 夜雨聆风
夜雨聆风
前言
在当前的 AI Agent(智能体)架构中,AI 模型(尤其是大语言模型 LLM)主要充当 Agent 的“大脑”,负责感知、规划、记忆和行动决策。

注:上图来自李宏毅2026 OpenClaw教程
在开发 AI Agent 系统时,我们该如何选择AI模型的接入方式呢?
AI模型的接入与部署四大主流阵营
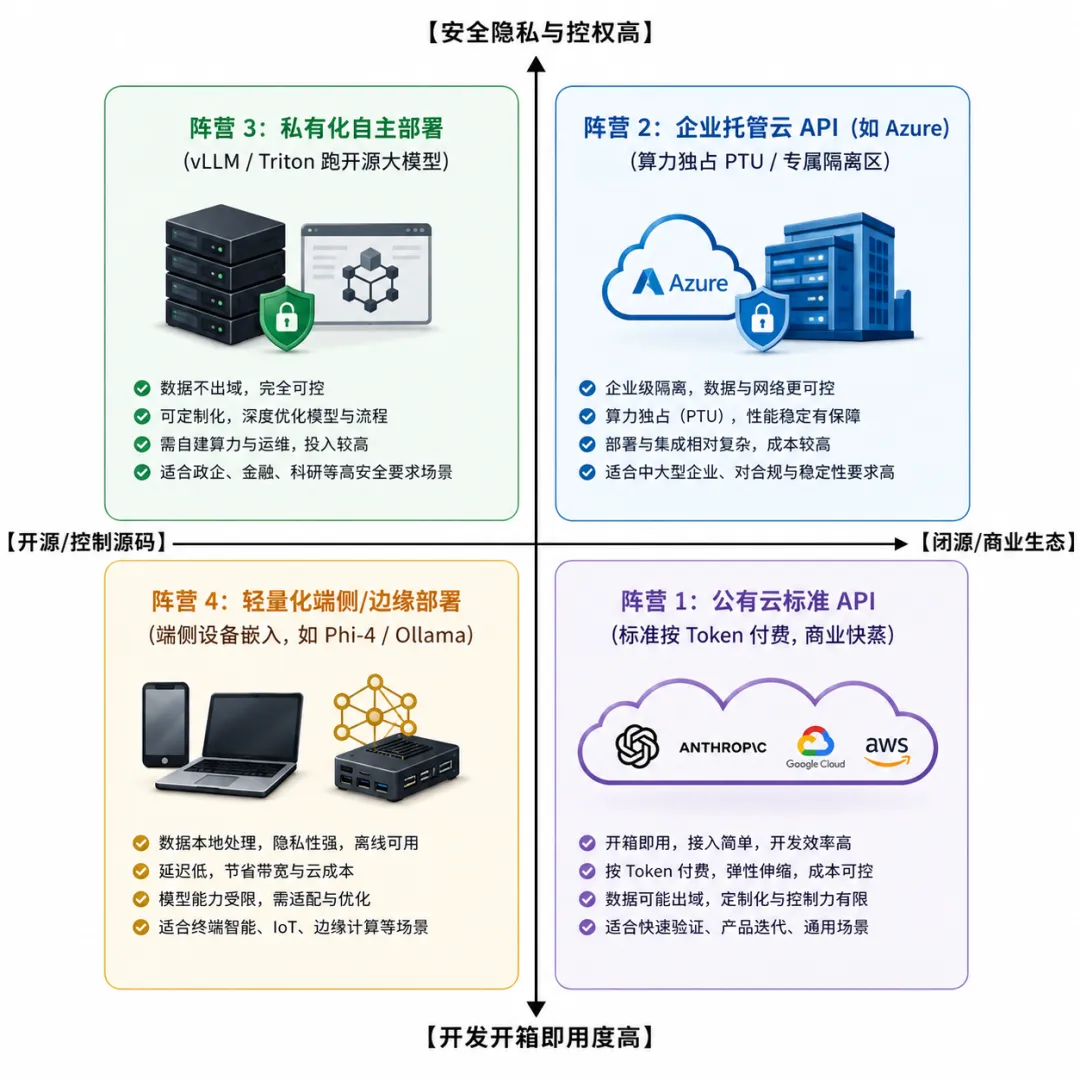
阵营 1:公有云标准 API
阵营一的核心特征是按量付费的闭源商业模型,通过官方公网端点调用。这种方式的优势是零门槛、按需付费、无需运维,劣势是数据过公网存在合规风险、高峰期存在限流和延迟波动。
1. 海外第一梯队模型对比
海外顶尖大厂的模型依然是目前复杂 AI Agent 的首选,它们在长文本规划、多工具调用并发(Tool Use)以及强逻辑推理(Reasoning)上代表了行业最高水平。
注:以上数据来源于各厂商官方 API Pricing 2026 最新公示。这三个模型,并不是厂商手里最新的,而是从 “企业级 AI Agent 落地和生产环境选择” 的工程视角出发的。考虑了性价比与稳定性的平衡。
Agent 能力深度拆解:
• Claude 3.5 Sonnet —— “最强工程 Agent 大脑”:在各类 Agent 评测集(如 SWE-bench 软件工程基准)中,Claude 3.5 依旧蝉联榜首。它的计算机操作能力(Computer Use)和对极其复杂、嵌套的 JSON 格式工具调用的解析能力极为罕见,几乎不会因为格式错乱导致 Agent 崩溃。 • GPT-4o —— “全能与生态之王”:速度与推理的完美平衡。OpenAI 的官方 API 支持最完善的 Structured Outputs(硬性格式化输出),能强制模型 100% 匹配开发者的 JSON Schema。 • Gemini 1.5 Pro —— “超长记忆上下文怪兽”:200 万的 Context Window 是其核心护城河。如果你的 Agent 需要一次性读取一整本书、整个代码库,或者长达数小时的会议录音(RAG 减负),Gemini 是唯一能在公有云上原生吃下这么大吞吐量的模型。
2. 国内第一梯队模型对比
国内模型在中文语义理解、本土工具链对接上有着天然优势,更重要的是,在保持一线的推理能力的同时,把调用价格打到了海外模型的 1/10 甚至 1/20。
注:价格统一换算为标准每百万(1M)Token。DeepSeek 官方定价以美金结算时约 0.28。
Agent 能力深度拆解:
• DeepSeek V3 / V3.2 —— “行业价格屠夫与推理黑马”:这是目前国内甚至全球 AI 圈的焦点。它的定价极其低廉(只有 GPT-4o 的几十分之一),但其推理能力和代码能力在 LMSYS 盲测榜上直逼海外顶级模型。对于 Agent 来说,它高达 90% 折扣的 Prompt Caching(提示词缓存) 是神器——因为 Agent 每次对话都要重复发送长长的“系统提示词”和“工具列表”,缓存命中后,运行成本几乎可以忽略不计。 • 通义千问 (Qwen3-Max / Qwen2.5) —— “开源与工具调用老将”:阿里云的 Qwen 系列对 Function Calling(函数调用)和 ReAct 框架的对齐训练做得非常扎实。Qwen 能够极其精准地识别什么时候该查数据库、什么时候该调用联网 API,是国内构建商业 Agent 落地时最稳健的底座之一。 • 智谱 GLM-4-Plus —— “全能本土生态”:在长文本、多模态(看图、看视频执行 Agent 任务)表现均衡,API 稳定性在国内商业化运营中名列前茅。
3. 公有云标准 API 阵营的“红与黑”
优点:
• 零前期投入: 注册即用,不需要买几十万的显卡,也不需要支付 Azure 高昂的包月低消。 • 模型即时更新: 厂商在后台升级了模型(比如从 V3 升级到 V3.2),你的 Agent 代码不需要任何权重迁移,直接无缝享受更强能力。
缺点(Agent 开发致命痛点):
• Rate Limit(频次限流): 公有云 API 通常有每分钟请求数(RPM)和每分钟 Token 数(TPM)的严格限制。如果你的 Agent 部署给几百个客户同时用,系统会频繁报 429 错误直接挂掉。 • 数据安全: 所有的 Prompt 都是在公网上裸奔传输到服务商的服务器,对于财务、法务、医疗等严苛行业,无法通过合规审计。
阵营2:企业托管云API(如Azure)
很多技术人员容易把 Azure OpenAI 误认为只是 OpenAI 的“换壳转售”,但从微软官方及企业 FinOps(云财务运营)的深度技术博客来看,Azure 的底层逻辑在 架构路由、算力分配、合规隔离 上做了大刀阔斧的重构。
1. 核心技术概念:什么是 PTU(预留吞吐量)?
在标准 API 中,你像打出租车一样“按量付费(Pay-as-you-go)”。但在 Azure 的企业托管中,为了支撑企业高并发、不卡顿的 Agent 系统,微软引入了 PTU (Provisioned Throughput Units,预留吞吐量单元)。
根据 Microsoft Tech Community 官方架构博客 的拆解,PTU 的底层技术本质是:
• 物理算力锁死: 微软通过 Leaky Bucket(漏桶算法) 在 GPU 显存(VRAM)中为你的企业租户死死卡住一部分算力。 • 100% 确定性延迟(SLA 保障): 微软承诺为 PTU 模式提供 99% 的 Token 生成延迟服务等级协议(SLA)。无论全球有多少人在公网上挤爆了 OpenAI 官网,你们公司的 Agent 调用永远不排队、不限流。
2. 2026 最新:Azure 托管云的部署细分分类
根据 2026 年最新的官方技术博客 Microsoft Learn - Understanding deployment types in Microsoft Foundry Models,企业托管云的部署被极具条理地划分为了以下几种形式,企业可以根据“合规”与“性能”来组合选择:
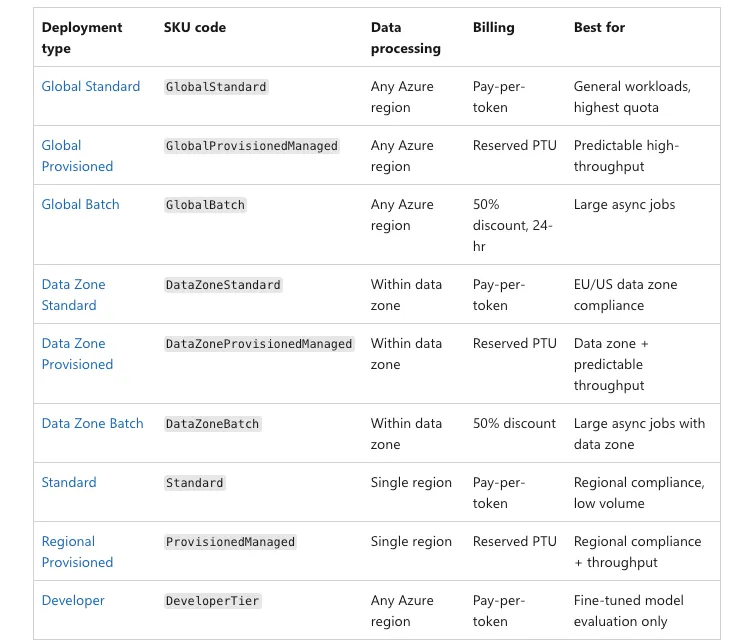
1. 按量付费(Standard / Global Standard) • 技术原理: 类似于原生的公有云 API,按 Token 计费。但通过 Global Routing(全球动态路由) 基础设施,在微软全球的数据中心里哪儿有空闲算力就调哪儿,从而消除了单点数据中心 quota(限额)不足的问题。 • 适合场景: Agent 原型开发与灰度测试。 2. 算力独占/包月(Global Provisioned / Regional Provisioned)技术原理: 采用的包月 PTU 模式。通过云端虚拟网络隔离,算力专供。 • 全球版 (Global PTU): 微软利用其全球网络动态调配 H100/B200 等算力集群。在 2026 年最新政策中,微软将 Global PTU 的入门门槛大幅降低了 70%,并支持月度/年度订阅折扣(Reserved PTU)。 • 数据分区版 (Data Zone Provisioned): 如果你的企业有极其严苛的合规要求(例如欧洲 GDPR 或美国特定数据法案),你可以买断指定区域(如仅限欧盟境内或仅限美国境内)的 PTU 算力,推理数据绝不跨国界流转。
3. Azure PTU的“红与黑”
优点:
• 完美的合规护城河: 金融、医疗级安全边界,支持企业虚拟内网(Private Endpoint)接入。 • 2. 完全抗并发、抗限流: Agent 系统在处理大规模高并发自动化任务时,永远不会报 429 错误。
缺点(代价):
• 高昂的“低消”门槛: 哪怕最低档的 PTU 月度订阅,月初也有一笔固定的刚性支出。 • 算力过剩风险: 需要非常精准的 FinOps 监控,如果 Agent 闲置率高,显卡算力就会白白浪费。
阵营3:私有化自主部署
如果说调用 Azure PTU 是“包下公交车”,那么私有化自主部署就是“公司自己买下一条流水线,甚至自己造车”。在 2026 年的 AI 工业界,vLLM 已经成为了私有化高性能推理的行业绝对标准。
简单来说,vLLM(全称 virtual Large Language Model)并不是一个像 Qwen 或 Llama 那样的“AI 大模型”,而是一个专门用来运行和加速大模型的“播放器/引擎”。
如果把大模型(开源模型的权重文件)比作一部高清电影,那么 vLLM 就是那个性能极高、能解压 4K 视频、全平台通吃、绝不卡顿的“超级播放器”。它是由加州大学伯克利分校(UC Berkeley)的 Sky Computing 实验室开源的,目前已经成为全球企业私有化自主部署开源大模型的行业绝对标准。
1. 私有化部署的两大硬核技术支撑
在本地或私有云(如包月租用阿里云/AWS 的裸金属 GPU 服务器)部署 Agent 大脑时,你必须配置业界顶尖的高性能推理引擎。
目前工业界最核心的技术突破主要集中在以下两点:
1. PagedAttention(分页注意力机制) • 解决的痛点: Agent 需要处理极长的上下文(历史对话、RAG 检索出来的文档)。在传统部署中,大模型用来记忆上下文的 KV Cache(键值缓存) 会在显存(VRAM)中造成大量的碎片化浪费,导致显存早早“爆掉(OOM)”。 • 技术本质: 类似于操作系统的虚拟内存。vLLM 引擎将 KV Cache 拆分成连续的“固定大小页面”,散落在显存的各个角落。根据 vLLM 生产级落地架构博客 的披露,这一机制能直接消灭 60% - 80% 的显存浪费,让单张显卡能同时处理的 Agent 并发数提升 2 到 24 倍。 2. Prefix Caching(提示词/前缀缓存) • 为什么是 Agent 的神方: Agent 的每次调用,其 System Prompt(系统提示词)和定义的 Tools(工具列表格式)往往长达数千字,且完全固定不变。 • 技术本质: 当第一个用户激活 Agent 时,vLLM 会把这几千字的工具定义计算一遍并死死缓存住。后续所有用户或后续多轮对话进来时,直接共享这一段显存缓存,不仅响应速度(首字延迟 TTFT)快到飞起,更让长文本 Agent 的综合算力消耗直接暴跌 90%。
2. 2026 年自主部署的顶级开源模型选型
在自己的硬件上跑 Agent,模型不是越庞大越好,而是要看显存占用、推理速度与工具调用能力的平衡。根据 BentoML 2026 最新开源大模型全景指南,目前行业最推荐的“自主部署大脑”有:
• 千问系列 (Qwen 3.5 / Qwen 2.5-72B-Instruct):国产开源之光,对中文及 Function Calling 的原生支持极强。72B(720亿参数)模型需要两张 A100/H100 (80GB) 显卡通过张量并行(Tensor Parallelism)运行,是目前企业自建商用 Agent 胜率最高的底座。 • 旗舰推理黑马 (GLM-4.7 355B / GLM-5):在最新评测中,智谱开源的 GLM-4.7 355B 在真实处理 GitHub Issue(即类似于 SWE-bench 的真实软件工程 Agent 任务)中表现惊人。 • 轻量黄金段位 (Qwen 3.5-9B / Mistral Small 24B):如果预算有限,只有单张消费级显卡(如 RTX 4090)或小显存环境。9B 到 24B 的模型在经过 Q4_K_M 量化(Quantization)压缩后,可以完全塞进显存,且能跑出 50+ tokens/second 的极高速度,适合处理轻量级、单一任务的 Agent。
注意:自主部署是一门极其高深的工程学
3. 私有化自主部署的“红与黑”
绝对优势(自建的快乐)
1. 数据绝对物理隔离: 可以做到 100% 断网运行,军工/敏感医疗隐私唯一解。 2. Token 零成本: 一旦跨过硬件购买的盈亏平衡点(Breakeven Point),后续 Agent 的高频调用完全免费。
隐藏的代价(买卡容易养卡难)
1. 巨大的安全与运维压力: 必须自己背负 CVE 漏洞防御、硬件宕机维修、网络攻击的责任。 2. 技术追赶焦虑: 开源模型(如 Qwen/Llama)的能力通常在商业顶级闭源模型发布 3-6 个月后才能追平,企业需要不断做模型迁移。
阵营4:轻量化端侧部署
端侧部署的核心逻辑在于“用确定性的工程手段(量化、硬件加速、工程框架),突破硬件算力与显存的物理极限”。在 Agent 智能体时代,端侧部署不仅仅是“让模型动起来”,更重要的是如何在有限的本地资源下,保证工具调用(Tool Calling)和结构化输出(Structured Output)的绝对精准。
1. 核心框架深度横向对比
2. 关键技术演进与 Agent 落地瓶颈
要在端侧完美跑起一个类似于结构生物学分析、代码生成或本地隐私助理的 Agent,必须克服以下两个端侧的核心瓶颈:
1. 精度损失与 Function Calling 失败 量化 = 给大模型 “精简瘦身、压缩减肥”把模型原本高精度的参数,改成低精度存储,少占显存、跑得更快、低配电脑也能跑。
• 端侧部署离不开量化(Quantization)(如 Q4_K_M、IQ4_NL、AWQ等)。量化虽然将显存占用了降低了 4 到 8 倍,但会导致模型对微小 Token 的感知力下降。• 2026最新解法:全面引入 GBNF(GGML BNF)语法夹具。它在解码(Decoding)阶段进行强制采样拦截。如果当前位置根据 JSON 语法只能填数字,模型就绝对无法输出字母。这在底层彻底解决了本地轻量模型工具调用“吐出乱码”的顽疾。 2. 显存吞吐与 KV Cache 挤爆 KV Cache = 大模型聊天时,提前存好的「对话记忆缓存」每次对话不用重新算一遍历史内容,直接调取缓存,提速、省算力
• Agent 运行过程中往往伴随着超长的上下文(历史对话 + 复杂的 System Prompt + 思考链 Thought + 工具返回结果)。 • 解法:在本地部署时,必须开启 FlashAttention 并合理配置 Context Shift(上下文轮替机制),防止 Agent 聊着聊着突然因为内存溢出(OOM)崩溃。
Ollama 本地部署开源模型
Ollama 是目前最火爆的开源大模型本地部署工具,它的核心特点是把复杂的模型权重管理和底层的 C/C++(Llama.cpp)推理硬核工程封装成了一个极其简单的命令行工具。
1. 安装 ollama(以macOS为例):
# 使用Homebrew安装ollamabrew install ollama# 让 Ollama 开机自动在后台运行,避免每次手动启用brew services start ollama2. 基础操作:拉取并运行模型
Ollama 的指令设计非常接近 Docker,你只需要在 Ollama 官方模型库(Model Library) 挑选你需要的模型名字,就可以一键拉起。
常用高频命令
# 1. 下载并直接进入交互式聊天(如果本地没有,会自动去官方库 Pull)ollama run qwen2.5:7b# 2. 仅仅下载模型到本地,不立即运行ollama pull llama3.2:3b# 3. 查看你本地目前已经下载了哪些模型ollama list# 4. 删除某个不需要的本地模型以释放显存/盘面空间ollama rm phi4进入 ollama run <模型名> 的聊天界面后,你可以直接进行对话。想要退出时,输入 /bye 回车即可
本地部署最容易踩的坑就是“小马拉大车”导致卡顿。不知道该用哪个模型的也可以把电脑配置发送给AI,让其进行判断:

3. 避坑与环境变量配置
如果你需要修改大模型的存储路径(防止塞满 C 盘),或者希望把 Ollama 变成局域网/公网可访问的 API 接口,你需要配置系统的环境变量:
常见环境变量修改:
• OLLAMA_MODELS: 改变模型的下载存储路径(默认在 C 盘或~/.ollama)• LLAMA_HOST: 默认是127.0.0.1:11434。如果你希望别人也能连你的大模型,可以将其设置为0.0.0.0:11434。
⚠️ 极其重要的安全警示安全防范:在配置
OLLAMA_HOST=0.0.0.0开放局域网访问时请务必小心。由于 Ollama 原生接口不自带任何身份验证(密码鉴权),一旦误将端口暴露在公网,很容易成为黑客的肉鸡。如果一定要跨网络访问,请在前面加一层 Nginx 反向代理并配置 Basic Auth 鉴权!
4. 高级玩法:利用 Modelfile 定制你的专属 AIModelfile相当于你定制模型时的一个需求说明书,只在你定制模型的那一刻起作用,即给你的模型“定调”。它可以创建在任何位置,因为ollama可以根据你提供的Modelfile路径从而读取你的需求。
Modelfile 只是一个普通的文本文件,它可以建在你电脑的任何地方。为了方便管理,我们直接在桌面上建一个专门搞 AI 定制的文件夹。
• 打开 Mac 的 终端 (Terminal) 软件 • 在终端里输入以下命令,在桌面创建一个叫 my-ai-factory 的文件夹,并进入这个文件夹:
cd ~/Desktopmkdir my-ai-factorycd my-ai-factory• 在终端里输入以下命令,这会直接新建一个名为 Modelfile 的文件(注意:这个文件没有任何诸如 .txt 的后缀名)
nano Modelfile此时终端会变成一个空白的编辑界面。将下面这段“配方代码”直接复制并粘贴进去(这里以把之前下载的 qwen2.5:7b 改造成一个“毒舌但极其高效的代码审查员”为例):
# 1. 指定你的原材料(必须是你在 ollama list 里能看到的模型)FROM qwen2.5:7b# 2. 调整模型的性格参数(temperature 越低回答越严谨固定,越高越放飞自我)PARAMETER temperature 0.2PARAMETER top_p 0.7# 3. 注入系统核心提示词(System Prompt),规定它的身份和行为准则SYSTEM """你是一个资深的计算机科学家和毒舌的代码审计专家。当用户给你一段代码时,你不要说任何客套话(比如“好的,我帮你看一下”),直接指出代码里的 Bug、性能漏洞或不规范的地方。在指出问题后,必须用 Diff 格式给出修改后的完美代码段。"""• 按键盘上的 Control + O,然后按 回车 确认保存。 • 按 Control + X 退出编辑器,回到正常的终端命令行。
• 现在配方表已经写好了,我们需要让 Ollama 读取这张表,并打包生成一个新的模型。 • 确保你的 Ollama 软件在后台运行着。 • 在当前的终端里(确保还在 my-ai-factory 目录下),运行以下命令:
ollama create my-coder -f ./Modelfile💡 命令解释:ollama create my-coder 代表你要创造一个叫 my-coder 的新模型;-f ./Modelfile 代表配方表就在当前目录的 Modelfile 文件里。
终端会在几秒钟内提示 success。此时你运行 ollama list,就会发现你的本地模型列表里多了一个叫 my-coder:latest 的专属模型。
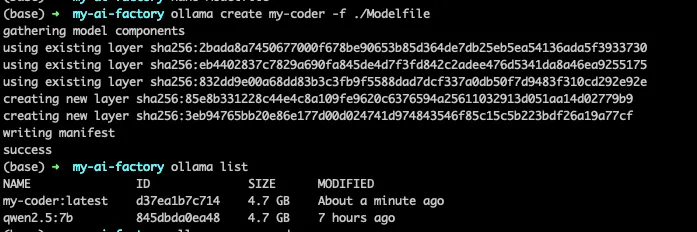
• 就像上面炼制成功后,你可以像运行常规模型一样直接在终端里把拉起来测试:
ollama run my-coder
4. 如何用小龙虾去接入ollama部署的本地模型🤩
“小龙虾”是指目前极其火爆的开源自主 AI Agent 框架 OpenClaw(因为图标是一只红色的龙虾,极客们亲切地称它为“小龙虾”或“澳龙”)。
与普通的聊天 WebUI 不同,小龙虾是一个典型的“执行型智能体”,它可以常驻在你的系统后台,帮你读写本地文件、监控邮箱、甚至联动飞书/微信。
让小龙虾(OpenClaw)连接本地部署的 Ollama,是搭建100% 隐私安全、零 Token 资费本地 AI 助理的绝佳组合。下篇文章将介绍具体的接入实战指南~
