 夜雨聆风
夜雨聆风Harness Engineering:让 AI Agent 从“会聊天”走向“能干活”的关键工程能力
在过去一年里,AI Agent 的讨论越来越多。很多人关注模型本身:哪个模型更聪明、哪个模型代码能力更强、哪个模型推理更稳定。但在真实项目里,你会发现一个问题:模型能力很强,并不等于 Agent 就能稳定完成任务。
一个能真正落地的 AI Agent,除了需要强大的大模型,还需要一套包裹在模型外面的工程系统。这个系统负责给模型提供上下文、接入工具、控制流程、验证结果、处理失败、记录过程,并在必要时让人介入。
这套工程方法,就可以称为:Harness Engineering。
一、什么是 Harness Engineering?
在 AI Agent 领域,Harness 可以理解为:
包裹在大模型外面的“控制框架、执行环境和约束系统”。
如果说大模型是 Agent 的“大脑”,那么 Harness 就是 Agent 的“身体、工具、流程、记忆和安全系统”。
一个裸模型只能根据输入生成回答:
用户问题 → 大模型 → 回答而一个真正可用的 Agent 应该是:
用户任务 → Harness → 大模型 → 工具执行 → 验证结果 → 失败恢复 → 最终报告所以,Harness Engineering 关注的不是模型本身怎么训练,而是如何让模型在真实任务中稳定、可控、可验证地工作。
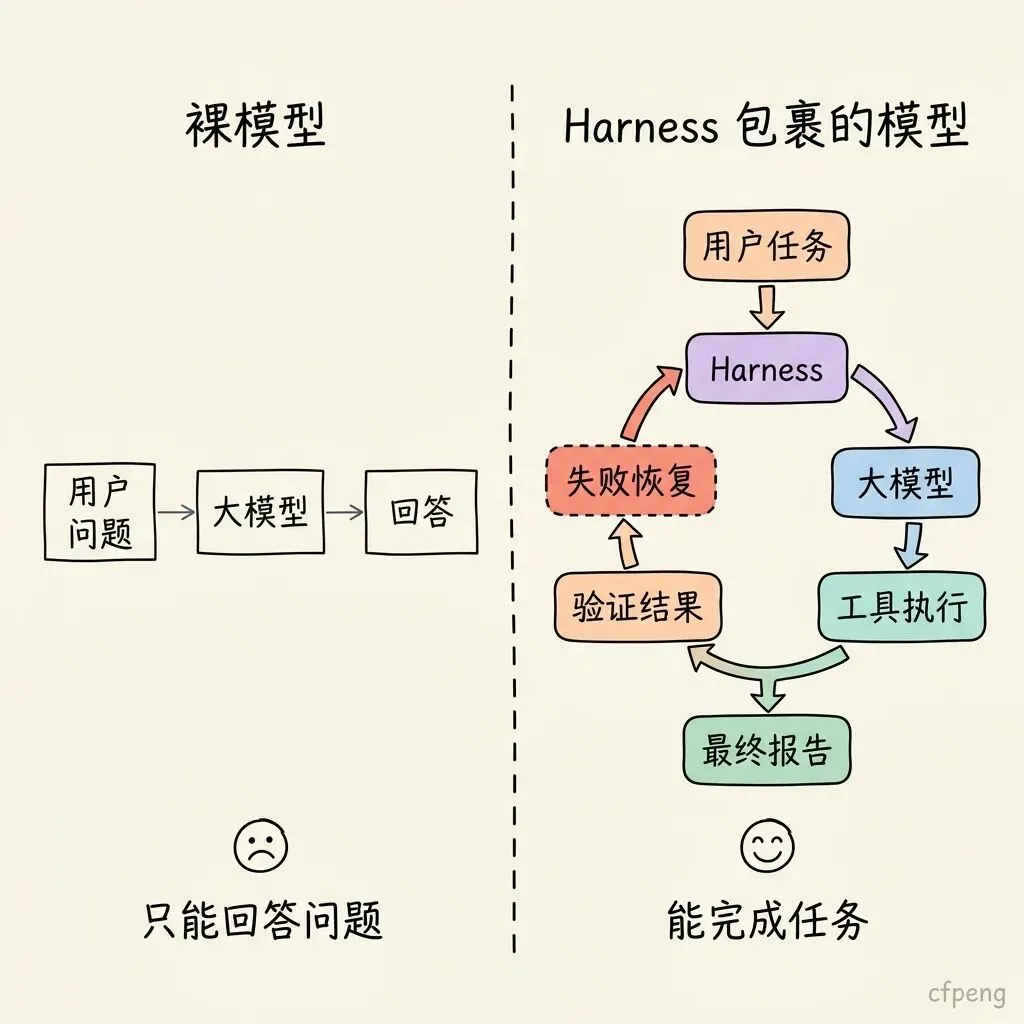
二、为什么需要 Harness Engineering?
很多 AI Agent 在 Demo 阶段看起来很惊艳,但进入真实项目后就会暴露问题。
比如:
看错文件; 忽略关键日志; 修改了不该改的代码; 没有运行测试就说任务完成; 出错后反复尝试同一种错误方案; 做到一半忘记原始目标; 无法展示当前进度; 用户不知道它到底做了什么。
这些问题很多并不是因为模型“不够聪明”,而是因为 Agent 外部的工程控制系统不完整。
换句话说:
AI Agent 的稳定性,不只取决于模型能力,更取决于 Harness 设计能力。
一个好的 Harness,可以让 Agent 从“能回答问题”变成“能完成任务”。
三、Harness Engineering 和 Prompt Engineering 有什么区别?
很多人会把 Harness Engineering 和 Prompt Engineering 混在一起。其实它们不是一个层级的问题。
Prompt Engineering 更像是:
怎么写好一条指令。
Harness Engineering 更像是:
如何设计一套完整的 Agent 运行系统。
例如,用户说:
帮我修一下这个 Spring Boot 项目的启动错误。Prompt Engineering 可能会设计一段更好的提示词:
你是一个资深 Spring Boot 工程师,请根据错误日志分析问题并给出修复方案。但 Harness Engineering 要考虑的是完整流程:
1. 读取错误日志2. 搜索相关配置文件3. 定位可能的 Bean、依赖、数据库或环境问题4. 读取相关源码5. 提出最小修改方案6. 修改代码或配置7. 运行测试或启动命令8. 如果失败,重新分析错误9. 成功后输出根因、修改点和验证结果
这就是两者的本质区别。
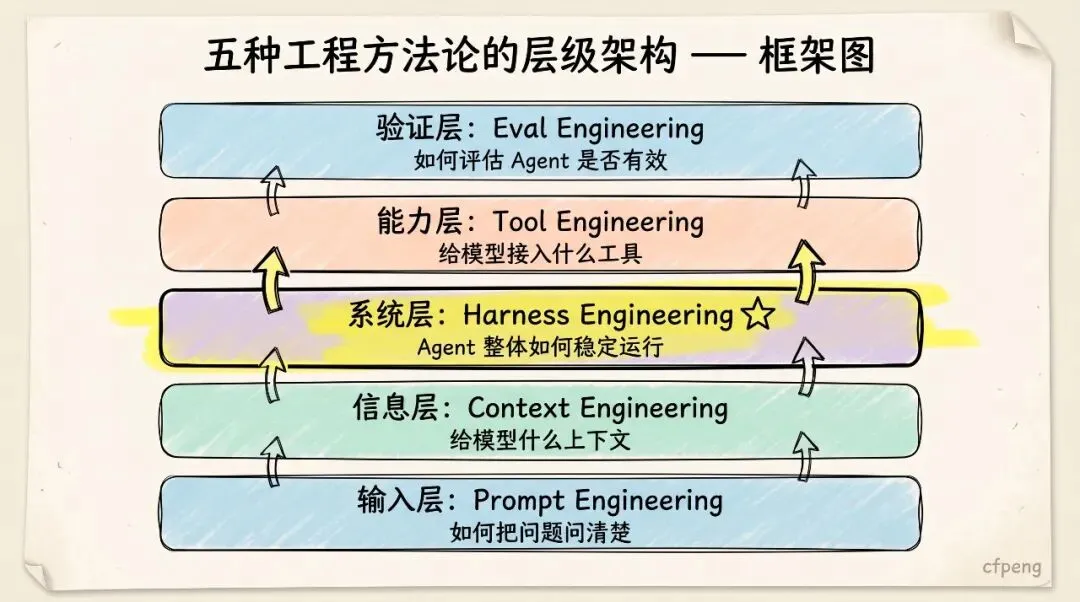
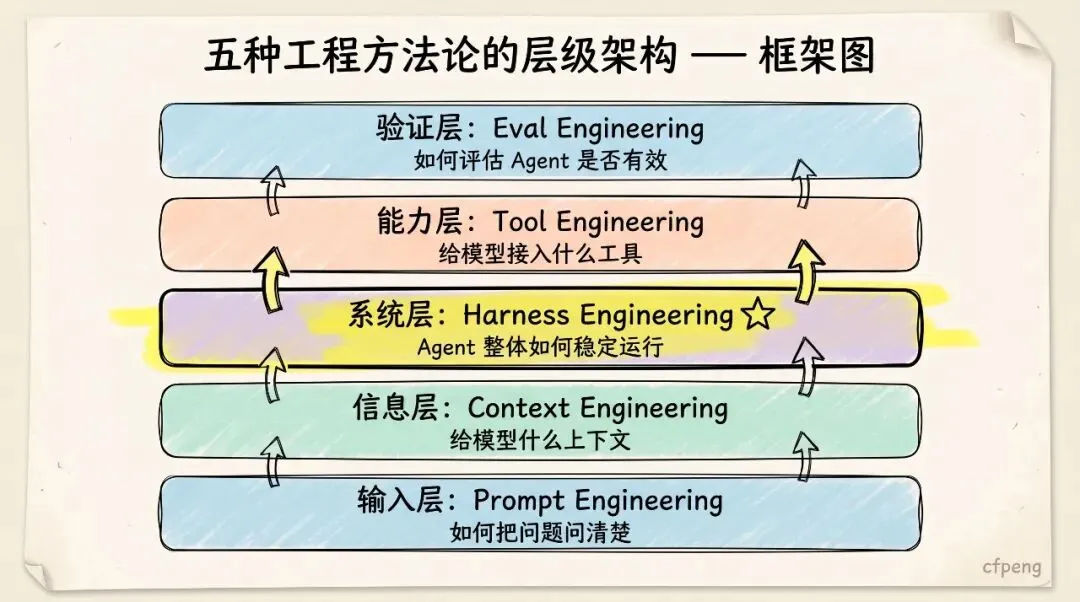
四、Harness Engineering 的核心架构
一个完整的 AI Agent Harness 通常可以分为以下几层:
它不是一个简单的“模型调用链”,而是一套完整的任务执行系统。
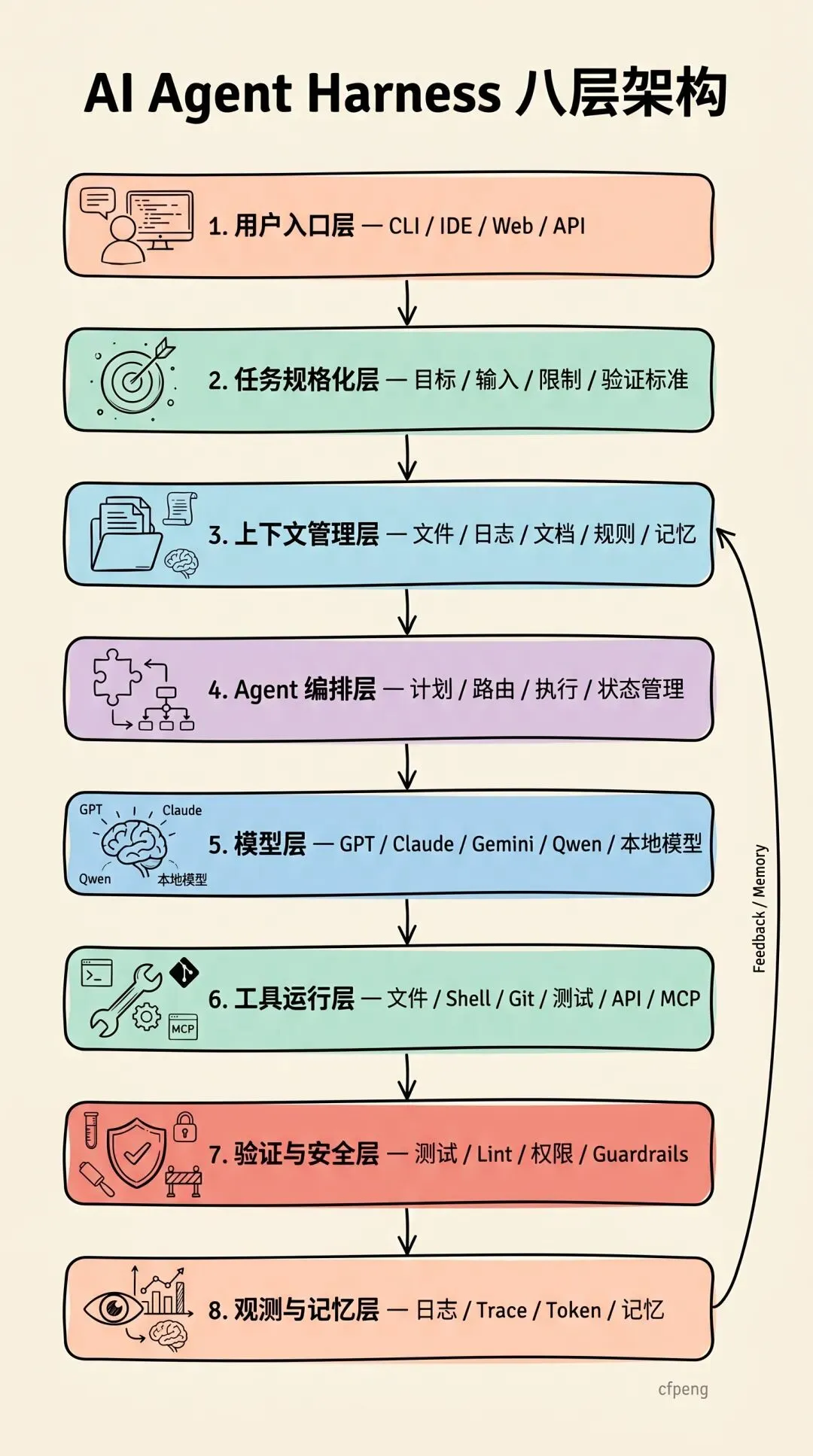
五、Harness Engineering 架构图
下面是一张完整的 AI Agent Harness Engineering 架构图:
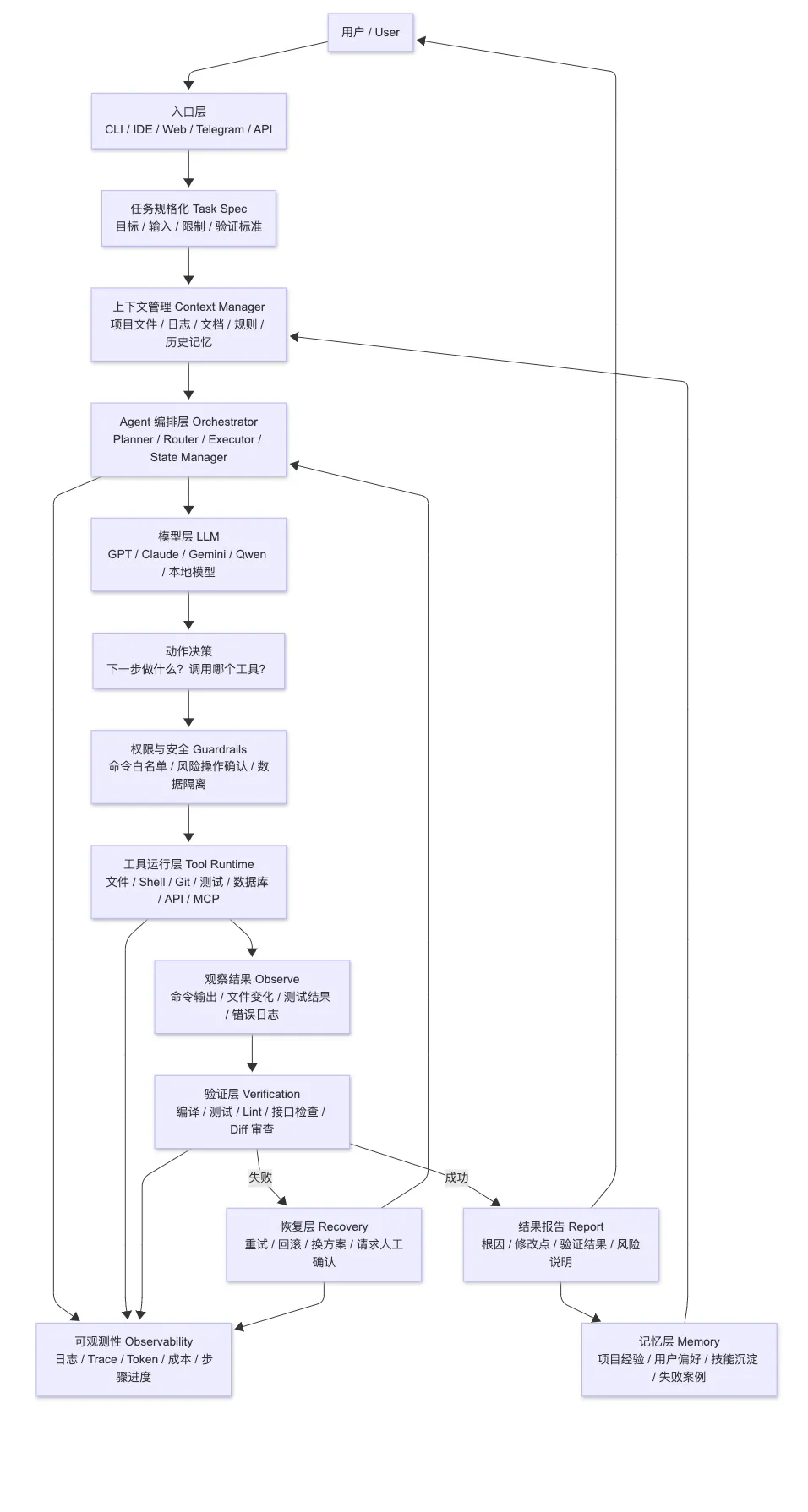
如果用一句话概括这张图:
Harness Engineering 就是给大模型外面加上一套“上下文系统、工具系统、流程系统、验证系统、安全系统、观测系统和记忆系统”。
六、各模块分别解决什么问题?
1. 用户入口层:让 Agent 可以被调用
用户入口层负责接收任务和返回结果。
常见入口包括:
命令行 CLI; IDE 插件; Web 控制台; Telegram Bot; Slack Bot; API 接口; 企业内部系统入口。
例如 Hermes Gateway、Claude Code、Codex CLI、Cursor Agent,都有自己的用户入口。
这一层不仅负责收发消息,还要展示进度、处理确认、展示结果。
2. 任务规格化层:把模糊需求变成明确任务
用户的表达通常是自然语言,而且经常比较模糊。
比如:
帮我看看这个项目为什么启动失败。Agent 不能直接开始乱改,而应该先把任务结构化:
目标:修复项目启动失败输入:错误日志、配置文件、源码、依赖信息限制:不要大范围重构,不要修改无关业务逻辑验证标准:项目能成功启动,相关测试通过输出:根因、修改文件、验证结果、风险说明
任务规格化可以防止 Agent 目标漂移,也方便后面的验证和审计。
3. 上下文管理层:决定给模型看什么
Agent 不是知道所有事情,它需要上下文。
但真实项目里,代码、文档、日志、历史记录可能非常多,不可能全部塞进模型上下文。
所以 Context Manager 要负责选择:
当前任务需要哪些文件; 哪些日志最关键; 是否需要读取 README、AGENTS.md、项目规范; 是否需要加载历史经验; 哪些内容需要摘要; 哪些敏感信息不能进入模型上下文。
对于开发类 Agent,上下文通常包括:
README.mdAGENTS.mdpom.xml / build.gradle错误日志相关 Controller / Service / Repository配置文件 application.ymlGit diff历史类似问题
上下文给得太少,Agent 容易误判;上下文给得太多,Agent 容易混乱。因此 Context Engineering 是 Harness Engineering 的关键组成部分。
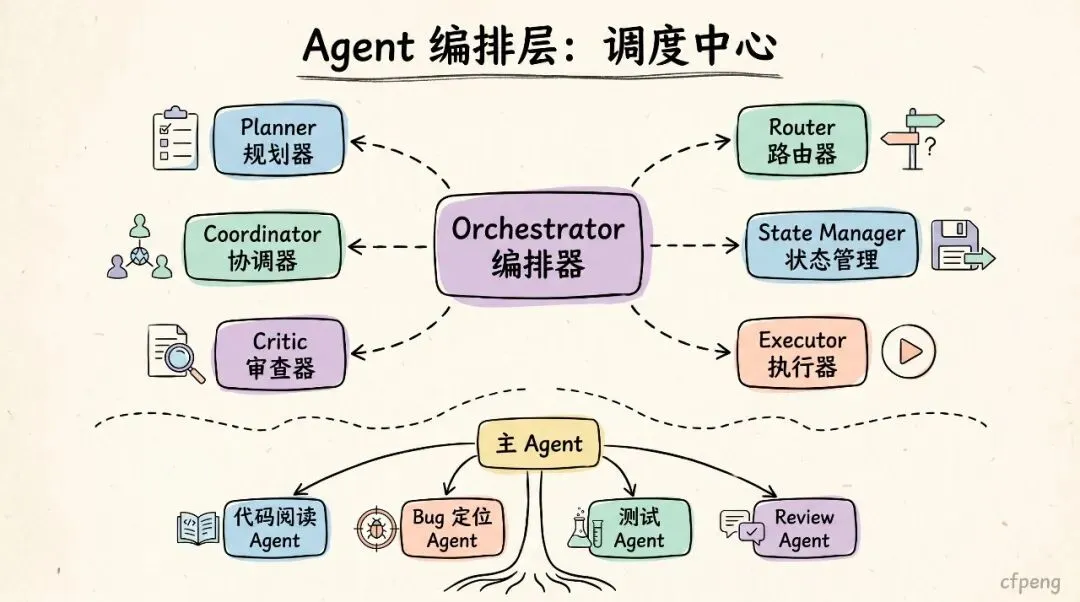
4. Agent 编排层:决定下一步做什么
Orchestrator 是 Harness 的调度中心。
它负责决定:
当前任务应该由哪个 Agent 处理; 下一步是规划、读文件、执行命令,还是验证结果; 是否需要调用子 Agent; 什么时候停止; 什么时候进入错误恢复流程。
典型组件包括:
比如一个开发 Agent 可以拆成:
主 Agent├── 代码阅读 Agent├── Bug 定位 Agent├── 测试 Agent└── Review Agent
编排层决定这些 Agent 如何协作。
5. 模型层:负责推理、生成和决策
模型层就是大语言模型本身。它可以是:ChatGPT、Qwen、DeepSeek、本地 vLLM。在 Harness Engineering 里,模型很重要,但模型不是全部。
更准确地说:
模型 = 推理引擎Harness = 执行系统
模型负责理解、推理、生成方案;Harness 负责把方案放进真实环境里执行、验证和约束。
6. 工具运行层:让 Agent 真正能做事
没有工具的 Agent,本质上还是聊天机器人。
工具层让 Agent 可以操作真实世界:
read_filewrite_filesearch_coderun_shellgit_diffgit_commitrun_testsquery_databasecall_apibrowser_searchmcp_tools
但工具不是越开放越好。
一个好的 Tool Runtime 必须包含权限控制:
哪些目录可以读; 哪些目录可以写; 是否允许删除文件; 是否允许执行危险命令; 是否允许访问数据库; 是否允许提交代码; 是否允许部署生产环境。
工具层的关键不是“给 Agent 无限能力”,而是“给 Agent 可控能力”。
7. 验证层:不能让 Agent 自己宣布成功
这是 Harness Engineering 最重要的一层。
Agent 很容易出现一种问题:
它说完成了,但其实没有验证。
因此,完成任务不能只看模型输出,而要看外部验证结果。
对开发 Agent 来说,验证方式包括:
编译是否通过; 单元测试是否通过; Lint 是否通过; 接口是否返回正确; 页面是否正常打开; 日志是否还有异常; Git diff 是否符合预期。
例如修复 Spring Boot 项目时,可以运行:
./gradlew test./gradlew bootRunmvn testcurl http://localhost:8080/health
一个可靠 Agent 应该形成验证闭环:
执行 → 验证 → 失败 → 分析原因 → 重新执行 → 再验证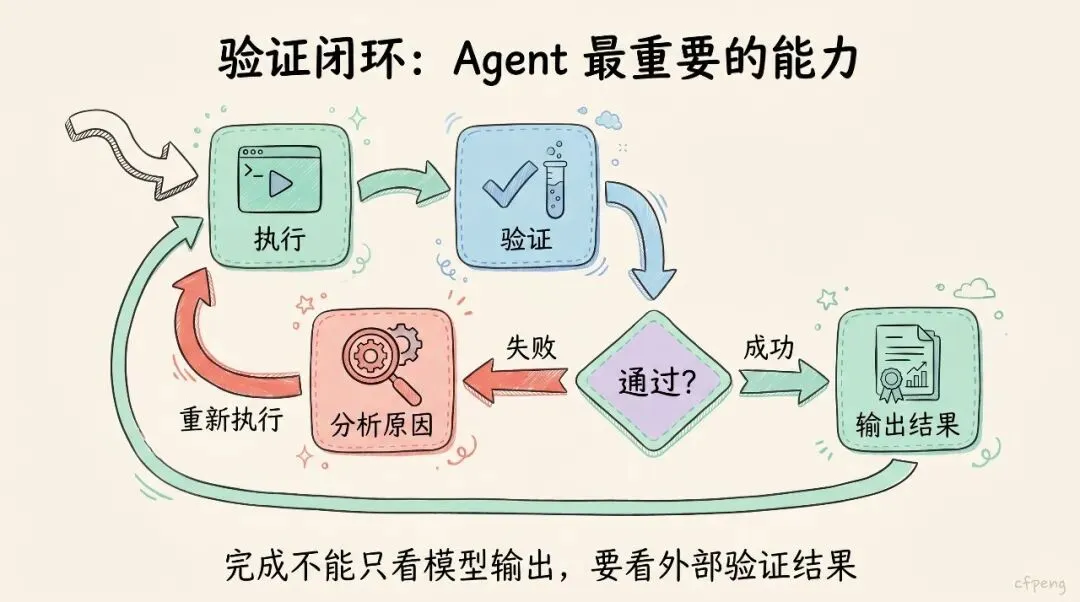
8. 安全约束层:防止 Agent 乱来
Guardrails 负责约束 Agent 的行为。
常见限制包括:
禁止删除用户目录; 禁止操作生产数据库; 禁止泄露密钥; 禁止自动部署生产环境; 禁止大范围重构; 禁止修改无关文件; 高风险命令需要人工确认。
例如这些操作应该默认拦截或要求确认:
rm -rf /DROP DATABASEgit push --forcekubectl delete namespace
AI Agent 越强,越需要安全边界。
9. 记忆层:让 Agent 不要每次从零开始
Memory 可以分为几类:
例如一个长期服务你的开发 Agent,可以记住:
项目启动命令是什么测试命令是什么常见错误如何排查代码风格是什么用户更喜欢详细解释还是直接给命令哪些方案之前试过但失败了
有了记忆,Agent 才能从“一次性问答”变成“长期协作伙伴”。
10. 可观测性层:让用户知道 Agent 做了什么
可观测性是很多 Agent 产品目前的短板。
一个好的 Harness 应该能清楚展示:
当前执行到哪一步; 读了哪些文件; 执行了哪些命令; 修改了哪些代码; 为什么这么改; 测试结果是什么; Token 消耗是多少; 失败了几次; 是否回滚过。
如果没有可观测性,用户只能看到一句“完成了”,但不知道 Agent 是怎么完成的,也不知道是否可信。
对于生产级 Agent 来说,可观测性不是锦上添花,而是基础能力。
七、一个开发 Agent 的完整执行流程
假设用户给 Agent 一个任务:
帮我修复 Kotlin Spring Boot 项目的启动失败问题。一个具备良好 Harness 的 Agent 应该这样执行:
1. 接收任务2. 结构化目标、限制和验证标准3. 读取错误日志4. 搜索相关配置和源码5. 判断错误类型6. 读取相关文件7. 制定最小修改方案8. 修改代码或配置9. 运行测试或启动命令10. 如果失败,读取新错误并重新分析11. 如果成功,查看 Git diff12. 输出根因、修改点、验证结果和风险说明13. 将经验写入项目记忆或技能库
这就是 Harness Engineering 在真实开发场景中的价值。
八、为什么未来 Agent 的竞争会转向 Harness?
随着模型能力越来越强,单纯比较模型本身的差距会逐渐缩小。
真正决定 Agent 是否好用的,可能会变成:
谁的工具系统更完整; 谁的上下文管理更精准; 谁的验证机制更可靠; 谁的错误恢复能力更强; 谁的权限控制更安全; 谁的可观测性更清晰; 谁能沉淀长期记忆和技能。
也就是说,未来 AI Agent 的竞争,不只是模型能力的竞争,更是 Harness Engineering 的竞争。
一个没有 Harness 的强模型,可能只是一个聪明但不稳定的助手。
一个有优秀 Harness 的模型,才能成为真正可靠的 Agent。
九、总结
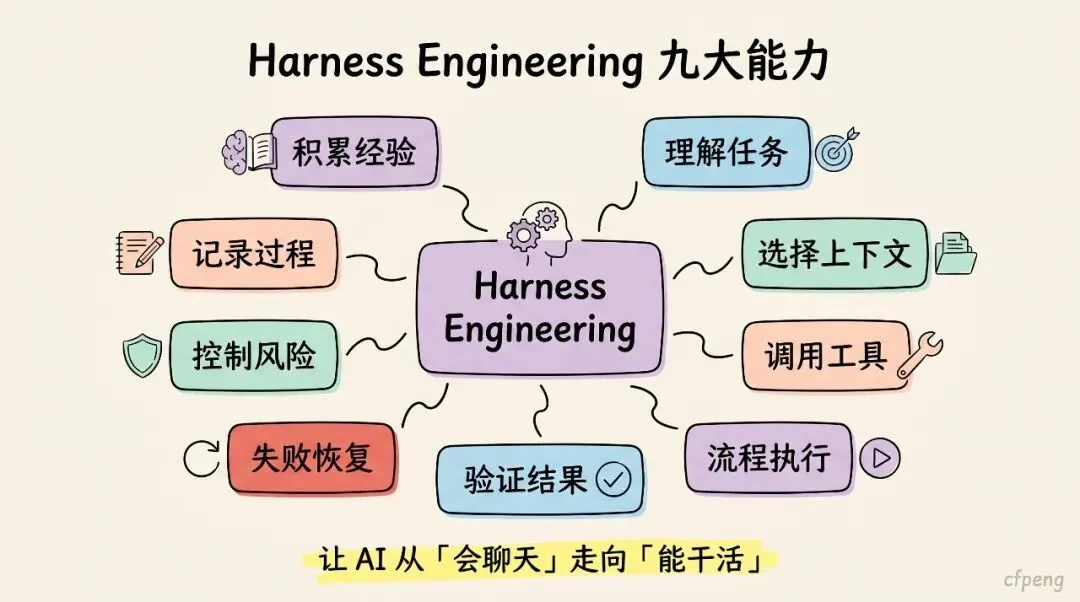
Harness Engineering 可以用一句话概括:
给大模型设计一套可控、可验证、可恢复、可观测、可扩展的执行系统。
它让 Agent 具备以下能力:能理解任务、能选择上下文、能调用工具、能按流程执行、能验证结果、能失败恢复、能控制风险、能记录过程、能积累经验。
所以,真正的 AI Agent 架构不是:
用户 → 大模型 → 答案而是:
用户 → Harness → 大模型 → 工具 → 验证 → 恢复 → 报告未来,想要做好 AI Agent,不仅要会选模型、写 Prompt,更要懂 Harness Engineering。
因为只有 Harness,才能让 AI 从“会聊天”走向“能干活”。
