 夜雨聆风
夜雨聆风和OpenClaw聊天,聊着聊着他就‘失忆’了,你想跟他分享一件花了一个月才做完的事,结果他说:你在说什么?虽然他已经有设计Memory架构但是还是会选择性的遗忘很多记忆,并且新的对话中,他大部分情况下不会选择先读取记忆再跟你聊天,那能不能给他装个笔记本,让我们在提到具体的事的时候他可以通过翻笔记本查到?
多维表格可以完美契合这个需求,它可以实现把你和AI交流的东西转换成结构化数据存起来,作为一个INFJ,实在没办法拒绝这样的工具,现在它已经变成了我日常和工作中的一大利器。
那么如何在OpenClaw中配置飞书多维表格,实现数据写入、任务记录与自动化同步?分别按照以下步骤分享一下:
/1 前置准备
开始前,先确认以下条件已经满足。
已有可用的飞书账号。
本地或服务器端已完成 OpenClaw 的安装。
创建飞书应用、创建多维表格以及配置应用权限的操作权限。
/2 创建飞书应用
(1)打开飞书开放平台,创建企业自建应用。
应用名称可以按用途命名,如:大聪明
(2)创建完成后记录应用的App ID与App Secret。
这两项是后续获取tenant_access_token的基础凭证。
App ID: cli_xxxxxxxxxxxxxApp Secret: xxxxxxxxxxxxxxxxxxxxxxxx
飞书的调用链路通常是:应用凭证换取访问令牌,再通过访问令牌调用多维表格接口。这样做的好处是便于权限隔离、凭证轮换与访问控制。
/3 配置应用权限
在飞书开放平台的应用详情页进入“权限管理”,为应用申请多维表格相关权限。
权限类型 | 建议用途 | 说明 |
读取类 | 读取表格结构与记录 | 用于获取表格信息、字段配置等 |
写入类 | 新增或编辑记录 | 用于把 OpenClaw 的结果写入多维表格 |
消息发送 | 发送提醒或通知 | 用于任务提醒、同步成功通知等场景 |
权限配置完成后,需要创建版本并发布应用。若审批被拒,通常是因为申请范围过大。实践中更稳妥的方式是只申请当前场景必须的权限,并优先限定到指定成员或仅自己可用。
以上三点可以参考另一篇文章:如何配置OpenClaw。
/4 创建多维表格
打开https://my.feishu.cn/base在飞书中新建多维表格。
按照需要设计字段结构。字段一定要设计合理,不然后面的数据存储就会比较麻烦。例如:
字段名 | 字段类型 | 必填 | 用途说明 |
日期 | 日期时间 | 是 | 记录写入日期 |
工作内容 | 多行文本 | 是 | 记录工作事项 |
会议内容 | 多行文本 | 是 | 记录学习内容 |
未完成事项 | 多行文本 | 否 | 待处理事项 |
/5 获取表格信息(重点)
接入 OpenClaw 之前,需要先拿到多维表格的app_token和table_id。最直接的办法是从多维表格的URL中提取。
https://my.feishu.cn/base/NeXXXXXXXXXXXXXXXXXXXXXXh?table=tXXXXXXXXXXX3└──────── app_token ──────┘ └─ table_id ─┘
如果需要通过接口查询,也可以先获取tenant_access_token,再调用表格列表接口,列出指定app_token下的所有数据表。
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables"headers = {"Authorization": f"Bearer {tenant_access_token}"}resp = requests.get(url, headers=headers)
正式集成前先做一次连通性测试,确认令牌获取、表格读取以及字段识别都没有问题,可以让bot测试。
APP_ID = "cli_xxxxxxxxxxxxx"APP_SECRET = "your_app_secret"APP_TOKEN = "your_app_token"TABLE_ID = "your_table_id"
/6 在OpenClaw中集成
实际接入时,可以在OpenClaw的脚本目录中放置一个独立的同步脚本,例如 feishu_bitable_sync.py。这个脚本负责三个动作:获取访问令牌、组装字段、写入记录。
这里可以让Openclaw自己来创建并且把‘分析输入并同步内容到表格’、‘分析并输出表格内容’等这些需要的操作做成skill,这样每次使用多维表格的时候都调用skill就可以了,保证了任务执行的稳定性。
def get_tenant_access_token():url = f"{BASE_URL}/auth/v3/tenant_access_token/internal"payload = {"app_id": APP_ID, "app_secret": APP_SECRET}resp = requests.post(url, json=payload)data = resp.json()if data.get("code") != 0:raise Exception(f"获取 token 失败: {data}")return data.get("tenant_access_token")def create_record(token: str, fields: dict):url = f"{BASE_URL}/bitable/v1/apps/{APP_TOKEN}/tables/{TABLE_ID}/records"headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"}payload = {"fields": fields}resp = requests.post(url, headers=headers, json=payload)result = resp.json()if result.get("code") != 0:raise Exception(f"创建记录失败: {result}")return result.get("data", {}).get("record", {}).get("record_id")
写入字段时,日期字段统一使用毫秒级时间戳;多选字段传数组;单选字段传对应选项值。只要表格中的字段名称与脚本里的字段键保持一致,后续写入就比较稳定。
/7 示例:每日工作记录
我目前的做法是定时任务+skill调用实现每日内容的格式化同步。
(1)让OpenClaw每天定时提醒我填写内容。
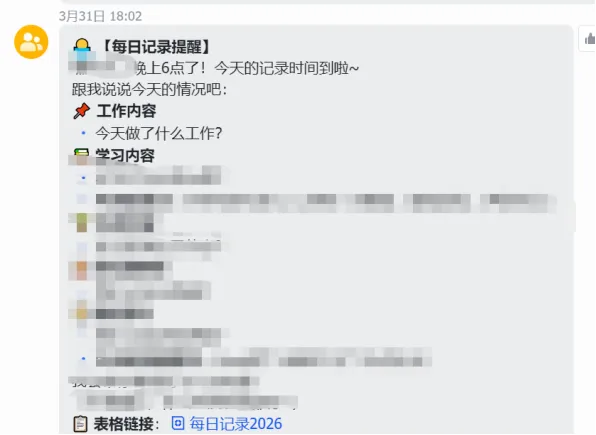
- name: "每日工作"schedule:kind: "cron"expr: "2 18 * * *"tz: "Asia/Shanghai"sessionTarget: "main"wakeMode: "next-heartbeat"payload:kind: "systemEvent"text: "每日记录时间到啦!今天的工作内容分别是什么?"
(2)OpenClaw收到回复后,调用上一步封装的skill,通过一个解析脚本把自然语言拆成结构化字段,再调用同步函数写入飞书。即使最初只做简单的规则解析,也足够支撑多数日常工作场景。
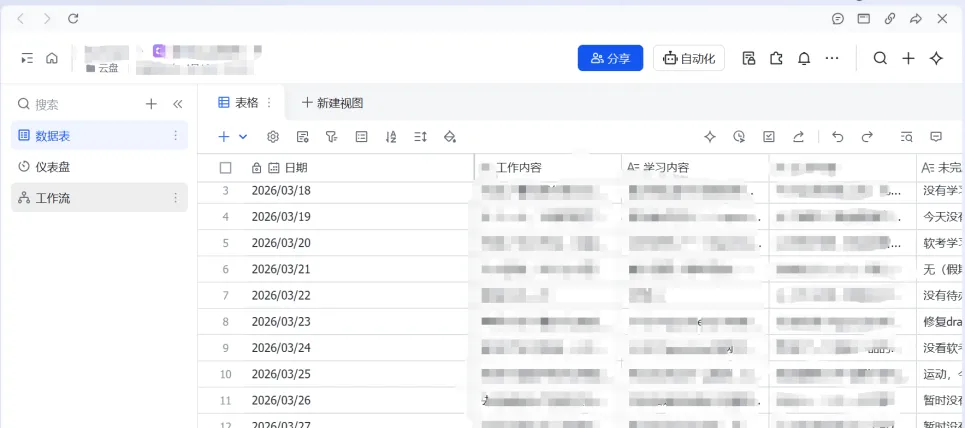
这里只是一个简单的例子,打通飞书表格之后还会有很多提效场景,比如我用邮箱+飞书多维表格识别实现了定期回顾等,其他场景还请欢迎大家多多交流。
/8常见问题
问题 | 常见原因 | 处理方法 |
获取 token 失败 | App ID 或 App Secret 配置错误;应用未发布 | 检查凭证是否复制准确,并确认应用已发布 |
无权限写入表格 | 应用没有编辑权限;未被加入表格协作者 | 在表格共享设置中把应用加入协作者并授予编辑权限 |
字段不存在 | 字段名不一致;字段类型不匹配 | 核对字段名称、大小写和字段类型 |
日期显示异常 | 使用了秒级时间戳或时区处理不当 | 统一使用毫秒时间戳并确认时区配置 |
/9总结
整个接入流程可以概括为:创建应用、配置权限、设计表格、获取参数、测试连接、编写同步脚本、接入定时或触发器。把多维表格当作结构化数据底座,OpenClaw负责写入、解析和提炼,这种方式可以覆盖记录、同步、回顾和分析四个环节,相当于给OpenClaw又加了一个外挂知识库。
小郭 | 半吊子AI学习中
分享AI知识科普&学习心得相关,不定时更新
致力于把感兴趣的一切都用好玩的方式说出来
谢谢关注:
