 夜雨聆风
夜雨聆风你是不是也经常看到这样的场景:很多人想在本地体验一下最近爆火的大模型(比如DeepSeek、Qwen、Llama),结果打开教程一看——“去HuggingFace下载模型”、“用Transformers加载”、“注意显存大小”……满屏术语,直接劝退。最后只能上闲鱼花几百块找人帮忙部署,自己还是那个“只会调API”的工具人。
其实,部署大模型就像组装一台电脑:你不需要会造CPU,但得知道内存、硬盘、显卡是干嘛的,知道去哪里买配件、怎么把它们装起来。今天这篇文章,就是帮你先把这些“配件”搞清楚——模型到底是个什么东西?我从哪里下载?下载回来的那些文件都是干嘛的?为什么有的模型几GB,有的几百GB?
这不是一篇枯燥的理论课,而是一份人人都能看懂的大模型“解剖指南”。我会用最直白的语言,带你彻底搞懂这些基础概念。懂了这些,你就拿到了本地部署的第一把钥匙,以后再也不用为“看不懂教程”而发愁。
1. 大模型全球生态——托管平台与代码仓库
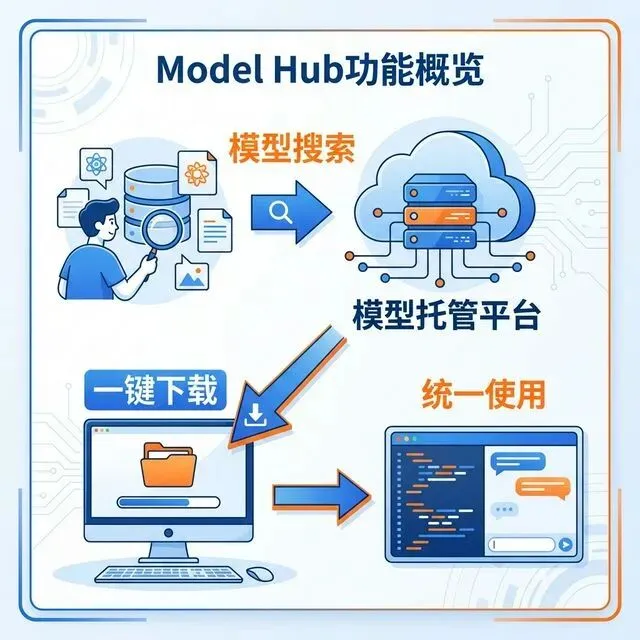
1.1 模型托管平台概述——大模型的“应用商店”
在正式动手之前,我们先要搞清楚一个概念:什么是模型托管平台?它就像手机上的应用商店,只不过里面存放的不是APP,而是各种训练好的大模型。
1.1.1 新手最常遇到的困惑
回想一下,如果你现在想用一个大模型,通常会遇到三个问题:
模型从哪里下载?以前你可能需要去论文作者的个人主页翻找,下载一个几百MB的压缩包,解压后还不知道哪个是真正的模型文件。
下载后怎么用?不同模型的加载方式千奇百怪,代码怎么写?用哪个库?
这模型靠谱吗?网上下载的模型会不会有病毒?效果到底行不行?
模型托管平台的出现,就是为了一站式解决这些问题。它提供标准化的搜索、下载和使用方式,让你像安装APP一样使用大模型。
1.1.2 两大主流平台:HuggingFace 和 ModelScope
目前全球最流行的两个平台是:
HuggingFace(抱脸):全球最大的模型仓库,托管了超过210万个模型,几乎你能想到的所有知名模型(Llama、GPT、BERT等)都能在这里找到。不过服务器在国外,国内访问有时会慢。
ModelScope(魔搭社区):阿里云推出的国内平台,中文友好,下载速度快,而且有很多针对中文优化的模型(如通义千问Qwen系列、ChatGLM等)。
对于国内新手,我的建议是:做中文应用优先用ModelScope,需要国际模型(如Llama)可以去HuggingFace,两个平台搭配使用最香。
1.2 实战指南——账号注册与模型下载
光说不练假把式,接下来我们手把手教你在这两个平台上注册、搜索并下载模型。
1.2.1 HuggingFace 实用操作指南
1.2.1.1 注册账号
打开,点击右上角“Sign Up”。
填写邮箱、密码和用户名(用户名一旦设置不能修改,它将作为你以后发布模型的URL前缀)。
查收验证邮件,点击链接激活账号。
1.2.1.2 获取 Access Token(访问令牌)
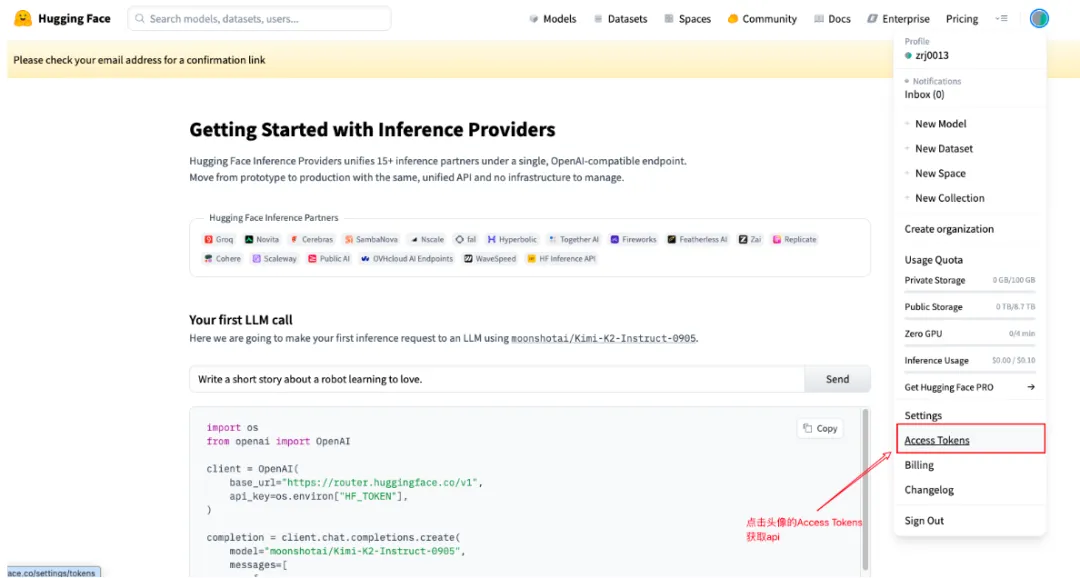
很多模型(如Llama 3、Gemma)需要登录才能下载,而且使用Token可以享受更快的下载速度。
登录后点击右上角头像 →Settings→Access Tokens。
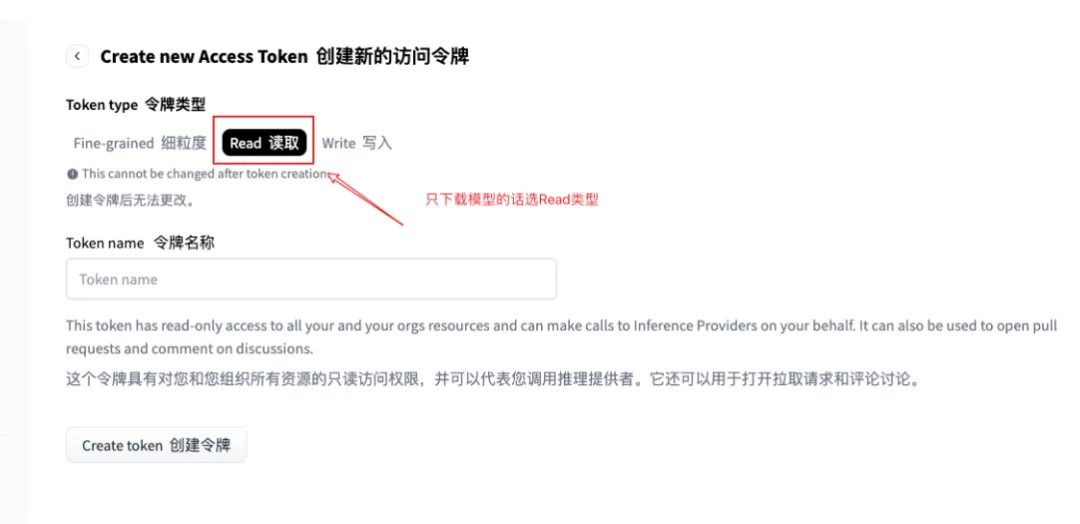
点击New token,选择Read权限(只读即可,日常下载用这个最安全),起个名字(比如“MyLaptop”),然后点击生成。
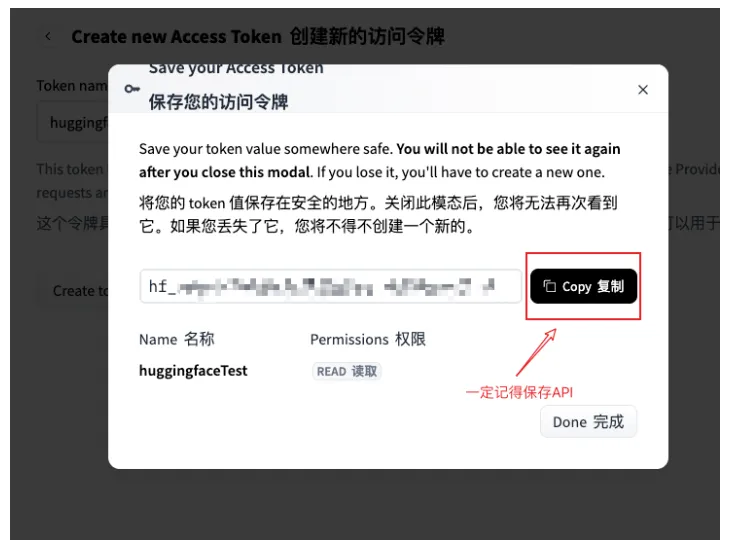
立即复制并保存好这个以hf_开头的Token,关闭窗口后就再也看不到了!
1.2.1.3 本地登录配置
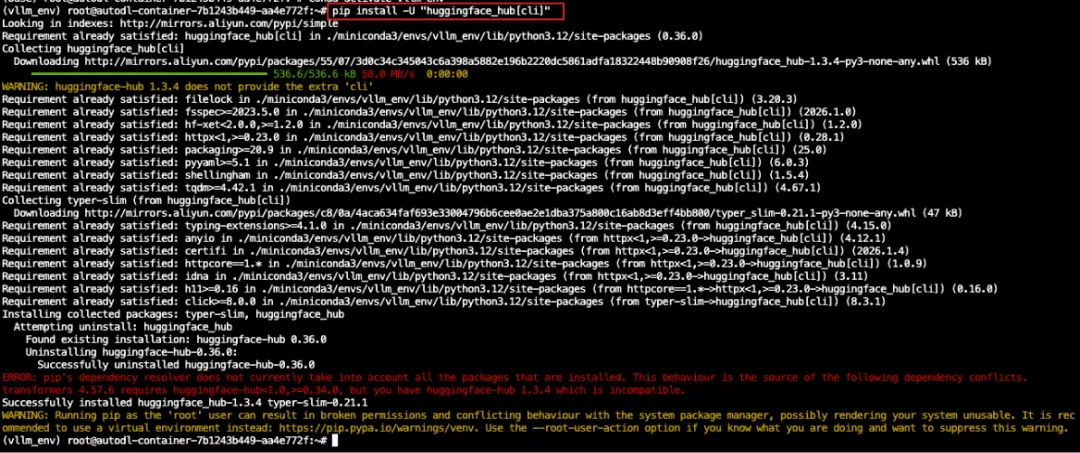
在本地电脑上安装huggingface_hub并登录,以后下载模型就不需要每次都输入Token了。
# 安装huggingface_hub(包含命令行工具)pip install -U "huggingface_hub[cli]"# 执行登录命令,粘贴刚才保存的Token(粘贴时屏幕不会显示,直接回车即可)huggingface-cli login# 验证登录成功huggingface-cli whoami # 应该显示你的用户名
1.2.1.4 如何搜索和筛选模型
访问 https://huggingface.co/models 。
在搜索框输入关键词(如“Qwen2.5-7B”)。
左侧筛选栏可以按任务(Task)、排序(Sort by Most Downloads)、大小(Size)筛选。新手建议选“< 3B”的模型,普通电脑也能跑。
1.2.1.5 如何下载模型(三种方式)
方式一:在代码里自动下载(最常用)
from transformers import AutoModel, AutoTokenizer# 第一次运行时会自动下载模型,后续会使用缓存model = AutoModel.from_pretrained("bert-base-chinese")tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
方式二:使用huggingface-cli命令行下载(推荐用于大模型)
# 下载整个模型仓库(适合小模型)huggingface-cli download bert-base-chinese# 高效下载:只下载.safetensors和.json文件,排除旧的.bin格式,并指定本地目录,支持断点续传huggingface-cli download Qwen/Qwen2.5-7B-Instruct \--include "*.safetensors" "*.json" "*.model" \--exclude "*.bin" \--local-dir ./models/Qwen2.5-7B \--resume-download
参数说明:
--include:只下载匹配的文件(支持通配符)
--exclude:排除不需要的文件
--local-dir:指定保存路径(强烈推荐,便于管理)
--resume-download:支持断点续传
如果遇到大模型(几十GB),可以启用多线程并发下载,大幅提升速度:
# 1. 先安装加速库pip install hf_transfer# 2. 启用加速下载(在命令前加环境变量)HF_HUB_ENABLE_HF_TRANSFER=1huggingface-cli download gpt2
注意: 开启此选项后,进度条可能不如默认详细,但速度会明显提升。
方式三:使用Python SDK snapshot_download(进阶)
from huggingface_hub import snapshot_downloadmodel_path = snapshot_download(repo_id="Qwen/Qwen2.5-7B-Instruct",local_dir="./models/Qwen2.5-7B",allow_patterns=["*.safetensors", "*.json"],ignore_patterns=["*.bin"],token="你的_READ_TOKEN" # 如果已登录可以省略)
1.2.1.6 国内用户加速方案
我们可以讲将国内镜像和多线程结合,这样速度最快,在国内网络环境下,这种组合通常能达到 50-100 MB/s 的下载速度(看网速带宽)。
import os# 设置国内镜像站,用于加速os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 设置多线程os.environ['HF_HUB_ENABLE_HF_TRANSFER'] = 1# 然后正常使用from_pretrained即可from transformers import AutoModelmodel = AutoModel.from_pretrained("bert-base-chinese")
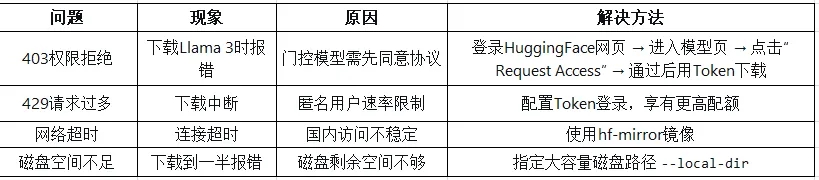
1.2.1.7 常见问题速查
1.2.2 ModelScope 实用操作指南
ModelScope对国内用户非常友好,我们快速过一下。
1.2.2.1 注册账号
访问 ModelScope官网 ,点击右上角“登录/注册”。
使用手机号验证码注册即可。
1.2.2.2 获取 Access Token
鼠标悬停在右上角头像 → 个人中心 → 访问令牌。
复制那个以
SDK_开头的字符串。
1.2.2.3 本地 CLI 登录,并下载模型
# 安装ModelScope SDKpip install modelscope# 登录(将<您的SDK令牌>替换为实际令牌)modelscope login --token <您的SDK令牌># 基础命令:下载整个模型modelscope download --model 'Qwen/Qwen2.5-7B-Instruct'# 进阶命令:指定下载目录(推荐)modelscope download --model 'Qwen/Qwen2.5-7B-Instruct' \--local_dir './models/Qwen2.5-7B'# 高级用法:只下载必要文件,排除旧格式modelscope download --model 'Qwen/Qwen2.5-7B-Instruct' \--include '*.safetensors' '*.json' \--exclude '*.bin' '*.pth' \--local_dir './models/Qwen2.5-7B'
CLI 相关参数说明:
--model:模型 ID,示例 Qwen/Qwen2.5-7B-Instruct
--local_dir:指定下载路径,示例 ./models/Qwen2.5-7B
--include:只下载匹配的文件,示例 '*.safetensors'
--exclude:排除不需要的文件,示例 '*.bin'
--revision:指定版本,示例 v1.0.0
1.2.2.4 使用Python SDK下载
from modelscope import snapshot_download# 指定目录和版本model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct', # 模型 IDcache_dir='./models', # 指定下载目录revision='master' # 指定版本号)
ModelScope的优势是下载速度快,而且很多模型支持在线运行(免费GPU环境),特别适合新手测试。
2. GitHub 与大模型开发——代码仓库的作用
很多新手误以为GitHub也是下载模型的,其实不然。
HuggingFace / ModelScope 是“模型仓库”,存放的是训练好的权重(几十GB);GitHub是“代码仓库”,存放的是源代码、示例和文档(几KB到几MB)。
对于大模型开发者,GitHub的价值在于:
获取示例代码和教程
查看模型的官方实现
寻找开源框架(如LangChain、vLLM)
解决报错(在Issues里搜索)
2.1 注册GitHub账号(含2FA强制验证)
现在GitHub强制要求开启2FA双重验证,否则无法使用命令行操作。
访问 GitHub ,点击 Sign up 注册(推荐使用Gmail/Outlook邮箱)。
完成人机验证和邮箱验证。
开启2FA:头像 → Settings → Password and authentication → Enable two-factor authentication,用手机Authenticator APP扫描二维码,并保存好恢复码。
2.2 获取 Personal Access Token
自2021年起,GitHub不再支持密码操作,必须使用Token。
头像 → Settings → Developer settings → Personal access tokens → Tokens (classic) → Generate new token (classic)。
配置 Token 名称、有效期和权限 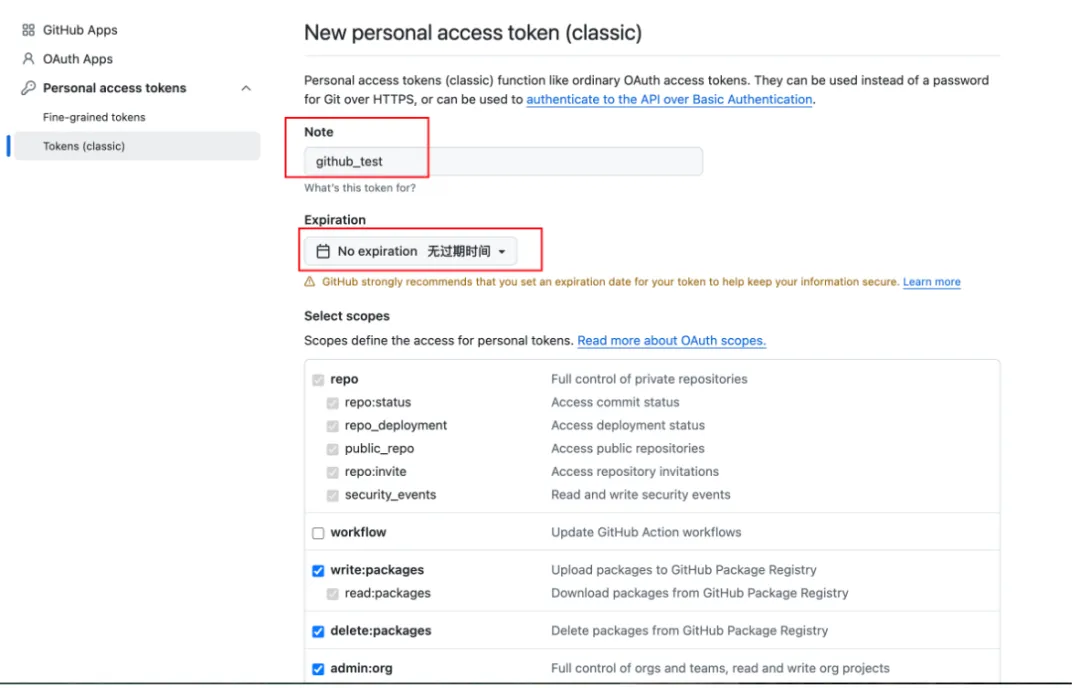

勾选
repo权限(读写仓库),设置有效期,生成后立即复制保存(以ghp_开头)。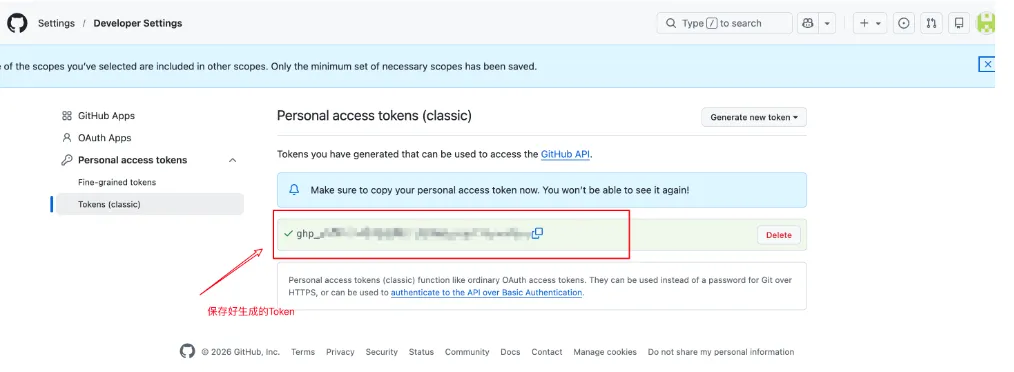
❓ 常见疑问:Classic 和 Fine-grained 有什么区别?
这里的下拉菜单会让你选择 Classic(经典版) 还是 Fine-grained(细粒度版)。
Classic(经典版):相当于"万能钥匙"。权限范围广,配置一次能管理你账号下所有仓库,适合个人开发者和学习场景。Fine-grained(细粒度版):相当于"单房间钥匙"。必须逐个指定只能访问哪一个仓库,安全性更高,适合企业级多仓库管理场景。
结论:为了避免"新建项目又得重新申请 Token"的麻烦,请务必选择 Classic 版本!
2.3 使用 Token 克隆私有仓库
# 克隆公开仓库(不需要Token)git clone https://github.com/langchain-ai/langchain.git# 克隆私有仓库(需要Token)git clone https://github.com/yourusername/private-repo.git# 提示输入用户名时输入你的GitHub用户名# 提示输入密码时粘贴Token(不是密码!)
2.4 高级搜索技巧(5步筛选高质量项目)
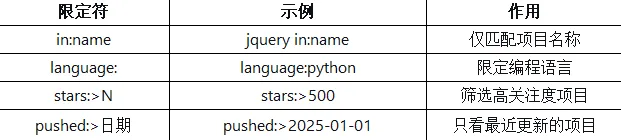
GitHub上有4亿个项目,如何找到靠谱的?具体语法速查表:
举个例子:我们想要寻找一个基于 Python 的、活跃维护的 PDF 表格提取库,具体步骤如下:
步骤1:初步筛选,初筛结果 1.6k,包含多种语言,结果杂乱无章,包含 Java、C# 以及大量废弃项目
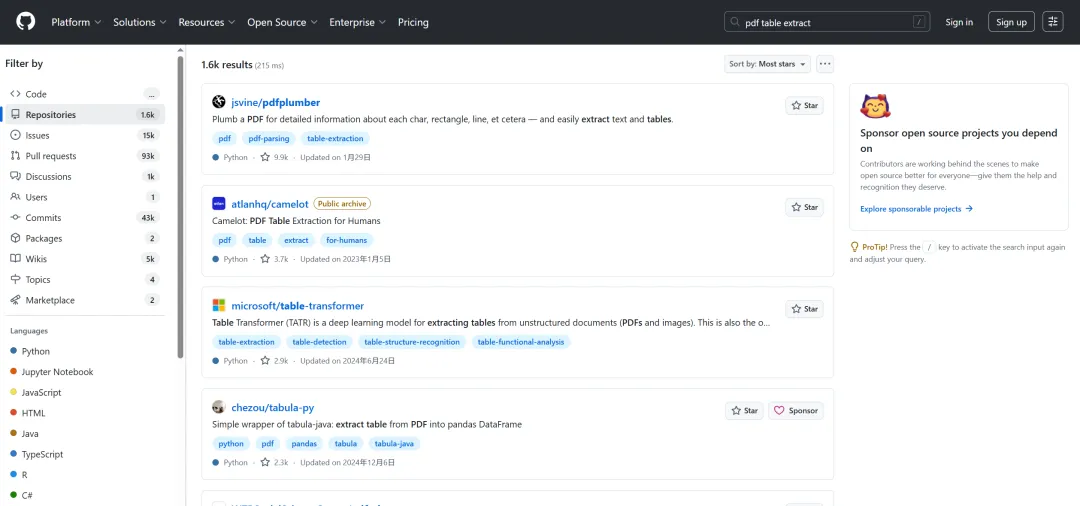
步骤2(限定语言):pdf table extract language:python
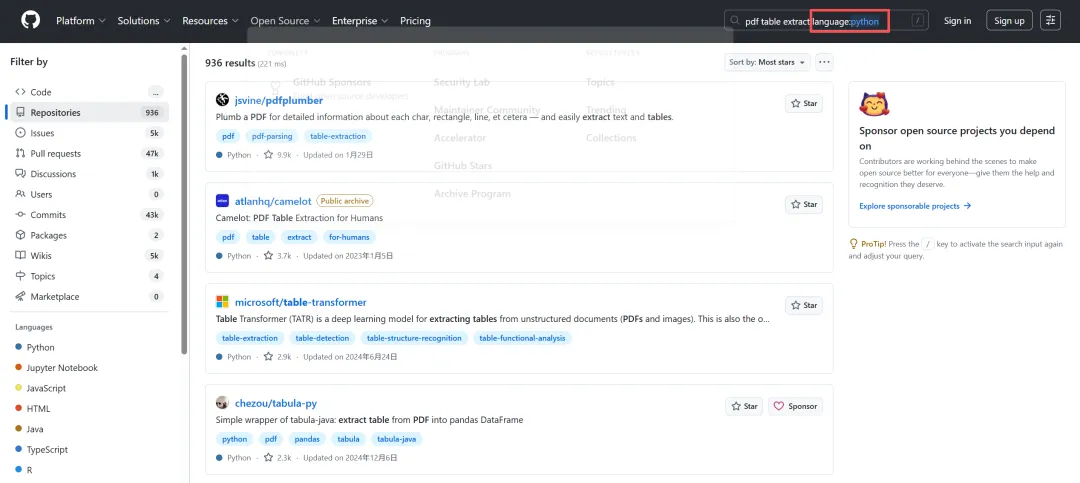
步骤3(活跃度清洗):pdf table extract language:python pushed:>2026-03-01
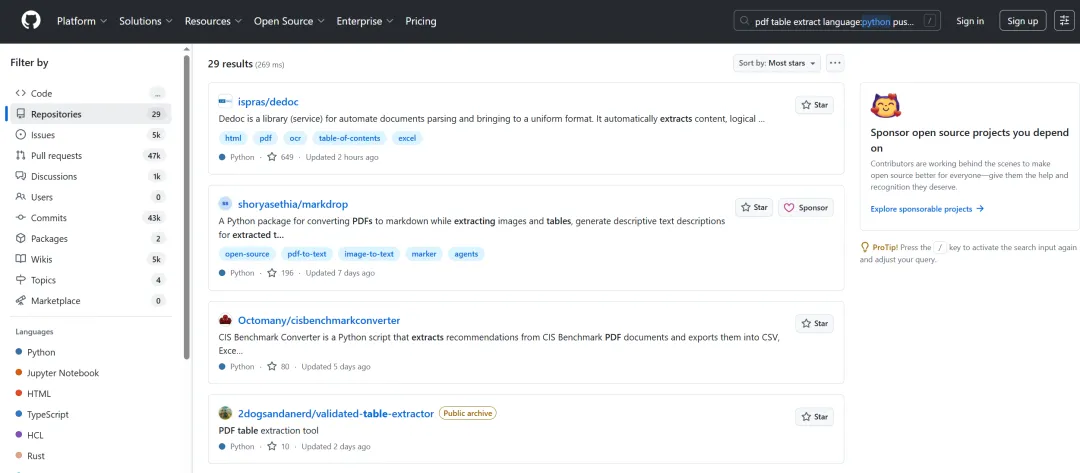
添加时间过滤,结果缩小到 29,直接过滤掉所有在 2026 年前停止更新的库。
步骤四(质量验证):pdf table extract language:python pushed:>2026-03-01 stars:>50
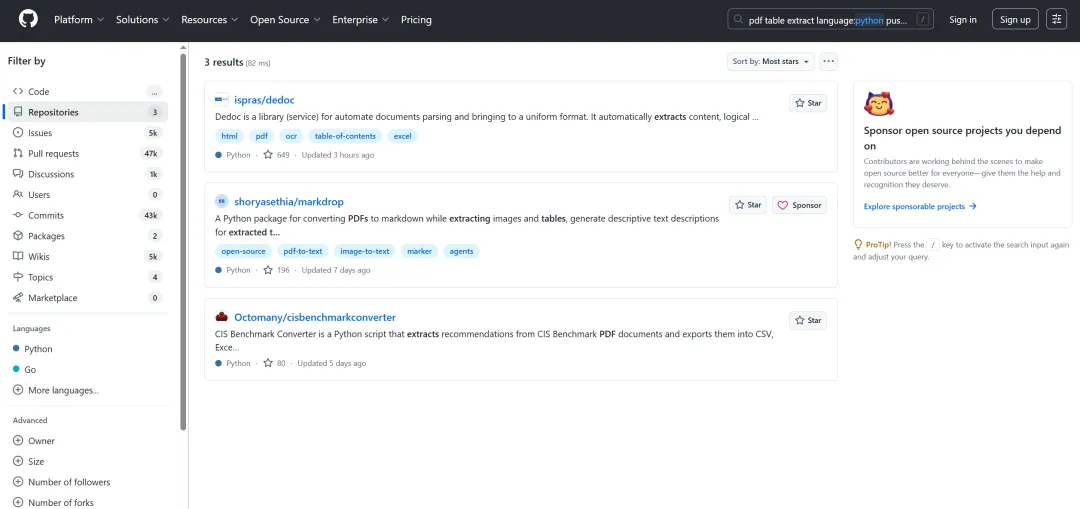
添加星标过滤,仅剩 3 个高质量项目。
步骤五(协议合规):如用于商业项目,追加 license:mit 或 license:apache-2.0。
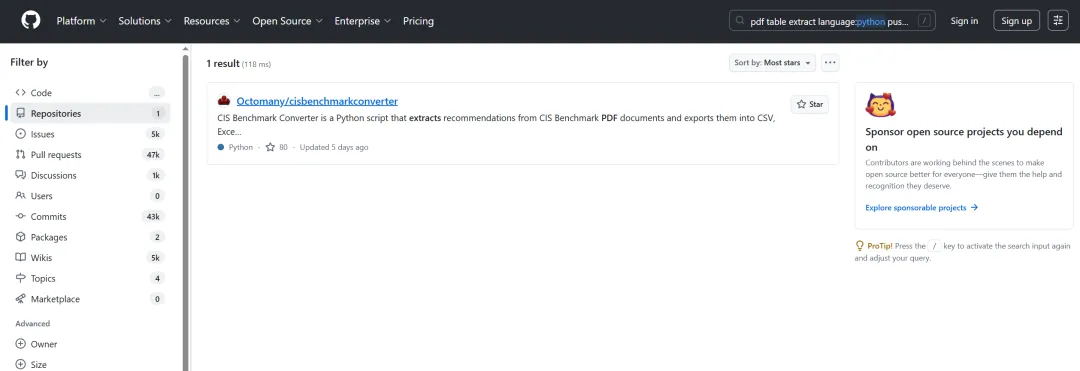
添加协议过滤,仅剩 1 个符合 MIT 协议的项目。
MIT和Apache 2.0区别如下:

接着进入项目详情页后,可以在右侧边栏验证协议类型:
3. 核心概念——权重、架构与文件结构
在正式进入技术细节之前,我们需要先建立一个清晰的认知框架。很多初学者在学习大模型的过程中,会陷入一种"工具使用者"的状态:会用 ollama run 跑模型、会用 LM Studio 加载 GGUF 文件,但对于"模型内部到底是什么"一无所知。这种状态在日常玩耍时没问题,但一旦遇到实际问题——比如模型加载报错、显存不够、输出乱码——就会完全束手无策。
3.1 理解模型背后的内容
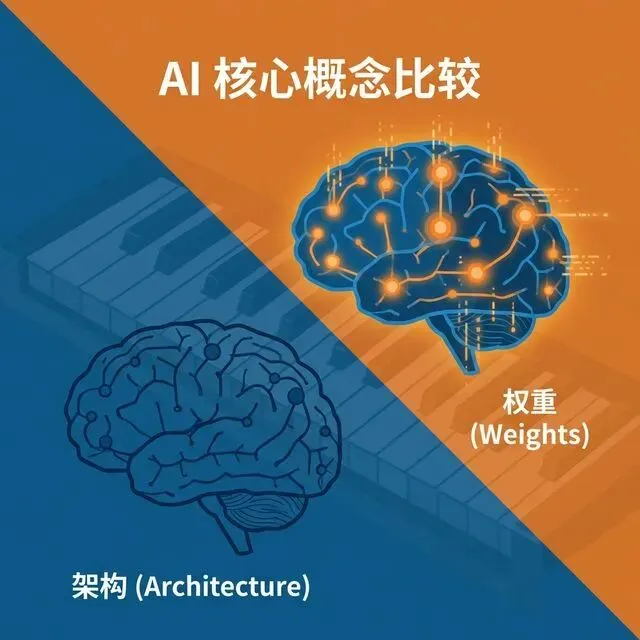
让我们从一个最基本的问题开始:当你从 HuggingFace 或 ModelScope 下载一个"模型"时,你实际上下载的是什么?答案是:模型 = 架构(Architecture)+ 权重(Weights)。
架构:用代码(通常是 Python 编写的 PyTorch 类)描述的神经网络结构(比如多少层、多少头注意力),相当于“蓝图”。
权重:训练得到的数百万到数千亿个浮点数,相当于“经验参数”。
与此同时,很多初学者误以为模型文件越大越厉害,其实不然。模型能力由参数量和训练数据质量决定,文件大小只是参数量与量化精度的乘积(如FP16、INT4)。例如,7B参数的FP16模型约14GB,而70B参数的INT4模型约35GB,后者参数量大10倍,能力远超前者。因此,评判模型应看参数量而非文件大小。
3.2 两种"用脑方式":Dense 模型与 MoE 模型

在前面的内容中,我们理解了"架构 + 权重"的基本关系,也知道了参数量决定模型能力。但这里有一个问题值得深思:明明 DeepSeek-V3 号称 671B 参数,为什么有人说它"实际上只相当于一个 37B 的模型"?这背后涉及到当前大模型领域最重要的两种架构范式——Dense(稠密)模型与 MoE(Mixture-of-Experts,混合专家)模型。
理解这两种架构的区别,对于后续的显存估算和部署决策至关重要。因为它们的"参数量"含义完全不同,直接影响你对硬件需求的判断。
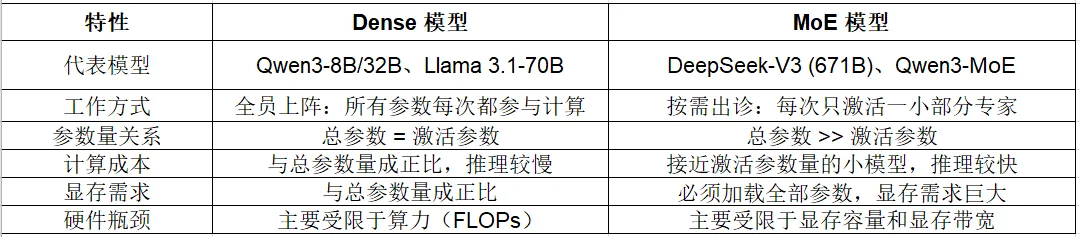
3.2.1 Dense 模型:全员上阵的"全才"
Qwen3-8B、Llama 3.1-70B 等模型,都属于 Dense(稠密)模型。它们的工作方式很直接:对于输入的每一个 token,模型中的所有参数都会参与计算。
用一个类比来理解:Dense 模型就像一个"全能型选手",无论遇到什么问题——写代码、翻译、聊天、做数学题——都要调动全身所有的"脑细胞"来处理。Llama 3.1-70B 有 700 亿参数,每次推理就要计算这 700 亿个参数,一个都不能少。
3.2.2 MoE 模型:按需出诊的"专家团"
MoE 模型则采用了一种完全不同的策略:它拥有海量的参数,但每次只激活其中一小部分来处理当前的输入。
继续用类比来理解:MoE 模型就像一个大型医院的"专家会诊中心"。医院里有几百位专科医生(专家),但每个病人来了之后,前台(门控网络)会根据症状只派 2-8 位最相关的专家去会诊,其余医生继续待命。这样既保证了诊断质量(因为总共有几百位专家的知识储备),又控制了每次会诊的成本(只有几位专家实际工作)。
以 DeepSeek-V3 为例:它的总参数量高达 671B,但每次推理只激活约 37B 参数。这意味着你用跑 37B 模型的算力,就能享受到 671B 模型的知识储备。
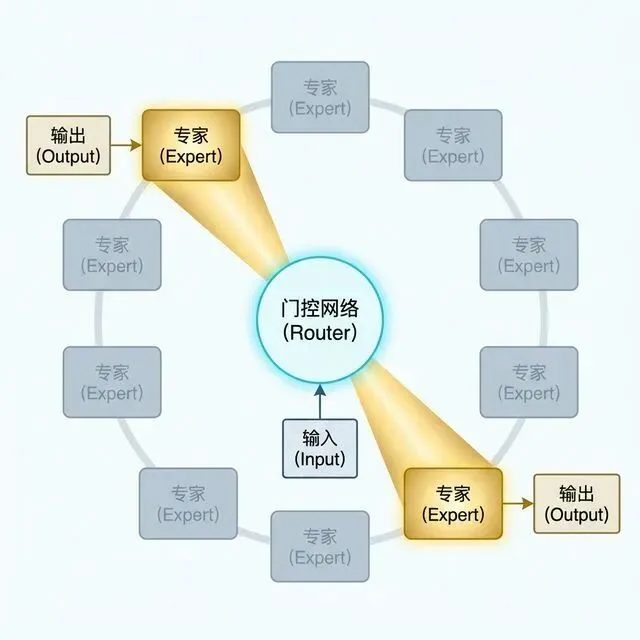
3.2.3 MoE 的内部结构:门控网络与专家
MoE 并没有改变 Transformer 的整体架构,而是修改了其中的 FFN(前馈神经网络)层。传统 Transformer 中,每一层都有一个统一的 FFN 处理所有输入;而在 MoE 架构中,这个 FFN 被拆分成了多个独立的小 FFN,每一个就是一个"专家"。
MoE 的核心组件有两个:
门控网络(Router):这是 MoE 的"分诊台"。当一个 token 输入时,门控网络会计算它与各个专家的匹配度,然后选择分数最高的 Top-K 个专家(例如 Top-2 或 Top-8)。只有被选中的专家会进行计算,其他专家被跳过。
专家(Experts):每个专家本质上就是一个独立的小型 FFN。不同的专家在训练过程中会自然地习得不同的知识模式——有的擅长处理语法结构,有的擅长代码逻辑,有的擅长数学推理。
早期的 MoE 存在一个问题:每个专家可能会"偏科",导致一些通用的基础知识(如语法结构、常见表达)需要在每个专家里都学一遍,造成参数浪费。DeepSeek-V2/V3 和 Qwen-MoE 等新一代模型引入了一个关键创新——共享专家(Shared Experts)。
共享专家的设计思路很直观:
共享专家:无论输入是什么,永远被激活,负责处理通用知识(语法、常识等)
路由专家(Routed Experts):按需激活,负责处理专业知识(代码、数学、特定领域等)
这种"通才 + 专才"的组合,大大提高了参数的利用效率。你可以把它理解为:医院里既有全科医生(共享专家,每个病人都会先看),又有专科医生(路由专家,按需会诊)。
理解了 MoE 的工作原理后,我们就能看到它在部署时面临的核心矛盾:虽然每次计算只用到一小部分参数,但所有参数都必须加载到内存中等待被召唤。
以 DeepSeek-V3 为例:每次推理只激活 37B 参数,计算速度接近一个 37B 的 Dense 模型。但它的 671B 总参数在 FP16 下需要约 1.3TB 的存储空间——这些参数必须全部加载到内存或显存中,因为门控网络在每一层都可能选择不同的专家,你无法提前知道哪些专家会被用到。
这就引出了 MoE 模型本地部署的关键策略——Expert Offloading(专家卸载):
将共享专家和当前激活的路由专家放在 GPU 显存中(快速计算)
将大量休眠的路由专家放在 CPU 内存(RAM)中(等待被召唤)
这也是为什么 llama.cpp 和 ktransformers 这类框架对 MoE 模型如此重要——它们能够智能地在 CPU 和 GPU 之间调度专家权重。对于 MoE 模型的本地部署,你的内存(RAM)容量可能比显存(VRAM)更重要。
Dense 模型与 MoE 模型核心对比:
3.3 模型文件解析
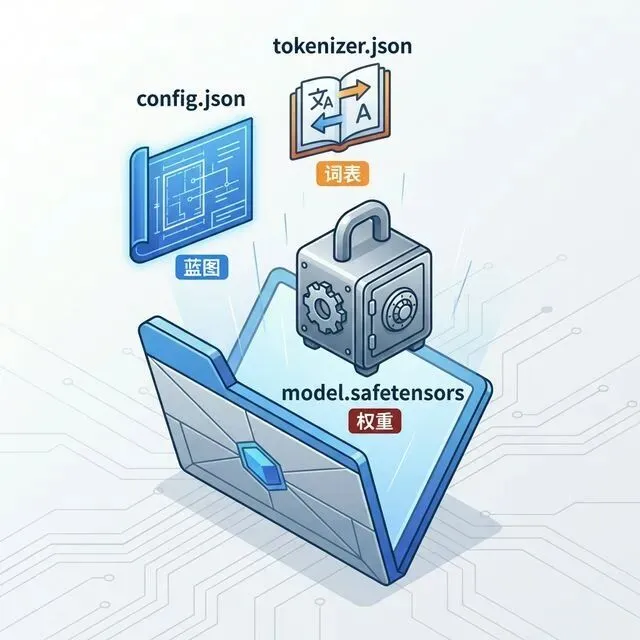
在3.2中,我们从宏观角度理解了"架构"与"权重"的关系。现在,让我们进入更具体的层面:当你从 HuggingFace 或 ModelScope 下载一个模型后,文件夹里那一堆文件,具体如下:
config.json # 模型架构配置文件(必选)tokenizer.json # 词表映射(必选)tokenizer_config.json # 分词器配置(必选)model-00001-of-00004.safetensors # 权重分片(必选)model.safetensors.index.json # 分片索引(必选)generation_config.json # 生成参数(可选)special_tokens_map.json # 特殊token映射(可选)README.md # 模型说明(可选)
3.3.1 config.json:模型的“蓝图”
{"architectures": ["Qwen2ForCausalLM"],"hidden_size": 4096,"num_hidden_layers": 32,"num_attention_heads": 32,"vocab_size": 151936,"max_position_embeddings": 32768}
architectures:指定模型类型,加载库会调用对应的Python类。
hidden_size:隐藏层维度(宽度)。
num_hidden_layers:层数(深度)。
vocab_size:词表大小(能识别的token数量)。
max_position_embeddings:最大上下文长度。
3.3.2 tokenizer:模型的“翻译官”
Tokenizer负责把人类语言转换成模型能理解的数字ID,以及把数字ID解码回文字。
tokenizer.json:存储词汇到ID的映射表。tokenizer_config.json:定义分词规则和特殊token(如<|end_of_text|>)。
重要:Tokenizer和Model必须来自同一个文件夹,混用会导致乱码。
3.3.3 safetensors vs bin:安全性的演进
.bin:基于Python的pickle格式,反序列化时可能执行任意代码,有安全风险。
.safetensors:纯二进制格式,只存储张量数据,支持内存映射(mmap),加载更快更安全。
建议:优先下载 .safetensors 格式的模型。
3.3.4 大模型的分片机制
70B级别的模型权重通常被分成多个文件,比如:
model-00001-of-00004.safetensorsmodel-00002-of-00004.safetensorsmodel-00003-of-00004.safetensorsmodel-00004-of-00004.safetensorsmodel.safetensors.index.json
index.json 是“目录”,记录了每一层权重存储在哪个文件中。加载时会自动读取索引并加载对应分片。
3.3.5 generation_config.json:模型的"性格"
generation_config.json 是一个可选但重要的文件,它定义了模型生成文本时的默认行为。
{"temperature": 0.7,"top_p": 0.8,"max_new_tokens": 512,"do_sample": true,"eos_token_id": 151643}
关键参数解读
temperature:控制随机性,值越高输出越发散,值越低输出越确定top_p:核采样阈值,只从累积概率达到 p 的 token 中采样max_new_tokens:最大生成长度eos_token_id:结束符 ID,模型生成到这个 token 就停止
🔥 踩坑预警:很多小白抱怨模型"车轱辘话"或者"停不下来",往往是因为
generation_config.json中的eos_token_id设置错误,或者与 Tokenizer 中的定义不一致,导致模型不知道何时该停止生成。解决方案:确保eos_token_id与tokenizer_config.json中的定义一致。
3.5 显存估算速算法(硬门槛)
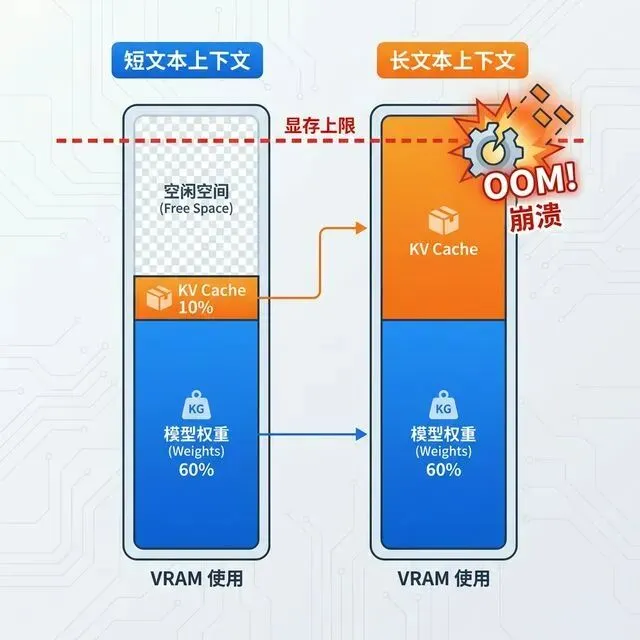
静态显存是指模型权重本身占用的显存,这是一个固定值,由模型参数量和量化精度决定。
静态显存(模型权重本身):
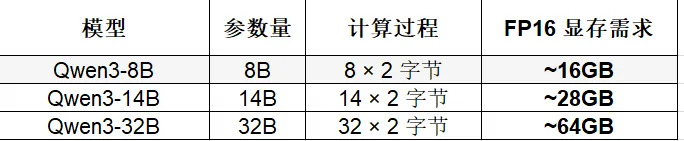
显存(GB) ≈ 参数量(B) × 每参数比特数 / 8FP16:每参数2字节 → 7B模型 ≈ 14GB,14B ≈ 28GB,32B ≈ 64GB
INT4:每参数0.5字节 → 7B ≈ 3.5GB,14B ≈ 7GB,32B ≈ 16GB。
让我们用这个公式计算几个常见模型的显存需求,本次以Dense 模型静态显存估算示例(FP16 精度)
对于 Dense 模型,这个公式非常直观——参数量乘以每个参数的字节数就是显存需求。但对于 MoE 模型,情况要复杂得多,我们在下面单独讨论。
MoE 模型的显存陷阱:用总参数量计算,而非激活参数量
在之前中,我们了解到了MoE 模型的"总参数量"和"激活参数量"是两个完全不同的数字。在估算显存时,必须使用总参数量,因为所有专家的权重都必须加载到内存中。这是新手最容易犯的错误之一。
以 DeepSeek-V3 为例,MoE 模型显存估算的常见误区,我们来看这个差异有多大:

从表格可以看出,如果错误地用激活参数量来估算,你会以为 DeepSeek-V3 只需要 74GB 显存,实际上它需要 1.3TB——差了将近 20 倍。这也解释了为什么 MoE 模型的本地部署通常需要借助 CPU 内存(RAM)来存放大量休眠的专家权重,而不是把所有参数都塞进 GPU 显存。
⚠️ 常见误区:看到 DeepSeek-V3 "激活参数 37B"就以为它和 Qwen3-32B 的显存需求差不多。实际上,DeepSeek-V3 的总参数量是 671B,即使使用 INT4 量化也需要约 230GB 的存储空间。MoE 模型的显存/内存需求,永远由总参数量决定。
动态显存(KV Cache):模型在生成第 N 个 token 时,需要"回头看"前 N-1 个 token 的信息。为了不重复计算,模型会把之前所有 token 的 Key 和 Value 向量缓存起来,这就是 KV Cache。
KV Cache与上下文长度成正比,公式:

以 Llama 4 Scout 70B 为例,精度采用FP16,每 1000 个 token 的 KV Cache 约占用 640 MB,如果想跑满 128K 上下文:128 × 0.64 GB ≈ 82 GB 仅用于 KV Cache!这意味着:即便你有两张 RTX 4090(48GB 总显存),虽然能加载 35GB 的 INT4 权重,但剩下的 13GB 只够支撑约 20K token 的上下文,根本跑不满 128K。
🔥 避坑指南:不要被模型宣传的"支持 128K 上下文"所迷惑。实际能用多长的上下文,取决于你的显存余量。公式:可用上下文长度 ≈ (总显存 - 模型显存) / 每 1K token 的 KV Cache 大小
你在下载模型时,可能会看到这样的版本:
Qwen2.5-7B-Instruct(FP16,约14GB)Qwen2.5-7B-Instruct-GPTQ-Int4(INT4,约4GB)Qwen2.5-7B-Instruct-GGUF(Q4_K_M,约4.5GB)
同一个模型,为什么文件大小差这么多?这就涉及到量化(Quantization)的概念。简单来说,量化就是一种“压缩”技术,让庞大的AI模型能够在我们普通人的电脑上跑起来。
4.1 什么是量化
想象一下,你要记录一个班级所有学生的身高。你有两种记账本:
高精度账本:每个学生的身高都精确到小数点后6位(比如:
175.362841 kg)。这非常精确,但每个数字都要占很大地方,账本很厚。低精度账本:你决定只保留整数(比如:
175 kg)。虽然丢掉了一些细微的差别,但账本瞬间变薄了3/4,而且“175”这个关键信息还在。
在计算机世界里,存储小数有不同的精度(占用的字节数不同),就像不同的“账本”:
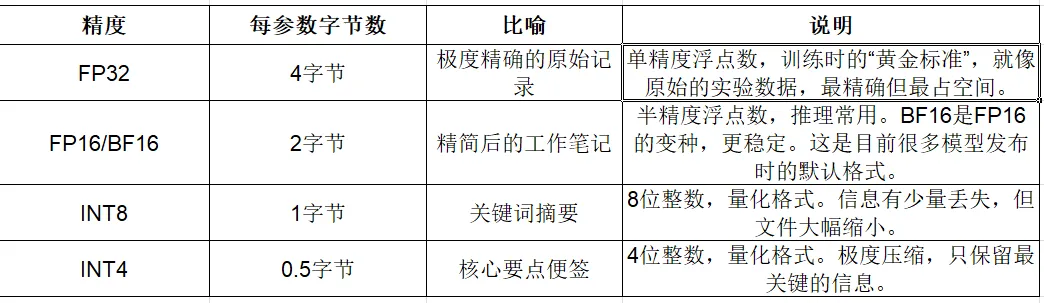
量化的本质:就是一套“智能压缩”算法。它把高精度的浮点数(如FP16)映射成低精度的整数(如INT4),从而大幅减少文件大小和显存占用。这就像把一张4K高清图片压缩成JPEG格式——文件变小了,肉眼看不出太大区别,但主体信息还在。
4.2 量化的效果
量化到底有多厉害?我们用70B参数的超大模型来算一笔账:
FP16精度(原始大小):70B参数 × 2字节 = 140GB,这意味着你需要4张A100 80GB这种单价近10万元的顶级专业显卡才能运行。这对绝大多数人来说是天方夜谭。
INT4精度(量化后):70B参数 × 0.5字节 = 35GB,只需要两张RTX 3090 24GB这种消费级显卡(总价约2-3万元)就能本地运行。甚至一些优化好的单张24GB显卡也能勉强跑起来。
INT4量化让原本需要几十万元服务器才能跑的模型,变成了双卡3090就能本地运行。 这就是量化技术的魅力——它把AI模型从昂贵的“数据中心机房”带到了普通极客的“书房电脑”里。
4.3 量化的代价
你可能会担心:压缩这么多,模型会不会变傻?会不会像压缩过度的图片一样满是马赛克?
结论是:在合理的量化等级下,几乎感觉不到差异。
我们以Qwen3-8B模型为例,用“困惑度”(Perplexity,PPL,衡量模型预测能力的指标,数字越低越好)来看不同精度的效果对比:
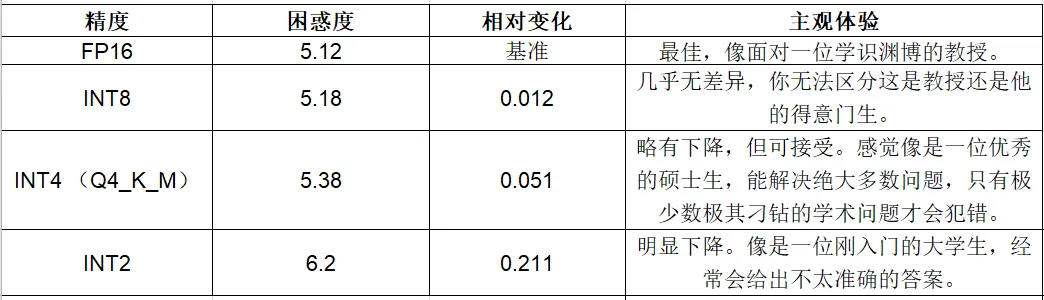
从数据看,INT4量化只带来约5%的困惑度上升,在实际对话、写作、编程等任务中,你几乎感知不到差异。这就是为什么 INT4是目前本地部署的“甜点”精度——它在显存节省(节省75%)和效果保持(保留95%以上的能力)之间取得了最佳平衡。
4.4 三大主流量化压缩算法
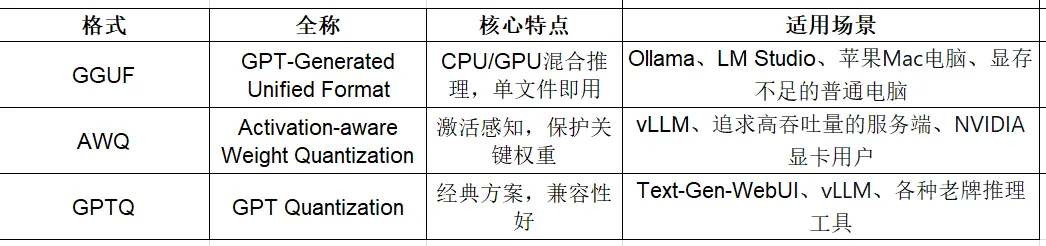
你会看到模型文件有不同的后缀,比如GGUF、AWQ、GPTQ,它们就像是不同的“压缩算法”,各有侧重,适用于不同的场景。
4.4.1 GGUF:最灵活的“通用格式”
GGUF是目前个人电脑上最流行的格式,它的最大优势是 “灵活”。
CPU/GPU混合“作战”:当你显存不够时,它可以把一部分计算任务卸载到系统内存(RAM)里,由CPU负责。虽然速度会慢一些,但至少能让程序跑起来,不会直接“崩溃”。这对于显存有限(比如只有6GB、8GB)的消费级显卡非常友好。
单文件,即下即用:一个GGUF文件就是一个完整的模型,配合Ollama等软件使用非常方便。
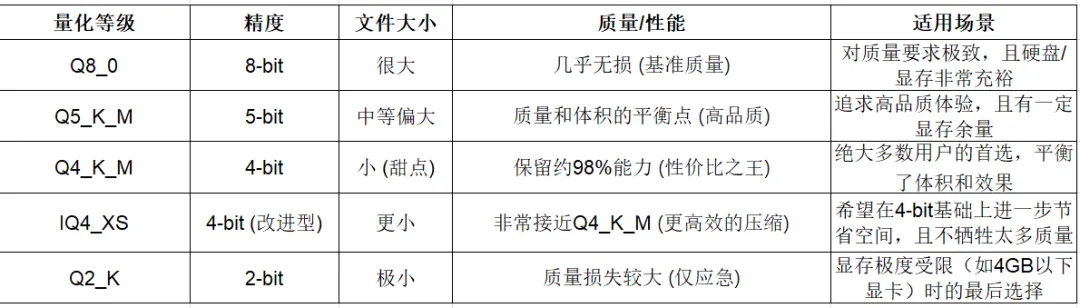
GGUF文件的后缀(如Q4_K_M)代表了不同的量化等级,你可以理解为“压缩率”:
4.4.2 AWQ 与 GPTQ:GPU的“专属高速格式”
如果你拥有性能不错的NVIDIA显卡,并且显存足够装下整个量化后的模型(比如RTX 3060 12GB),那么AWQ和GPTQ是追求极致速度的更好选择。
它们不支持CPU卸载,显存不够就直接报错。
AWQ(Activation-aware Weight Quantization):这是一种更“聪明”的量化方法。它在压缩时,会像“重点复习”一样,观察模型在推理时哪些权重会产生更大的“激活值”。它发现,大约只有1%的权重是关键的“考点”。因此,AWQ的策略是完美保护这1%的关键权重,只压缩剩下的99%。这使得AWQ在同样的4-bit下,效果往往比传统方法更好。
GPTQ:这是量化领域的“老牌劲旅”,非常经典和稳定。它利用复杂的数学方法(二阶导数信息)来补偿量化过程中的误差,兼容性极好,被Text-Gen-WebUI等老牌工具广泛支持。
回顾这一路,我们从最基础的“模型到底是个什么东西”开始,一步步拆解了模型托管平台、代码仓库、模型文件结构、量化原理和显存估算。现在,你应该已经具备了这样的能力:
知道去哪里找模型、看得懂模型文件夹里的每一份文件、明白为什么同一个模型有不同大小、能估算出自己的电脑到底能跑多大的模型。
这些听起来很基础,但恰恰是无数人卡在门口的地方——因为他们只学会了“复制粘贴命令”,却没搞懂背后是什么。而你不同,你有了“内功心法”,再看任何教程,都不会再一头雾水;遇到报错,也知道该从哪里入手排查。
下一篇文章,才是真正的“动手时刻”。我会带你租一台云端GPU(几块钱一小时),亲手用Transformers跑通第一个模型,再用llama.cpp玩转量化,最后部署Ollama和vLLM,搭建起属于自己的API服务——从此,你不再是个“只会调API的工具人”,而是真正能掌控模型的“手艺人”。

