 夜雨聆风
夜雨聆风在业界翘首以盼SpaceXAI首次公开募股之际,OpenAI的一项突破性成果震惊了科学界:其GPT-next模型,据推测是运行了不足32小时或成本低于1000美元的GPT 5.6版本,成功反证了长达80年的Erdős平面单位距离问题[2]。
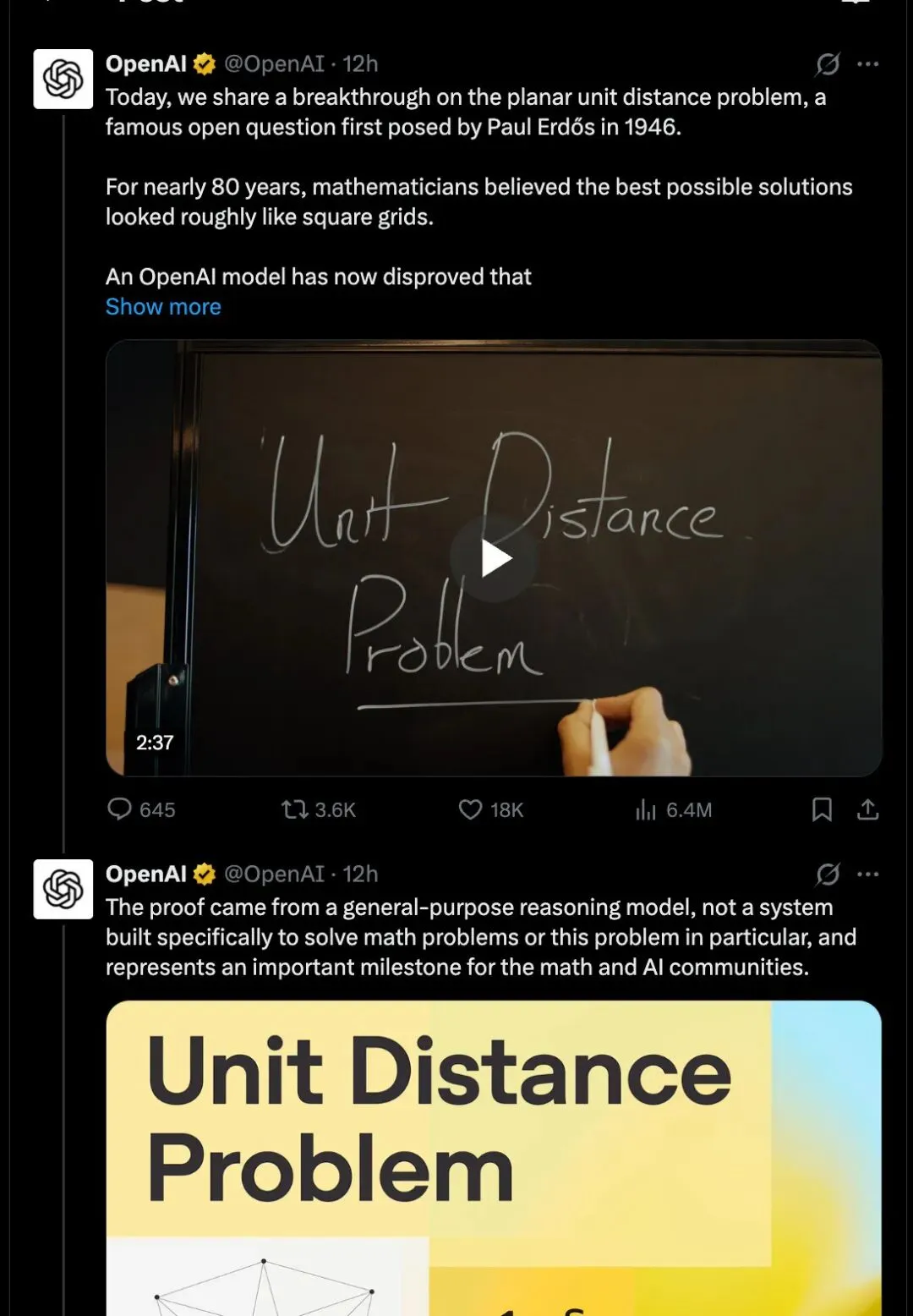
这项成果的重要性在于,它并非来自AlphaProof或Lean这类专用数学模型,而是由一个通用大语言模型(LLM)完成[4]。这预示着AI的扩展推理能力有望超越数学领域,普惠更广泛的科学探索。就像2025年AI在国际数学奥林匹克竞赛(IMO)中取得金牌的表现[3]一样,本次突破再次证明了通用AI在复杂问题解决上的巨大潜力。
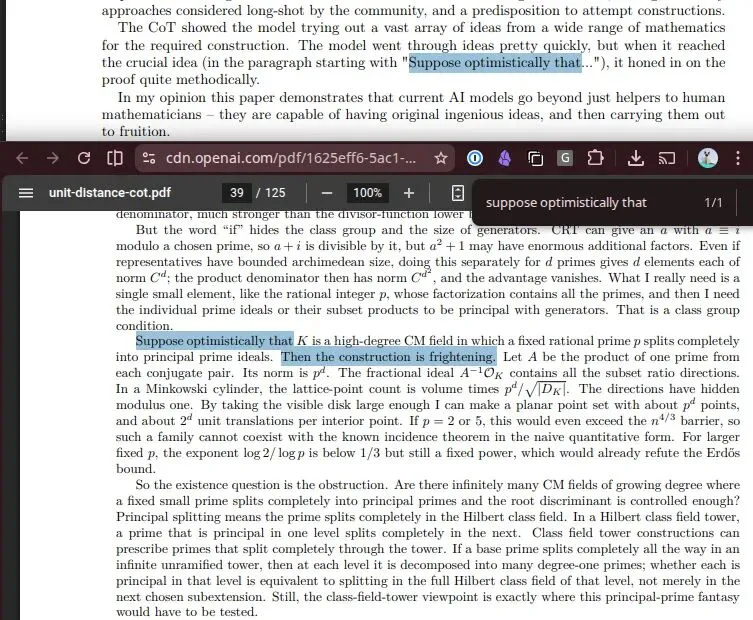
在OpenAI模型生成的125页输出报告中,一个被广泛关注的“第39页时刻”[6]展示了其反证的关键步骤。


这项研究的意见函作者指出,虽然这是一个反证而非证明,但它仍然指明了未来发展的方向[4]:AI正在走向能够解决复杂科学难题的未来。这次事件也引发了关于“测试时计算(test-time compute)”在前沿推理中实际作用的讨论[14, 15, 16]。
一、AI Twitter热点回顾
1. OpenAI数学里程碑
- OpenAI宣布在单位距离问题上取得突破,是最具影响力的技术进展[6]。这不仅因为其科学新颖性,更因为它预示着长程推理能力的巨大提升[6, 7, 8]。
- 该成果获得了数学家和相关研究人员的异常强烈认可。数学家Timothy Gowers称之为AI解决“著名”开放数学问题的首个真正清晰的案例[9]。OpenAI研究员Hongxun Wu将其描述为“最难问题”上内部推理LLM的里程碑[10]。来自Thomas Bloom[11]、gdb[12]、alexwei_[13]和polynoamial[4]等人的其他反应都指向同一个观点:这在质量上超越了以往“AI解决奥林匹克数学问题”的里程碑。
- 值得关注的技术背景:OpenAI表示,该模型并未被推到极限,并旨在最终公开使用[4]。据voooooogel[6]透露,已发布的推理摘要本身篇幅巨大,约125页,这引发了关于测试时计算在前沿推理中实际作用的讨论。一些观察者明确指出,这是推理时扩展是当前进展范式的进一步证据[14],另一些人则推断形式科学和数学领域未来将更快取得进展[15, 16]。
2. Cohere Command A+开放发布与架构讨论
- Cohere以Apache 2.0开源权重发布了Command A+,将其定位为迄今为止最强大的模型,并明确优化了低硬件需求[17]。随后,官方对许可进行了澄清[17]。这次发布意义重大,部分原因在于这是Cohere的首个完全开放的Apache 2模型[18]。社区反应集中于此,认为这是向更宽松、更易于部署的企业级开放模型迈出的重要一步[19, 20]。
- 模型细节在多个帖子中重复提及:大约是218B MoE / 25B活跃参数,多模态,支持48种语言,并且可以在相对适中的配置上运行[21, 22]。vLLM在发布当天即提供了支持,并指出它可以在仅需2块H100显卡(W4A4量化)的设置下运行[23]。
- 基准测试结果褒贬不一但可信:Artificial Analysis将其Command A+模型在智能指数上评为37分,与Claude 4.5 Haiku的水平相当,尤其在非幻觉行为和良好速度方面表现出色,但在科学推理和编码方面弱于顶级同类模型[24]。社区还深入研究了其架构:不寻常的选择包括并行Transformer块、大量共享专家的使用、LayerNorm而非RMSNorm、相对较低的32层深度以及非典型的头部/专家配置[25, 26, 27]。这使得该版本不仅是一个模型发布,更是一个有价值的架构数据点。
3. Agent、内存和科学工作流的基准测试
- InferenceBench是近期发布的技术含量最高的成果之一。它通过开放式推理优化任务,旨在实现AI研发自动化。然而,目前前沿Agent的表现却令人失望:它们在系统级工程、依赖管理和广泛探索方面表现不佳,甚至不如简单的vLLM/SGLang超参数调优基线[28]。该讨论还报告了一种明显的逆向扩展效应,即像Claude Sonnet 4.6和GLM-5这类模型因其能保持稳定的最终状态而表现良好,而更大的模型却常常产生脆弱的最终配置。
- Terminal-Bench Science将Agent评估从编码扩展到实际科学工作流,目前已开放任务贡献[29]。与此同时,MINTEval旨在测试频繁更新和干扰下的长上下文记忆系统:平均实例长度为138.8k令牌,最高可达1.8M,但在7个系统中,平均准确率仅为27.9%,最好的也只有33.4%[30]。这补充了越来越多的研究,这些研究认为记忆应该是一个专门的学习子系统,而非仅仅是RAG/上下文填充[19]。
- 在人机交互研究方面,ThoughtTrace引入了一个大规模数据集,记录了用户在实际LLM对话中的自我报告思维:包含10,174条思维标注、2,155次多轮对话、1,058名用户、20个模型。报告称,该数据集在用户行为预测方面带来了41.7%的提升,在对齐方面带来了25.6%的提升[32]。这是对对话日志未能捕捉到的“潜在用户状态”进行检测的最具体尝试之一。
4. Google I/O后续:Gemini 3.5 Flash、Omni、AI Studio和Antigravity
- Gemini 3.5 Flash开始在Gemini应用中进行更广泛的推广,包括全球免费访问[7]。Google将其定位为迄今为止最强大的Agent和编码模型,声称其性能在前沿水平,速度是同类模型的4倍,成本不到一半[7]。然而,外部讨论则褒贬不一,尽管在发布阶段基准测试表现良好,但多个帖子对其实际成本/性能和令牌效率提出了质疑[24, 15, 23]。
- Gemini Omni似乎比3.5 Flash给人们留下了更深刻的印象。Google将其定位为用于视频和混合输入工作流的会话式多模态创建/编辑模型[7],Gemini应用演示展示了会话式视频编辑[7]。早期反应普遍认为Omni是一款比核心LLM更新更具差异化的产品[15]。
- 在工具方面,AI Studio更深入地推动了端到端开发者工作流和移动访问[7],而一些帖子试图解读Gemini Spark、Antigravity以及Google内部/外部Agent工具之间的关系[33, 34]。一个更具体的Antigravity相关更新是推出了Google Agent堆栈的Science Skills,集成了30多个生命科学来源,如UniProt和AlphaFold DB[23]。
5. Agent基础设施、检索与开发工具
- 多个帖子都得出了相同的操作教训:Agent在基础设施现实面前失败,而不是在演示面前失败。这一主题体现在关于研究Agent与依赖冲突和配置作斗争的定性讨论中[4],LangChain推动LangSmith Sandboxes GA[20],以及为deepagents提供更轻量级代码解释器支持,作为纯工具执行和完整沙盒之间的中间地带[15, 20]。
- 在检索/搜索基础设施方面,Perplexity描述了一个生产化的查询感知、引用保留的上下文压缩系统,该系统将上下文令牌减少了70%,同时提高了答案质量,并声称在SimpleQA上实现了50倍压缩,达到了前沿水平[22]。Weaviate 1.37添加了MMR重排功能,以提高RAG/Agent中向量检索的多样性[23]。同时,SID-1被提出作为一种经过RL训练的Agent搜索模型,在引用的设置中,其召回率比RAG+重排高1.9倍,速度快24倍,成本比GPT-5.1便宜99%[28]。
- Cursor、VS Code和Codex都发布了显著的工作流更新。Cursor在Agent工作区添加了自动化功能[21],VS Code改进了markdown/HTML预览、远程会话连续性以及实用模型可配置性[26, 27]。在模型方面,Composer 2.5在编码Agent表现出色,在Artificial Analysis编码Agent指数中获得62分,且成本远低于顶级的Opus/GPT-5.5变体[24]。OpenAI还在移动设备上推出了Codex[7]。
6. 热度最高推文精选
- OpenAI数学里程碑:OpenAI宣布单位距离突破是本期最具影响力的技术帖子,兼具科学新颖性与长程推理的启示[6]。
- Cohere Command A+开放发布:本期最重大的模型发布之一,主要原因在于其Apache 2.0许可证和不同寻常的架构[17]。
- Anthropic与SpaceX/Colossus的算力扩张:据报道,Anthropic正在扩大其在Colossus 2上的算力部署[20]。后续帖子引用了一份文件,该文件评估了SpaceX的计算协议,到2029年5月每月价值12.5亿美元[1]。
- Exa融资:Exa以22亿美元估值完成了2.5亿美元的C轮融资,明确将自身定位为组织网络数据以服务Agent的搜索实验室[33]。
二、AI Reddit热点回顾
1. Qwen3.7预览与27B路线图
- Qwen正在努力研发[48]:一张图片显示Chujie Zheng透露Qwen正在“努力研发”,并引用了一则公告,称Qwen3.7预览版已上线Arena,包括Qwen3.7-Max-Preview和Qwen3.7-Plus-Preview;该帖子声称阿里巴巴在文本排名第六,在视觉排名第五。Reddit帖子标题和自述内容表明用户期待更大、更新的开源模型——特别是122B和新的27B——尽管截图本身主要是预告而非技术基准细分[54]。评论者对高端模型感到兴奋,但也有人实际关注小型本地模型:一些人希望有适用于低端硬件的9B/4B变体,而另一些人则期待122B,一个更好的35B,或者开玩笑说Qwen可能很快就会“烧”掉他们的GPU。
- Artificial Analysis对Qwen3.7 Max进行评分,27B/35B等待中[49]:一篇Reddit帖子突出了一张Artificial Analysis排行榜截图[56],其中Qwen3.7 Max排名第5,大致与GPT 5.4 (xhigh)持平,略领先于Gemini 3.5 Flash。作者指出Qwen3.6 27B比其Max版本落后精确6分,并希望即将发布的Qwen3.7 27B/35B变体能接近Max模型的性能。评论者主要“热切等待开源模型”,并将此分数视为Qwen团队现在能够与主要实验室竞争的证据,尽管担心Max模型并非开源。一个技术担忧是Qwen是否已修复其先前“过度思考”的倾向。
- Qwen极有可能发布另一款27B模型[50]:一张X/Twitter截图显示xiong-hui (barry) chen表示Qwen正在“等待确切的路线图”,但他认为发布另一款27B模型的可能性很高,帖子标题将其框定为备受好评的Qwen 3.6 27B的可能后续[58]。技术意义在于推测Qwen将继续优化中型密集模型范围内的参数效率/“智能密度”,而不仅仅是扩展到更大的MoE模型。评论者主要讨论本地推理的实用性:一些人想要更大的122B-A10B MoE模型,而另一些人则认为27B对于16GB显存的用户来说太重,更喜欢35B/A3B风格的MoE,可以在消费级游戏笔记本或混合CPU/GPU设置上运行。
2. 开源模型发布:Lance 3B和Command A+
- 字节跳动发布了一款试图以3B参数实现几乎所有功能的开源模型[51]:字节跳动研究院发布了Lance[52],一款原生统一多模态模型,宣称拥有3B活跃参数,用于图像/视频理解、文本到图像/文本到视频生成以及图像/视频编辑,该模型是在128块A100的预算下从头开始训练,采用了分阶段多任务配方。评论者指出,“3B活跃参数”可能低估了实际部署所需的显存:Hugging Face模型卡要求至少40GB显存,其中Lance_3B的safetensors约为24.7GB,Lance_3B_Video约为28.4GB;一位评论者将其描述为一个复合BAGEL风格系统,结合了经过调优的WAN 2.2 3B视频模型、一个3B像素空间图像模型以及Qwen2.5-VL-3B作为VLM骨干。讨论集中在小活跃参数计数能否在复杂场景下保持质量,以及对已发布Gradio演示功能不足的批评——据报道仅涵盖基本的T2V和VQA,而忽略了VLM聊天、T2I和Agent风格的交互。一位评论者认为,40GB的要求可以通过按需加载/卸载子模型来降低,以牺牲内存换取延迟。
- 关于Cohere的Command-A系列模型发生了什么?[53]:Cohere宣布推出其首款MoE开源模型Command A+,将其定位为高效/低延迟的企业Agent模型,而非纯粹的顶级基准领导者;Cohere声称其强大的量化工作使其可以在1-2块GPU上实际部署,并以Apache 2.0许可证发布,供广泛商业使用[17, 24]。Nick Frosst明确表示,此次发布受到了社区反馈的影响,是Command/R系列专注于为小型团队和开发者构建实用Agent的延续[19]。评论普遍对Cohere重回有竞争力的开源模型发布持积极态度,有人指出最初的Command R+在创意/资源规划工作流方面堪称“传奇”。评论者主要的技术要求是提供GGUF格式以支持本地推理。
3. Claude中继滥用和Agent沙盒安全
- 我花了一周时间研究中国的“转运站”经济,以零售价10%的价格转售Claude。供应链比我预想的更疯狂[54]:一张X上的文章预览截图显示,一篇报道揭露了中国“转运站”经济以大幅折扣转售Claude/Anthropic API访问权限的现象,被描述为从中国AI公司到美国Claude端点的“令牌走私/推理外流”地图[63]。该帖子指出,这些中继使用刷号的Anthropic账户、住宅代理、TLS指纹欺骗、短信/SIM卡银行验证、KYC绕过,以及one-api、new-api、claude-relay-service、claude2api、clewdr和clove等开源中继堆栈,通过合并OAuth令牌为多个用户提供服务。报告还强调了所谓的质量/安全风险:CISPA Helmholtz审计发现,中继静默地用Haiku/GLM/Qwen替换“Opus”会导致高达47.21%的性能下降和45.83%的模型指纹验证失败,同时所有提示/响应都可能被记录用于蒸馏数据集。评论普遍认为供应链细节是可信但令人担忧的,特别是模型替换和KYC绕过的说法。一位评论者质疑审计证据的来源——Anthropic、内部遥测,还是蜜罐/假客户测试——而另一个人则认为一旦补贴的令牌定价结束,廉价推理可能会消失。
三、其他AI社区热点回顾
1. Anthropic人才与支持压力
- Karpathy加入Anthropic[55]:一张X帖子截图显示Andrejt Karpathy表示他已加入Anthropic,将暂停以教育为中心的工作,回归前沿LLM研发[56]。Reddit帖子标题“Karpathy加入Anthropic”将其视为前沿模型竞争中的一次重大人才流动,鉴于Karpathy在深度学习、LLM教育和工业AI研究方面的突出地位。评论大多将此举视为AI行业“剧情”而非技术新闻,将其比作一位超级明星加入了最强的团队,暗示Anthropic目前拥有最优秀的阵容。也有评论对Sam Altman/OpenAI进行负面评价,表明评论者认为此举具有竞争意义。
2. Agentic OS构建和图像LoRA工作流
- Google Antigravity 2.0在12小时内使用96个Agent从零开始创建了一个操作系统,令牌成本不足1K美元——并且它能运行Doom[57]:该帖子声称Google Antigravity 2.0在12小时内协调了96个Agent,以不到1K美元的令牌成本从零开始构建了一个操作系统,据说生成的操作系统能够运行Doom。链接的Reddit视频因403 Forbidden响应而无法访问,因此无法从源头验证任何实现细节、基准、架构或可复现证据。评论大多是非技术性的玩笑,但一位评论者质疑其经济性,认为单个Agent在一小时内可以消耗100美元的令牌,并暗示声称的成本可能相差几个数量级。
- Klein 9B蒸馏版结合两个LoRA实现极致真实感[58]:该帖子声称Klein 9B Distilled / Flux2 Klein Base 9B通过堆叠多个LoRA(Better Skin Concept 2.0 + Smartphone Snapshot Photo Reality v13.0 OMEGA,可选结合SNof 1.3)实现了异常高的照片真实感。作者表示所有样本均为纯文本到图像生成,未经编辑/放大,在RTX 3060 Ti 8GB上生成,并认为Klein可以以1.0的权重运行3个LoRA而不会出现视觉降级,这与Z Image Turbo不同,后者在2个LoRA或权重高于约1.4时会遇到困难。评论者大多对感知到的真实感做出反应,有人表示有些图片让他们怀疑是否为AI生成;另一回复显得怀疑/批评,但未添加技术细节。
3. 付费AI计划使用限制
- 与Pro版聊天8分钟后,我的使用量就达到了100%。这是开玩笑吗?我可是Pro订阅用户啊[59]:一张Google Gemini Pro“使用限制”页面的手机截图显示,用户在聊天约8分钟后,当前限制已达到100%,而单独的每周限制仅显示使用了5%;该页面还推销更高层级,承诺“比AI Pro多20倍的使用量”,每月费用为409.99美元[69]。该帖子在技术上具有相关性,因为它展示了消费级LLM产品中日益精细/不透明的配额执行,这可能反映了基于模型、时间窗口或计算成本的限制,而非简单的每周消息上限。评论者将此视为Google效仿Anthropic的限制措施,并担心随着提供商试图收回推理成本,付费AI订阅正在变得更具侵略性地计量。一些人对Google,尽管拥有基础设施规模,却似乎面临计算资源限制或将用户推向昂贵的高级使用计划表示惊讶。
参考链接
- [1] https://twitter.com/semianalysis_/status/1786524254471715053
- [2] https://en.wikipedia.org/wiki/Unit_distance_graph
- [3] https://www.nature.com/articles/d41586-024-02381-0
- [4] https://twitter.com/polynoamial/status/1792686866504229987
- [5] https://substack-post-media.s3.amazonaws.com/public/images/0ff7bdc0-79ef-49ce-a5c0-f7db89d60637_1098x1582.png
- [6] https://twitter.com/voooooogel/status/1792660124671850785
- [7] https://twitter.com/openai/status/1792644265432658145
- [8] https://twitter.com/openai/status/1792644266304854581
- [9] https://twitter.com/wtgowers/status/1792681559194247563
- [10] https://twitter.com/HongxunWu/status/1792662057393457221
- [11] https://twitter.com/thomasfbloom/status/1792666792348393563
- [12] https://twitter.com/gdb/status/1792651474582696145
- [13] https://twitter.com/alexwei_/status/1792645601269389599
- [14] https://twitter.com/_arohan/status/1792684897143992505
- [15] https://twitter.com/scaling01/status/1792667107775594611
- [16] https://twitter.com/sama/status/1792644268611899539
- [17] https://twitter.com/CohereAI/status/1792644265432658145
- [18] https://twitter.com/aidangomez/status/1792688756306354460
- [19] https://twitter.com/nickfrosst/status/1792695277123985408
- [20] https://twitter.com/ClementDelangue/status/1792739796791986422
- [21] https://twitter.com/JayAlammar/status/1792702932228807094
- [22] https://twitter.com/mervenoyann/status/1792716447820155024
- [23] https://twitter.com/vllm_project/status/1792742900742514120
- [24] https://twitter.com/ArtificialAnlys/status/1792718104593457224
- [25] https://twitter.com/eliebakouch/status/1792708307222534571
- [26] https://twitter.com/rasbt/status/1792715426149171092
- [27] https://twitter.com/stochasticchasm/status/1792723326177587640
- [28] https://twitter.com/maksym_andr/status/1792747124991512808
- [29] https://twitter.com/StevenDillmann/status/1792697858364860434
- [30] https://twitter.com/hyunji_amy_lee/status/1792664531238617306
- [31] https://twitter.com/chuanyang_jin/status/1792691230107779373
- [32] https://twitter.com/simonw/status/1792705629161713888
- [33] https://twitter.com/_philschmid/status/1792700547070183863
- [34] https://twitter.com/GoogleDeepMind/status/1792742900742514120
- [35] https://twitter.com/jehyeoky248/status/1792686866504229987
- [36] https://twitter.com/LangChainAI/status/1792739796791986422
- [37] https://twitter.com/sydneyrunkle/status/1792667107775594611
- [38] https://twitter.com/hwchase17/status/1792739796791986422
- [39] https://twitter.com/perplexity_ai/status/1792716447820155024
- [40] https://twitter.com/weaviate_io/status/1792742900742514120
- [41] https://twitter.com/turbopuffer/status/1792747124991512808
- [42] https://twitter.com/cursor_ai/status/1792702932228807094
- [43] https://twitter.com/code/status/1792715426149171092
- [44] https://twitter.com/pierceboggan/status/1792723326177587640
- [45] https://twitter.com/OpenAIDevs/status/1792644265432658145
- [46] https://twitter.com/ExaAILabs/status/1792705629161713888
- [47] https://www.reddit.com/r/LocalLlama/comments/1cvqj89/qwen_is_cooking_hard/
- [48] https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2Ftf537p6v482h1.png
- [49] https://www.reddit.com/r/LocalLlama/comments/1cwa96b/qwen37_max_scored_by_artificial_analysis_27b35b/
- [50] https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2F98f65427l82h1.png
- [51] https://www.reddit.com/r/LocalLlama/comments/1cwagf9/qwen_will_release_another_27b_with_high/
- [52] https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2F9a2h05k8l82h1.png
- [53] https://www.reddit.com/r/LocalLlama/comments/1cvqj0x/bytedance_released_an_open_source_model_that/
- [54] https://huggingface.co/bytedance/Lance
- [55] https://www.reddit.com/r/LocalLlama/comments/1cvz142/re_what_ever_happened_to_coheres_commanda_series/
- [56] https://www.reddit.com/r/LocalLlama/comments/1cw562f/i_spent_a_week_researching_the_chinese_transfer/
- [57] https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2F8a3h0k8zl72h1.jpeg
- [58] https://www.reddit.com/r/Singularity/comments/1cw4g2f/karpathy_joins_anthropic/
- [59] https://twitter.com/karpathy/status/1792671049909242948
- [60] https://www.reddit.com/r/Singularity/comments/1cvyv5i/googles_antigravity_20_creates_an_operating/
- [61] https://www.reddit.com/r/StableDiffusion/comments/1cw560b/extreme_realism_with_klein_9b_distilled_2_loras/
- [62] https://www.reddit.com/r/ChatGPT/comments/1cvyi9b/8_minutes_of_chatting_with_pro_and_im_at_100/
- [63] https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2F7a3h0k8zl72h1.png
AI群: 欢迎加我微信 tsla10timesAI交流,拉你进群!我们刚刚建立这个AI交流社群,正在寻找志同道合的朋友一起成长!
