 夜雨聆风
夜雨聆风





AI Case 2 · PDF文档智能问答
AI Case 2 · 文档智能问答:上传PDF就能问
每天一个AI实战案例,21天从入门到精通
这是第2天,今天我们要构建一个PDF文档智能问答系统——上传一份PDF,然后像聊天一样向它提问。
一、今天要做什么?
你有没有遇到过这种场景:
-
收到一份50页的技术文档,老板让你”快速总结一下核心要点” -
客户发来一份PDF合同,你需要快速找到某项条款的具体内容 -
团队知识库里存了上百份PDF报告,每次找信息都要手动翻
PDF文档智能问答就是解决这些痛点的。它的核心思路是:
-
解析PDF → 提取全部文本 -
文本分块 → 把长文档切成小块 -
向量化 → 用Embedding模型把文本变成数学向量 -
存入向量数据库 → 建立语义索引 -
用户提问时 → 语义检索最相关的片段 → 喂给LLM生成精准答案
这就是RAG(Retrieval-Augmented Generation,检索增强生成)的经典流程。
二、系统架构
整个系统分为离线索引阶段和在线问答阶段:
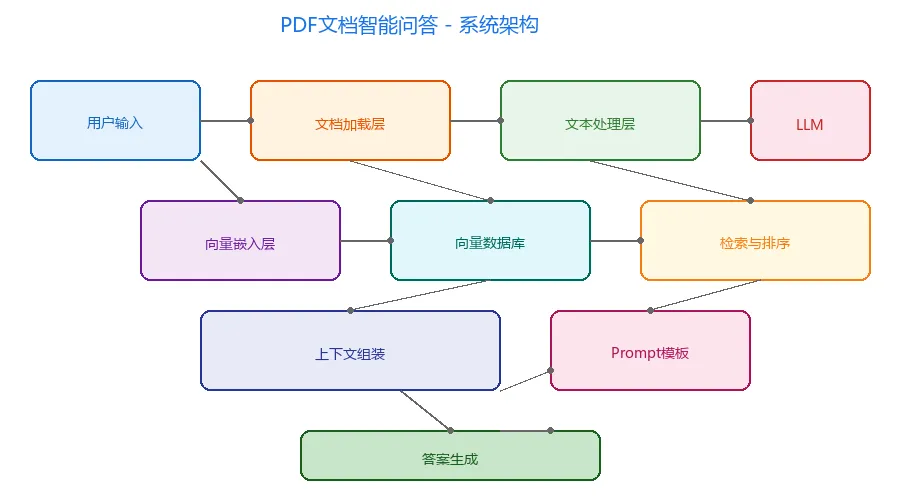
核心组件说明:
| 组件 | 作用 | 推荐方案 |
|---|---|---|
| PDF解析器 | 提取PDF中的文本内容 | PyPDF2 / pdfplumber |
| 文本分割器 | 按语义边界切分文本 | RecursiveCharacterTextSplitter |
| Embedding模型 | 文本向量化 | text-embedding-3-small / bge-large |
| 向量数据库 | 存储和检索向量 | FAISS / ChromaDB / Milvus |
| LLM | 理解上下文生成答案 | GPT-4 / Qwen / GLM-4 |
三、完整代码实现
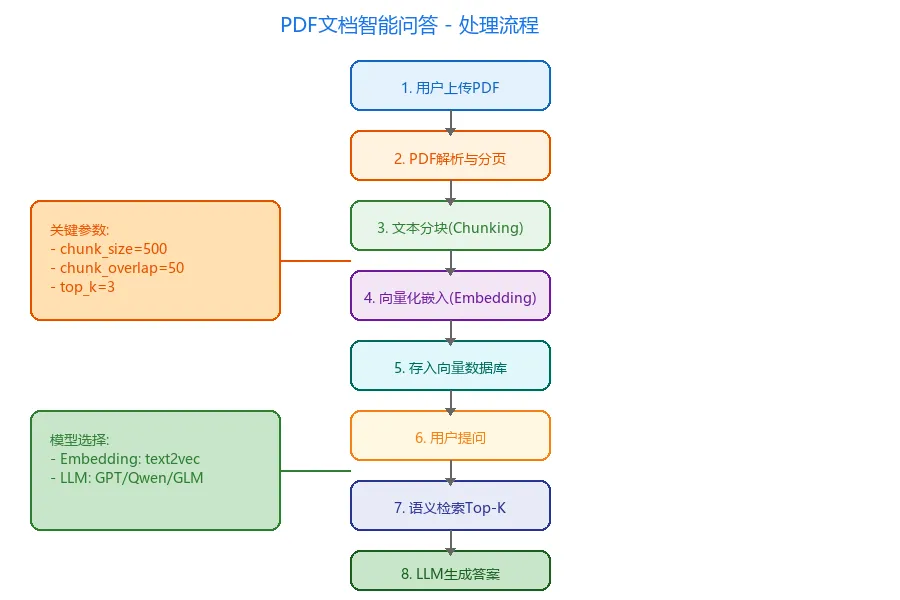
3.1 安装依赖
pip install PyPDF2 faiss-cpu chromadb sentence-transformers openai langchain
3.2 核心实现代码
"""
PDF文档智能问答系统
功能:上传PDF文件,基于RAG实现智能问答
"""
import os
import io
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# ============ 配置 ============
API_KEY = "your-api-key" # 替换为你的API Key
API_BASE = "https://api.openai.com/v1" # 或国内代理地址
MODEL_NAME = "gpt-4o-mini" # LLM模型
EMBEDDING_MODEL = "text-embedding-3-small" # Embedding模型
CHUNK_SIZE = 500 # 每块文本大小
CHUNK_OVERLAP = 50 # 块间重叠字符数
TOP_K = 3 # 检索返回的文档块数
# ============ 第1步:PDF解析 ============
def extract_text_from_pdf(file_path):
"""从PDF文件中提取全部文本"""
reader = PdfReader(file_path)
full_text = ""
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text:
full_text += f"\n--- 第{i+1}页 ---\n{text}"
return full_text
def extract_text_from_pdf_bytes(pdf_bytes):
"""从PDF字节流中提取文本(适用于Web上传场景)"""
reader = PdfReader(io.BytesIO(pdf_bytes))
full_text = ""
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text:
full_text += f"\n--- 第{i+1}页 ---\n{text}"
return full_text
# ============ 第2步:文本分块 ============
def split_text(text, chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP):
"""将长文本按语义切分为小块"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", ".", " ", ""],
length_function=len,
)
chunks = splitter.split_text(text)
print(f"文本分为 {len(chunks)} 个块")
return chunks
# ============ 第3步:构建向量索引 ============
def build_vector_store(chunks):
"""将文本块向量化并存入FAISS索引"""
embeddings = OpenAIEmbeddings(
model=EMBEDDING_MODEL,
openai_api_key=API_KEY,
openai_api_base=API_BASE,
)
vector_store = FAISS.from_texts(chunks, embeddings)
return vector_store
# ============ 第4步:构建问答链 ============
def build_qa_chain(vector_store):
"""构建检索增强问答链"""
llm = ChatOpenAI(
model=MODEL_NAME,
openai_api_key=API_KEY,
openai_api_base=API_BASE,
temperature=0,
)
# 自定义Prompt模板
prompt_template = """基于以下文档内容回答用户的问题。
如果文档中没有相关信息,请明确告知用户"该文档中未找到相关信息"。
回答时请引用文档中的具体内容,并标注出处页码(如果有的话)。
参考文档:
{context}
用户问题:{question}
请用中文回答:"""
PROMPT = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"],
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 将检索到的所有片段拼接
retriever=vector_store.as_retriever(search_kwargs={"k": TOP_K}),
chain_type_kwargs={"prompt": PROMPT},
return_source_documents=True, # 返回引用来源
)
return qa_chain
# ============ 第5步:完整问答流程 ============
class PDFChatBot:
"""PDF智能问答机器人"""
def __init__(self, api_key, api_base=API_BASE):
self.api_key = api_key
self.api_base = api_base
self.vector_store = None
self.qa_chain = None
self.file_name = None
def load_pdf(self, file_path):
"""加载PDF文件并建立索引"""
self.file_name = os.path.basename(file_path)
print(f"📄 正在解析: {self.file_name}")
# 提取文本
text = extract_text_from_pdf(file_path)
print(f"📝 提取文本长度: {len(text)} 字符")
# 文本分块
chunks = split_text(text)
if not chunks:
print("❌ 未能提取到有效文本")
return False
# 构建向量索引
print("🔍 正在构建向量索引...")
self.vector_store = build_vector_store(chunks)
# 构建问答链
self.qa_chain = build_qa_chain(self.vector_store)
print("✅ 索引构建完成,可以开始提问了!")
return True
def ask(self, question):
"""向文档提问"""
if not self.qa_chain:
return "请先加载PDF文件"
result = self.qa_chain({"query": question})
answer = result.get("result", "")
sources = result.get("source_documents", [])
# 格式化输出
output = f"**回答:**\n{answer}\n\n"
if sources:
output += f"**引用来源(共{len(sources)}个相关片段):**\n"
for i, doc in enumerate(sources):
snippet = doc.page_content[:100].replace("\n", " ")
output += f" {i+1}. {snippet}...\n"
return output
# ============ 使用示例 ============
if __name__ == "__main__":
# 初始化机器人
bot = PDFChatBot(api_key=API_KEY, api_base=API_BASE)
# 加载PDF
bot.load_pdf("example.pdf")
# 开始对话
questions = [
"这份文档的主要内容是什么?",
"文档中关于XXX的具体描述是什么?",
"帮我总结文档的核心结论。",
]
for q in questions:
print(f"\n{'='*50}")
print(f"👤 提问: {q}")
print(f"🤖 回答: {bot.ask(q)}")
3.3 进阶:使用ChromaDB持久化
"""使用ChromaDB实现向量索引的持久化存储"""
import chromadb
from chromadb.config import Settings
def build_persistent_store(chunks, persist_dir="./chroma_db"):
"""构建持久化向量存储"""
# 初始化ChromaDB客户端
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=persist_dir,
))
# 创建集合
collection = client.get_or_create_collection(
name="pdf_documents",
metadata={"hnsw:space": "cosine"},
)
# 分批存入(ChromaDB有批量限制)
batch_size = 500
for i in range(0, len(chunks), batch_size):
batch = chunks[i:i + batch_size]
ids = [f"chunk_{i+j}" for j in range(len(batch))]
collection.add(
documents=batch,
ids=ids,
)
# 持久化到磁盘
client.persist()
print(f"已存储 {len(chunks)} 个文档块到 {persist_dir}")
return collection
def search_similar(collection, query_text, embeddings_fn, top_k=3):
"""语义检索"""
query_embedding = embeddings_fn([query_text])[0]
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
)
return results
3.4 进阶:流式输出
"""实现流式输出,提升用户体验"""
def stream_qa(qa_chain, question):
"""流式问答"""
docs = qa_chain.retriever.get_relevant_documents(question)
context = "\n\n".join([d.page_content for d in docs])
prompt = f"""基于以下文档内容回答问题:
{context}
问题:{question}
回答:"""
for chunk in qa_chain.llm.stream(prompt):
print(chunk.content, end="", flush=True)
print()
四、关键技术详解
4.1 文本分块策略
分块是RAG系统中最关键的参数调优点之一:
| 策略 | 适用场景 | 优缺点 |
|---|---|---|
| 固定长度分块 | 通用场景 | 简单但可能切断语义 |
| 递归分块 | 多种文档类型 | 按分隔符递归切分,保留语义 |
| 语义分块 | 长文档 | 基于Embedding相似度切分,效果最好 |
| 父子分块 | 需要精确引用 | 检索小块,返回大块上下文 |
调参建议:
-
chunk_size=500, overlap=50→ 适合一般文档 -
chunk_size=1000, overlap=100→ 适合技术文档(代码块较多) -
chunk_size=300, overlap=30→ 适合FAQ/合同类精确查询
4.2 Embedding模型选择
| 模型 | 维度 | 中文支持 | 推荐场景 |
|---|---|---|---|
| text-embedding-3-small | 1536 | 支持 | 通用场景,性价比高 |
| text-embedding-3-large | 3072 | 支持 | 高精度需求 |
| bge-large-zh | 1024 | 优秀 | 纯中文场景,开源首选 |
| text2vec-large-chinese | 1024 | 优秀 | 中文长文本 |
4.3 检索优化技巧
# 技巧1:混合检索(关键词 + 语义)
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 3
faiss_retriever = vector_store.as_retriever(search_kwargs={"k": 3})
ensemble = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.4, 0.6], # BM25权重0.4, 语义权重0.6
)
# 技巧2:重排序(Reranker)
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
reranker = CrossEncoderReranker(top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=vector_store.as_retriever(),
)
五、常见问题与解决方案
Q1:PDF提取出的文本是空的?
→ 有些PDF是扫描件(图片型PDF),需要先用OCR工具(如Tesseract、PaddleOCR)进行文字识别。
Q2:回答不够准确?
→ 调大top_k参数获取更多上下文;优化分块策略确保语义完整性;尝试使用混合检索。
Q3:处理大文档很慢?
→ 使用ChromaDB的持久化功能,只需索引一次;对Embedding做批量处理减少API调用。
Q4:如何支持多文档?
→ 给每个文档块添加metadata(如文件名、页码),检索时可以按文档来源过滤。
六、今日小结
今天我们用不到200行代码构建了一个完整的PDF智能问答系统,核心知识点:
-
✅ PDF文本提取(PyPDF2) -
✅ 文本分块策略(RecursiveCharacterTextSplitter) -
✅ 向量化与存储(FAISS / ChromaDB) -
✅ RAG检索增强生成(RetrievalQA Chain) -
✅ 自定义Prompt模板优化回答质量
明天预告: 第3期——关键词提取与文本摘要,学习如何用AI快速提取文章的核心信息和自动生成摘要。
关注公众号「AI实践日记」,每天一个可运行的AI实战案例。
完整代码可在公众号后台回复「AI案例」获取。