 夜雨聆风
夜雨聆风





AI Native Infra:从 Unix 管道符到 Agent 时代的软件工程
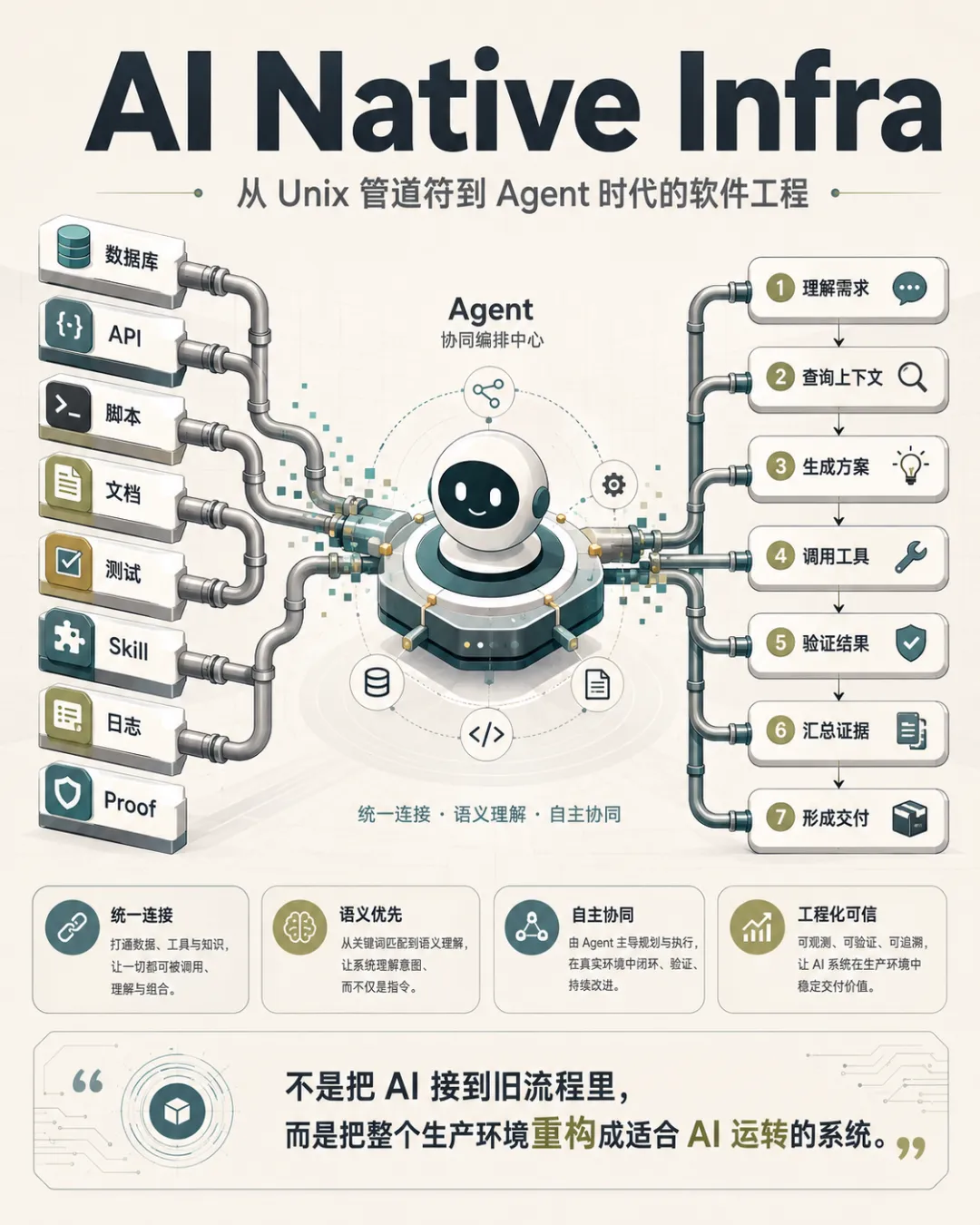
一、核心观点
AI Native 不是简单地把 AI 接入现有系统,也不是给旧流程加一个 Copilot。
真正的 AI Native,是把产品、工具、接口、数据、流程和组织方式,重新设计成适合 Agent 运转的系统。
过去的软件系统主要服务人。未来的软件系统不仅服务人,还要服务 Agent。
这会带来一个底层变化:
下一代软件工程的核心,不只是“用 AI 写代码”,而是“构造一个让 AI 能稳定工作、持续组合、自动验证、不断沉淀的生产环境”。
AI 原生基建的竞争,也不会只是单点工具竞争,而会变成:
-
可组合基建能力;
-
Agent 友好接口能力;
-
流程重构能力;
-
自动验证和证据闭环能力;
-
问题定义与创造力。
二、从《塞尔达》理解可组合系统
《塞尔达》的好玩,不只是因为画面、剧情或单个道具,而是因为它构建了一套可组合系统。
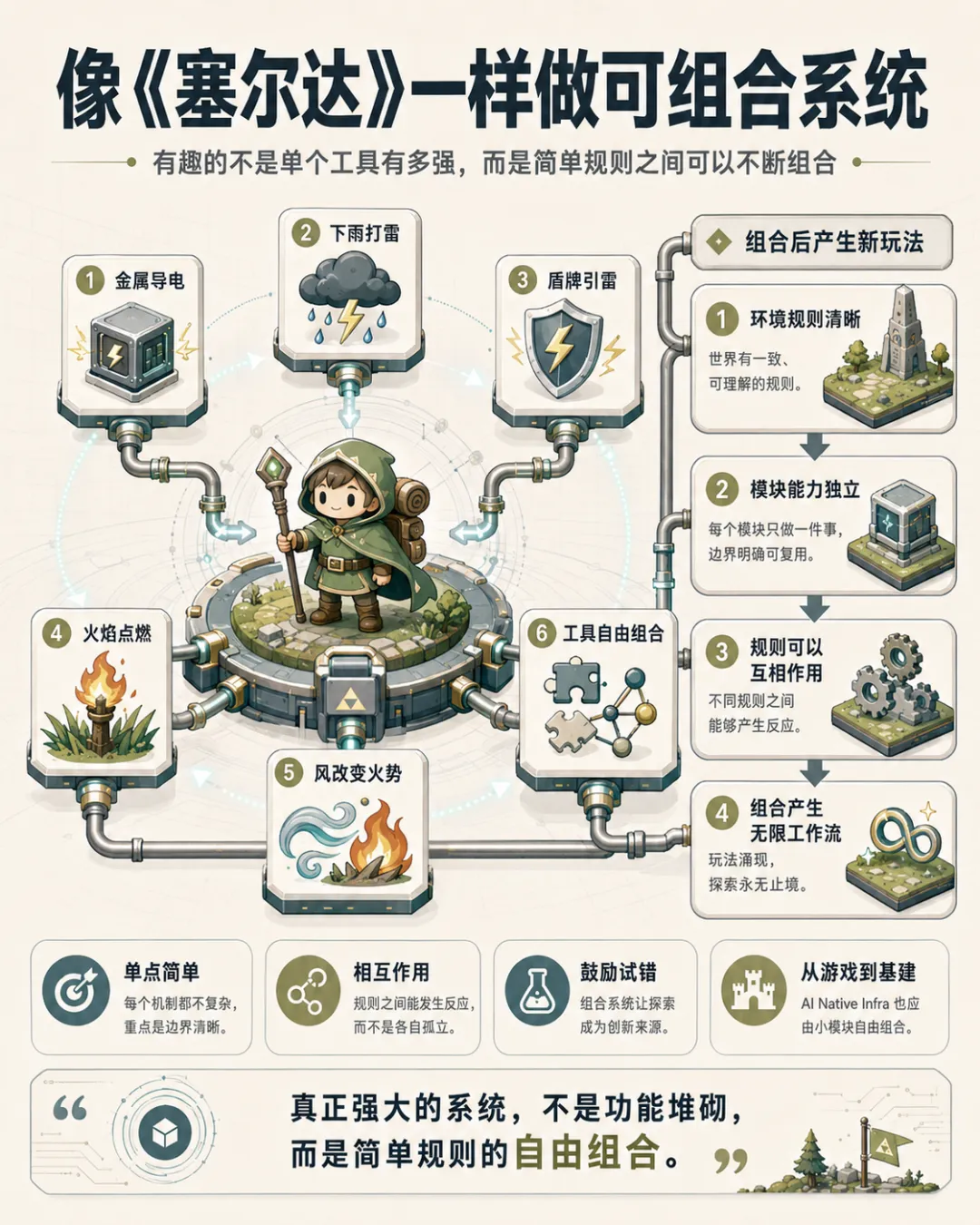
系统里的每个规则都很简单:
-
金属可以导电;
-
下雨容易打雷;
-
铁盾会引雷;
-
火可以点燃草地;
-
风可以改变火势;
-
工具之间可以互相组合。
每个工具本身都不复杂,但组合之后会产生大量玩法。
这对 AI Native Infra 很有启发。
好的 AI 原生基建,不应该是一个巨大、封闭、不可拆解的产品,而应该是一组边界清楚、能力单一、可以被自由组合的小模块。
例如:
-
数据库查询能力;
-
本地脚本执行能力;
-
API 调用能力;
-
RPC 调试能力;
-
日志检索能力;
-
文档检索能力;
-
测试执行能力;
-
Mock 环境;
-
数据回收机制;
-
Agent Skill;
-
自动化流程;
-
Proof Package 生成工具。
这些能力单独看都不一定复杂,但只要它们可以被 Agent 理解、调用、组合和验证,就会形成新的生产力。
一套组合方式,就是一个工作流。一套稳定工作流,就是一个内部产品。一批可复用的内部产品,就构成了 AI Native Infra。
所以,AI 原生基建的关键不是“大而全”,而是“小而清晰、可组合、可验证”。
三、从 Unix 管道符理解 AI Native Infra
AI Native Infra 的思想,也可以和 Unix 设计哲学联系起来看。
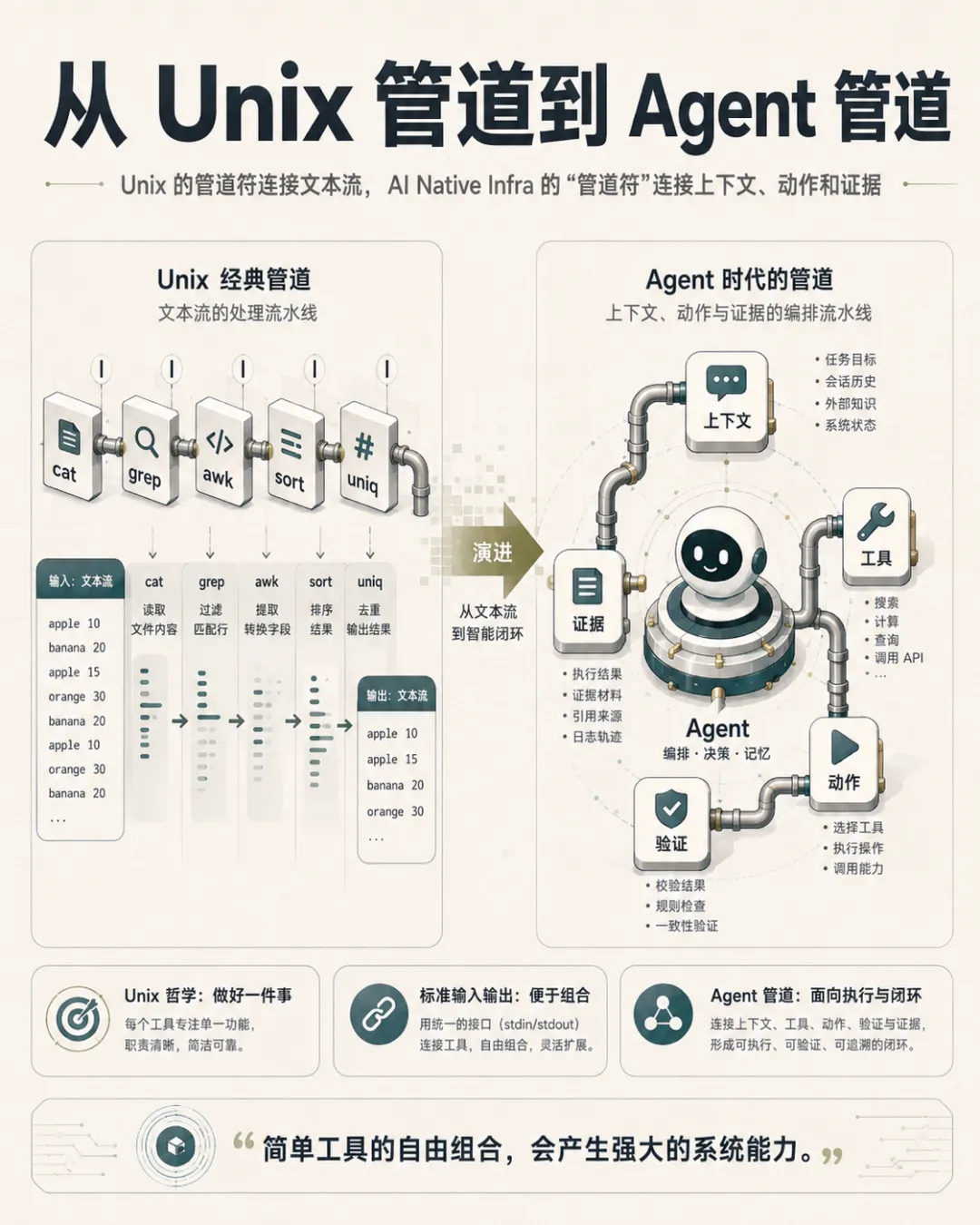
Unix 有一个经典原则:
做一件事,并把它做好。
一个 Unix 工具通常很小:
-
cat负责读取内容; -
grep负责过滤文本; -
sort负责排序; -
uniq负责去重; -
awk负责结构化处理; -
wc负责统计。
每个工具本身都不复杂,但它们可以通过管道符 | 串联起来:
cat access.log | grep "ERROR" | awk '{print $1}' | sort | uniq -c | sort -nr这条命令不是一个“大系统”,而是多个小工具组合出来的临时工作流。Unix 的强大,不在于每个命令都无所不能,而在于:
-
每个工具边界清楚;
-
每个工具输入输出稳定;
-
工具之间可以自由组合;
-
复杂能力可以由简单工具拼装出来;
-
用户可以按自己的意图临时创造新流程。
AI Native Infra 也应该遵循类似原则。
只不过,Unix 管道连接的是文本流,而 AI Native Infra 连接的是:
-
上下文流;
-
动作流;
-
数据流;
-
决策流;
-
证据流。
Unix 时代的组合方式是:
command A | command B | command CAgent 时代的组合方式会变成:理解需求 → 查询上下文 → 生成方案 → 调用工具 → 验证结果 → 汇总证据 → 形成交付可以把 AI Native Infra 理解为一种面向 Agent 的“新管道系统”。
过去,我们为人设计命令行工具,让人通过管道组合能力。未来,我们要为 Agent 设计可调用工具,让 Agent 通过上下文、约束、动作和证据组合能力。
一句话概括:
Unix 的管道符连接文本流,AI Native Infra 的“管道符”连接上下文、动作和证据。
四、AI 原生 API:从“返回结果”到“引导下一步”
传统 API 主要面向人。
接口失败时,通常返回一个错误码、一段错误信息,最多再配合一份文档。至于下一步怎么处理,需要人自己判断。
人可以靠经验补全上下文:
-
这个错误大概是什么原因;
-
应该查哪个字段;
-
应该换哪个参数;
-
应该调用哪个接口;
-
应该找谁确认。
但 Agent 不适合这种方式。
Agent 没有稳定的业务经验,也没有足够可靠的隐性上下文。一旦错误信息不清晰,它就容易乱猜、乱试、跑偏。
所以,AI 原生 API 的设计重点应该变化。
一个 Agent 友好的 API,不应该只返回:
{ "code": 400, "message": "参数错误"}而应该返回类似:
{"success": false,"reason": "platform 参数不合法","constraint": "platform 只能是 1、2、3","suggestion": "请先调用 /platform/list 获取合法平台值","next_action": {"tool": "http_get","endpoint": "/platform/list"}}
也就是说,API 的返回结果本身要能引导 Agent 的下一步动作。
未来好的接口返回,不只是 data 和 error,而应该包含:
-
failure reason:为什么失败;
-
constraint:违反了什么约束;
-
suggestion:建议如何修复;
-
next action:下一步可以调用什么;
-
evidence:当前判断依据是什么;
-
recoverability:这个错误是否可自动恢复;
-
risk level:继续执行是否存在风险。
这会改变 API 设计哲学。
过去 API 是“人读文档后调用”。未来 API 是“Agent 在运行过程中自解释、自修复、自推进”。
五、AI Native Infra 的本质:给机器铺路
人类做开发时,可以靠经验补洞。
文档不完整,可以问人。报错不清楚,可以猜。流程不顺,可以绕。环境有问题,可以手工修。数据缺失,可以临时查。
但 Agent 不适合长期依赖这些隐性能力。
Agent 需要的是:
-
明确的路径;
-
清晰的边界;
-
可调用的工具;
-
可读取的上下文;
-
可解释的错误;
-
可验证的结果;
-
可恢复的失败;
-
可沉淀的证据。
所以,AI Native Infra 的建设,本质上是在给机器铺路。
要让 Agent 稳定工作,就要尽量减少“断档”:
-
文档不能只写给人看,也要能被 Agent 读取;
-
错误不能只提示失败,还要提示下一步;
-
工具不能只提供能力,还要暴露约束;
-
流程不能只靠口头传递,还要沉淀成可执行规范;
-
验证不能只靠人主观判断,还要形成证据链;
-
经验不能只停留在人脑里,还要转化为规则、案例、Skill 和工具。
AI 原生基建最重要的标准不是“功能有多强”,而是:
Agent 是否能顺滑地完成下一步。
失败并不可怕。真正可怕的是失败之后没有路径、没有解释、没有恢复方案。
AI Native Infra 要解决的,就是让 Agent 在失败后也能顺滑接上。
六、AI 的“手脚”就是一个个小基建
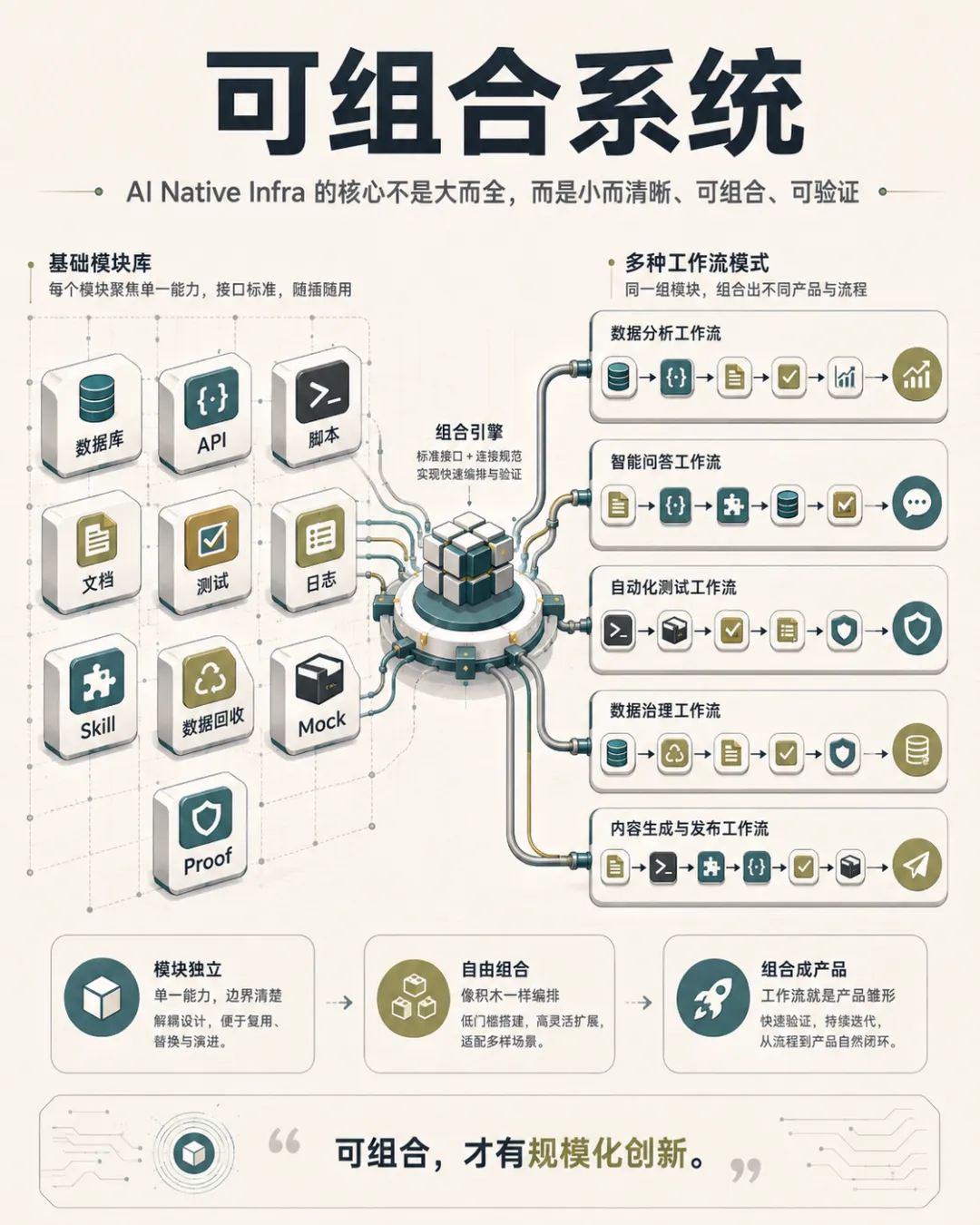
大模型更像大脑,但它需要手和脚。
这些手脚,就是各种可调用的小基建。
例如在研发场景中,Agent 需要:
-
读取代码;
-
理解接口;
-
查询文档;
-
调用测试;
-
检索日志;
-
查询数据库;
-
构造请求;
-
执行脚本;
-
回收数据;
-
验证结果;
-
总结证据;
-
生成变更说明。
如果这些能力都只能由人手工完成,那么 Agent 只是一个“建议生成器”。
如果这些能力可以被工具化、接口化、文档化、Skill 化,并且能被 Agent 稳定调用,那么 Agent 才真正拥有了执行能力。
因此,AI Native Infra 不是一个单点工具,而是一组可组合、可调用、可验证的小能力网络。
这些小基建可以有不同形态:
-
一个 API;
-
一个 CLI;
-
一个脚本;
-
一份结构化文档;
-
一个测试用例集合;
-
一个数据构造工具;
-
一个日志查询工具;
-
一个 Agent Skill;
-
一个自动化工作流;
-
一个 Proof Package 模板。
单个能力不一定复杂,但关键是要满足四个要求:
-
Agent 能看懂;
-
Agent 能调用;
-
Agent 能知道失败原因;
-
Agent 能拿到验证结果。
七、下一代软件工程:从“写代码”到“构造系统”
过去软件工程的核心能力,是把需求翻译成代码。
但在 AI 编程时代,写代码本身的成本会快速下降。
真正稀缺的能力会转向:
-
能不能提出值得解决的问题;
-
能不能把模糊问题拆成 AI 可执行的结构;
-
能不能定义清晰的约束;
-
能不能设计可验证的验收标准;
-
能不能为 Agent 提供足够上下文;
-
能不能构建工具链支持 Agent 执行;
-
能不能把一次成功沉淀成可复用能力。
这意味着软件工程师的角色会发生变化。
过去更像“代码实现者”。未来更像“系统设计者 + Agent 指挥者 + 验证链建设者”。
代码能力仍然重要,但不再是唯一核心。
更重要的是构建一个让 AI 能持续产出的工程环境。
在这个环境里,需求不是一句话,而是结构化意图。开发不是直接写代码,而是先明确约束与验收。测试不是最后补一补,而是交付证据的一部分。文档不是事后总结,而是 Agent 的运行上下文。工具不是给人点一点,而是给 Agent 调度使用。流程不是靠人记住,而是沉淀成可执行路径。
这就是下一代软件工程的变化。
八、AI 提效不是自动发生的,需要重构生产环境
AI 提效很像电气化早期的工厂改造。
早期工厂虽然装上了电机,但车间布局、人员动线、作业流程仍然是人力时代的结构。所以电力并没有立刻带来巨大效率提升。
真正的效率爆发,发生在工厂重新围绕机器能力设计之后。
AI 也是一样。
如果企业只是把 AI 插入旧流程:
-
人还是按旧方式提需求;
-
文档还是散落在各处;
-
接口还是只给人读;
-
测试还是靠人工经验;
-
数据还是无法安全调用;
-
审核还是没有证据链;
-
失败还是需要人兜底;
-
经验还是无法沉淀复用。
那么结果很可能不是提效,而是多了一套流程。
人要写需求给 AI。AI 要生成结果给人。人要再检查 AI。AI 出错后人还要返工。最后旧流程没少,新流程又加了一层。
真正的 AI Native,不是“人类流程 + AI 工具”,而是把需求、开发、测试、发布、审计、运维、知识沉淀,重新组织成适合 Agent 运转的生产系统。
这才是 AI 提效真正发生的地方。
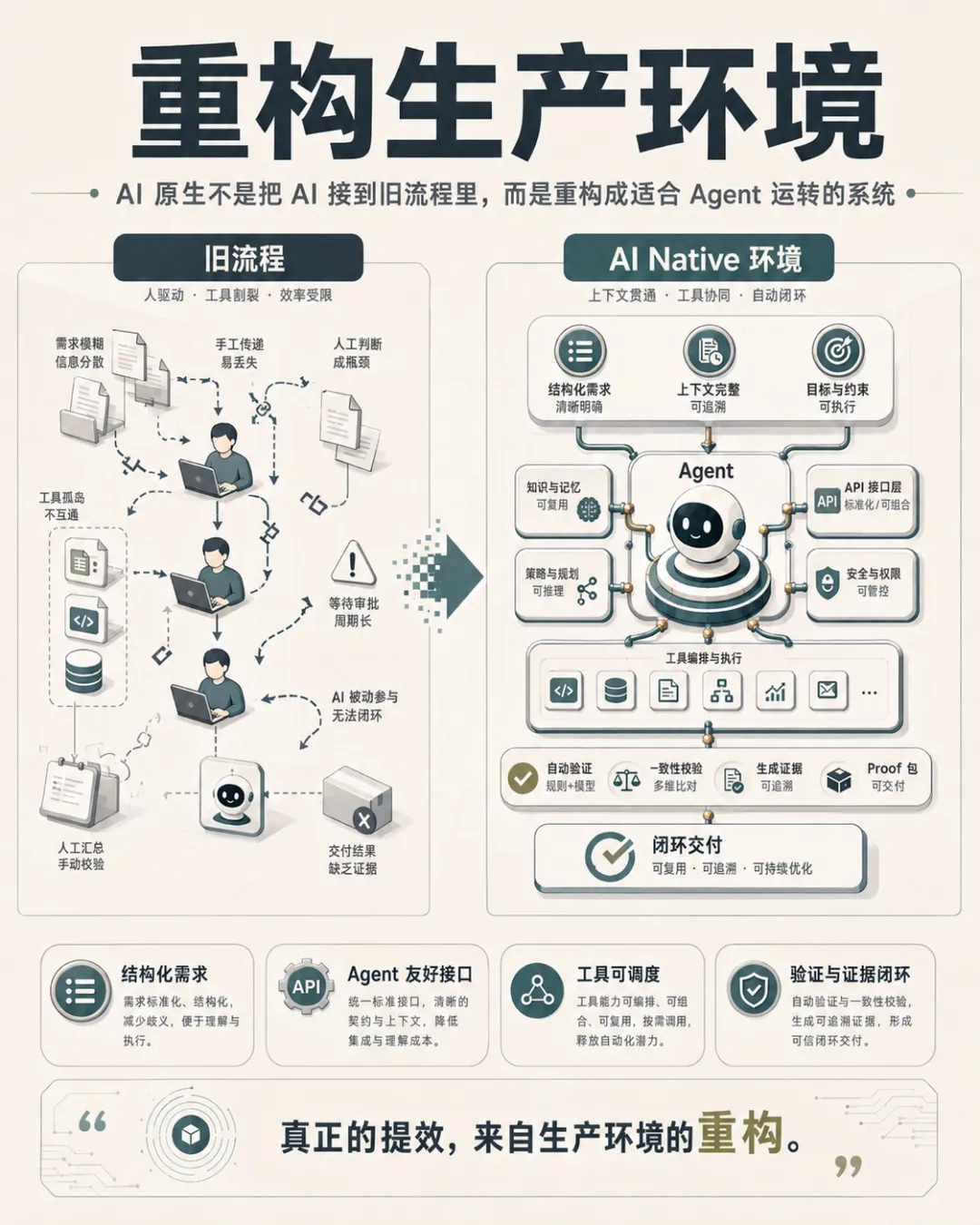
九、面向 Agent 的工程系统应该长什么样
一个面向 Agent 的工程系统,至少应该具备几类能力。
1. 结构化需求能力
Agent 不适合直接处理大量模糊表达。
需求应该尽量结构化,包括:
-
目标;
-
非目标;
-
约束;
-
验收标准;
-
未知点;
-
上下文;
-
下一步检查点。
这不是为了增加流程,而是为了减少 Agent 的误解和跑偏。
2. 上下文供给能力
Agent 的产出质量高度依赖上下文。
所以项目应该沉淀:
-
项目结构说明;
-
关键模块说明;
-
接口说明;
-
本地启动方式;
-
测试方式;
-
常见错误;
-
架构约束;
-
不允许破坏的兼容性要求。
这些材料不是传统意义上的“文档负担”,而是 Agent 的运行燃料。
3. 工具调用能力
Agent 要真正完成任务,必须有工具可用。
例如:
-
查数据库;
-
查日志;
-
调接口;
-
跑测试;
-
构造数据;
-
模拟 MQ;
-
生成 Mock;
-
执行回滚;
-
生成报告。
没有工具,Agent 只能停留在“说”。有了工具,Agent 才能开始“做”。
4. 失败恢复能力
工具和接口失败时,不能只告诉 Agent “失败了”。
应该告诉它:
-
为什么失败;
-
是否可重试;
-
可以换什么参数;
-
应该查什么上下文;
-
下一步可以调用什么;
-
是否需要人工介入。
失败恢复能力,是 Agent 友好系统的关键指标。
5. 验证与证据能力
AI 生成内容的最大问题,不是它不会写,而是它可能写得很像对的。
因此,下一代工程交付必须重视证据链。
每次交付都应该能回答:
-
改了什么;
-
为什么这么改;
-
验证了什么;
-
验证结果是什么;
-
哪些风险仍然存在;
-
哪些动作因为基建不足无法验证;
-
是否需要人工补充判断。
这就是 Proof Package 的价值。
它不是额外文档,而是 AI 时代的交付凭证。
十、下一代软件工程的几个预测
预测一:文档会从“说明材料”变成“运行材料”
未来的文档不只是给人读,而是给 Agent 作为上下文、约束和决策依据。
好的文档会直接影响 Agent 的产出质量。
文档的价值不再只是“知识沉淀”,而是“运行时上下文”。
预测二:API 会从“调用接口”变成“协作接口”
接口不只是返回数据,还要返回约束、失败原因、修复建议和下一步路径。
API 会越来越像 Agent 的行动导航。
预测三:测试会从“质量保障环节”变成“交付证据”
AI 生成的代码能不能上线,不应该只看代码本身,而要看它提供了什么验证材料。
测试结果、日志、截图、数据校验、回归记录,都应该成为证据包的一部分。
预测四:工具会从“人用工具”变成“Agent 可调度能力”
过去工具追求界面好用。
未来工具还要追求:
-
Agent 可理解;
-
Agent 可调用;
-
Agent 可组合;
-
Agent 可验证;
-
Agent 可恢复。
预测五:组织竞争会从“人力规模”转向“系统放大能力”
过去组织效率依赖人数、经验和流程管理。
未来组织效率更依赖系统放大能力:
-
一个人能调度多少 Agent;
-
一个 Agent 能调用多少工具;
-
一次交付能沉淀多少复用能力;
-
一个团队能否把经验转化为机器可用的基建。
预测六:创造力会比代码能力更稀缺
当代码生成越来越便宜,真正稀缺的是:
-
能不能发现值得解决的问题;
-
能不能提出让自己兴奋的方向;
-
能不能把问题拆成 AI 可执行的系统;
-
能不能把一次灵感变成可复用的工作流。
未来不是没有代码能力要求,而是代码能力会被放到更大的系统设计能力之下。
十一、对团队的启发
如果要在团队内部推进 AI Native Infra,不建议一开始就追求大而全的平台。
更现实的路径是从小基建开始:
-
把常用查询工具化;
-
把接口调试 CLI 化;
-
把项目上下文文档化;
-
把测试验证自动化;
-
把错误信息结构化;
-
把经验沉淀成 Skill;
-
把交付结果证据包化。
每做一个小基建,都要问几个问题:
-
Agent 能不能看懂它?
-
Agent 能不能调用它?
-
调用失败时,Agent 知不知道下一步?
-
调用成功后,Agent 能不能拿到可用证据?
-
这个能力能不能和其他能力组合?
如果答案是肯定的,这个小基建就有 AI Native 价值。
十二、最终结论
AI Native Infra 不是把 AI 接到旧流程里,而是把整个生产环境重构成适合 AI 运转的系统。
它不是一个超级平台,而是一组可组合的小基建。它不是一个智能入口,而是一套 Agent 可理解、可调用、可验证、可恢复的能力网络。它不是简单提效工具,而是下一代软件工程的基础设施。
Unix 证明了:
简单工具的自由组合,可以产生极强的系统能力。
AI Native Infra 会延续这个规律:
Agent 友好的小基建,通过上下文、动作和证据连接起来,会组合出下一代软件生产系统。
一句话总结:
Unix 把小工具连接成工作流,AI Native Infra 把小基建连接成 Agent 工作流。
下一代软件工程,不是人被 AI 替代,而是人开始设计适合 AI 工作的工程世界。