 夜雨聆风
夜雨聆风最近刚好有个业务场景需要对用户提问进行澄清式追问,调研了一下现在的一些方法,觉得Amazon给出的这一套很不错,分享给大家~
想象这样一个场景:你去找客服机器人,输入了一句话——
"耳机有连接问题"
这短短六个字,藏着多少种可能的含义?是蓝牙配对失败?是有线接口接触不良?是 iOS 连不上还是安卓连不上?耳机是哪个品牌?
一个不够聪明的客服机器人,会直接从知识库里捞出排名最高的几篇文档,然后大概率捞到"蓝牙连接问题"相关的内容(因为这类问题最多),然后对用户说:"您好,请尝试重新配对蓝牙……"
但如果用户用的是有线耳机呢?机器人给出的解决方案完全答非所问,用户只好重新描述一遍,体验极差。
这就是任务型对话系统(Task-Oriented Dialogue, ToD)中一个非常核心的难题:查询歧义(Query Ambiguity)。
这篇来自 Amazon 的论文 AsK(Aspects and Retrieval based Hybrid Clarification) 提出了一种聪明的混合式澄清框架,在 ACL 2025 工业轨道发表。它的目标是让 AI 在恰当的时机、以恰当的方式向用户提问,而不是漫无目的地追问,也不是闷头给出错误答案。
二、AsK 的核心思路:根据歧义程度动态路由
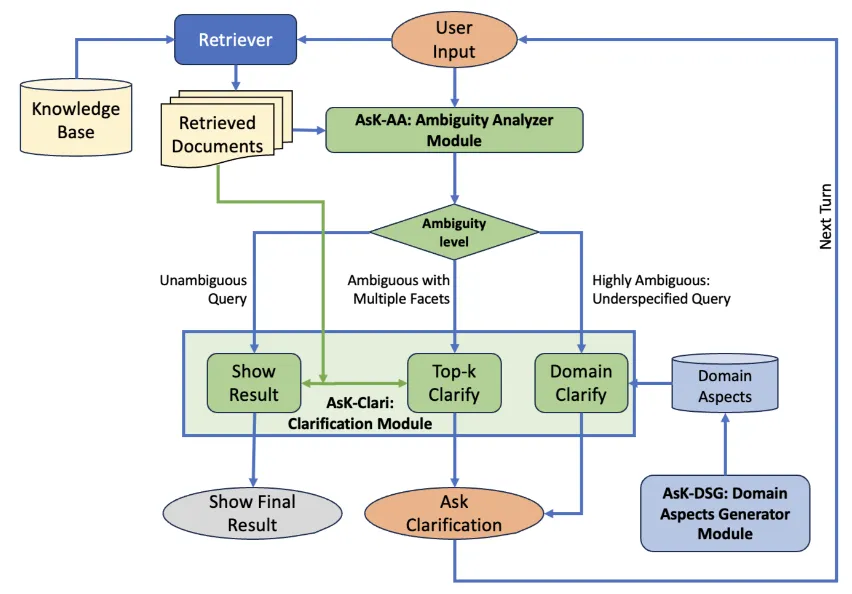
AsK 框架的核心洞察非常直觉:
歧义高的时候,应该从更广的领域知识来问;歧义低的时候,应该从检索到的文档来问;歧义非常低的时候,直接给答案就行。
为了实现这个"路由"逻辑,AsK 定义了三种查询状态:
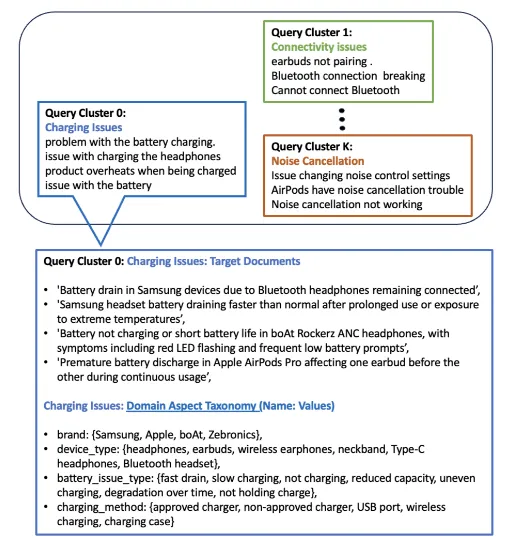
"领域维度"是什么?
以耳机为例,影响用户问题定性的关键维度包括:
连接类型:(有线 / 无线蓝牙)
品牌:(Samsung / Apple / Sony……)
故障类型:(充电问题 / 配对问题 / 音质问题……)
充电方式:(USB-C / 无线充电盒……)
这些就是"领域维度"——当用户查询模糊时,对准这些维度提问,能最有效地缩小解决方案范围。
人工标注?不现实。
不同的产品品类有完全不同的方面体系,手动为每个品类标注一套这样的体系成本极高,而且难以更新维护。
AsK 的解法:用 LLM + 聚类自动生成。
具体流程是:
1. 查询聚类
把历史用户查询用 Cohere 多语言嵌入模型转化为向量,然后用凝聚层次聚类(Agglomerative Clustering)自动分成若干"问题类型"簇。比如耳机问题可能聚出"充电类"、"连接类"、"音质类"等簇。聚类不需要预先指定簇的数量,而是通过设置距离阈值自动确定。
2. 文档抽取
对每个簇,找出对应的目标文档(即历史上真正解决了这类问题的知识库文档)。
3. LLM 提炼方面
这样生成的方面体系粒度适中:既不像"产品所有属性"那么宽泛,又不像"单个文档关键词"那么狭窄,而是针对特定问题类型的精准区分维度。
四、模块二:歧义分析器(AsK-AA)
这是整个框架最关键的模块,分类器选用的是Longformer模型。
它的任务是:输入用户查询 + 检索到的 Top-k 文档,输出一个三分类结果(show-result / topk-clarify / domain-clarify)。
为什么选 Longformer?
用户查询 + Top-k 文档拼在一起,文本很长,超过了 BERT 的 512 token 限制。Longformer 支持最长 4096 个 token,正好适合这个任务。
最难的问题:训练数据从哪来?
论文不假设任何已标注的"歧义等级"数据——这种数据在现实中几乎不可能大规模获取。AsK 的解法是弱监督(Weak Supervision)。
思路是:从现有的检索数据集(只有"用户查询→目标文档"映射)中,自动推导出歧义信号:
- 信号一:
num-aspects(q)——用 LLM 判断这个查询里明确说明了几个领域维度。一个写明"蓝牙耳机充电问题"的查询,已经包含了连接类型和问题类型,属性丰富,歧义低;而"耳机有问题"几乎没有任何方面信息,歧义高。 - 信号二:
retrieval-rank(q)——目标文档在检索结果中排在第几。如果正确文档排名很靠前,说明检索系统能准确理解这个查询(歧义低);如果正确文档排名很靠后甚至不在 Top-k 里,说明查询太模糊,检索系统也被弄晕了(歧义高)。
结合这两个信号,论文训练了一个决策树,自动确定三分类的阈值,然后给全量训练数据打上弱标签,再用这些弱标签训练 Longformer 分类器。
整个流程不需要人工标注一条歧义数据,完全自动化。
五、模块三:澄清问题生成(AsK-Clarify)
有了歧义分析器的分类结果,就可以选择对应的澄清策略:
高歧义(domain-clarify):从领域维度库中选最有区分力的方面来提问。提示词会要求 LLM 选择"能最大幅度降低当前 Top-k 文档歧义度的那个方面",并给出穷举的选项列表。
中等歧义(topk-clarify):把 Top-k 文档作为上下文,让 LLM 归纳出文档间的关键差异,据此提问。
基于上述思路,论文还提出了三个澄清问题生成变体:
- AsK-SR(软路由)
把领域维度知识、top-k文档、歧义分类都传给 LLM,让它自己决定参考哪方面的信息进行生产。 - AsK-CM(合并模式)
把领域维度知识、top-k文档都传给 LLM,但不告诉它当前歧义分类,让 LLM 生成自由发挥。 - AsK-HR(硬路由)
严格按照歧义分析器的分类,要么只用领域维度知识,要么只用 Top-k 文档,二选一,互不干扰。
实验证明 AsK-HR 表现最好——明确的策略选择比模糊的"两者都用"更有效。
六、实验结果:效果有多好?
论文在两个数据集上做了评测:
PT(Product Troubleshooting,产品故障排查):Amazon 内部真实客服对话数据,约 19,433 条训练查询,2,858 篇知识库文档。
PS(Product Search,产品搜索):ESCI 公开数据集(耳机、手机、音响品类),约 11,432 条训练查询,3,454 篇文档。
实验结果:
单轮澄清和多轮对话都取得了不错的效果,详情见原文(论文地址见文末原文链接)!
澄清问题和选项的相关性评分也全面领先,说明 AsK 不只检索效果好,生成的问题本身质量也更高。
消融实验也证实了两个信号缺一不可:去掉领域维度计数信号(num-aspects)或去掉文档排名信号(retrieval-rank),模型性能均有下降,尤其是后者对高歧义类别的影响更大。
七、工业落地效果
Amazon 在真实电商客服系统中部署了 AsK,经过 4 周 A/B 测试,覆盖六个产品品类:
用户自助解决率提升 35%(更多问题被用户自己解决,无需转人工)
人工客服接触量下降 12.7%
退货率降低(用户问题被更准确地识别和解决)
这些数字在工业系统中非常实在,也验证了论文方法的实际价值。
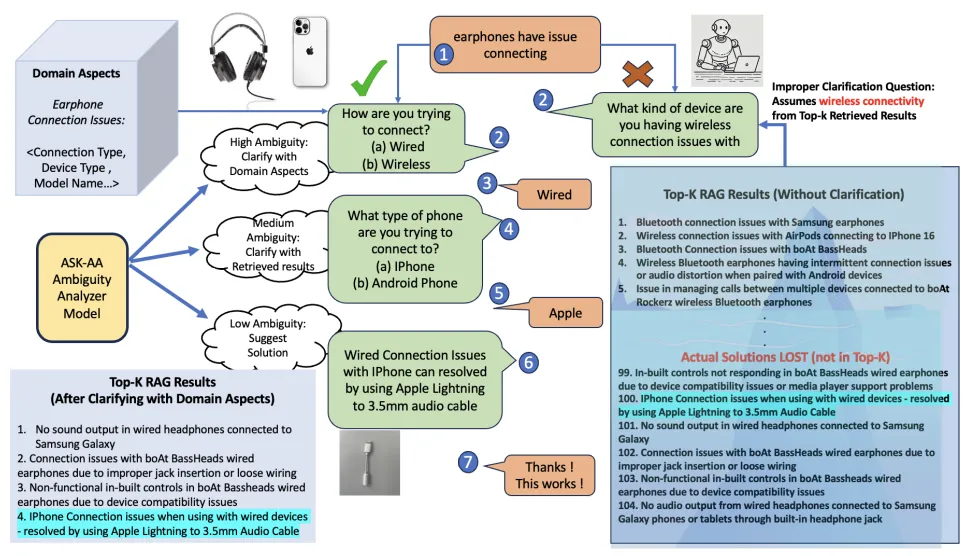
八、还存在哪些问题?
论文坦诚地列出了三个主要错误类型:
1. 方面选择偏差:歧义分析器路由正确(判断为高歧义),但 LLM 在选择具体问哪个方面时选错了,因为其领域知识不够深入。结果需要多问几轮才能回到正轨。
2. 细粒度文档变体:知识库里存在大量"近似重复"文档(比如同品牌不同型号的故障处理),这类文档的差别太细微,检索系统很难分辨,导致歧义分析器误判为"无歧义",过早给出答案。
3. 多轮对话漂移:早期对话轮次的分类错误会在多轮中级联放大——比如本该用领域维度提问,却走了 topk 路由,后续问题越问越偏,最终答非所问。
AsK 的核心贡献可以概括为一句话:在查询歧义程度不同时,动态切换澄清策略,而不是一刀切地只用一种方式。
它的精妙之处在于:
不需要人工标注歧义等级数据,通过弱监督从检索数据中自动推导; 不需要人工维护领域维度,通过聚类 + LLM 自动生成和更新; 通过硬路由策略,让每种信息源都发挥最大效用; 在真实工业系统中取得了显著的业务指标提升。
这种"先判断情况,再选择策略"的思路,对所有需要与用户进行多轮交互以澄清需求的 AI 系统都有很强的参考价值——无论是客服机器人、搜索助手,还是各类基于 RAG 的智能问答产品。
