 夜雨聆风
夜雨聆风





24个集群仅用7秒!龙虾 OpenClaw 如何高效完成 Redis 巡检?
★ 点击名片,关注我们不迷路 ★
这是「AI运维实验室」的第三篇文章。前两篇聊了养虾社 Meetup 见闻和 OpenClaw 企业部署,这一篇讲一个具体的实战案例——怎么给你的龙虾写一个 Redis 巡检 Skill。
每天 20 分钟的体力活
我管着 24 个 ElastiCache Redis 集群,之前每天早上的巡检流程是这样的:
-
登录 AWS 控制台 -
逐个点开集群看 CPU、内存、连接数 -
跟昨天的数据对比,看有没有异常 -
把结果整理成报告发群里
后来我用 OpenClaw 做了自动化。给龙虾写了一个 Redis 巡检 Skill,现在在飞书里打两个字”Redis 巡检”,龙虾 7 秒出完整报告。
效果长什么样
在飞书聊天窗口发一句话,龙虾自动执行脚本、拉数据、对比基线、输出报告:
━━━━━━━━━━━━━━━━━━━━━━━━Redis 每日巡检报告2026年03月19日 星期四 09:30最近 24 小时━━━━━━━━━━━━━━━━━━━━━━━━[OK] 全部 24 个集群正常-- TOP 5 CPU集群 CPUxxx-redis-06 20.1%xxx-cache-01 19.4%xxx-main 19.3%xxx-proxy 14.9%xxx-biz-01 12.3%-- TOP 5 内存集群 内存xxx-data 72.8%xxx-persist 58.4%xxx-mail 57.7%xxx-queue 57.6%xxx-proxy 48.4%-- TOP 5 连接数集群 连接数xxx-persist 4,101xxx-redis-06 2,281xxx-redis-02 2,076xxx-redis-05 1,679xxx-main 1,650━━━━━━━━━━━━━━━━━━━━━━━━
如果有异常,会自动标记并高亮:
! 异常集群: 2/24集群 异常项xxx-cache-01 CPU: 72.3% (阈值70%, 基线45.2%, +60%) [!]xxx-redis-04 Evictions: 156 (过去24h)
[!] 是警告(指标突增 1.5 倍以上),[!!] 是严重(突增 2 倍以上)。不是简单的阈值告警,而是跟 7 天前同时段对比——能发现”缓慢恶化”的问题,比如内存每周涨 2%,单看当天数据正常,但跟基线一比就能发现趋势。
三样东西,就这么多
先看整体架构:
┌─────────────────────────────────────────────┐│ 飞书 ││ 用户发送 "Redis 巡检" │└──────────────────┬──────────────────────────┘│ WebSocket▼┌─────────────────────────────────────────────┐│ OpenClaw Gateway ││ ┌─────────┐ ┌──────────┐ ┌────────────┐ ││ │消息路由 │→│ AI Agent │→│ SKILL.md │ ││ │ │ │ (Gemini) │ │ 匹配触发词 │ ││ └─────────┘ └──────────┘ └─────┬──────┘ │└───────────────────────────────────┼─────────┘│ exec▼┌─────────────────────────────────────────────┐│ redis-overview.sh ││ ┌──────────┐ ┌───────────┐ ┌──────────┐ ││ │读取 │→│ 批量查询 │→│ 对比基线 │ ││ │config.json│ │ CloudWatch │ │ 标记异常 │ ││ └──────────┘ └───────────┘ └──────────┘ │└───────────────────────────────────┬─────────┘│▼┌─────────────────────────────────────────────┐│ AWS CloudWatch API ││ 24 集群 × 5 指标 = 2 次 API 调用 ││ 当前数据 + 7 天前基线 │└─────────────────────────────────────────────┘
巡检执行流程:
"Redis 巡检"│▼读取 config.json(集群列表 + 阈值)│▼构建批量查询 JSON├── 当前时段: 5 指标 × 24 集群└── 基线时段: 同上(7天前)│▼2 次 CloudWatch API 调用(共 7 秒)│▼逐集群分析├── CPU > 70%? ──────→ 标记异常├── CPU 突增 > 1.5x? → 标记 [!]├── CPU 突增 > 2.0x? → 标记 [!!]├── 内存 > 80%? ─────→ 标记异常├── 命中率下降 > 10%? → 标记异常└── Evictions > 0? ──→ 标记异常│▼输出报告(异常集群 + TOP 5)
整个方案的实现只有三样东西:
一个 bash 脚本
核心逻辑:调 CloudWatch get-metric-data API 批量查询所有集群的指标,同时拉 7 天前同时段的数据作为基线,逐个对比发现异常。
aws cloudwatch get-metric-data \--metric-data-queries file:///tmp/queries.json \--start-time "$START_TIME" \--end-time "$END_TIME" \--profile "$PROFILE" \--region "$REGION"
关键优化:用批量查询代替逐个查询。26 个集群 × 5 个指标 = 130 个指标,只需要 2 次 API 调用(当前 + 基线),7 秒搞定。之前逐个查要 3 分钟。
一份说明书(SKILL.md)
告诉龙虾:用户说什么话的时候,跑哪个脚本。
- "Redis 巡检" → redis-overview.sh(全局巡检)- "xxx Redis 详情" → redis-detail.sh(单集群详情)- "Redis 对比" → redis-compare.sh(上线前后对比)
龙虾不需要理解 Redis 是什么,它只需要知道”用户说了这句话,我就跑这个命令”。SKILL.md 就是这个映射关系。OpenClaw 的 Skill 体系设计得很巧妙——你不用写代码教 AI 怎么做,只需要用 Markdown 写一份说明书。
一个配置文件(config.json)
定义你的集群分组和告警阈值:
{"groups": {"core": ["xxx-main", "xxx-cache"],"api": ["xxx-redis-01", "xxx-redis-02"]},"thresholds": {"cpu_warn": 70,"memory_warn": 80,"spike_ratio": 1.5}}
换个环境用,改这个文件就行,脚本不用动。
不只是巡检
同样的模式,我还做了两个场景:
单集群详情——想看某个集群最近 3 小时的趋势,发一句”xxx-main 详情”,龙虾返回 CPU、内存、连接数、命中率、延迟的逐小时数据。
上线对比——发布后想确认有没有影响 Redis,发一句”xxx-main 对比 30”,龙虾自动对比发布前后 30 分钟的指标变化,输出对比表。
三个场景覆盖了日常 Redis 运维 90% 的需求:每天看一眼全局、出问题查详情、上线后确认影响。这就是 OpenClaw Skill 的威力——一个 Skill 解决一类问题,组合起来就是一套完整的运维工具箱。
从 20 分钟到 7 秒
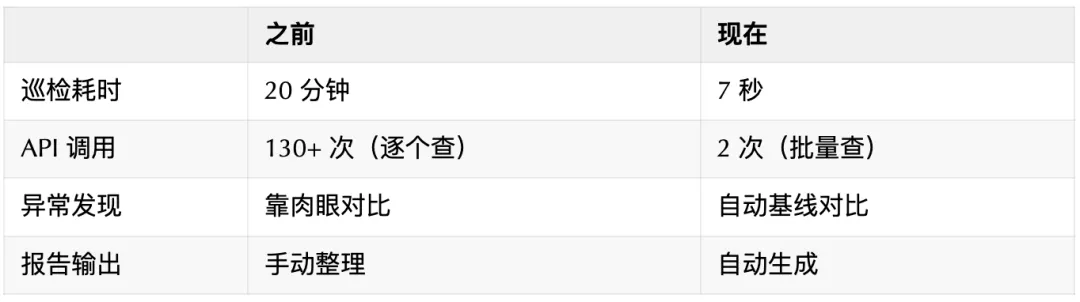
省下来的不只是时间。以前巡检是”看一眼没问题就过了”,现在龙虾每天自动跟 7 天前的基线对比,能发现肉眼看不出来的缓慢变化。
这也是 OpenClaw 做运维的核心价值——不是替代运维,是给运维装上外挂。你还是那个做决策的人,但龙虾帮你把重复劳动干了。
安全:给龙虾最小的钥匙
把 AWS AK/SK 交给 AI Agent,安全必须做到位。我们的做法是三层防护:
最小权限
给龙虾的 IAM 用户只有 CloudWatch 只读权限,连 EC2 列表都看不了:
{"Effect": "Allow","Action": ["cloudwatch:GetMetricData","cloudwatch:ListMetrics","elasticache:DescribeCacheClusters","elasticache:DescribeReplicationGroups"],"Resource": "*"}
就这四个 Action,多一个都不给。即使 AK/SK 泄露,攻击者也只能看监控数据,碰不了任何资源。
IP 白名单
IAM Policy 里加了 IP 条件限制,只允许 OpenClaw 所在机器的出口 IP 调用:
{"Condition": {"IpAddress": {"aws:SourceIp": ["<办公网络出口IP>/32"]}}}
AK/SK 拿到别的机器上用?直接 Access Denied。
异常访问检测
通过 CloudTrail + EventBridge 监控 AK/SK 的使用行为:
-
CloudTrail 记录所有 API 调用(谁、什么时间、从哪个 IP、调了什么) -
EventBridge 规则匹配异常模式:非白名单 IP 调用、非工作时间调用、调用频率突增 -
触发后 Lambda 自动推告警到钉钉,同时可以自动禁用 AK/SK
CloudTrail → EventBridge 规则 → Lambda → 钉钉告警└→ 自动禁用 Key
三层加起来:最小权限控制爆炸半径,IP 白名单防泄露利用,异常检测兜底。给龙虾的钥匙,只能开一扇门,只能在一个地方用,用的时候还有摄像头盯着。
代码开源
完整代码已开源,7 个文件,拿去改改 config.json 就能给你的龙虾装上 Redis 巡检技能:
https://github.com/clawnoc/clawnoc-skills/tree/main/skills/aws-redis-monitor
写于 2026 年 3 月,又一个不用手动巡检的早晨。龙虾已经把报告发到飞书了。
来源:本文转自公众号“AI运维实验室”,点击查看原文。
近期好文:
“高效运维”公众号诚邀广大技术人员投稿
投稿邮箱:jiachen@huayou-tech.com,或添加联系人微信:greatops1118。
“点赞”+“红心”,让我元气满满