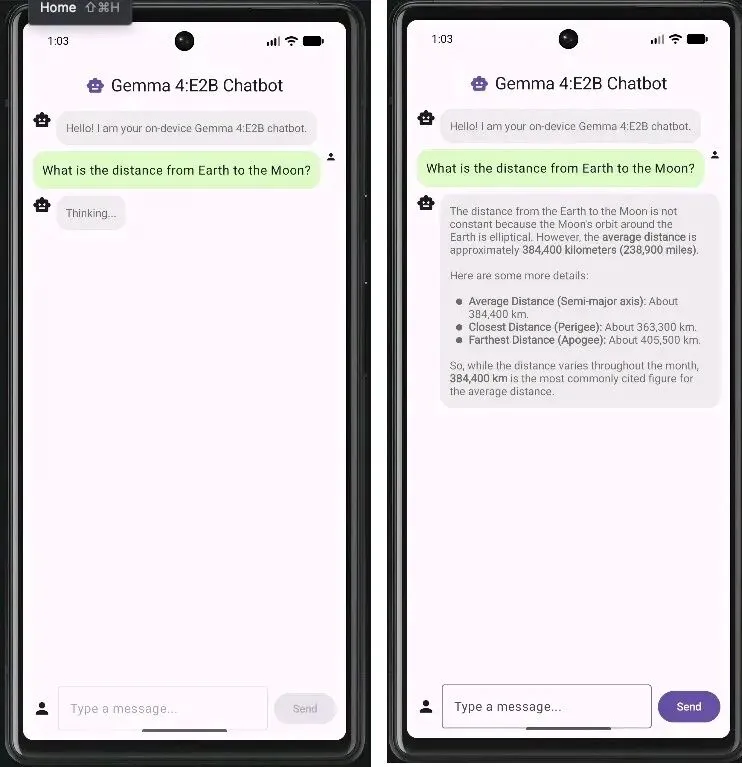
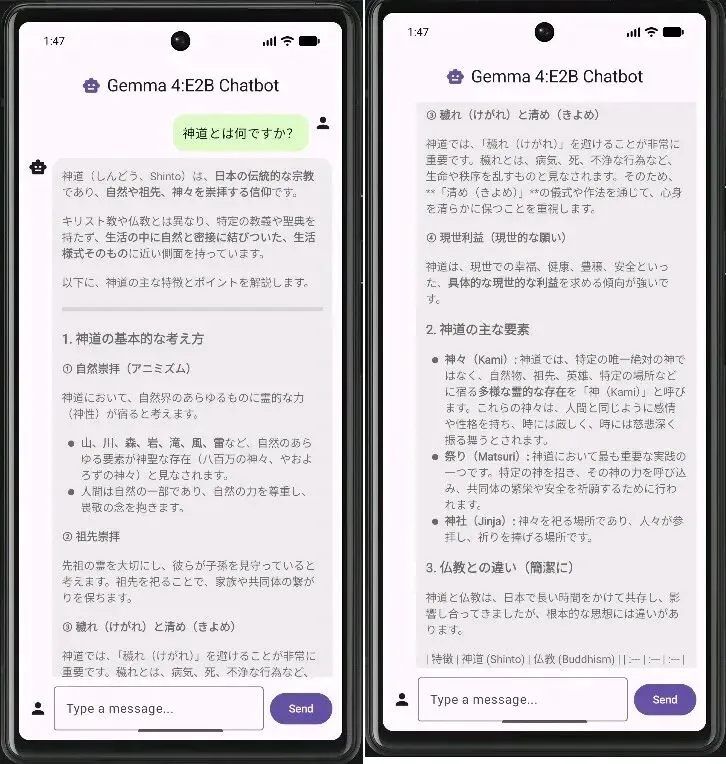
GitHub – gabrielpreda/kotlin-gemma-4e2b-chatbot
一个完全本地运行的Android聊天机器人,用Kotlin编写,基于端侧Gemma 4:E2B推理(无需后端,无需API)
你可以克隆、修改代码,在自己的手机上运行属于你自己的Gemma 4:E2B应用。
总结思考
顺利的部分
项目里有几个环节比我预期的顺畅很多:
- Compose做UI非常好用:对于小型聊天应用来说,Compose非常适配。一个
LazyColumn、一个输入框、一个按钮再加几个状态变量就能搞定大部分需求。 - 模拟器+CPU足够开发使用:这让迭代效率高了很多,我不用每次改代码都跑到真机上测试。
- 生命周期搞对之后,推理逻辑非常简单:把引擎、对话、模型路径都配置正确之后,发送提示词、拿到回复的逻辑非常干净。
整个体验最让我意外的是:最终能用的版本,比调试过程中踩的那些坑要简单太多了。
遇到的困难
- 模型与运行时不匹配:选错模型格式浪费了大量时间。
- 会话管理:对话生命周期是最难解决的问题。
- 流式输出:流式输出听起来很吸引人,但会快速增加复杂度。
- Markdown渲染:因为Compose默认不支持Markdown,要正确展示回复需要额外的开发工作。
本地运行的优势
完全本地运行有几个实打实的好处:
- 隐私:所有数据都不会离开设备。
- 无按次请求成本:模型下载完之后,应用运行不会产生API调用费用。
- 离线可用:没有网络也能使用聊天机器人。
- 完全可控:UI、提示词、模型集成、数据流全部由你自己控制。
这和基于云端AI服务开发应用的体验完全不同。
后续优化方向
这个版本是故意做的极简版,还有几个很明显的优化方向:
- 流式回复:如果回复能逐步展示的话,UI体验会好很多。
- 更好的Markdown支持:尤其是对公式和更丰富的格式的支持。
- 应用内下载模型:用
adb传模型只适合开发,不适合面向普通用户的应用。 - 更好的视觉设计:固定的标题栏、图标、头像、更好的间距、更精致的聊天布局都能提升体验。
- 对话管理:包括新建聊天、保存对话、重置对话、给对话加标题这些功能。
如果你也想做类似的项目,我最主要的建议是:先跑通最小可用版本,不要一开始就想着加所有功能。
原文链接:https://medium.com/@gabi.preda/running-gemma-4-e2b-on-android-a-minimal-kotlin-app-4272609bedc9