 夜雨聆风
夜雨聆风
导语
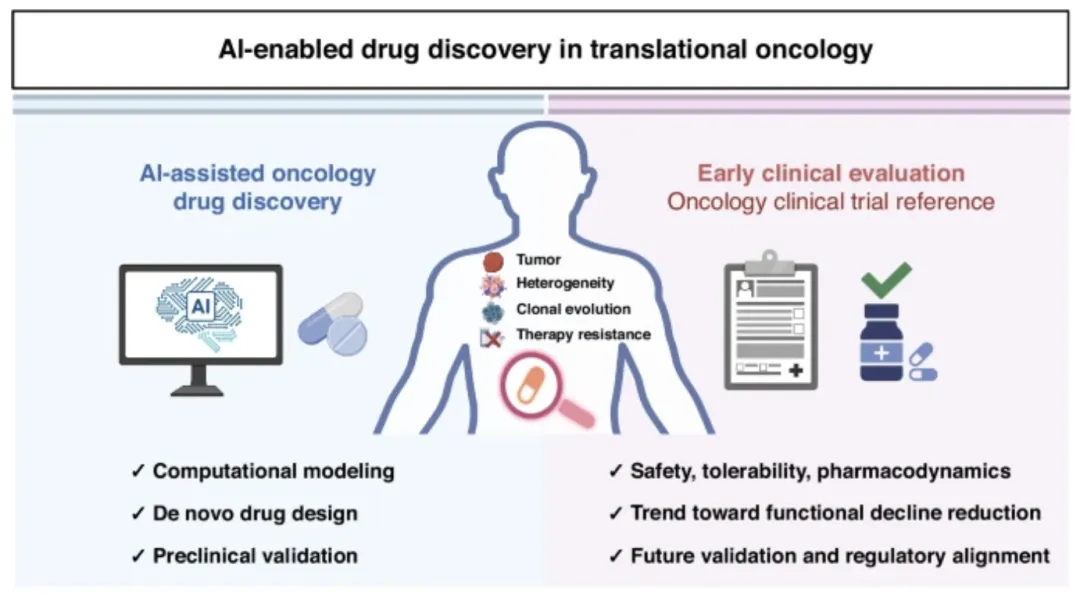
AI制药到今天,最容易犯的错误有两个。 一个是把它看得太轻,仿佛只是文献检索和分子筛选的效率工具;另一个是把它看得太满,仿佛大模型已经接近替代科学家。更接近现实的判断是:今天的机器学习,已经足够明确地在优化药物研发,但还远没有证明可以取代人类科学家承担药物研发的主体责任;至于未来会不会继续上移,现在还不能下过满的结论。2026年的综述也强调,AI驱动分子进入人体试验已经给出概念验证,但更广泛的验证、机制理解和监管对齐仍是必要条件。
也正因为如此,OpenAI这次推出GPT-Rosalind,真正值得行业认真看的,不是又来一个更强的大模型,而是它试图切入药物研发中最贵、最核心、也最依赖高级人才经验的那一步:从文献、数据库、组学、实验结果到下一轮假设、实验规划和资源配置之间的那条认知链。OpenAI将GPT-Rosalind定义为面向生物学、药物发现和转化医学的专用推理模型,当前以research preview方式通过trusted access向合格客户开放,并配套推出可连接50多个科学工具和数据源的Life Sciences research plugin。

换句话说,GPT-Rosalind真正想改写的,不是化学合成,也不是临床执行,而是更前面那一步:决定“下一步该做什么”的那一步。这一步看起来没有临床数据耀眼,却直接决定后面大量实验、资金和时间会不会被浪费。
一、OpenAI这次抢的,不是“分子设计器”,而是药物研发的“脑入口”
过去几年,AI制药公司大多在做能力模块。有人做结构预测,有人做分子设计,有人做表型组学平台,有人做自动化实验闭环,也有人把平台能力转成自有资产推进临床。OpenAI这次的不同之处在于,它不是先做某个垂直模块,而是直接从上层认知入口切进来。GPT-Rosalind的公开定位,核心能力就是证据整合、假设生成、实验规划和多工具调用。
这意味着,OpenAI并不是要先证明“我能比别人更快画一个分子”,而是要先证明“我能把文献、数据库、内部知识、专业模型和研究者判断串成一条更高效的推理链”。这件事一旦成立,它改变的就不是一个工具点,而是研发前端的工作方式。Novo Nordisk与OpenAI的合作也说明了这一点:合作不只覆盖药物发现,还延伸到制造和商业环节,且Novo公开强调目标是“supercharge”科学家,而不是替代科学家。
所以,GPT-Rosalind真正要改写的是哪一步?答案可以压成一句话:不是把药做出来的最后一步,而是“从复杂证据里定义问题、形成判断、决定下一轮实验和资源配置”的那一步。
二、把产业地图摊开看:OpenAI、Isomorphic、Recursion、Schrödinger、晶泰、英矽,其实站在不同位置
如果把今天最有代表性的玩家放在一张图里,逻辑会清楚很多。这场竞争从来不是“谁更会用AI”这么简单,而是谁占据了药物研发流程中的哪一层价值。
第一层,是认知与决策入口。代表是 OpenAI。GPT-Rosalind真正想拿下的,是研发前端最昂贵的认知链:文献整合、证据归纳、假设生成、实验规划和多工具调用。它要抢的不是某一个单点算法的位置,而是“下一步该做什么”的入口。
第二层,是底层设计引擎。代表是 Isomorphic Labs。它的核心不是做通用科研助手,而是做更底层的药物设计engine,试图把分子相互作用理解、结构推理和多模态设计统一到一个更强的设计框架里。过去两年,Isomorphic持续扩展与Novartis的合作,2026年又与Johnson & Johnson建立跨模态、多靶点合作,覆盖小分子、抗体、肽和分子胶。


第三层,是数据工厂与表型闭环。代表是 Recursion。它不是只卖模型,而是想把高通量实验、表型组学、化学和AI整合成一个工业化平台。与Exscientia完成整合后,这条路线更明确了:它的价值不只是“会预测”,而是把药物发现做成可规模化迭代的数据工厂。
第四层,是嵌入研发流程的基础工具链。代表是 Schrödinger。这类公司最容易被忽视,但反而最不容易被轻易替代。Takeda的zasocitinib关键III期阳性结果,再次提醒行业:真正抗波动的,未必是最会讲“自动发现新药”的公司,而可能是那些已经嵌进药企真实流程里的基础设施型工具平台。

第五层,是实验执行基础设施。代表是 晶泰科技。晶泰的价值不在于它是不是中国版OpenAI,而在于它把AI、物理计算和自动化实验连到了研发执行层。RTX-117先后获得中国CTN、美国相关临床推进,并于2026年完成首例受试者给药,说明它更像是在证明平台能不能把项目往前推,而不只是“模型会不会说”。

第六层,是平台转资产、资产进临床。代表是 英矽智能。英矽的重要性,在于它已经不只是平台叙事,而是进入“AI Biotech”逻辑:用AI找靶点、做分子、做资产,并把部分项目推进到临床和BD兑现。Rentosertib在IPF中的Phase IIa结果,以及与礼来的27.5亿美元潜在总额合作,使它成为少数已经把平台能力转成较硬产业结果的AI公司之一。

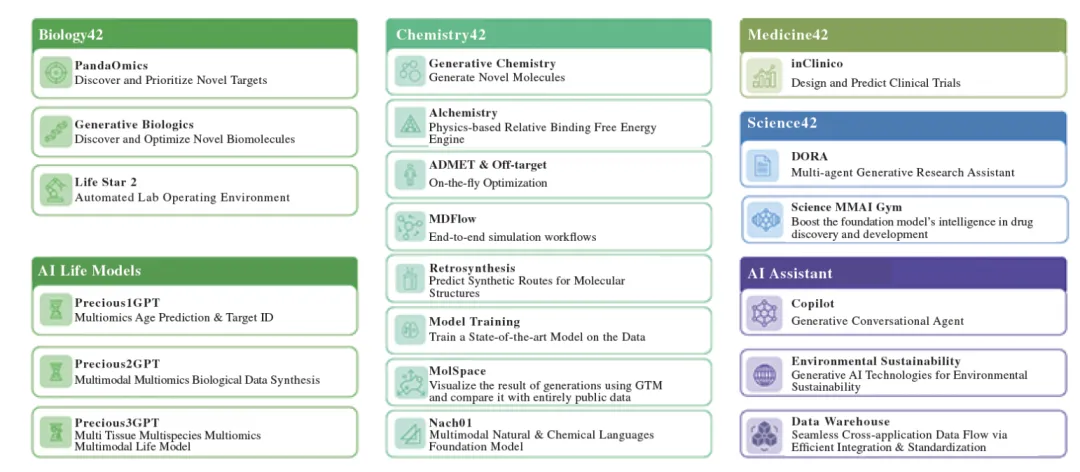
这张图最重要的意义,不是证明大家都很强,而是说明:这些公司并不在同一个位置竞争。OpenAI在争上层入口,Isomorphic在做底层设计引擎,Recursion在做数据工厂,Schrödinger在卖流程基础设施,晶泰在补实验执行闭环,英矽则在把平台尽量兑现成临床资产。
三、这张产业地图真正说明了什么?
它说明,今天AI医药的竞争,已经不是单纯比较“谁的模型更强”,而是在比较三类完全不同的能力。
第一类能力,是谁能定义问题。这是OpenAI想占的位置。它不直接证明一个靶点在人体里有效,但它想提升从证据到判断的速度,让研发前端更快收敛。
第二类能力,是谁能把问题转成可执行的设计和实验。这是Isomorphic、Recursion、Schrödinger、晶泰各自所在的位置,只是路径不同:有的偏设计引擎,有的偏数据工厂,有的偏工具基础设施,有的偏实验闭环。
第三类能力,是谁能把平台能力最后兑现成临床资产。这才是英矽、Recursion后半段真正要回答的问题。因为一旦走到这一步,市场评价标准就不再是模型先进不先进,而是能不能持续做出药。
所以,这张图最核心的判断不是AI会颠覆一切,而是:今天的机器学习,本质上是在优化药物研发链条的不同环节。它可以帮助人更快看见问题、更快组织证据、更快提出候选方向,但还没有证据表明,它已经可以脱离人类科学家,独立承担药物研发的主体责任。这既符合OpenAI对GPT-Rosalind当前“research preview”的定义,也符合行业到目前为止的公开临床兑现程度。
至于未来会不会变,现在不适合下过满的结论。因为一方面,大模型确实在持续上移,从文献问答走向复杂工作流编排;另一方面,药物研发里最关键的环节仍然受真实实验、临床转化和监管证据链约束,这些都不是单靠推理模型就能跨过去的。
四、分别看这些公司,谁最值钱,谁最难,谁最容易被高估
OpenAI最锋利的地方,在于它没有先去和别人比谁更会做单点分子设计,而是直接切进了研发前端最难标准化的认知环节。它要卖的不是狭义药物模型,而是科研工作流的上层编排能力。它的价值在于抢入口;它的局限在于,入口再强,也不能替代真实实验和人体验证。
Isomorphic Labs最强的是设计引擎想象力。它代表AI制药里最“技术正统”的路线:先把底层设计能力做深,再推向更广阔的药物形式和靶点空间。但它的局限同样清楚:产业预期很高,临床兑现仍在路上。路透今年1月还报道,其临床时间表已从原先目标延后至预计2026年底前启动。
Recursion最像“想把药物研发重新工业化”的公司。它的优点是平台感最强,既想做数据工厂,也想推进自有资产。REC-4881在FAP中的持续数据说明,它并不是只卖平台故事;但问题也在于,一旦走向重平台、重临床,它最终仍要接受Biotech的评价体系,而不是Software的估值想象。
Schrödinger代表的则是另一个现实:最不容易被替代的,往往不是最热闹的公司,而是那些已经深度嵌入真实研发流程的基础设施型平台。它未必最性感,但商业逻辑相对更稳,因为它卖的是药企会长期采购的能力,而不是单次故事。
晶泰科技的位置很特别。它不该被简单归为“国产AI制药公司”,更准确地说,它是“AI+物理计算+自动化实验”的研发基础设施平台。OpenAI越往上走,晶泰这类越靠近实验执行和闭环的能力,反而越不容易被通用模型直接稀释。它的价值来自底座;它的局限在于,目前最强的仍是平台与闭环能力,而不是已经被大规模临床验证的资产兑现能力。
英矽智能则是国内最接近全球第一梯队AI Biotech的代表之一。它已经不只是讲平台,而是在用临床结果和BD给自己定价。Rentosertib的IIa结果和礼来合作,让它比很多平台公司更接近“平台—资产—临床—交易”闭环;但这也意味着它面对的要求更高:接下来市场不会只问AI能不能做药,而会更直接地问平台能不能持续做出值得买单的药。
结语
如果只从新闻层面看,OpenAI入局医药研发,很容易被看成又一轮AI热潮。但如果把产业地图摊开,就会发现更关键的变化不是AI药企变多了,而是行业价值捕获层级开始上移。
过去大家比的是谁有更好的单点模型。现在开始比的是:谁能成为科研工作流的总入口;谁拥有不可轻易复制的底层引擎、实验闭环或基础设施;谁又能把平台持续兑现为临床资产。
也正因为如此,OpenAI这次真正它提升的是证据整合速度、假设生成速度、实验优先级排序和跨工具协同能力。它首先冲击的不是临床试验本身,而是研发组织过去那套依赖碎片化经验、低效会议和部门割裂来推进前端研发的方式。
这也是为什么,对GPT-Rosalind最稳妥、也最专业的判断,不应该是“AI即将替代科学家”,而应该是:今天的机器学习,已经足够明确地在优化药物研发;但它优化的是人类科学家和研发组织的工作方式,而不是已经证明可以脱离人类独立完成药物研发。未来会不会继续上移,仍取决于模型能力,也取决于实验、临床和监管能否被真正接上。
——END
注:如有更进一步感兴趣话题,欢迎评论区留言。
