 夜雨聆风
夜雨聆风





重磅!OpenClaw 联合 NVIDIA 开源 ClawHub 智能体技能安全扫描数据集,直击 AI 安全命门!

图 1:OpenClaw 与 NVIDIA 联合发布 ClawHub 智能体安全防护计划
导语:随着大语言模型和 AI 智能体(Agent)的爆发,如何保障智能体“技能(Skills)”的安全成为了行业亟待解决的命门。近日,OpenClaw 联合 NVIDIA重磅宣布,合作开源针对67,453 个 ClawHub 技能的安全扫描数据集,以多层信任防御模型共筑 AI 智能体安全防线!
一、 核心亮点与关键发现
本次 OpenClaw 与 NVIDIA 的深度合作,在 Hugging Face 上开源了极其庞大的安全数据集。通过专业安全工具的全面体检,数据集向业界披露了关于智能体技能安全性的几大颠覆性发现:
OpenClaw 与全球芯片及 AI 巨头NVIDIA强强联手,在 Hugging Face 平台共享了包含67,453 个 ClawHub 智能体技能的全量安全扫描数据集,为全球安全研究人员提供了第一手实战样本。
在风险排查中,NVIDIA 专为智能体打造的扫描器SkillSpector标记了高达50%(整整 1/2)的技能存在“智能体风险 (Agentic Risk)”。这意味着在提示词和系统指令层面,AI 仍极易受到潜在的行为偏差与注入攻击影响。
令人欣慰的是,确认带有恶意(Malicious)漏洞或后门的技能占比极低,仅为0.31%。然而,令人吃惊的是,没有任何两个安全扫描器在风险判定上的重合度超过 8.5%,显示出当前安全扫描工具之间的判定标准和技术维度存在巨大差异。

图 2:基于安全数据集的 ClawScan 实时监测后台
二、 ClawHub 的多层安全防御模型
鉴于安全扫描器间极低的重合度,公告指出:单纯依赖任何一种单一安全检测工具均无法有效守护智能体安全。因此,ClawHub 构建了一套多层信任模型(Layered Trust Model),将多个安全防御维度的数据融为一体,生成了最终的ClawScan 安全评分:
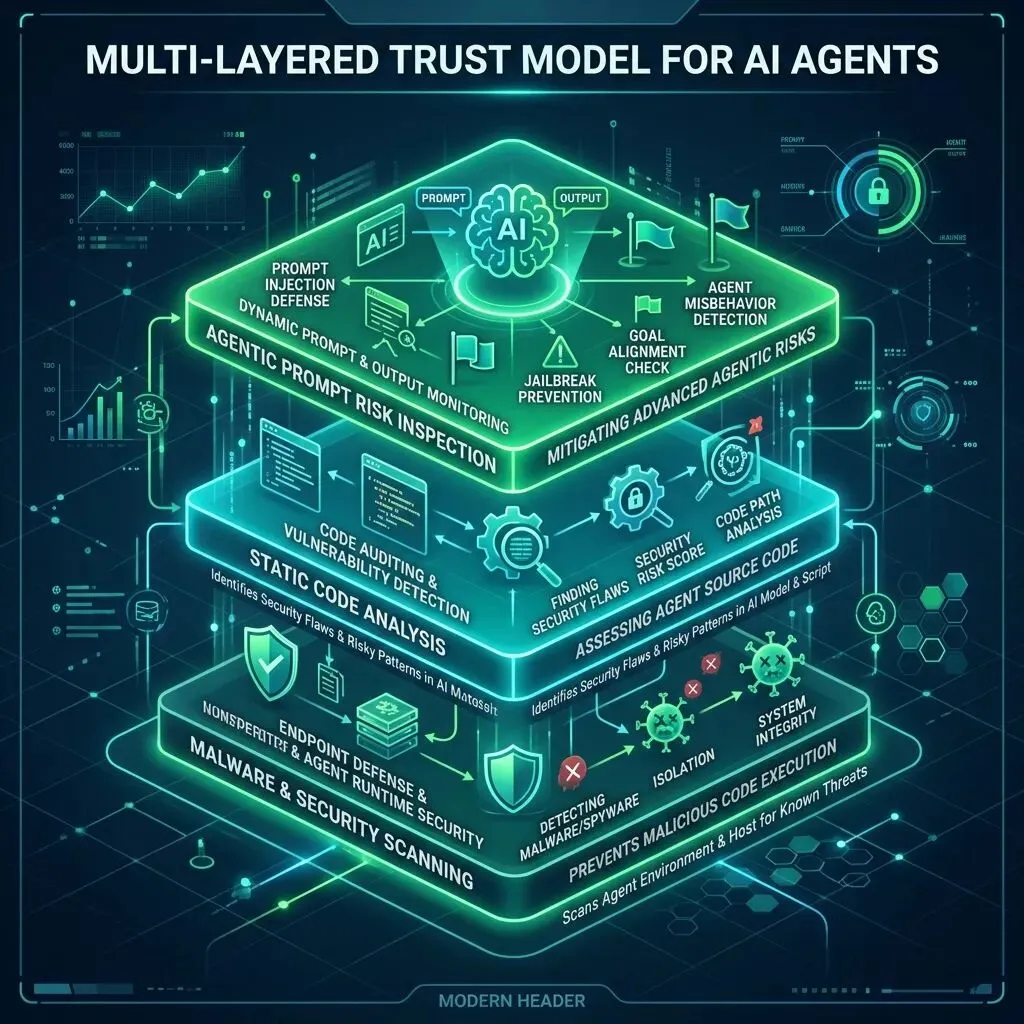
图 3:ClawHub 智能体技能多层信任防御框架
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
三、 相关资源与直达通道
为了方便开发者与研究学者第一时间使用该安全扫描数据集,我们整理了官方提供的各项核心资源入口:
-
🌐官方博客:OpenClaw & NVIDIA 合作详情立即阅读 -
📄研究论文:ClawHub 安全信号 PDF下载论文 -
🤗开源数据集:Hugging Face 仓库克隆数据 -
🐦官方推文:X (Twitter) 讨论传送门参与互动
🦞 总结愿景:
OpenClaw 此次开源安全数据集,旨在呼吁整个 AI 社区共同参与,协力构建更完善的智能体安全解决方案。正如其口号所言:“水涨众螯高(A rising tide lifts all claws 🦞)”。