 夜雨聆风
夜雨聆风
导读在数据驱动业务的背景下,快手生活服务数据中心作为新兴且高速发展的业务支撑部门,面临着需求激增与人力有限的核心矛盾,传统数仓建设模式中的烟囱式建设、需求交付低效、数据质量管控难等问题日益凸显。本次分享将围绕快手生活服务数据中心基于 AI Agent 的数仓智能化建设展开,介绍项目背景、核心实践、落地效果及未来规划,为同类场景下的数仓研发提效提供参考。
1. 项目背景
2. 数仓 AI Agent 的核心实践(智能评审、智能 DQC、智能客服)
3. 项目落地效果
4. 未来规划
5. 问答环节
分享嘉宾|潘广远 快手 快手生活服务数据中心架构师
编辑整理|曲洋
内容校对|郭慧敏
出品社区|DataFun
01
项目背景
1. 业务特点&核心矛盾
快手生活服务业务线成立于 2022 年,相较于快手其他成熟业务线,具有三大显著特点:一是业务新颖,处于快速探索阶段;二是发展迅猛,每日不断迭代新玩法、新功能,业务复杂度持续提升;三是业务边界拓展,2024 年组织架构升级后,业务范围从团购延伸至线索广告等领域,需求规模呈爆发式增长。
自业务线成立以来,数据需求总量已增长 7 倍,但数据研发团队规模始终维持在 10 人左右,核心矛盾集中在“如何以有限人力高质高效交付业务需求,同时保障数仓建设质量”。

2. 传统数仓建设痛点&传统解决方案的局限性
传统数仓建设模式下,团队面临三大核心问题:一是烟囱式建设,研发人员各自为战,导致数据口径不统一、字段及表级重复建设严重,维护成本极高;二是需求交付效率低,业务需求增速远超研发交付能力,供需缺口持续扩大;三是数据质量管控难,数据质量作为数仓生命线,偶发的低级错误仍会造成严重影响,且质量问题溯源及整改成本高。
为应对上述问题,团队最初从四个方面的环节保证质量,分别是:
制定流程规范
质效指标监督
上线前评审
定期 review & 治理
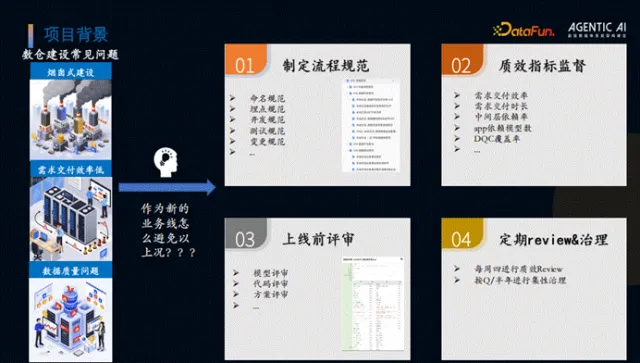
具体内容为:制定了完善的流程规范,包括命名规范、埋点规范、开发测试规范等,建立了需求交付效率、需求交付时长、中间层依赖率、app 依赖模型数、DQC 覆盖率等效能指标,要求上线前完成模型、代码评审及方案评审,并通过每周直销 Review、按季度/半年集中治理的方式管控质量。
但实践后发现效果不及预期:流程规范执行不到位,需求压力大时易跳过评审环节;评审阶段人力消耗大(每月约 50 人日)且依赖架构师经验导致质量不可控;集中治理周期长、下游依赖多,陷入“边治理边污染”的恶性循环。基于此,团队转向探索 AI 驱动的智能化解决方案。

02
数仓 AI Agent 的核心实践
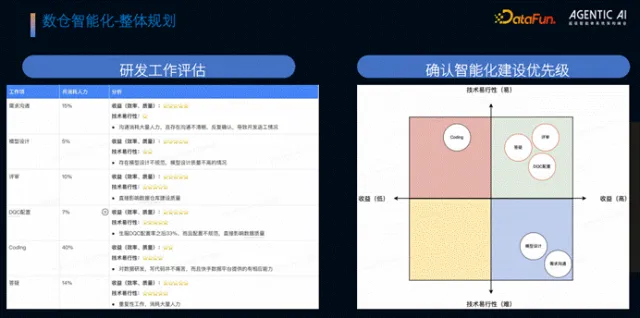
1. AI 应用场景评估
团队从收益高低与技术可行性两个维度,对数仓研发各环节进行评估,最终确定核心突破方向:评审(收益最高、技术可行性最高)、DQC 配置(数仓质量核心,需求迫切)、答疑(重复工作多,人力消耗大);暂不优先投入需求沟通(实现难度极高)、模型设计(实现难度高)、编码(平台已有基础能力,人力占用高但难度低)。
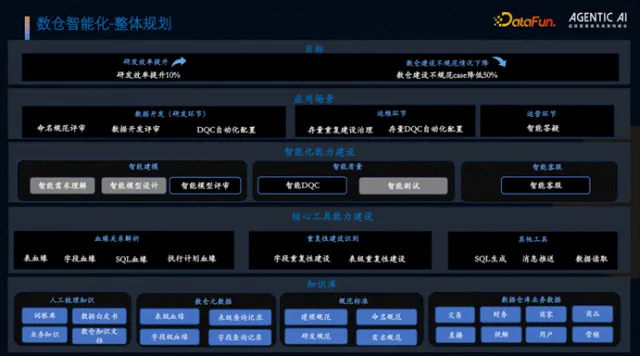
2. 整体规划
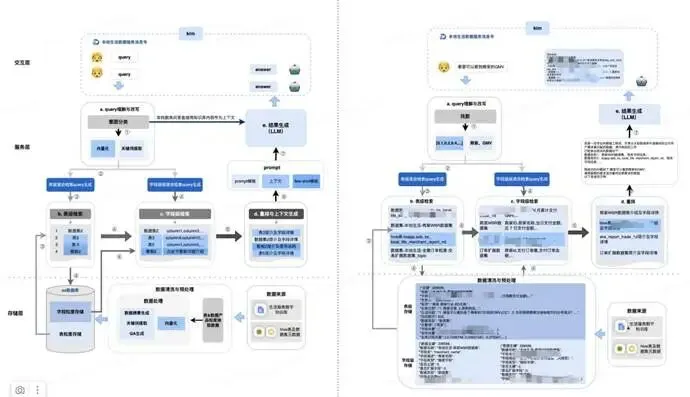
项目核心目标是通过智能化产品实现研发人效提升 10%,数仓建设不规范案例减少 50%。整体架构分为三层:底层为知识库梳理,涵盖人工梳理词根、数据白皮书、业务知识、数仓元数据、标准规范及脱敏后的业务数据;中间层为核心工具能力建设,包括血缘解析、重复建设识别等工具;顶层为智能化能力构建,涵盖智能建模、智能质量、智能客服三大模块,最终应用于数据开发、运维及运营全环节。
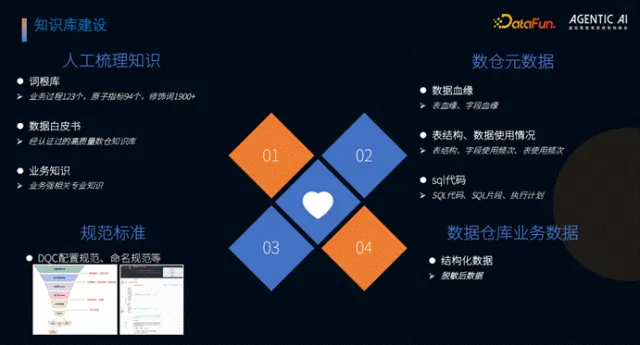
3. 知识库建设
知识库是智能化能力的基础,团队从四方面完成建设:一是人工梳理词根体系,沉淀业务过程词根 123 个、原子指标词根 94 个、修饰词词根 1900 余个,为语义一致性提供支撑;二是编制数据白皮书,耗时三个月梳理高质量数仓知识库,作为核心知识来源;三是整合元数据,包括表/字段血缘、使用频次、资产等级、SQL 代码及执行计划等,并新增 SQL 片段切分能力;四是规范标准体系,明确 DQ 配置、命名等各类规范,同时对业务数据进行脱敏处理,规避数据安全风险。
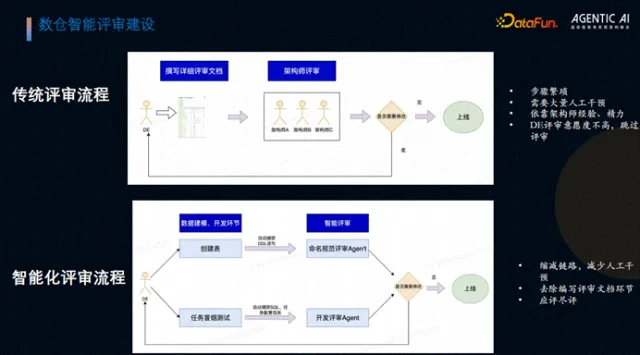
4. 数仓智能评审建设
(1)评审流程优化
传统评审需研发人员撰写评审文档,再约3名架构师评审,流程低效、人力消耗大,且研发人员为赶进度易跳过评审,导致数仓出现语义混乱、重复建设等问题。例如,多名研发人员设计的表存在命名差异但核心内容一致、维度语义模糊、指标命名不统一等情况,给数据使用和维护带来极大困扰。
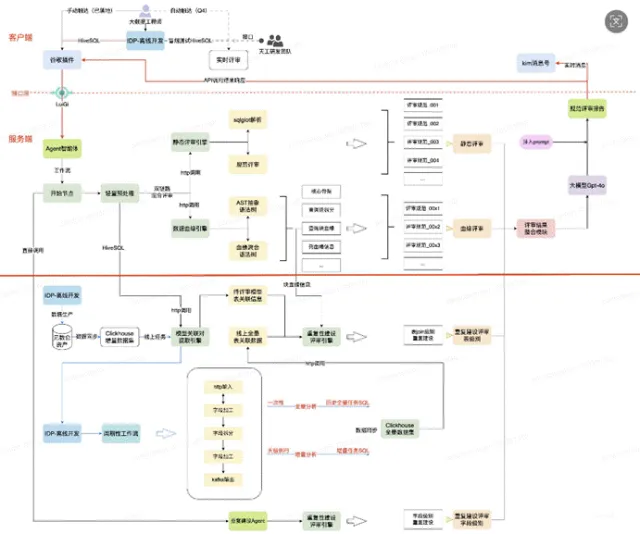
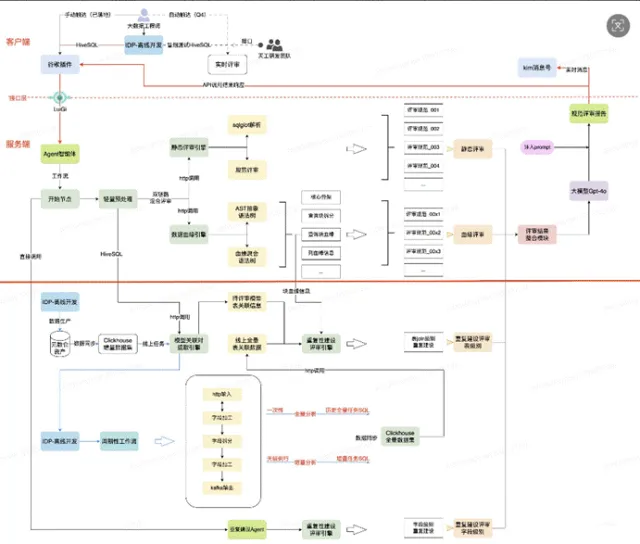
团队将评审流程与数据研发链路深度绑定,去除低效的文档撰写和人工评审环节,基于研发必交付的 DDL 语句和 SQL 代码(涵盖 80% 以上评审项),拆分出两条评审链路:一是命名规范评审,保障数仓语义一致性;二是开发评审,校验 SQL 代码质量。评审异常结果通过 Kim 消息推送至研发人员,实现“应评尽评”,强制规范执行。
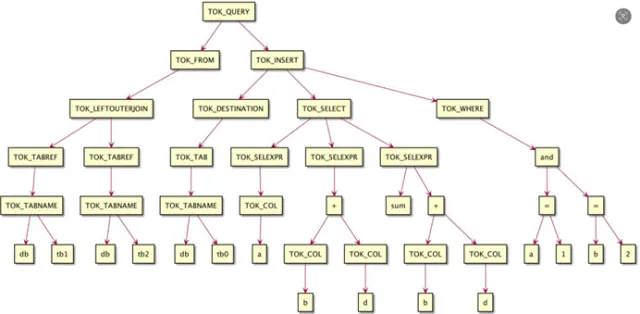
(2)核心工具库建设
重点建设两大工具库:一是 SQL 血缘解析工具,将 SQL 抽象为语法树并层层解析,获取代码块层级及列血缘路径,同时清洗执行计划以匹配引擎操作动作,满足深层评审需求;二是重复建设识别工具,基于血缘解析结果,通过相似度算法识别字段级重复建设,结合大模型二次确认,通过执行计划判断表级重复建设。

5. 智能评审-模型命名规范评审
团队将评审任务拆分为原子级别,构建多类 Agent 并通过 Workflow 串联:包括维度评审 Agent、原子指标评审 Agent、派生指标评审 Agent、表名规范评审 Agent。自动捕获用户的 DDL 语句后,按类型路由至对应 Agent,Agent 调用知识库并结合提示词,由大模型输出评审结果及优化建议。
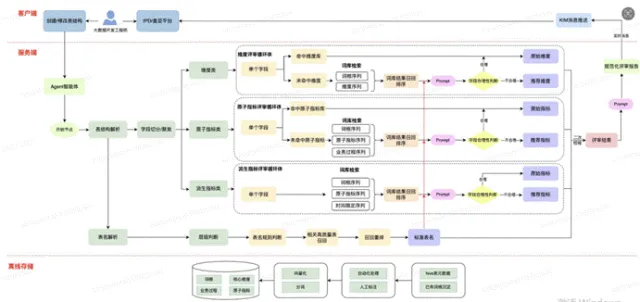
以下是一个案例:DDL 语句缺少时间周期、缺少中文注释,在修饰词、原子指标、度量顺序上有错乱的情况。我们给出了修正后的 DDL 语句和修改原因总结。目前以周为维度跟踪统计效果为:命名规范评审推荐准确率达 85%,执行率达 90%。

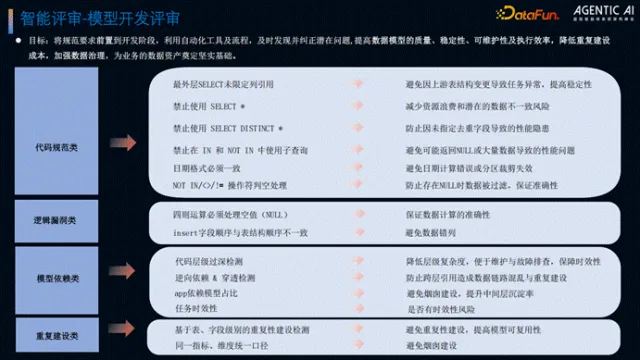
6. 智能评审-模型开发规范评审
代码评审聚焦四类问题:一是代码规范类,校验是否使用 SELECT *、日期格式是否一致等性能及规范问题;二是漏洞类,检查四则运算空值处理、INSERT 顺序与表结构一致性等;三是模型依赖类,管控代码层级、逆向/穿透依赖、APP 依赖模型数量(要求为 70%)及任务时效性风险;四是重复建设类,对比历史代码识别字段及表级重复建设。通过 SQL 结构化解析后输入大模型,结合知识库生成评审意见及优化建议,推送至研发人员整改。
为了解决大模型在直接处理长篇 SQL 时可能出现的“胡说八道”问题,采取了先结构化再评审的策略 。
输入层:自动捕获用户提交的非结构化 SQL 代码 。
解析引擎:利用核心工具能力,将非结构化 SQL 抽象为语法树,解析出代码块层级、列血缘路径以及执行计划等结构化数据 。
知识支撑层:整合模型开发规范、评审规范提示词(Prompts)以及存量代码知识库 。
智能评审层:由大模型 Agent 结合结构化元数据与知识库,进行多维度的逻辑判断。
实现过程主要聚焦于将复杂的代码逻辑转化为 AI 可理解的规则,并进行深度比对:
SQL 结构化处理:针对用户千奇百怪的编写习惯(如深层子查询、With 语句),通过工具将其解析为列引用、层级、代码块等结构化信息 。
代码规范类:检测是否使用了 SELECT *、日期格式是否统一、是否影响性能
逻辑漏洞类:识别四则运算是否漏掉空值处理、INSERT 顺序与表结构是否一致 。
模型依赖类:监控代码层级深度、是否存在逆向依赖或穿透依赖,以及 APP 层对中间层模型的依赖率(要求达到 70% )。
重复性检测:基于解析出的血缘解析结果,与历史全量代码进行相似度算法比对,识别字段级和表级的重复建设 。
反馈机制:评审结论通过 KIM 消息实时推送给研发人员(DE),并自动生成优化建议(如建议沉淀到某张存量表中)。

通过引入 AI Agent 评审,该部门在提升数仓质量方面取得了显著数据:
重复建设识别:能够有效识别出 90% 的重复建设情况,目前已识别并正在治理 900 多个重复建设项 。
规范化提升:消除了 90% 的命名不规范情况,确保了数仓语义的严格一致性 。
人效释放:相比人工评审(每月消耗约 50 PD 人力且易跳过评审),AI 评审实现了“应评尽评”,整体项目人效提升了约 11.34% 。
7. 智能DQC配置
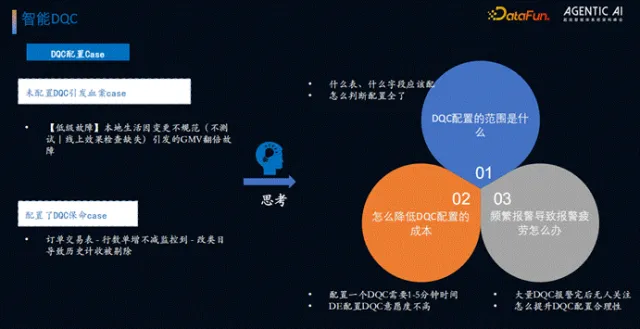
(1)DQC 核心痛点
DQC 作为数仓质量生命线,存在三大问题:一是配置范围不明确,部分表/字段未配置 DQC 导致质量事故(如主键重复导致 GMV 数据翻倍错误);二是配置成本高,单条 DQC 配置需 1-5 分钟,研发人员配置意愿低;三是无效报警多,大量报警无人关注,掩盖核心风险。
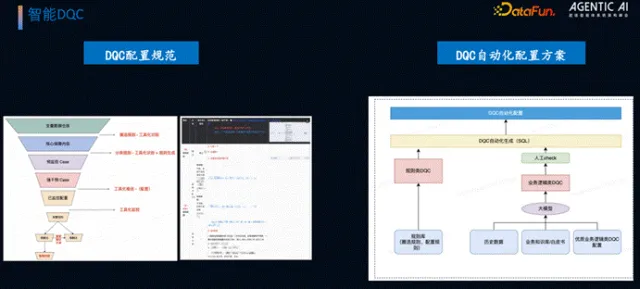
(2)智能化解决方案
团队将 DQC 分为两类针对性处理:一是规则类 DQC,基于预设规则及 SQL 模板自动生成并配置,无需智能能力介入;二是业务逻辑类 DQC(如曝光次数大于点击次数、分项补贴金额之和等于总补贴金额),基于历史优质 DQC 配置、业务白皮书及历史数据,通过大模型生成规则,经人工校验后自动化配置,且此类 DQC 触发后直接阻断流程,保障数据质量。
8. 智能客服
采用 RAG 架构,核心优化方向是提升问答准确性,而非技术创新。通过优质数据白皮书、全量元数据(表/字段血缘、描述、使用频次等)构建高质量知识库,由大模型预生成 QA 对;结合用户意图识别(找表、找字段、找报表),通过二阶段检索(表+字段检索)召回相关信息,经重排序后由大模型生成最终答案。
智能客服在找表找数类需求中,接受率达 93%,准确率达 90%,大幅减少重复答疑人力消耗。
03
项目落地效果
通过上述智能化实践,团队在多维度取得显著成效:评审层面,命名规范不规范情况消除 90%,重复建设识别率达 90%,评审准确率达 90%;治理层面,识别出 900 余个重复建设案例,正在推进集中治理;DQC 层面,配置率从 33% 提升至 90%,有效降低质量风险;编码层面,AI 生成编码覆盖率达 20.83%;答疑层面,找表找数需求准确率达 90%。综合测算,研发人效提升 11.34%,超额完成核心目标。

04
未来规划
团队将从三方面深化智能化建设:一是建模层面,探索模型高内聚低耦合、易用性、扩展性的智能评价方法,攻克需求理解痛点,将业务需求自动转化为标准指标维度矩阵;二是质量层面,新增 DQC 巡检能力,对报警分类归因、锁定高风险项,构建自动化智能测试能力,校验主键一致性、行数、指标波动等;三是客服层面,拓展业务类问题解决方案,针对口径不一致、数据不可见等问题提供智能化解答。

05
问答环节
Q1:对于数据治理基础较薄弱、指标管理尚处空白的企业,应如何开展研发提效工作?
核心是先建立标准规范,从数仓建设初期梳理词根及命名规范,降低后续重构与治理成本;基于基础规范搭建简单工作流,借助大模型开展初步评审,虽准确率有限,但可有效规避基础不规范问题,逐步积累后再推进深度智能化能力。
Q2:在智能评审阶段需要大量的知识信息(如原数据、SQL、执行计划等),这些内容是直接放入知识库还是通过其他方式处理?
词根及历史存量代码需纳入知识库,支撑重复建设识别;标准规范可写入提示词;其他内容根据场景判断归属,优先保障核心知识的准确性。采用每日增量更新模式,自动捕获新任务的代码及执行计划,全量初始化至知识库。
Q3:当内部存在大量重复建设或不规范情况时,如何实现高准确率的“找数/问数”?
技术与业务结合:准确率往往不仅由技术决定,数仓本身的规范性是前提 。
白皮书策略:建议花费精力梳理一套高质量的数据白皮书 。检索优先级:在大模型检索时,设置优先级:优先检索白皮书(解决约 50% 核心资产问题,确保极重要场景不出错),检索不到时再检索原数据 。
Q4:数据白皮书和知识库在需求更迭中如何保持持续迭代?
更新频率:目前主要按月度周期进行人工迭代 。数据来源:利用项目管理平台上的规范需求文档,以及研发人员(DE)对业务和数据资产建设的总结 。

分享嘉宾
INTRODUCTION

潘广远

快手

快手生活服务数据中心架构师

10 年+的数据仓库从业经历,先后就职于京东、阿里、快手,在数据仓库建设、数据仓库治理方面积累了丰富经验,热衷于探索 AI 在数据仓库中的应用。

往期推荐
阿里云 EMR Serverless Spark + DataWorks 技术实践:引领企业 Data+AI 一体化转型

点个在看你最好看
SPRING HAS ARRIVED

