 夜雨聆风
夜雨聆风不是写文档。是找文档。
动力系统部的工程师要写一份发动机地面试车测试大纲。在他打开编辑器之前,他要先做这些事:找系统工程部的需求文档里关于这台发动机性能指标的条目,找总体设计部的接口要求,找全局 ICD 里的推力/质量/接口定义,找试验与验证部的测试标准模板,找质量与可靠性部的 FMEA 相关条目。五个部门,五套文档体系,版本各异,格式不一,散落在不同人的电脑和系统里。
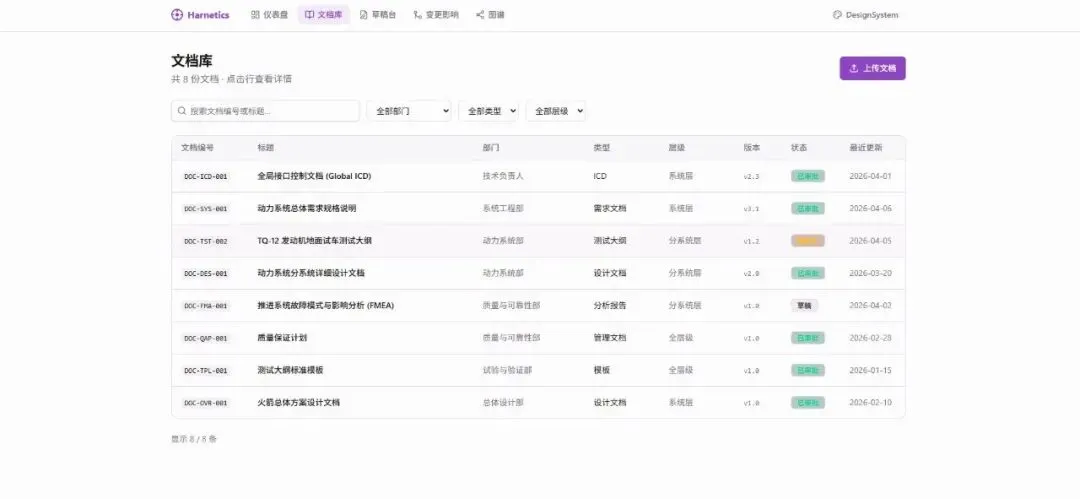
他要花 2-3 天完成这些定位、核对、对齐的工作。然后才能开始写初稿。
这四个人独立确认了一组数据:每天 40-60% 的工作时间花在文档编写和评审上。其中最耗时的不是"写",是"对齐"——确保自己的文档和上游、平级的其他文档在内容上一致、版本上对得上、引用不遗漏。
我管这个成本叫对齐税。每份文档都要交,涉及的部门越多、层级越多,税越重。
对齐税从哪来
一家商业火箭公司通常有十来个部门。系统工程部、总体设计部、动力系统部、GNC 与航电部、结构与机构部、回收部、AIT 部、发射与运营部、试验与验证部、质量与可靠性部、供应链部、前沿技术预研部。每个部门既是文档的生产者,也是其他部门文档的消费者。
文档之间的依赖有两个方向。
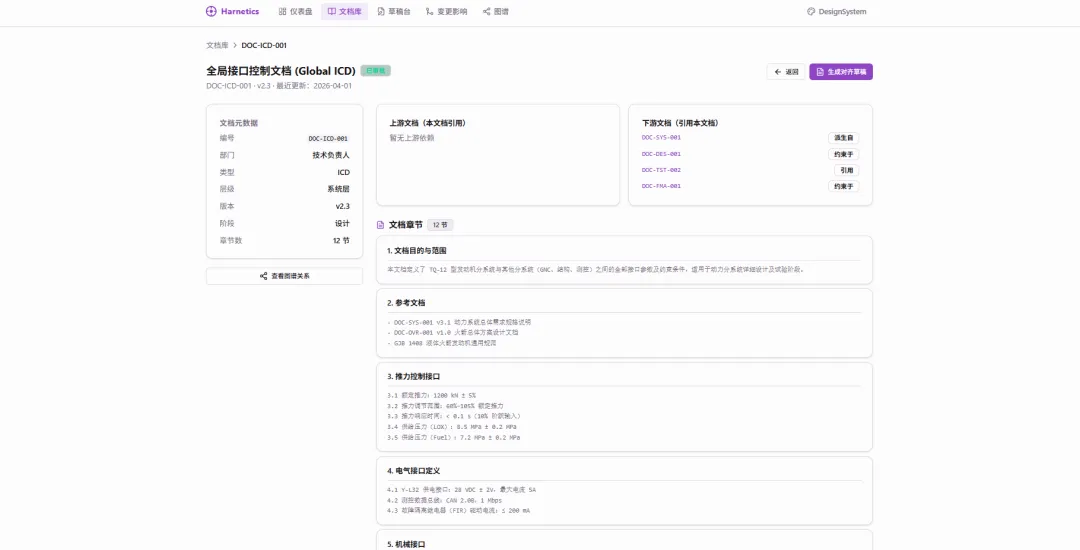
纵向是系统层级。任务需求分解到系统需求,系统需求分解到分系统指标,分系统指标再到单机规格。一条性能指标从上往下走,可能扇出三四条分支,分到不同部门。比如一条推力指标,分解到动力部是推力要求,到 GNC 部变成推力矢量控制精度要求,到结构部变成推力传递结构强度要求。三个部门,三份文档,来自同一条上游需求。
横向是工程流程。同一层级内,需求文档、设计文档、集成方案、测试大纲、验证报告之间要前后衔接。测试大纲要引用设计文档的接口定义,验证报告要追溯到需求条目。
纵向五层,横向五阶段,十二个部门。再加上版本——ICD 刚更新了 v2.3,动力部的设计文档可能还引用着 v2.1。不一定是忘了改,可能修订还在排期。但你不查就不知道。
目前的对齐方式就三种:邮件问、开会对、手动查。
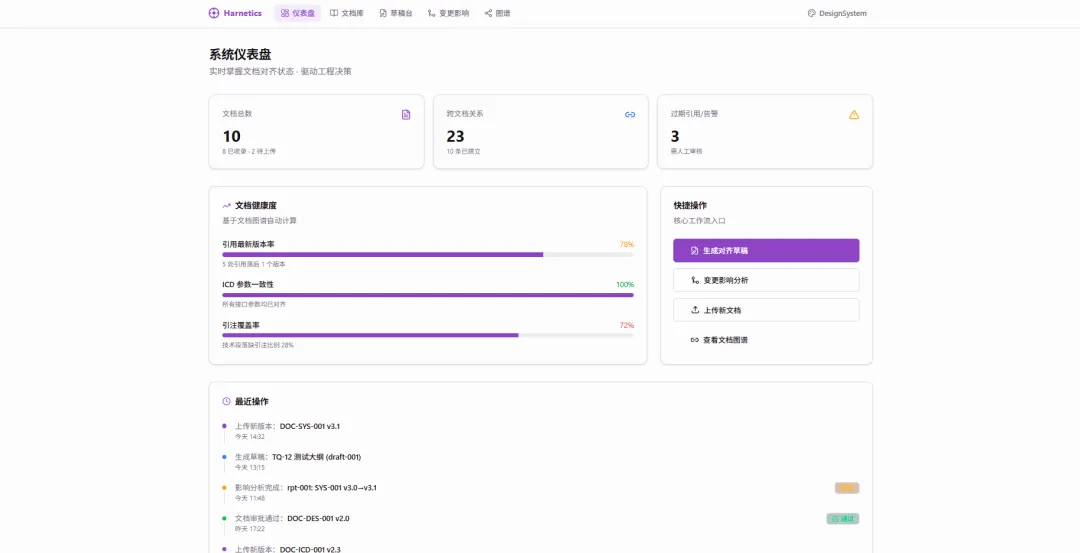
这不是信息化水平低的问题。PDM 和 OA 系统能管版本,但管不了文档之间的语义对齐。一份测试大纲里的某个测试项对应的是上游需求文档里哪条指标、ICD 里哪个参数,这种映射关系目前只存在一个地方——工程师的脑子里。对齐税是结构性的。 文档数量和部门数量的乘积决定了工作量。
关系网络比文档本身重要
访谈里让我最意外的不是"文档多"——这谁都猜得到。意外的是:文档之间的关系结构才是真正值钱的东西。
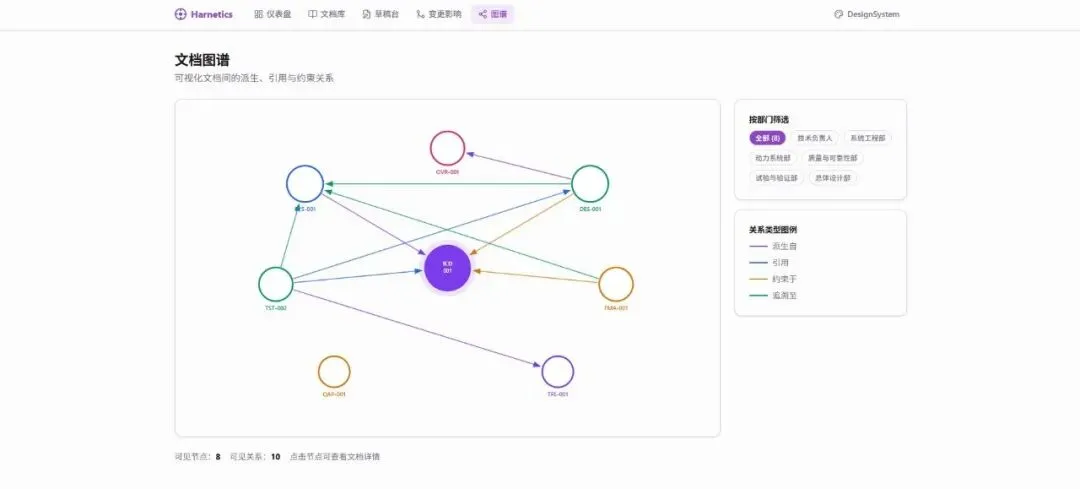
全局 ICD 被十二个部门引用,每个部门引用不同章节。系统级需求文档的一条指标分解到三个部门变成三条分支需求。测试大纲里的每个测试项对应一条需求和一组 ICD 参数。这些引用、追溯、约束、版本替代关系,构成了一张庞大的有向图。
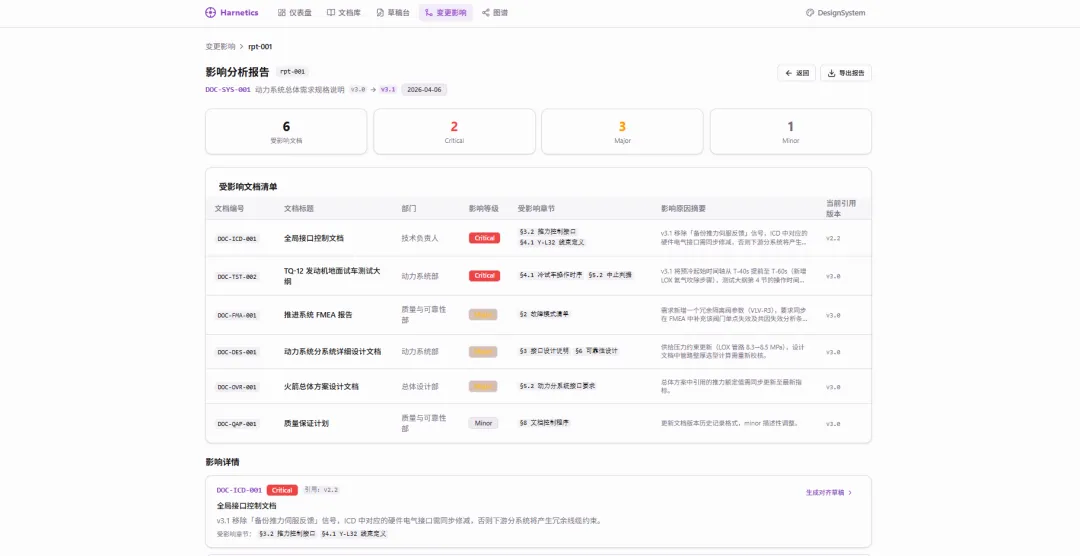
如果一条需求改了,下游三个部门都要更新。谁通知他们?谁检查他们更新了没有?
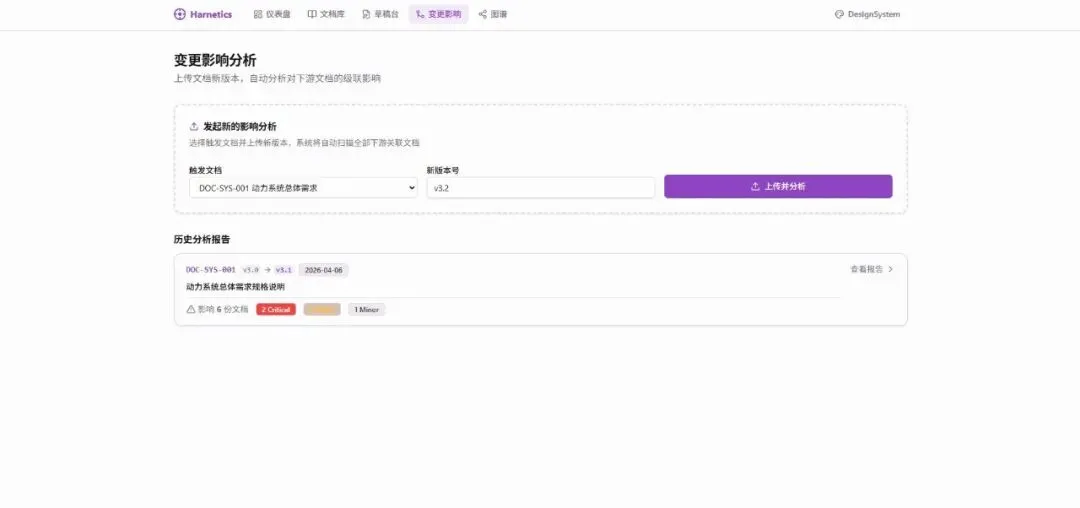
目前的答案是:没人。或者开会时顺便提一嘴。
这张关系网是隐性的,每个人脑子里有一张局部的图,但没有被任何系统完整维护。所以对齐这件事不可能一劳永逸——每次有人新写或修改一份文档,相关的对齐就要重新做一遍。
如果把这张网显性化——所有文档是节点,引用/追溯/约束/版本替代是边——你就有了一张文档图谱。 有了图谱,两件事就变得可以让机器做了。
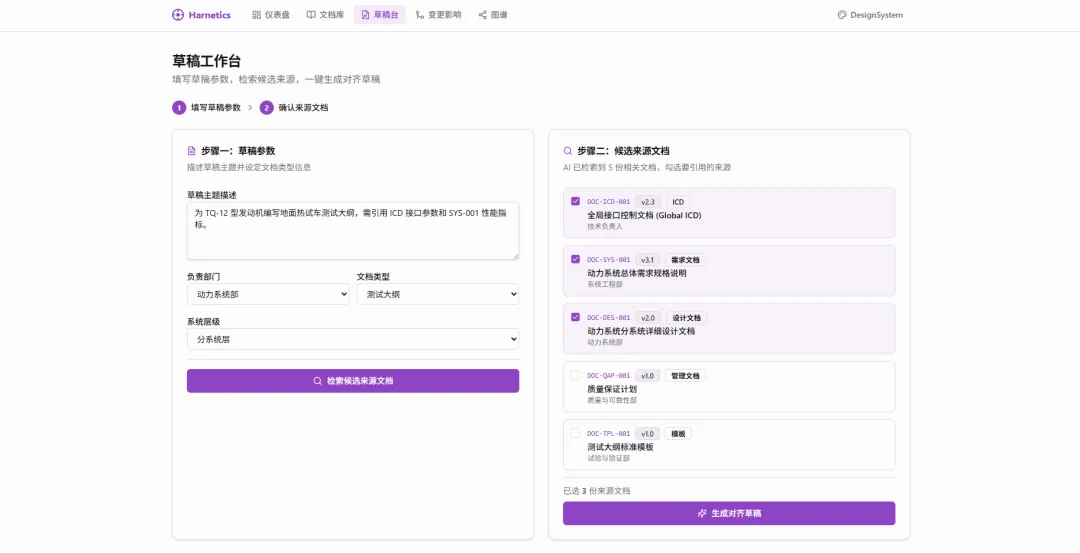
第一件,草稿生成。工程师说"我要写测试大纲",系统沿着图谱的边自动找到上游需求、ICD 约束、测试模板、历史类似文档,组装成带引注的初稿。每个技术指标旁边标注它来自哪份文档哪个章节。工程师审核修改,不用从空白页开始。
第二件,变更通知。ICD 改了一个参数,系统沿着边找到所有引用该参数的下游文档,列出受影响清单——哪个部门、哪份文档、哪个章节需要检查。不用群发邮件问"这个改动影响到你了吗"。
我做了这个东西
本文插图呈现的系统叫 Harnetics,一个 Harness-Agent 系统。Python 写的,开源。MVP 只做上面两件事。
技术栈不复杂:SQLite 存图谱关系,chromadb 做语义检索帮助定位相关章节,litellm 统一接本地大模型接口。所有数据本地跑——航天数据不上云,这是红线,没得商量。
设计上有一个决策值得说。
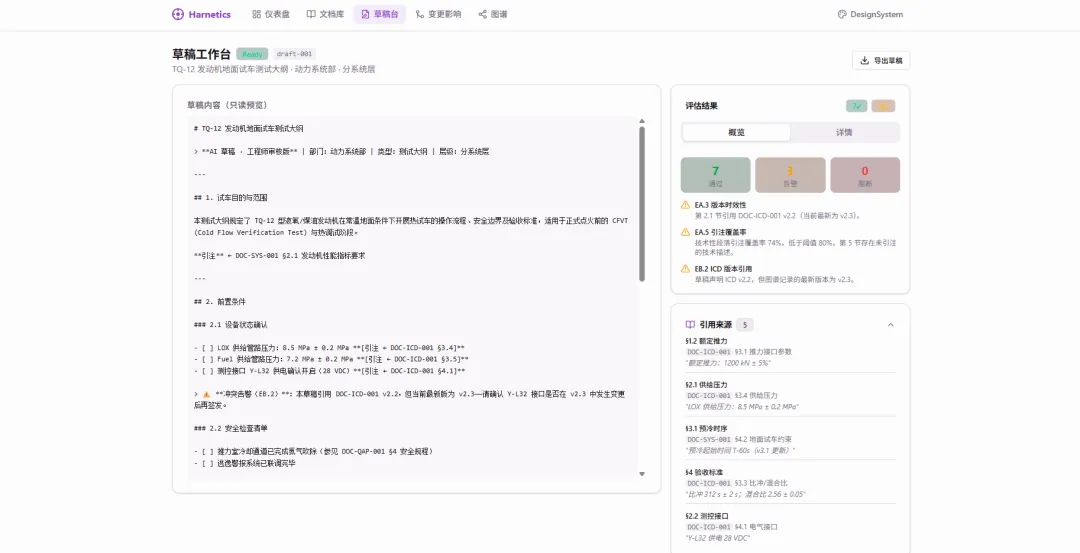
自动检查一共 14 项,分阻断和告警两级。阻断级:每个技术指标必须有来源引用、接口参数必须和 ICD 定义一致、不能有凭空捏造的数据——不通过就不能提交审核。告警级:引用版本是否最新、上级需求是否全覆盖——不阻止提交,但标出来让你知道。
为什么分两级?因为访谈中发现有些不一致不是错误,是版本时差。ICD 更新了,设计文档的修订还在排期,要是一刀切全阻断,工作流就堵死了。全放过又等于没查。阻断守底线,告警给提醒。 这是实际工作场景下的折中。
第一个验证场景选的是动力系统部的发动机地面试车测试大纲。理由:频率高、跨部门依赖明确、格式相对标准。需要对齐的上游文档只有四类——系统需求文档、全局 ICD、测试标准模板、历史类似测试大纲,加起来大概 10 份。够验证核心链路了。
目标很具体:
这个东西不做什么
坦诚讲几个边界。
它不做工程决策。测试方案怎么选、材料怎么定、设计怎么权衡,这些是工程师的专业判断。它也不替代审批流程——审批该怎么走还怎么走,它加速的是审批之前的准备工作。
它的前提是文档能被解析。Markdown、Word、Excel、PDF、YAML 都支持。但如果关键信息存在微信群聊记录或者口头默契里,图谱建不起来。
它也不是一步到位的。先在一个部门的一种文档上验证,跑通了再扩展。多项目多型号支持、对接 DOORS/PDM,都是后面的事。
说白了,它就是个润滑剂。降低文档在部门之间流转时的摩擦力。不替代人,不替代流程。
我的伙伴 Win 说了句很精准的话:在这个产品里,数据就是文档,重心在于数据怎么流转。
如果你在商业航天公司做系统工程、AIT、试验验证、质量管理,你每天都在交对齐税。这个项目想做的事很简单:把其中一部分从人工成本变成机器成本。
PS. MVP 版本准备上线 Github仓库,欢迎关注加群追踪进度
审校:Win

