 夜雨聆风
夜雨聆风上周,一位做了8年功能测试的朋友跟我吐槽:
"群里都在聊AI自动化,领导也开始问'你们能不能用AI提效'。我连Python都写不利索,感觉自己随时要被淘汰……"
这种焦虑,我几乎每天都在社群里看到。AI大模型一夜爆火,铺天盖地的"AI替代测试"文章让人心慌。但冷静下来想想——你真的了解大模型能做什么、不能做什么吗?
这篇文章不贩卖焦虑,不鼓吹技术,只做一件事:帮你看清AI在测试领域的真实能力边界。看完之后,你就知道该担心什么,该学什么,以及——焦虑根本没必要。
大模型能帮测试人做什么?
别急,先看看这8个你今天就能用起来的场景
📌 场景一:智能生成测试用例
输入需求描述,让大模型帮你生成结构化测试用例。这是目前最成熟、最高频的使用场景。
💡 Prompt 示例:
1. 支持手机号+验证码和账号密码两种方式 2. 连续5次密码错误锁定账号30分钟 3. 支持"记住我"功能,有效期7天 |
✅ 生成后由你审核、补充,效率提升3-5倍。
📌 场景二:自动化脚本生成与调试
不会写代码?让AI帮你写。把你想要的操作用自然语言描述清楚,它就能输出可运行的脚本。
💡 Prompt 示例:
1. 打开Chrome浏览器 2. 访问 https://example.com/login 3. 输入用户名"testuser"和密码"Test@123" 4. 点击登录按钮 5. 验证跳转到首页(URL包含/dashboard) 6. 截图保存到 ./screenshots/ 目录 请添加异常处理和日志输出。 |
📌 场景三:缺陷报告智能补全
发现了bug但写缺陷报告头疼?把现象描述扔给AI,它帮你整理成标准的缺陷报告格式。
💡 输入:
"在购物车页面,商品数量输入负数后点结算,页面白屏了,控制台报错 TypeError"🎯 AI输出标准缺陷报告:
标题:购物车-输入负数商品数量后结算导致页面白屏 |
📌 场景四:测试数据批量生成
造测试数据是体力活。让AI帮你批量生成手机号、身份证号、订单号、各种边界值数据,甚至直接输出SQL插入语句。
- 手机号:真实号段格式 - 年龄:覆盖0、17、18、65、66、100等边界值 - 邮箱格式:包含无效格式(缺少@、缺少域名等) 以CSV格式输出,可直接用于Postman批量导入 |
📌 场景五:接口文档快速评审
拿到一份API文档,让AI帮你做初步评审——检查字段缺失、状态码不一致、鉴权逻辑漏洞等。
✅ 实战技巧:把Swagger/OpenAPI的JSON直接贴给大模型,让它按照你的评审Checklist逐项检查。
📌 场景六:日志分析与缺陷定位
几百行的报错日志看不过来?让AI帮你快速定位关键信息:错误类型、调用链路、可能原因。
📌 场景七:测试报告自动生成
把测试执行结果数据给AI,自动生成结构化的测试报告——含图表建议、风险分析、结论。
📌 场景八:新人/转岗测试知识答疑
相当于一个24小时在线的技术导师。问什么答什么,从测试理论到工具使用,比搜索引擎更精准。
 小结:以上8个场景的共同特点是——AI负责生成初稿,你负责审核把关。它是你的效率放大器,不是你的替身。
小结:以上8个场景的共同特点是——AI负责生成初稿,你负责审核把关。它是你的效率放大器,不是你的替身。
大模型不能做什么?看清限制,才能用好工具
❌ 1. 无法独立执行端到端测试
大模型可以生成脚本,但它不能帮你启动浏览器、点击按钮、观察结果、判断通过与否。它没有手,没有眼,更没有你们系统的账号权限。
🔴 本质:AI是"脑",自动化框架是"手"。只有脑没有手,测试执行不了。
❌ 2. 无法理解未表达的业务逻辑
你写"用户可以登录",AI能想到密码校验、验证码过期等通用场景。但"用户在凌晨2点到5点之间登录需要二次验证"这种业务特有规则,如果你不说,它永远猜不到。
❌ 3. AI幻觉——会一本正经地胡说八道
这是大模型最危险的特点。它不会告诉你"我不知道",而是编造一个看起来合理的答案。比如推荐一个不存在的API方法,引用一篇不存在的论文,或者生成一段语法正确但逻辑完全错误的代码。
🔴 防御策略:所有AI输出必须验证!特别是代码、数据、技术方案——逐行看,逐条跑。
❌ 4. 无法处理高度敏感的数据
医疗数据、金融交易、用户隐私信息——这些敏感数据不能直接粘贴到公开的大模型对话中。这是数据安全红线,不是AI的能力问题。
⚠️ 最佳实践:敏感数据必须脱敏后再输入。有条件的团队建议部署私有化大模型(如本地跑Llama、Qwen等)。
❌ 5. 无法替代测试人的判断力
"这个bug该不该报?" "这个用例优先级是P0还是P2?" "线上这个异常影响范围有多大?"——这些需要经验、业务理解和上下文判断的问题,AI给不了你准确的答案。它能给参考,但拍板的人是你。
❌ 6. 无法保证输出的一致性
同一个问题问三遍,大模型可能给出三个不同质量的答案。它没有"标准答案",每次输出都是概率生成。这对需要高度一致性的测试标准来说是硬伤。
大模型在测试各阶段的能力边界
一张表看清AI在每个测试阶段能帮你多少
| 强辅助 | |||
| 强辅助 | |||
| 弱辅助 | |||
| 中等 | |||
| 强辅助 | |||
| 强辅助 | |||
| 弱辅助 |
🔧 主流大模型在测试场景的表现对比
如何正确使用大模型辅助测试
一套经过实战验证的工作流
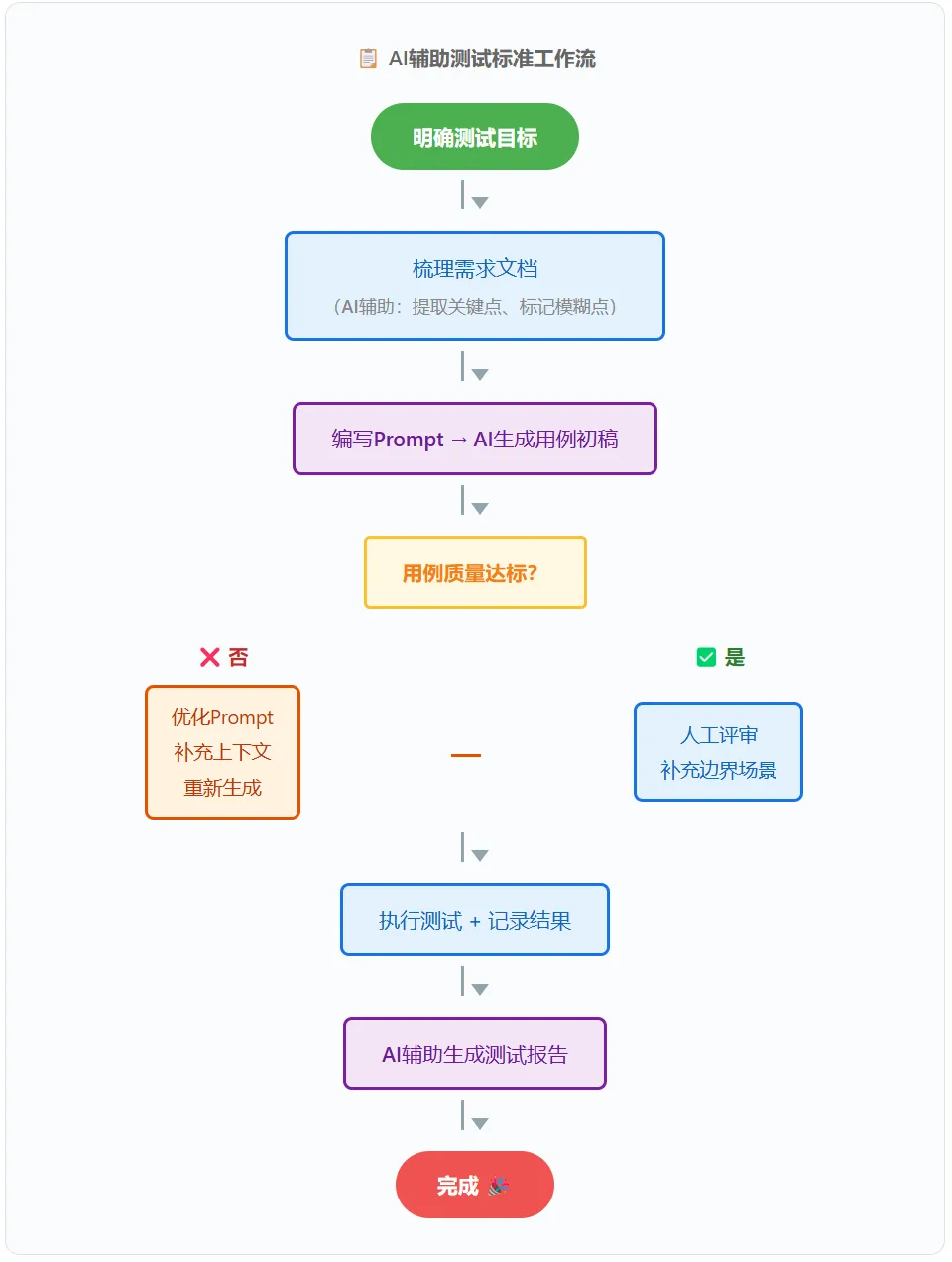
🎯 Prompt Engineering 实用技巧
✅ 好的Prompt四要素: 1️⃣ 角色定义:告诉AI你是谁——"你是一个有10年经验的金融系统测试专家" 2️⃣ 明确任务:具体告诉它做什么——"生成等价类划分的测试用例" 3️⃣ 约束条件:限定输出格式——"用Markdown表格,包含用例编号和优先级" 4️⃣ 示例参考:给一个你满意的结果样本——"参考以下示例风格:..." |
❌ 常见误区:
• "帮我写个测试用例" → 太空泛,AI不知道测什么系统
• "像上次那样写" → AI没有"上次"的记忆(除非在同一对话中)
• 直接粘贴整个PRD → 信息过载,AI反而抓不住重点
从AI工具到AI思维:测试人的进化路径
不用焦虑被替代,但要主动进化
🟢 Level 1:AI工具使用者(1-2周上手) 会用ChatGPT/通义千问生成用例、写缺陷报告、整理文档。重点:学会写好Prompt。 |
🔵 Level 2:AI+自动化结合者(1-3个月) AI生成自动化脚本 → 调试完善 → 集成到CI/CD流水线。掌握Python/Selenium/Playwright基础。 |
🟣 Level 3:AI测试架构师(3-6个月) 能搭建AI辅助测试平台,利用API调用大模型能力,将AI融入团队测试流程。 |
🟠 Level 4:AI思维测试专家(持续进化) 不只是用AI工具,而是用AI思维重新思考测试策略:哪些环节适合AI介入?如何设计"人机协作"的最优解?如何评估AI辅助的效果? |
📌 核心观点:AI不会淘汰测试工程师,但会用AI的测试工程师会淘汰不会用的。这条路不需要你成为程序员,只需要你愿意迈出第一步。
 |
