 夜雨聆风
夜雨聆风先进封装核心技术变革深度解析
核心问答 | 封装技术演进 · Chiplet · 玻璃基板 · Hybrid Bonding · TCB · 热管理 · 国内封装格局
为什么"封装"正在超越"制程",成为半导体竞争的新主战场?
▌ 半导体芯片封装方式Loadmap
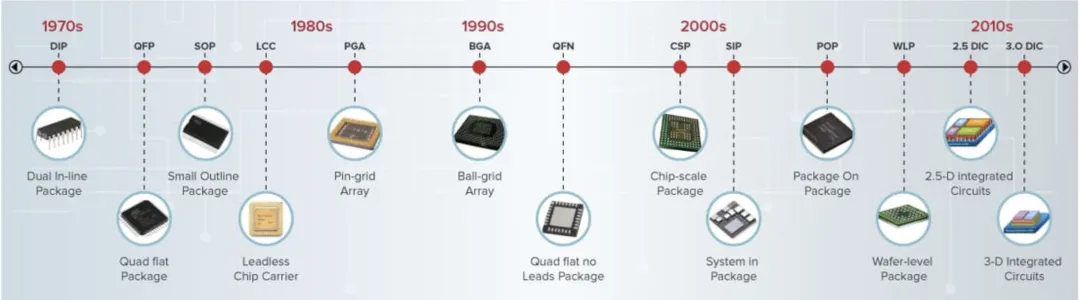
二十年来,半导体行业的核心逻辑是"摩尔定律驱动的制程缩放"——每两年,晶体管特征尺寸缩小0.7x,性能提升而成本下降。然而,自2016年前后,这一逻辑开始动摇:
•物理极限逼近:7nm以下节点的漏电流、短沟道效应、EUV光刻成本使得制程缩放的收益递减,成本反而快速上升
•算力需求爆炸式增长:AI大模型的参数量从GPT-3的1750亿到GPT-4的数万亿,对芯片算力和内存带宽的需求以10倍以上的速度增长,超越了制程缩放的供给能力
•功耗与散热瓶颈:单颗芯片功耗突破1000W成为系统集成的现实挑战,传统封装的热阻设计无法满足需求
•"封装"的战略重估:当制程缩放减速,通过先进封装实现的"系统级集成"成为新的性能跃升路径——Chiplet(小芯片)+先进封装正在成为下一代计算架构的核心范式
▌ 本文目录
PKG-1 先进封装的战略地位:从"后道配套"到"前道替代"的范式转变
PKG-2 封装技术演进路线图:从Lead Frame到Hybrid Bonding的60年跨越
PKG-3 Chiplet架构:先进封装使能的系统级集成新范式
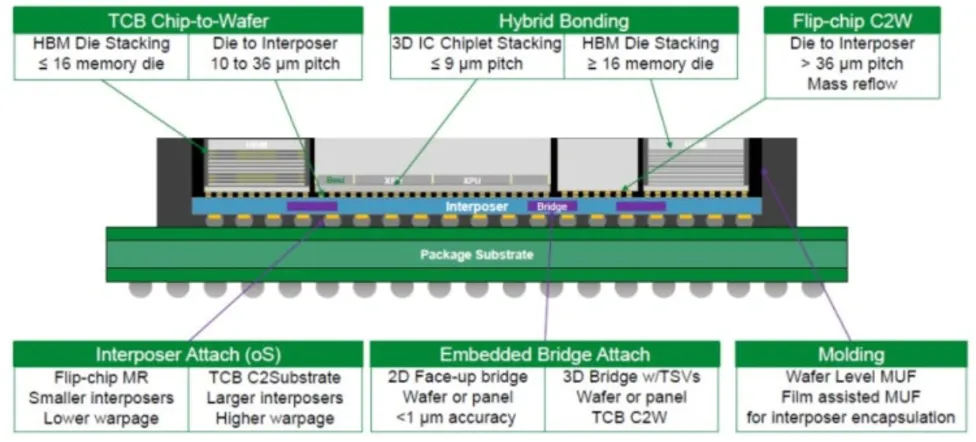
PKG-4 TCB(热压键合):HBM堆叠的主流键合工艺详解
PKG-5 Hybrid Bonding(混合键合):无凸块直接Cu-Cu键合的技术革命
PKG-6 玻璃基板(Glass Substrate):下一代先进封装基板的技术突破
PKG-7 先进封装的热管理:从TIM到液冷的热设计工程实践
PKG-8 全球先进封装供应链格局与国内企业的机遇和挑战
[PKG-1] 先进封装的战略地位:从'后道配套'到'前道替代'的范式转变
▌ Advanced Packaging分类
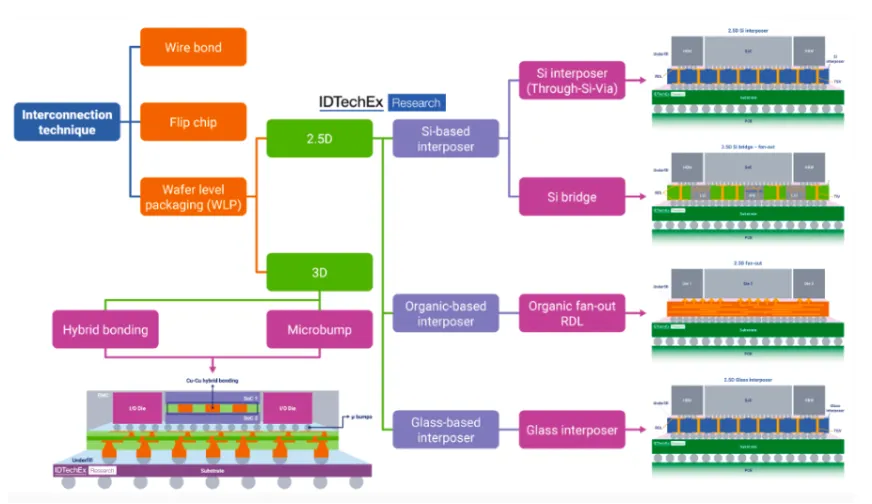
▌ 一、传统封装 vs 先进封装的本质差异
半导体封装经历了从"保护芯片"到"集成系统"的根本性功能转变。传统封装(引线键合、BGA等)仅承担物理保护和引脚引出功能;而先进封装(Advanced Packaging)已成为实现芯片间高密度互连、多维度集成的核心工艺:
维度 | 传统封装(Conventional Packaging) | 先进封装(Advanced Packaging) |
主要功能 | 保护芯片(防水/防静电/防机械损伤);引出电气接口 | 实现多Die异构集成;提供芯片间高带宽低延迟互连;系统级性能优化 |
互连方式 | 金线/铜线引线键合(Wire Bond,间距>100μm) | Flip Chip Bump(间距40~100μm)/ Micro Bump(间距<50μm)/ Hybrid Bonding(间距<10μm) |
集成对象 | 单颗Die或同质Die | 异构Die:Logic+Memory+Analog+RF+传感器等多类型Die混合集成 |
主要玩家 | OSAT(日月光/安靠/长电等外包封测厂) | Fab(台积电CoWoS)/ IDM(英特尔Foveros/三星I-Cube)/ 专业OSAT(升级版) |
与制程的关系 | 制程后的"配套工序" | 制程替代工具——用封装集成弥补制程缩放放缓 |
市场规模(2025E) | 约400亿美元(传统封测) | 约250~300亿美元(快速增长,CAGR>15%) |
▌ 二、先进封装成为战略级竞争要素的三大驱动力
◆ ① AI算力爆炸:系统带宽需求超越单芯片物理极限
以NVIDIA为代表的AI芯片,其对内存带宽的需求已超越单颗DRAM所能提供的上限。通过先进封装将多颗HBM Stack与GPU Die集成在同一封装中,将系统带宽从单通道的~51GB/s(GDDR6X)提升至5TB/s以上(H100:3.35TB/s;B200:8TB/s)——这一跃升完全依赖先进封装,而非制程缩放。
带宽演进数据(NVIDIA GPU系列):• A100(2020):2TB/s(HBM2E × 6颗,CoWoS-S) • H100(2022):3.35TB/s(HBM3 × 4颗,CoWoS-S) • H200(2024):4.8TB/s(HBM3E × 4颗,CoWoS-S)• B200(2024):8TB/s(HBM3E × 8颗,CoWoS-L)• B300(2025E):~16TB/s(HBM3E 12颗,下一代CoWoS)
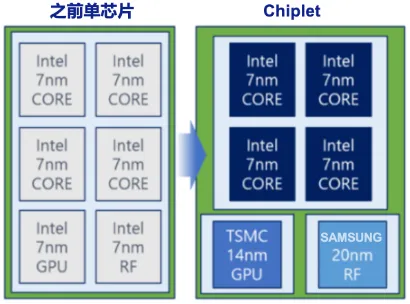
◆ ② Chiplet架构普及:先进封装成为大型芯片的"默认基础设施"
AMD、Intel、TSMC等主要厂商已将Chiplet(小芯片)架构定为旗舰产品的标准路线:将一个大型SoC拆分为多个可独立制造的小芯片(Chiplet),通过先进封装集成。这一架构显著提升良率、降低成本,并实现不同功能块的异构制程优化。
◆ ③ 制程成本倒逼:先进封装提供性价比更优的性能提升路径
2nm节点的晶圆成本约为5nm的3倍以上,而通过先进封装将多个成熟节点Die集成可以用更低成本实现接近的系统性能。英特尔将此策略明确化:"封装即制程(Packaging is the new Process)"——先进封装已从支持角色升级为性能创新的主角。
先进封装技术 | 代表产品 | 实现的核心价值 |
CoWoS(TSMC) | NVIDIA H100/H200/B200 | GPU+HBM异构集成;AI算力密度提升 |
Foveros(Intel) | Intel Meteor Lake、Lunar Lake | 异质制程Die集成(Compute Tile 4nm + I/O Tile 6nm + SoC Tile 22nm) |
EMIB(Intel) | Intel Stratix 10 FPGA | 局部高带宽Die间互连(Die-to-Die 55Gbps/mm) |
I-Cube/X-Cube(三星) | 三星AI加速器 | 3D/2.5D混合;HBM+Logic集成 |
SoIC(TSMC) | 台积电CoWoS-3D | 3D Stacking with TSV,Die-on-Die超高密度集成 |
Fan-Out(台积电InFO等) | Apple A系列处理器 | 超薄低成本2.5D集成;大面积RDL布线 |
[PKG-2] 封装技术演进路线图:从Lead Frame到Hybrid Bonding的60年跨越
▌ 一、封装技术六代演进全景
技术代际 | 时间节点 | 代表技术 | 互连间距 | 关键特征 | 推动力 |
第一代:引线框架 | 1960s~1980s | DIP、TO、QFP、SOIC | 引线间距>500μm | 通孔插装→表面贴装;机械冲压成形 | 器件保护+PCB集成的最基本需求 |
第二代:BGA/CSP | 1990s~2000s | PBGA、CBGA、CSP、LGA | 焊球间距0.5~1.27mm | 面阵列焊球引出;I/O数量大幅增加;底部填充(Underfill)技术 | 手机/PC对引脚数增加的需求;SMT制程成熟 |
第三代:Flip Chip | 2000s~2010s | FC-BGA、FC-CSP | Bump间距100~200μm | Die倒置,正面焊盘通过Bump直接连接基板;显著缩短信号路径 | CPU/GPU性能提升;信号延迟和带宽的改善需求 |
第四代:2.5D/SiP | 2010s~2020s | CoWoS、EMIB、Fan-Out | RDL间距2~10μm;Die间>40μm | Silicon Interposer实现Die-to-Die高带宽互连;系统级集成 | 移动SoC集成化;AI芯片带宽需求爆发 |
第五代:3D Stacking | 2015s~现在 | HBM TSV、Foveros、SoIC | TSV间距25~50μm;Micro Bump 40~55μm | 垂直堆叠Die通过TSV互连;存储器带宽突破瓶颈 | AI训练对HBM的需求;存储带宽墙问题 |
第六代:Hybrid Bonding | 2020s~未来 | Intel IFLEX、SoIC-X | 键合间距1~10μm | 无凸块Cu-Cu直接键合;接近原子级互连密度;理论无限扩展 | 制程缩放极限;下一代AI芯片>10TB/s带宽需求 |
▌ 二、先进封装的技术收敛趋势
从上述演进可以清晰看到一条技术收敛曲线:封装互连间距从>500μm持续向<1μm逼近,封装集成密度向芯片内部互连密度逼近。当封装互连间距达到与芯片内部BEOL(后端互连)同等量级时,"封装"与"制造"的界限将彻底消融——这正是Hybrid Bonding所代表的技术方向。
💡 "封装技术演进的终极形态是:封装层的互连密度=芯片内部BEOL互连密度"。届时,单颗物理芯片和多颗封装在一起的芯片,在性能上将无法区分。这是Hybrid Bonding对半导体行业的根本性意义——它预示着传统"芯片"概念的瓦解和"计算层"(Computing Layer)新范式的诞生。
[PKG-3] Chiplet架构:先进封装使能的系统级集成新范式
▌ 一、Chiplet架构的核心逻辑
Chiplet(小芯片)架构将传统大型SoC「拆」成多个功能独立、可分别制造优化的小芯片(Chiplet),再通过先进封装「合」在一起——以「拆+合」的方式实现超越单芯片物理极限的系统性能:
▌ Chiplet结构以及封装方式
维度 | 单芯片(Monolithic) | Chiplet架构 |
良率 | 随Die面积增大急剧下降(泊松分布:良率=e^(-D₀×A),A↑→良率↓) | 各Chiplet面积小,良率高;坏Chiplet不影响其他Chiplet,整体良率=各Chiplet良率之积(比单片更优) |
制程灵活性 | 全部功能只能用同一制程节点 | 不同功能用最优制程:CPU用3nm,I/O用7nm,Analog用28nm,成本最优化 |
研发周期 | 全新SoC需重新设计所有模块(约2~3年) | 可复用已有Chiplet(IP重用);只重新设计需要升级的模块(约1~1.5年) |
供应链弹性 | 依赖单一Fab、单一制程的稳定供应 | 可从多家Fab采购不同Chiplet,供应链更分散、更灵活 |
性能上限 | 受限于单Die面积(Reticle约858mm²) | 理论上通过增加Chiplet数量无限扩展(受封装和热设计约束) |
▌ 二、Chiplet架构的关键使能技术:Die-to-Die互连标准
Chiplet架构的最大挑战是不同来源的Chiplet之间的互连标准化——如果每家公司的Chiplet接口不兼容,就无法实现跨公司的Chiplet生态系统:
互连标准 | 倡导方 | 主要特性 | 典型带宽 | 应用场景 |
UCIe(Universal Chiplet Interconnect Express) | Intel、台积电、三星、高通、AMD等联合 | 开放标准;兼容现有封装技术(Advanced Packaging和Standard Package两种Profile) | 约1~2TB/s(先进封装Profile) | 跨公司Chiplet生态;标准化Die-to-Die接口 |
BoW(Bunch of Wires) | OIF(开放互连论坛) | 极低延迟;面向Fly-by拓扑 | 高带宽密度 | AI加速器Die-to-Die |
HBI(High Bandwidth Interface) | TSMC | 与CoWoS/SoIC结合;针对TSMC封装优化 | 极高(配合SoIC) | 台积电生态内 |
AIB(Advanced Interface Bus) | Intel | EMIB封装专用 | 约2Tbps/mm | Intel FPGA Chiplet |
NVLink-C2C | NVIDIA | GPU-to-CPU私有协议(Grace Hopper) | 900GB/s | NVIDIA自有产品 |
💡 UCIe(通用Chiplet互连快线)是Chiplet生态标准化的关键里程碑——2022年由Intel/台积电/三星/AMD等50余家企业联合发布,旨在建立类似PCIe的Chiplet通用接口标准。UCIe的普及程度将直接决定独立Chiplet市场(类似IP核市场)能否真正兴起,是Chiplet架构从"厂商内部方案"走向"开放生态"的核心推手。
[PKG-4] TCB(热压键合):HBM堆叠的主流键合工艺详解
▌ 一、TCB的技术原理与应用场景
TCB(Thermal Compression Bonding,热压键合)是目前半导体堆叠封装中应用最广泛的Die-to-Die键合工艺,特别是在HBM内部的DRAM Die堆叠和Flip Chip封装中占据主导地位:
TCB核心原理: 在精密对准后,通过施加热量(约150~300°C)+ 机械压力(约10~100N/Die)的组合,使Die上的Solder Bump(SnAg焊料帽)或Cu Pillar Bump与基板/下层Die的焊盘形成冶金键合——热量使焊料软化/熔融,压力确保充分接触和焊接。
▌ 二、TCB工艺参数与设备详解
工艺参数 | 典型范围 | 影响 | 优化方向 |
键合温度 | 150~300°C(SnAg焊料:约220~250°C峰值) | 温度过低:焊料未充分熔融,键合力弱;温度过高:焊料氧化、周围材料热损伤 | 精确温度曲线控制(Profile);局部加热(Laser-Assisted Bonding避免整体高温) |
键合压力 | 10~100N/Die(约30~80N典型) | 压力不足:焊料接触不充分,Open Bond;压力过大:Die破裂、Bump变形短路 | 自适应压力控制;均一性(Co-planarity)校正 |
键合时间 | 0.5~5秒/Die(单点TCB) | 时间越短,吞吐量越高;时间过短,焊料冶金键合不完全 | 多头并行(Multi-Head Bonder);NCP(Non-Conductive Paste)预置缩短工艺 |
对准精度 | ±2~5μm(标准TCB);±0.5~1μm(高精度TCB) | 对准偏差导致电气失接(Open)或相邻Bump短路(Bridge) | 力/视觉双重对准系统;实时反馈校正 |
助焊剂/NCP | Flux(助焊剂)或NCP(非导电胶) | Flux需后续清洗(增加工序);NCP省去清洗但工艺窗口更窄 | 免洗型Flux(No-Clean Flux);NCP配方优化 |
▌ 三、TCB设备供应商格局
设备商 | 国籍 | 主要产品 | HBM相关份额 | 特点 |
韩美半导体(Hanmi Semiconductor) | 韩国 | TC Bonder(TWIN) | SK海力士主供应商(HBM3以前独供,~80%) | 高速多头TCB,TWIN系统双头并联提升吞吐量 |
ASMPT(ASM Pacific Technology) | 香港 | IConn系列 TCB | SK海力士、三星均有供货 | 全球最大封装设备公司,TCB产品线完整 |
한화세미텍(Hanwha Semitec) | 韩国 | 新型TC Bonder | 2025年开始SK海力士供货(打破韩美独供) | 后起竞争者,以HBM4 TCB机台竞争 |
BESI(Besi) | 荷兰 | Datacon 5000 TCB | 三星、微光供货 | 欧洲精密键合设备龙头 |
东丽工程(Toray Engineering) | 日本 | TCB系列 | 部分DRAM封装 | 高精度视觉对准系统强项 |
⚠️ 韩美半导体在SK海力士HBM3/3E产线的TCB Bonder市场约占80%,是单一供应商高度集中的典型案例。2025年韩华Semitec切入SK海力士供应后,韩美的独供地位被打破,引发市场对其未来份额的高度关注。对供应链多元化而言,这是良性变化;对已持有韩美股票的投资者则是风险信号。
[PKG-5] Hybrid Bonding(混合键合):无凸块直接Cu-Cu键合的技术革命
▌ AMD的 Hybrid Bonding

▌ 一、为什么Hybrid Bonding是先进封装的终极方向?
传统Die-to-Die互连方案(无论是Wire Bond、Flip Chip还是Micro Bump)都依赖中间介质(焊料、金线、铜柱)实现电气连接,这些中间介质的最小尺寸构成互连间距缩小的物理瓶颈。Hybrid Bonding从根本上消除了这一瓶颈:
互连方式 | 最小间距 | 导体材料 | 键合温度 | 可返修性 | 互连密度(相对) |
Wire Bond | >100μm | Au/Cu线 | 室温(热超声) | 不可返修 | 1x |
Flip Chip Solder Bump | 40~100μm | Sn-Ag焊料 | 220~250°C | 可以(焊料重熔) | 5~20x |
Cu Pillar Micro Bump | 25~55μm | Cu + Sn-Ag | 220~250°C | 可以(焊料重熔) | 20~100x |
Hybrid Bonding(Cu-Cu) | <10μm(当前);理论<1μm | Cu(纯金属直接键合) | 约150~300°C(退火) | 不可返修 | 100~1000x+ |
▌ 二、Hybrid Bonding的两种实现路径
◆ ① W2W(Wafer-to-Wafer)Hybrid Bonding
两整片晶圆直接键合,适合Die尺寸相同、良率较高的场景:
•优势:产能最高(整晶圆批量键合),键合均匀性好,设备成本相对低
•局限:要求两晶圆上Die尺寸完全一致;无法先筛选良品Die再键合(坏Die也会被键合),良率损失大
•适用场景:存储器Die/Logic Die良率均高的情况;CIS(图像传感器)堆叠(Sony、三星的3D CIS)
◆ ② D2W(Die-to-Wafer)Hybrid Bonding
将切割好的单颗良品Die(Known Good Die)键合到晶圆上,适合HBM等多层异构堆叠:
•优势:可以先筛选KGD(Known Good Die)再键合,避免将缺陷Die键入Stack,系统良率更优
•局限:对准精度要求极高(单Die逐个键合,每颗Die都需要独立的视觉对准);设备吞吐量相对W2W低
•适用场景:HBM的DRAM Die堆叠(三星HBM4规划);CPU/GPU+HBM的3D堆叠
◆ ③ W2W vs D2W 关键对比
对比维度 | W2W(Wafer-to-Wafer) | D2W(Die-to-Wafer) |
良品筛选 | 不能先筛选(坏Die也键合进去) | 可以先挑选KGD(提升整体良率) |
产能 | 高(整晶圆批量处理) | 中(逐Die处理,较慢) |
对准精度要求 | 相对低(晶圆级对准) | 极高(单Die级,<±0.5μm) |
适用Die尺寸关系 | 上下晶圆Die尺寸必须一致 | 上下Die尺寸可不同(更灵活) |
代表应用 | Sony Exmor RS CIS、部分Logic-Logic堆叠 | HBM4 DRAM Die堆叠(三星)、Intel Foveros Direct |
▌ 三、Hybrid Bonding面临的工程挑战(当前量产瓶颈)
🚨 三星HBM4 Hybrid Bonding的量产良率约10%(2026年初),远低于SK海力士MR-MUF的50~60%——这不是个别问题,而是Hybrid Bonding工艺固有的多重挑战的集中体现:
•CMP平坦化精度:键合面Cu Pad相对SiO₂的高度差需控制在±5nm以内(相当于约20个原子层)——当前最先进CMP设备的控制极限正是在此量级,无统计规律可循
•颗粒控制(Particle Control):单颗>100nm的颗粒落在键合界面,会造成约直径1000倍区域的键合失效("kissing bond"缺陷);需要Class 0~1级超洁净环境(NASA洁净室标准)
•键合前表面活化:SiO₂表面需要等离子体活化产生足够密度的羟基(-OH),活化后的表面保存时间极短(<2小时),要求活化与键合紧密衔接,限制了产线弹性
•Cu扩散退火的热应力:300°C的Cu-Cu退火温度在超薄Die(<40μm)上产生的热应力可达100MPa以上,导致Die翘曲(Warpage),破坏键合均匀性形成恶性循环
•不可返修:一旦Hybrid Bonding完成,任何缺陷Die无法单独更换,必须整Stack报废。这对堆叠前的每颗Die的测试覆盖率提出了接近100%的要求,而当前测试技术无法完全满足
📌 Laser-Assisted Bonding(激光辅助键合)是解决Cu退火热应力问题的新兴方向——利用激光局部加热实现Cu-Cu扩散键合,只加热键合界面而非整颗Die,大幅降低整体热应力。该技术由日本东丽工程等企业主导,是Hybrid Bonding的下一代改进方案。
[PKG-6] 玻璃基板(Glass Substrate):下一代先进封装基板的技术突破
▌ 一、现有封装基板的技术瓶颈
目前先进封装主要采用两类基板:有机基板(ABF,Ajinomoto Build-up Film基板)和硅中介层(Silicon Interposer)。两者各有局限:
基板类型 | 代表应用 | 优点 | 主要局限 |
有机ABF基板 | CPU/GPU的标准BGA封装 | 低成本;成熟工艺;大尺寸;低介电损耗 | 布线最小间距约2~5μm(RDL);热膨胀系数大(15~20ppm/°C),与Si(2.3ppm/°C)失配严重;无法实现TSV(有机材料无法钻TSV) |
硅中介层(Si Interposer) | CoWoS(台积电) | 布线间距可达0.4μm;热膨胀系数与芯片匹配 | 成本极高(12英寸硅片+多层金属布线);面积受限(Reticle大小约858mm²);供应链集中于TSMC;自身无有源功能 |
玻璃基板(Glass Substrate) | 下一代2.5D/3D封装(规划中) | 布线间距可达<1μm;热膨胀系数可调(接近Si);可大尺寸(>510×515mm);TGV(Through Glass Via)可实现;低介电损耗(高频性能好) | TGV(Through Glass Via)制造难度高;玻璃切割和处理(脆性);量产经验不足(2025~2026年进入量产验证阶段) |
▌ 二、玻璃基板的核心技术优势
◆ ① 超大面积可用性——突破硅Interposer的Reticle限制
硅Interposer受光刻机Reticle大小限制,单块约26×33mm(858mm²),需要拼接才能做更大面积(如TSMC CoWoS-L使用拼接Interposer,但接缝处有性能不一致问题)。玻璃基板可直接制造为510×515mm的超大面积,为AI芯片(尤其是下一代需要集成16颗以上HBM的系统)提供充裕空间。
◆ ② CTE可调——解决封装可靠性的根本问题
通过调整玻璃成分(SiO₂/B₂O₃/Al₂O₃比例),玻璃基板的热膨胀系数(CTE)可以调节至2~7ppm/°C范围,接近硅的2.3ppm/°C。这是有机ABF基板(CTE约15~20ppm/°C)所无法实现的,可从根本上降低热循环时Die-to-Substrate焊点的疲劳失效风险。
◆ ③ TGV(Through Glass Via)——垂直互连的玻璃TSV
类似硅TSV,TGV是贯穿玻璃基板的垂直导体通孔,实现基板正面和背面之间的电气连接。TGV制造通常采用激光钻孔(Laser Drilling)+铜电镀填充,但玻璃的脆性使TGV制造面临高应力开裂风险,是当前最主要的工艺难关之一。
玻璃基板产业链 | 主要企业 | 进展状态 |
玻璃基板材料 | 康宁(Corning,美国)、日本电气硝子(NEG)、旭硝子(AGC) | 康宁最为积极,已提供封装级玻璃基板样品;量产时间线约2026~2027年 |
TGV制造 | Corning(内部)、日本Toppan、DNP | Corning垂直整合TGV能力;Toppan和DNP在PCB+TGV组合方向探索 |
封装集成 | Intel(旗下Glass Core Substrate项目)、台积电、三星 | Intel最激进(已公开展示Glass Core Substrate样品);TSMC跟进研发中 |
国内进展 | 深圳兴森快捷、珠海越亚等 | 起步阶段;材料和TGV制造技术与国际领先差距约3~5年 |
⚠️ 玻璃基板当前最大的产业化挑战不是技术,而是供应链生态:需要玻璃材料商、TGV制造商、RDL布线商、封装集成商的完整协同,缺乏任何一环都无法量产。预计玻璃基板真正规模化应用要到2027~2028年,目前仍处于样品验证和客户认证阶段。
[PKG-7] 先进封装的热管理:从TIM到液冷的热设计工程实践
▌ 一、AI时代的芯片热挑战
随着AI芯片的功耗密度急剧上升,热管理已从封装设计的"辅助考量"变为"首要约束":
AI芯片 | TDP(热设计功耗) | 功耗密度(W/cm²) | 散热挑战 |
NVIDIA A100(2020) | 400W SXM版 | 约40W/cm² | 超高功耗密度,需专用散热模块 |
NVIDIA H100(2022) | 700W SXM版 | 约55~60W/cm² | HBM的热量需要通过封装体散出 |
NVIDIA H200(2024) | 1000W SXM版 | 约70~80W/cm² | 已超越传统风冷散热能力上限 |
NVIDIA B200(2024) | 1200W+ SXM版 | 约90~100W/cm² | 数据中心必须采用液冷或浸没冷却 |
下一代AI芯片(2025+) | 预计1500~2000W | 约120~150W/cm² | 封装内部热管理成为功能可靠性关键瓶颈 |
▌ 二、封装热路径分析
【封装热路径示意图 — 从热源到环境的热量流动路径(从Die到散热器):Die结温(Tj,最高约105°C)→ TIM1(Die与散热盖(IHS)之间的热界面材料)→ 散热盖(IHS/Integrated Heat Spreader,铜或钼铜)→ TIM2(IHS与散热器之间)→ 散热器(Air Cooler)/ 冷板(Liquid Cooler)→ 环境温度(Ta,约25°C)。热阻公式:θja = θjc + θcs + θsa;功耗:P = (Tj-Ta)/θja;关键:TIM1的热阻θjc是整个热路径的核心瓶颈】
▌ 三、关键热管理技术详解
◆ ① TIM(热界面材料)
TIM(Thermal Interface Material,热界面材料)填充Die与散热盖(IHS)之间的微小空气间隙,是降低热阻的关键:
TIM类型 | 热导率 | 典型应用 | 优缺点 |
硅脂(Thermal Grease) | 3~8 W/(m·K) | 普通CPU/GPU | 成本低;易涂抹;但长期使用后"泵出效应"导致性能下降 |
相变材料(PCM) | 3~6 W/(m·K) | 消费级CPU | 工作温度下相变为液态,填充性好;性能较稳定 |
金属热界面材料(Liquid Metal) | 30~50 W/(m·K) | 高端CPU(如AMD Threadripper) | 导热极优;但对铝腐蚀强;不可用于铝散热器 |
焊接型TIM(Solder TIM,sTIM) | 30~60 W/(m·K) | NVIDIA A100/H100 SXM | Die与IHS之间焊接(InAg焊料);导热最优;但返修难度大 |
石墨烯基TIM(Graphene TIM) | >100 W/(m·K)(面内) | 下一代高端封装研究中 | 超高面内导热;但垂直方向导热有限;制造成本高 |
◆ ② 液冷(Liquid Cooling)系统
当AI芯片TDP超过700W后,传统风冷(Air Cooling)无法有效散热,数据中心开始大规模转向液冷方案:
•直接液冷(Direct Liquid Cooling,DLC):冷水通过冷板(Cold Plate)直接接触芯片散热器背面,循环冷水带走热量。NVIDIA DGX H100采用此方案,TDP 700W全覆盖
•液浸冷却(Immersion Cooling):将整个服务器浸没在绝缘冷却液(如FC-72含氟液体)中,自然对流或强制循环带走热量。效率最高(PUE可达1.03),但建设和维护成本高
•背板液冷(Rear Door Heat Exchanger):在机柜背门集成液冷换热器,热空气经过背板时被冷水冷却,属于过渡方案
•封装内液冷(On-Package Liquid Cooling):微流道直接集成在封装基板或Interposer内部(研究阶段)——这是终极方案,但制造难度极高,目前处于学术研究阶段
◆ ③ HBM热管理的特殊挑战
HBM的散热面临独特的几何约束:HBM Stack紧邻GPU Die,两者被封装在同一封装体中,HBM Stack自身的热量如果无法及时散出,将导致DRAM温度过高而触发降速(Throttling):
•HBM热量路径:DRAM Die热量 → 穿过MR-MUF模塑料(导热约0.8W/m·K,较差)→ 到达封装顶面 → 通过TIM1 → 散热盖
•MR-MUF的热导率问题:EMC(环氧模塑料)的导热系数约0.8W/m·K,远低于铜(390W/m·K),是HBM内部热阻的主要来源。这也是Hybrid Bonding在热管理上的优势之一——无底部填充,热阻显著更低
•HBM4热设计变化:HBM4规划采用更薄的Die堆叠(从50μm向<40μm)和可能的Hybrid Bonding,结合优化的散热路径设计,目标将HBM热阻降低约30%
[PKG-8] 全球先进封装供应链格局与国内企业的机遇和挑战
▌ 一、全球先进封装产业格局(2025)
企业/机构 | 国家/地区 | 先进封装核心能力 | 代表技术 | 市场定位 |
台积电(TSMC) | 台湾 | CoWoS(2.5D)、SoIC(3D Stacking with TSV)、InFO(Fan-Out) | CoWoS-S/L/R、SoIC-X(Hybrid Bonding) | 全球先进封装产能核心,AI芯片唯一可选方案(几乎) |
英特尔(Intel) | 美国 | Foveros(3D)、EMIB(2.5D)、ODI(Omni-Directional Interconnect) | Foveros Direct(Hybrid Bonding)、Glass Core Substrate | IDM自用为主;开放Foundry提供IFS服务 |
三星电子 | 韩国 | I-Cube(2.5D)、X-Cube(3D TSV)、Hybrid Bonding(HBM4规划中) | I-Cube6、X-Cube、PnP(Package on Package) | 追赶台积电;HBM Hybrid Bonding赌博策略 |
SK海力士 | 韩国 | HBM MR-MUF / Advanced MR-MUF / Hybrid Bonding开发中 | HBM3E 12层 Advanced MR-MUF | HBM市场领导者(~70%市占);封装能力自持 |
日月光(ASE) | 台湾 | SiP、异构集成、Fan-Out、2.5D(部分CoWoS分包) | VIPack、Fan-Out PoP | 全球最大OSAT;CoWoS分包受益者 |
安靠(Amkor) | 美国 | SiP、Fan-Out、先进封装(获NVIDIA直接认证) | SWIFT(Silicon Wafer Integrated Fan-out Technology) | 美国本土先进封装主力;NVIDIA CoWoS备选产能 |
长电科技 | 中国 | SiP、Fan-Out(XDFOI)、先进封装探索 | XDFOI(极高密度Fan-Out集成) | 中国大陆最强OSAT;对标台积电InFO仍有差距 |
通富微电 | 中国 | SiP、先进封装(与AMD合作) | CoFoS(AMD GPU封装) | AMD GPU主要封装商;先进封装能力提升中 |
▌ 二、中国大陆先进封装的机遇与挑战
◆ 机遇:制程受限下的"封装优先"战略
由于出口管制限制了中国大陆获得最先进制程(3nm/2nm)的渠道,通过先进封装实现"以封装弥补制程"的路线成为国内AI芯片产业的现实选择:
•华为海思:昇腾910B采用7nm工艺+先进封装策略,在受限制程下通过封装集成提升系统算力
•海光信息、寒武纪等:均在探索Chiplet+先进封装的系统级设计,以绕开先进制程限制
•CXMT长鑫存储:已公开宣布HBM产能建设计划(月产5万片规模),如量产成功将是国内封装能力的重大突破
◆ 挑战:关键设备和材料的供应链缺口
🚨 中国大陆先进封装面临的最大挑战不是设计能力,而是关键设备和材料的"卡脖子"问题:
•TCB Bonder:韩美半导体、BESI等核心设备供应商受出口管制影响;国产TC Bonder(如精测电子、华兴半导体)在精度和吞吐量上与国际顶级仍有差距
•Probe Card(探针卡):FormFactor约占全球DRAM探针卡市场80%,属于受管制物项;国内探针卡(强一半导体、中科飞测等)在HBM级别高密度MEMS探针卡上尚处早期
•ATE(测试机):Advantest高速测试机(支持9.6Gbps+ High Speed Test)受出口管制,国内华峰测控/长川科技的高速测试能力目前无法满足HBM级别要求
•EMC(环氧模塑料):日本住友、Kyocera等供应90%以上的高端EMC;国内虽有华海清科等布局,但高端HBM专用EMC配方积累不足
•超高纯铜靶材和TSV电镀液:日本JX金属、三菱材料等供应核心材料;国内铜靶材企业(宁波江丰等)在TSV专用超纯铜方面仍处于认证阶段
▌ 三、2025~2030年先进封装市场展望
时间节点 | 技术里程碑 | 市场事件 |
2025年 | HBM4量产(SK海力士 Advanced MR-MUF 12层);三星HBM4 Hybrid Bonding良率攻关;CoWoS-L大规模扩产 | 全球先进封装市场规模约300亿美元;CoWoS产能持续紧张 |
2026年 | Hybrid Bonding量产良率突破30%(目标);玻璃基板进入量产验证;UCIe标准第二版发布 | Chiplet商用生态初步成型;首批商用玻璃基板封装产品问世 |
2027年 | HBM4E(>16层)量产;D2W Hybrid Bonding在HBM领域规模化;Intel Glass Core Substrate量产 | AI加速器系统带宽突破10TB/s;玻璃基板开始替代部分硅Interposer |
2028~2030年 | HBM5规划(Hybrid Bonding主流);3D SoC(System on Chip)概念接近实现;On-Package液冷初步商用 | 封装与制程边界彻底模糊;全球先进封装市场规模约700~1000亿美元 |
📝本文要点总结
•先进封装战略地位:从"后道配套"升级为"前道替代"——制程缩放放缓后,封装成为AI算力提升的新主引擎
•六代技术演进:DIP→BGA→Flip Chip→2.5D→3D TSV→Hybrid Bonding;互连间距从>500μm向<1μm持续压缩
•Chiplet架构:"拆"(拆分SoC为多功能Chiplet)+"合"(先进封装重新集成);UCIe标准推动开放Chiplet生态
•TCB:热压键合是HBM堆叠主流方案;韩美半导体曾独供SK海力士,韩华Semitec 2025年打破垄断
•Hybrid Bonding:无凸块Cu-Cu直接键合;理论互连间距<1μm;三星HBM4规划采用;当前量产良率约10%,核心挑战是CMP平坦度<1nm RMS和颗粒控制
•玻璃基板:超大面积(510×515mm)+CTE可调+低介电损耗;Intel最激进推进;量产时间线2027~2028年
•热管理:AI芯片TDP从400W→1200W+,数据中心被迫从风冷转向液冷;MR-MUF的EMC低导热(0.8W/m·K)是HBM热设计瓶颈;Hybrid Bonding因无底部填充而具热管理优势
•国内格局:长电科技/通富微电在中低端先进封装有能力;HBM级别TCB/ATE/探针卡/EMC等关键设备材料受制于管制,是最大挑战
💡 先进封装已经成为半导体行业未来十年最重要的技术战场。无论是AI芯片的算力突破、Chiplet生态的标准化还是存储器的带宽革命,都将以先进封装作为最终实现平台。对中国大陆半导体产业而言,在制程受限的现实约束下,以"先进封装+成熟制程"为核心的技术路线,可能是当前最现实可行的追赶战略。

*谢谢观看
团队编辑的知识点的内容 您感觉满意的话请关注我。
您的一份关注是我的动力。谢谢*
📅下期预告
下期将深入解析SK海力士2025年最新官方披露的HBM4技术路线图——Advanced MR-MUF vs Hybrid Bonding的技术选择逻辑,HBM4在带宽密度、功耗效率和堆叠层数上的具体规格目标,以及面向HBM5的长期技术规划,敬请关注。
🔔 关注 ChipNote芯笔记,持续深入半导体制程与AI芯片产业链
第七章真实DRC违规案例深度解析DRC:Case Study核心案例 | M2面积违规 · GT间距违规 · DG包围违规 · PAD规则 · CT位置违规 · M1封装改版
第六章典型存储器设计规则:DRC:Typical Memory Design Rule核心问答 | 存储器三区域规则体系·Cell/Core/Peri差异·SRAM位单元几何约束
第五章芯片密度规则与天线规则深度解析:DRC:Density&Antenna Rule核心问答|图案密度·Al/Cu工艺差异·CMP碟形缺陷·天线效应·修复策略
第四章芯片标准设计规则深度解析:DRC:Standard Design Rule核心问答 | AA规则 · GT规则 · CT规则 · Metal规则 · LDD阴影效应
第三章芯片设计规则术语精确定义:DRC:Terminology in Design Rule Define设计规则术语精确定义核心问答 | Width·Space·六大关键术语
第二章芯片设计规则基础入门:DRC:Design Rule Introduction核心问答 | 设计规则的定义·三大核心意义Drawing/Mask/Si-rules三层规则体系
第一章芯片设计规则检查:基础入门DRC(Design Rule Check)核心问答 | 什么是DRC · 验证流程 · Gating机制 · 工具资源配置
Dry Resist(干式光刻胶)深度解析-核心问答 | 半导体生产工序必备知识点
