夜雨聆风
夜雨聆风





RAG知识库中——文档预处理效果不好的原因与解决办法
“文档加载和清洗,并不是说直接把文档读出来,简单过滤一下就行了,最重要的是要保证内容的完整性,以及文档结构。”
如果你做过智能问答等场景的业务,那么你肯定遇到过流程正确,但效果很差的问题;而很多人包括网上很多方案都在说要更换embedding模型,调整chunk策略,优化召回方式等。但事实上主要原因都集中在文档处理上,文档处理的不好,哪怕你把前面几个步骤都优化到极致,依然效果不好。
问题出在哪?
问题是你的数据源都没处理好,怎么可能期望它能有一个好结果。
做文档处理首先需要解决的就是文档加载读取的问题,在真实的业务场景中,文档来源和形式都很复杂,包括但不仅限于word,pdf,ppt,excel,txt,图片等多种不同类型的文档类型,而不同的文档类型需要使用不同的文档读取工具。

其次,有些文档是由多种不同模态的数据组成,如pdf/word文档中可以同时有文字,图片,表格等多种格式的数据;而为了召回的准确性,这些不同的内容格式需要进行不同的处理。
我们以pdf文档为例,pdf文档分为两种,一种是可读取,另一种是扫描件;其中可读取的pdf文件只需要使用pdf处理工具即可加载,然后处理其文件内容,而扫描件只能使用OCR等技术去识别文档的内容,因为扫描件本质上类似于图片,无法直接读取到图片里的内容,所以只能对内容进行识别。
但这里有一个问题是,OCR识别的内容有时并不准确,甚至很多时候会出现一些错误。
以上内容是关于文档加载与解析,不论是使用pdf处理工具,还是使用OCR等技术,亦或者使用pandas等处理excel文档,都是第一步获取文档内容。
在真实的业务场景中,第一步可能会使用多种方式,比如说使用OCR,多模态模型,各种文档处理工具等。而且为了提升文档等解析效果,很多时候会使用多种策略组合的方式,比如说同时支持多种不同类型的文档格式,可以选择不同的解析策略。
数据清洗
在第一步文档解析拿到文档内容之后,拿到的文档内容并不能直接使用,而是需要对文档进行清洗,去除文档中的噪音,无关内容等。
RAG的效果很多时候是由召回的文档质量决定的,而要保证文档质量首先要解决的就是噪音问题,比如说页眉页脚,版权声明,无意义的空格/字符,导航菜单,停用词等。
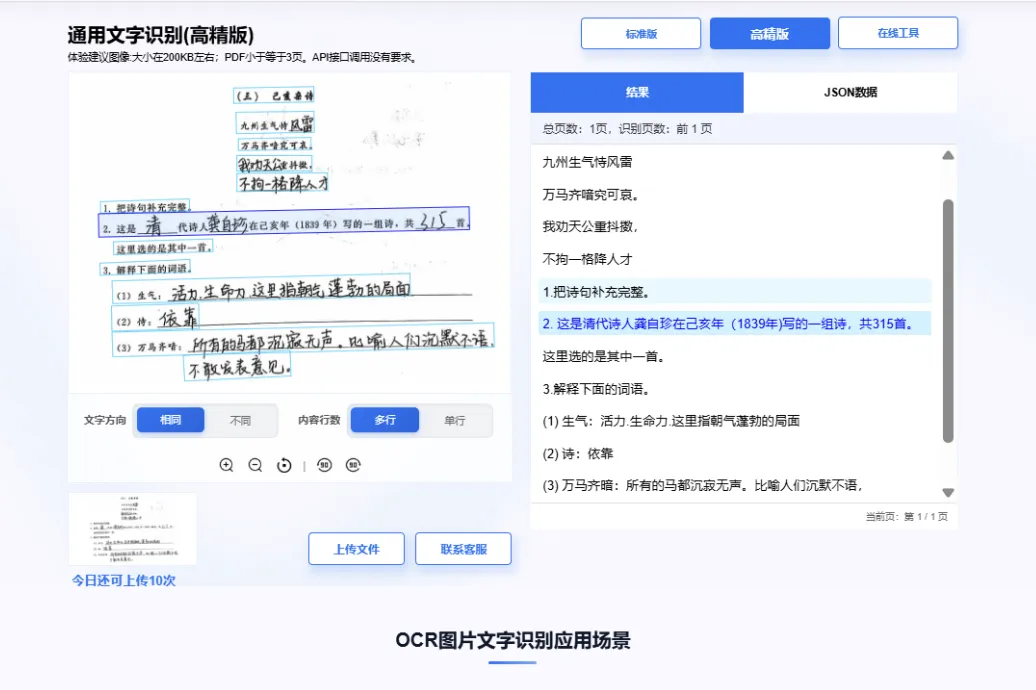
其中还有一个很重要的点是,文档结构问题;特别是OCR识别,很多时候扫描件经过OCR识别之后会丢失原本的文档结构。比如说标题层级丢失,文本抽取错乱,表格被打散等问题。
文档结构完整性
虽然说页眉页脚页码等对文档内容本身来说是噪音,但对保持文档结构有很大的作用;我们做RAG并不是文档处理完召回就结束了,还要保证文档的可溯源性,而这首先就要保证文档的结构完整性。
所以,文档的元数据(metadata)构建是重中之重,为了知识库系统的可维护性;文档需要实时新增新文件,删除过期文件,更新旧文件等;所以,有了元数据就不仅可以维护文档的结构,还可以对这些文档进行版本管理。
如果你也有RAG效果不好或者文档处理相关的问题,可以私信或者添加我微信。