 夜雨聆风
夜雨聆风





百度发布文档解析新王者:0.9B参数,96.33%得分新SOTA
文档解析,能把一张张文档图片变成机器能读懂的结构化内容,包括文字、表格、公式、图表、印章,甚至阅读顺序和版面布局。
这件事做得好不好,直接决定了下游检索、推理、RAG(检索增强生成)系统能不能拿到干净靠谱的输入。
百度PaddlePaddle团队发布并开源了PaddleOCR-VL-1.6。

一个0.9B参数的紧凑模型,在OmniDocBench v1.6上拿下96.33%的总分,登顶榜首。
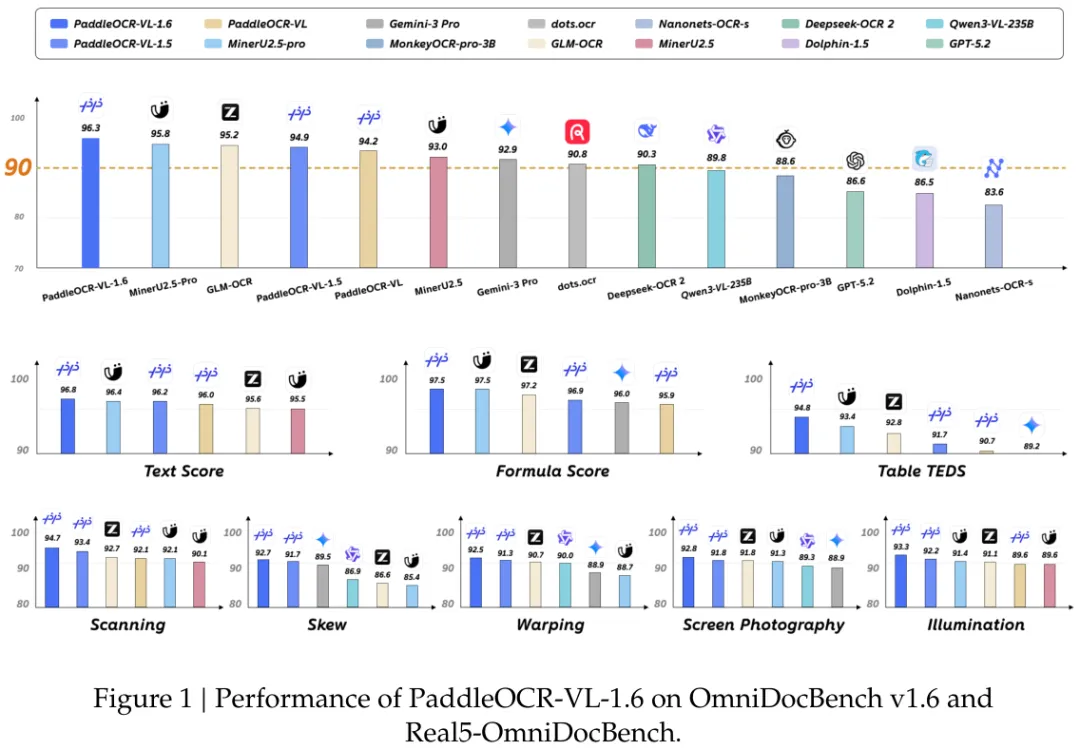
PaddleOCR-VL-1.6精准找到上一代模型的薄弱环节,对症下药补充了数据,然后用三阶段递进式训练(CPT-SFT-RL),把数据的价值榨干,从而获得了SOTA性能。 各类场景下,都比上一代模型有明显提升。例如:
表格识别

图表识别

公式识别

古籍识别

生僻字识别

印章识别

扭曲图像识别

弱点在哪里
PaddleOCR-VL-1.5已经是一个很强的基线模型,0.9B参数,在OmniDocBench v1.5上得分94.93%。
在基线的基础上,剩下的错误呈现出一个有趣的特征:它们不再均匀散布在各处,而是集中出现在模型特定的薄弱区域。
继续无差别地堆数据,收效甚微,因为大部分训练预算花在了模型已经搞定的部分上,对薄弱区域的改善有限。
PaddleOCR-VL-1.6的做法是,从上一代模型出发,系统性地诊断三类薄弱区域。
第一类叫Boundary-Fragile Regions(边界脆弱区域)。
有些样本,稍微做点不影响语义的视觉扰动,比如像素微移、JPEG压缩、轻微模糊,模型输出就大幅变动。甚至不同训练后期的checkpoint,对同一个样本的预测都不一致。
模型在这些区域的决策边界很不稳定,还没学到靠谱的映射。
第二类叫Coverage-Sparse Regions(覆盖稀疏区域)。
有些样本明明在训练集里出现过类似模式,模型就是预测不对。原因是周围的数据分布太稀疏,长尾文档模式被主流分布吞掉了。
基于这些覆盖稀疏区域,团队从内部大规模文档池中定向检索补充了长尾数据。
第三类叫Unreliable-Supervision Regions(不可靠监督区域)。
模型有时会稳定地输出高置信度的错误结果,问题不在输入难,在标签本身就错了。团队引入三个外部专家模型(Qianfan-OCR、GLM-OCR、MinerU2.5-Pro)对同一训练样本做独立预测,与原始标签交叉验证。
找出了薄弱区域,团队给这些区域精准补充了标注数据。
三步走练法
数据准备好了,PaddleOCR-VL-1.6 采用了 “模型驱动的数据引擎 + 渐进式后训练策略” 的整体优化框架。
先从PaddleOCR-VL-1.5出发定位弱点,再围绕这些弱点构建高价值数据,最后通过继续预训练、监督微调、强化学习的渐进式后训练流程,将新增数据的价值稳定注入模型。
在不改变 0.9B 高效架构的前提下,模型实现了更强的文档解析性能、鲁棒性和泛化能力。
PaddleOCR-VL-1.6整个系统由两个模型组成:PP-DocLayout V3做版面分析,PaddleOCR-VL-1.6-0.9B做视觉语言理解。
架构沿用PaddleOCR-VL-1.5的设计,包含Native Resolution Visual Encoder(原生分辨率视觉编码器)、Adaptive MLP Connector(自适应MLP连接器)和ERNIE-4.5-0.3B语言模型。
没有改架构,没有加大参数,提升全部来自更聪明的数据策略和更精细的训练流程。
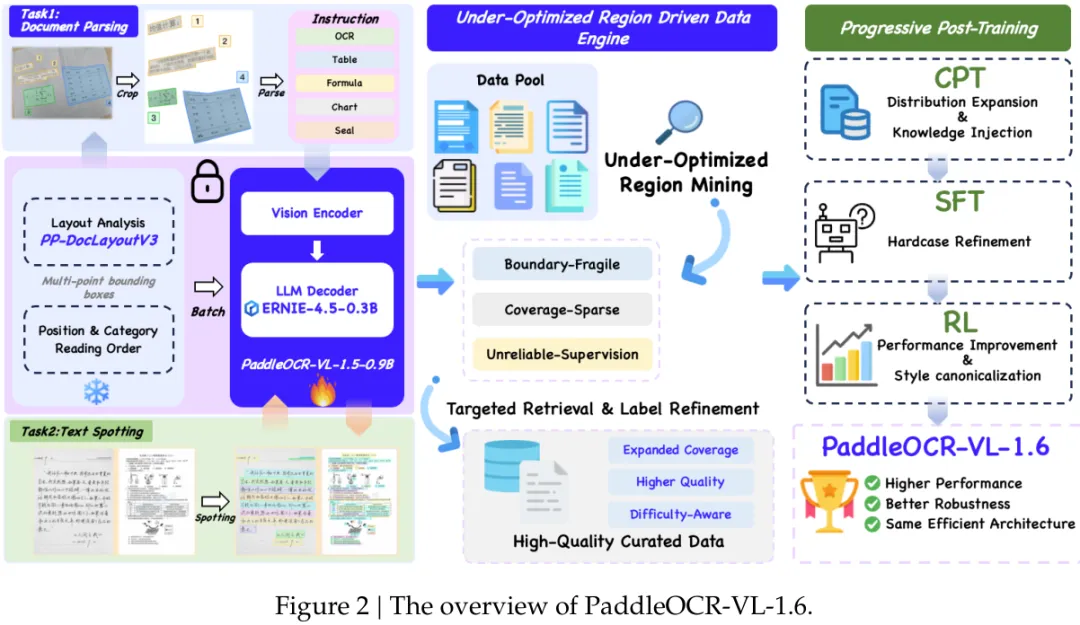
第一阶段是CPT(Continued Pre-Training,持续预训练),1680万样本。这一步的目标是广撒网,把数据引擎新挖出来的长尾样本(古籍、罕见字符、工业表格等)和修正后的标注全部灌进去,让模型先覆盖新的分布。
第二阶段是SFT(Supervised Fine-Tuning,监督微调),730万样本。这一步聚焦难题精练,数据来源有三个:用UACS(Uncertainty-Aware Cluster Sampling,不确定性感知聚类采样)策略从CPT语料中挖出的难样本,三个专家达不成共识的困难样本,以及被Unreliable-Supervision挖掘修正了标签的样本。高质量、高难度,专门打磨模型在脆弱区域的表现。
第三阶段是RL(Reinforcement Learning,强化学习),用GRPO做强化训练,49K样本。这一步的难点在于,0.9B的小模型对RL数据质量非常敏感,随意选样本容易顾此失彼,在某个子集上提分的同时整体性能反而下降。
训练效果高度依赖每个输入能否产生有信息量的奖励差异。对于语言模型只有0.3B的紧凑模型,对噪声数据、过难数据、过易数据、奖励平坦数据都格外敏感。
PaddleOCR-VL-1.6 设计了面向GRPO的高潜力样本挖掘策略,用监督微调后的模型对候选样本进行多次轨迹采样,并从提升潜力、生成不确定性和奖励方差三个维度筛选真正“可学习、有区分度、有收益空间”的样本。
针对文档解析任务输出形式复杂、二值奖励过稀疏的问题,PaddleOCR-VL-1.6 进一步精心设计可验证的奖励函数,将输出映射到任务相关的规范表示,并通过合法性、结构修正约束、真实得分三个维度提供稳定、可验证、任务对齐的奖励信号。
0.9B登顶榜单
OmniDocBench v1.6是当前文档解析最权威的评测基准之一,新增了MGAM(Multi-Granularity Adaptive Matching,多粒度自适应匹配)以减少匹配偏差,还增加了296页的Hard子集,覆盖复杂嵌套表格、密集公式布局和非常规文档结构。
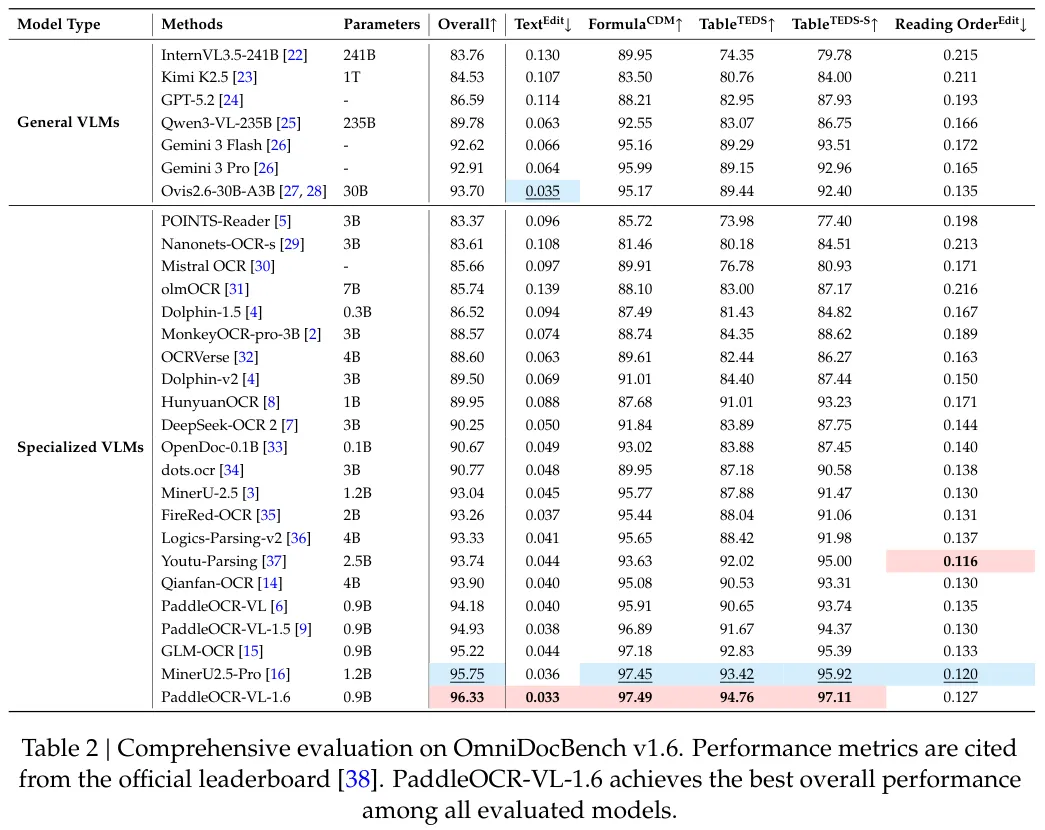
PaddleOCR-VL-1.6总得分96.33%,排名第一。和上一代PaddleOCR-VL-1.5的94.93%相比,提升了1.4个百分点。文本编辑距离降到0.033,公式CDM得分97.49%,表格TEDS得分94.76%,表格结构TEDS得分97.11%,阅读顺序得分0.127。
各项子任务都刷新了纪录。
更值得关注的是Real5-OmniDocBench上的表现。这个评测模拟真实场景,包括扫描、弯折、屏幕拍照、光照变化和倾斜五种情况,全部用手机实拍采集。
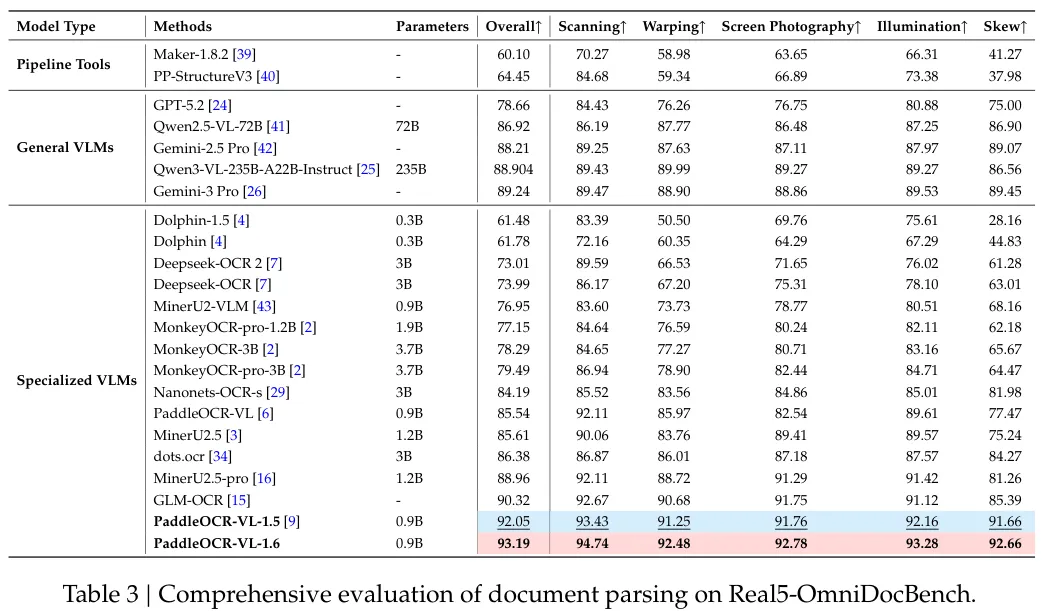
PaddleOCR-VL-1.6总得分93.19%,比上一代提升1.14个百分点,排名榜首。0.9B的模型,跑赢了Qwen3-VL-235B和Gemini 3 Pro这些百倍参数的通用大模型。
子能力方面同样全面领先。
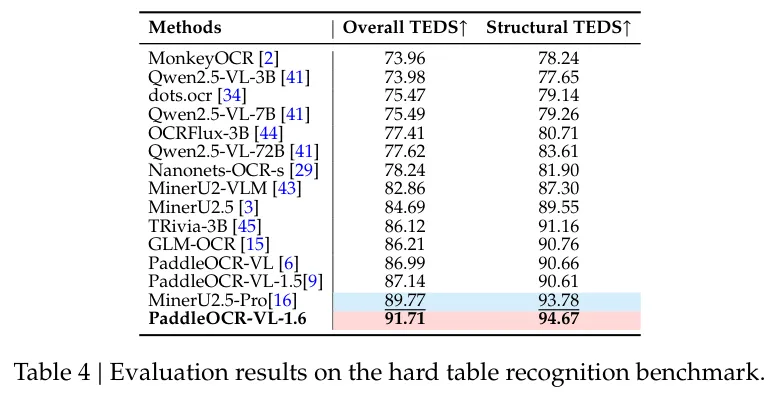
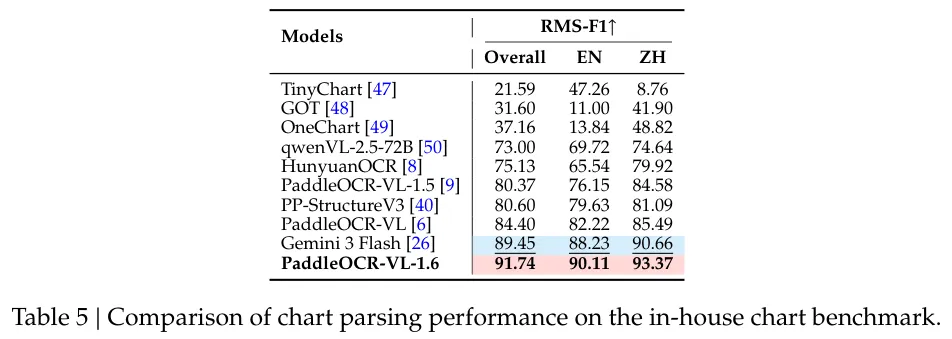
困难表格识别(1258个样本,覆盖20种表格类型),PaddleOCR-VL-1.6的TEDS得分91.71,结构TEDS得分94.67,比MinerU2.5-Pro高出近2个百分点。图表解析(1801个样本,11种图表类型),RMS-F1总分91.74,中文图表93.37,比上一代提升11个百分点以上。文本定位(9个维度),总分87.47,在古文书、日文、手写中文等维度均有提升。印章识别,NED(Normalized Edit Distance,归一化编辑距离)低至0.119,远超Qwen3-VL-235B的0.382。
0.9B参数,跑赢了241B的InternVL3.5、1T的KimiK2.5、235B的Qwen3-VL,甚至超过了GPT-5.2。
对行业来说,PaddleOCR-VL-1.6以更低的部署成本,可以在端侧和边缘设备上运行,适合文档数字化、票据识别、档案管理等实际场景。
这套”诊断薄弱区域、精准补数据、递进训练”的方法论,提供了一条在紧凑模型上持续提升性能的可行路径。
参考资料:
https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.6
https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL-1.6
https://github.com/PaddlePaddle/PaddleOCR
https://arxiv.org/pdf/2606.03264



