夜雨聆风
夜雨聆风PROBAST+AI工具在预测模型研究质量评价中的应用
PROBAST+AI是在原PROBAST工具基础上更新形成的预测模型研究评价工具,适用于使用传统回归方法或人工智能方法构建和评价的预测模型研究。该工具通过明确综述目的、分类预测模型研究类型、分领域评价模型开发和模型评价过程,并形成总体判断,为系统综述和证据综合提供了结构化方法。本文系统介绍PROBAST+AI的适用范围、核心流程、四个评价领域、总体判断规则及rationale书写方法,阐述其在实际系统综述中的操作要点,以期为研究者规范开展预测模型研究质量评价提供参考。

步骤一
使用PICOTS指南明确预测模型评价的预期目的或目标
步骤二
根据原始研究的目的,判断其属于哪一类预测模型研究。
若研究只是建立一个新的预测模型,而没有评价模型性能,则归为“仅模型开发”,只填写模型开发部分; 只建立模型,没有评价模型性能的情况极少若研究是在新的数据中验证一个或多个已有模型,则归为“仅模型评价”,只填写模型评价部分; 若同一篇文章既开发模型,又报告表观性能、内部验证或外部验证结果,则归为“组合研究”,需要同时完成模型开发和模型评价两部分。实际操作时,应以“每个模型、每个结局”为单位进行分类,而不是简单按整篇文章分类;如果某项研究不属于模型开发、模型评价或组合研究,则不适合使用PROBAST+AI。
步骤三
在明确综述PICOTS和模型研究类型之后,对每篇文献中每个感兴趣模型、每个相关结局,分别评价模型开发质量/适用性,或模型评价偏倚风险/适用性。如果一篇文章有多个模型或多个结局,应分别填写。例如Jeong等研究中有3个模型:治疗中VTE复发模型、治疗中大出血模型、停药后VTE复发模型,因此不能只评价一次,而应至少分成3个评价单元。在开始前,需要先填写三个基本信息:
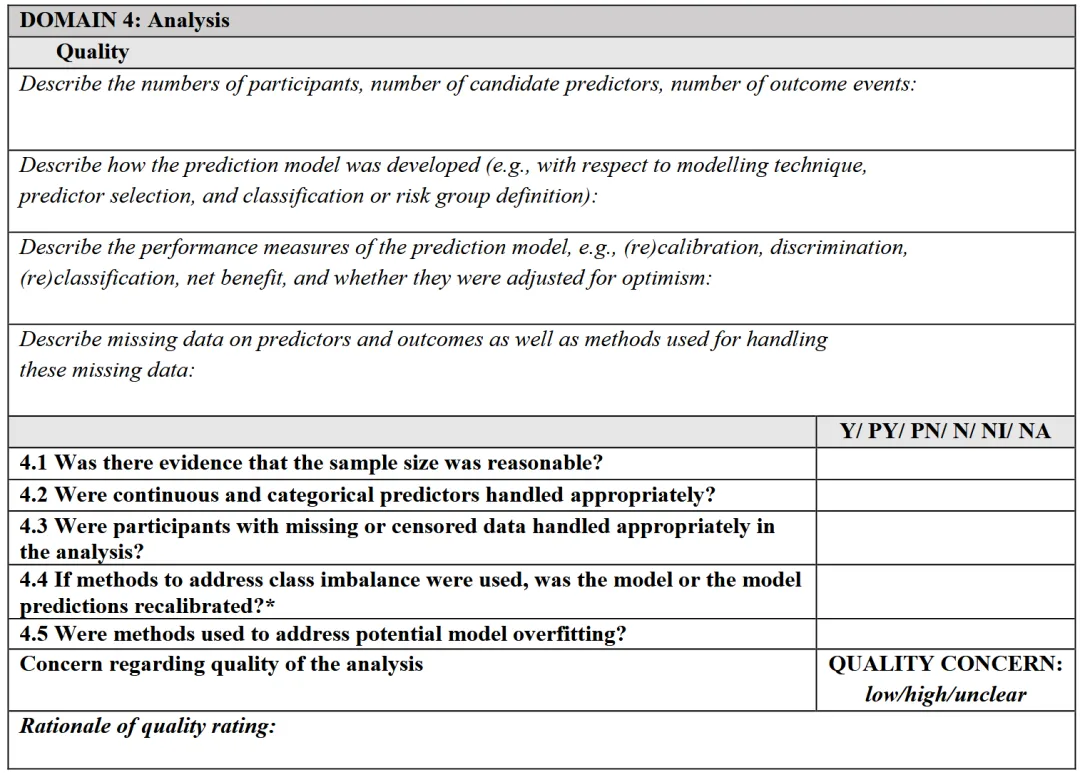
针对模型开发过程
评价“quality concern”和“applicability concern”
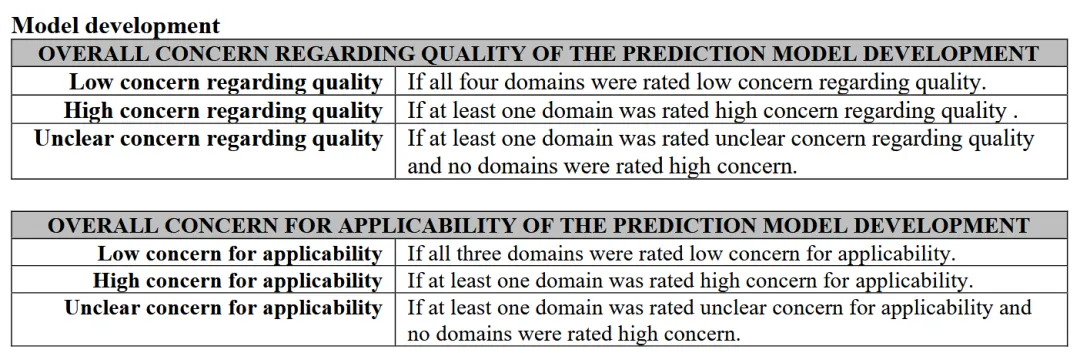
在 PROBAST+AI: Model development 部分共有4个Domain:
其中,前三个domain除了quality concern外,还需要额外评价applicability concern,即适用性关注程度,需要根据Step 1中定义的综述问题或预期用途来判断。每个domain都要判断模型开发过程的质量关注程度(concern about quality),分为:
signalling quesiongs
每个domain下面会有若干个signalling questions(信号问题)。这些问题用于帮助评价者判断该domain是否存在质量问题或偏倚风险。
信号问题的选项包括:
回答Yes或Probably yes通常提示低质量关注,即模型开发质量较高;回答No或Probably no则提示该domain可能存在较严重质量问题。 但最后domain评为low、high还是unclear,需要评价者综合判断,而不是机械计算。
写rationale
每个domain最好都写rationale。rationale不是原文摘抄,而是基于原文证据和PROBAST+AI标准写出的判断理由。
推荐句式:
原文报告/未报告【关键信息】。根据PROBAST+AI,该domain主要关注【评价重点】。由于【具体原因】,该问题可能/不太可能导致选择偏倚、测量偏倚、信息泄漏、过拟合或性能高估,因此本domain评为【low/high/unclear】。
例如:
原文报告研究使用全国理赔数据库,数据来源明确,纳入和排除标准较清楚。但该数据库并非为预测模型开发预先设计,且部分诊断和结局依赖编码识别,可能存在误分类。因此Domain 1评为unclear concern。
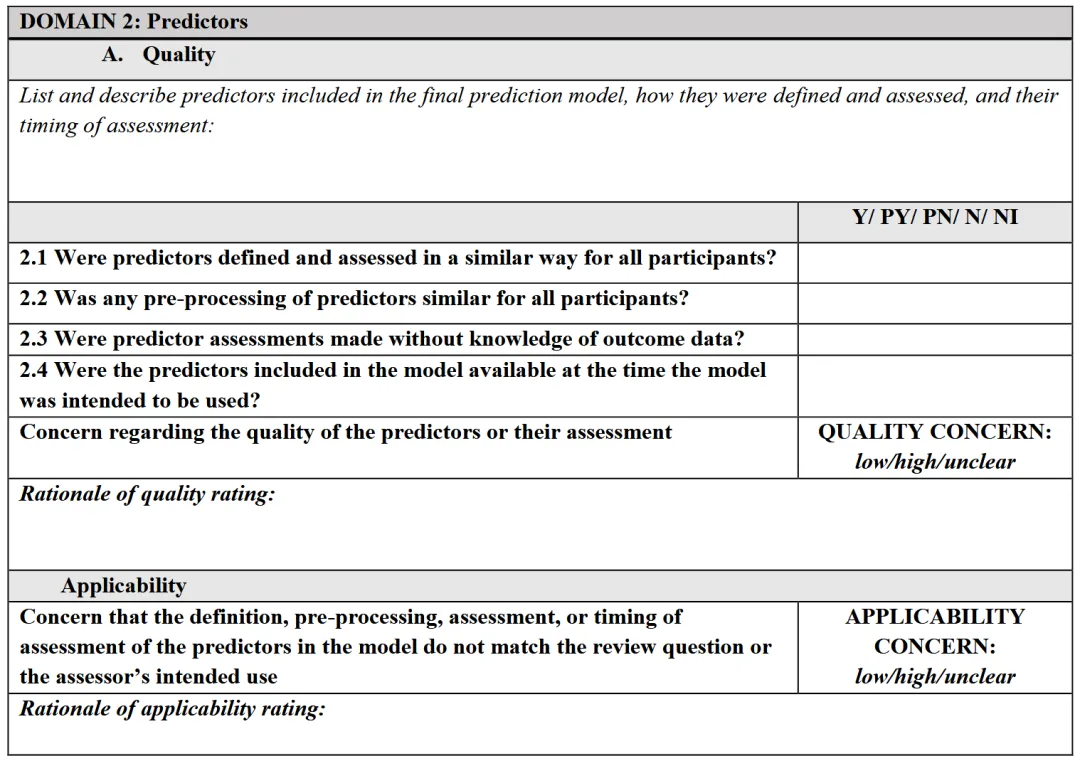
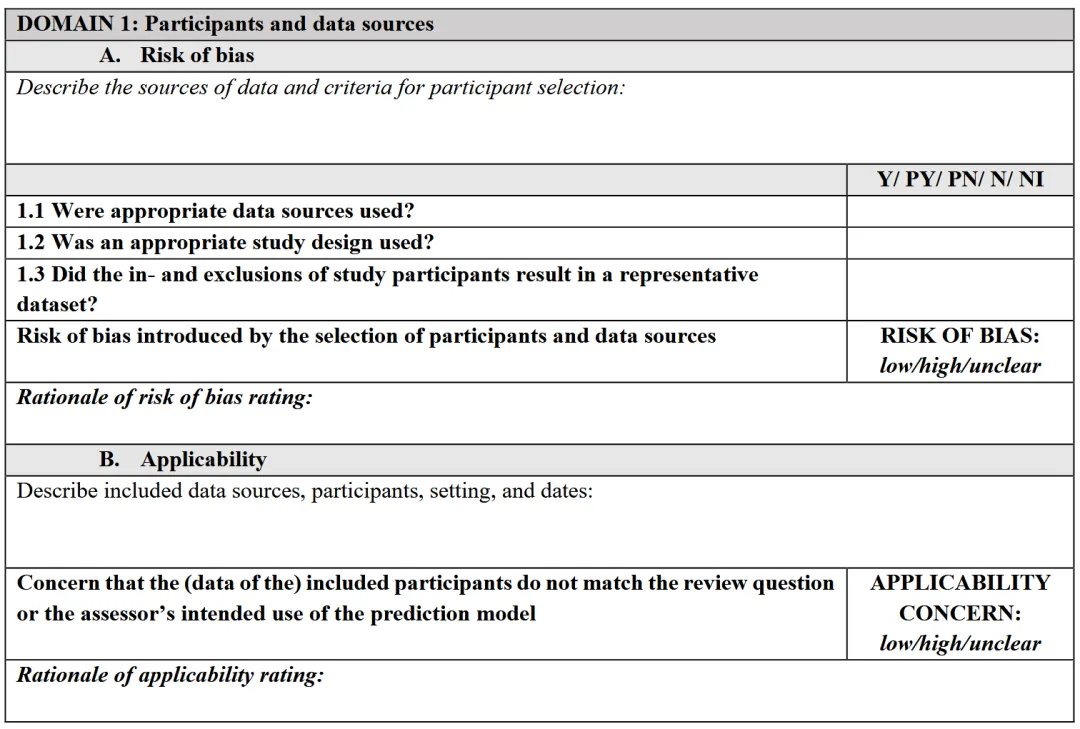
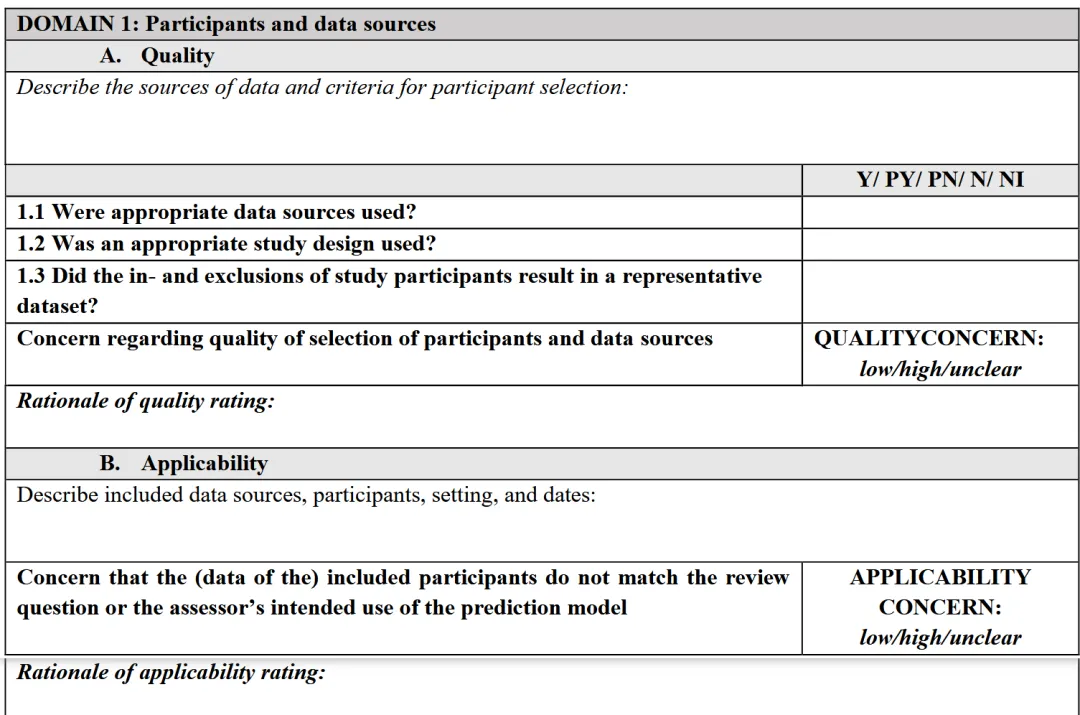 1.1 是否使用了合适的数据源
1.1 是否使用了合适的数据源
✅ Y/PY:数据源明确(如前瞻性队列、注册研究),采集 / 测量方法详细可追溯;❌ PN/N:公开数据集无采集细节、数据来源不明;❓ NI:未描述数据源信息。
针对模型评价过程
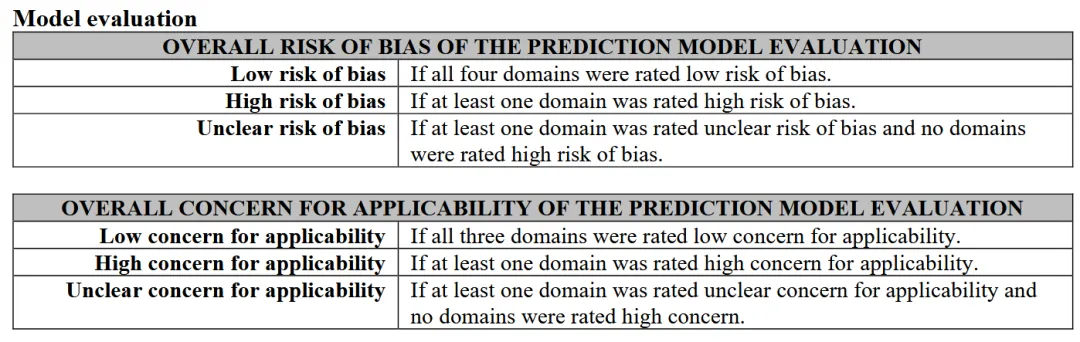
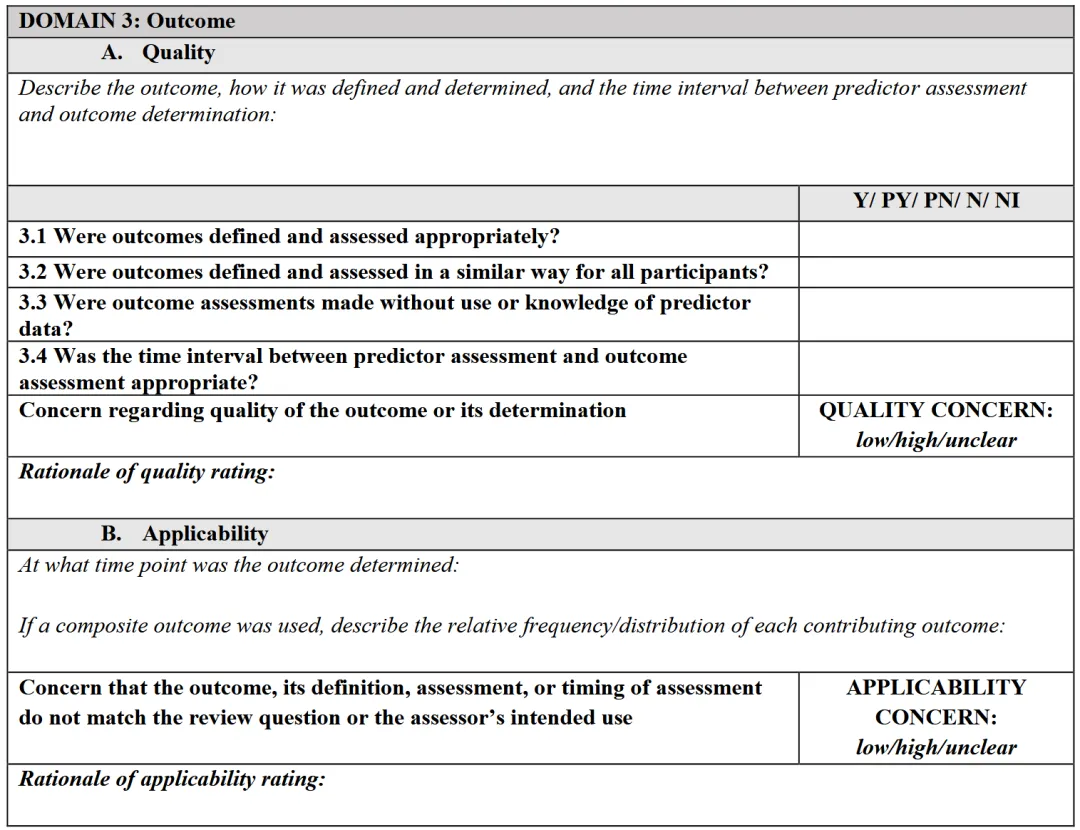
如果当前研究是在验证已有模型,则只需要完成Model evaluation部分。此时评价重点从“模型是否开发得好”转为:这个模型的性能评价是否可信?模型评价部分同样有4个domain,但判断的是risk of bias(偏倚风险),而不是quality concern。
前三个domain仍然需要判断applicability concern。
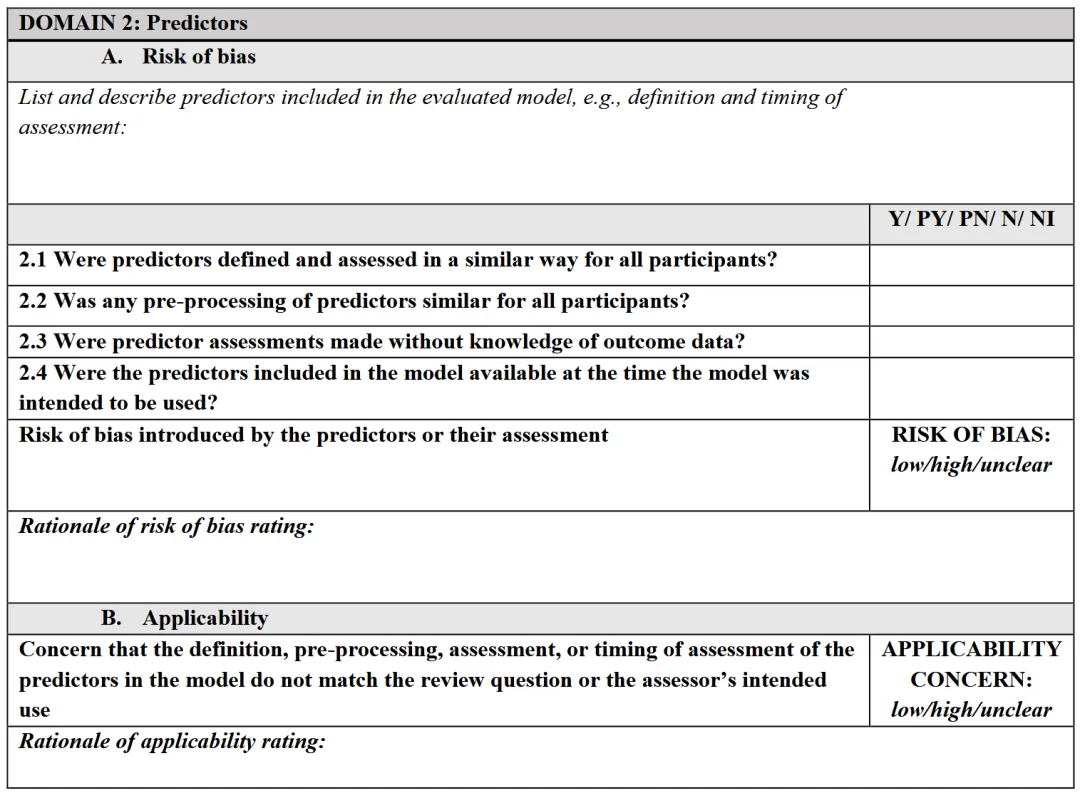
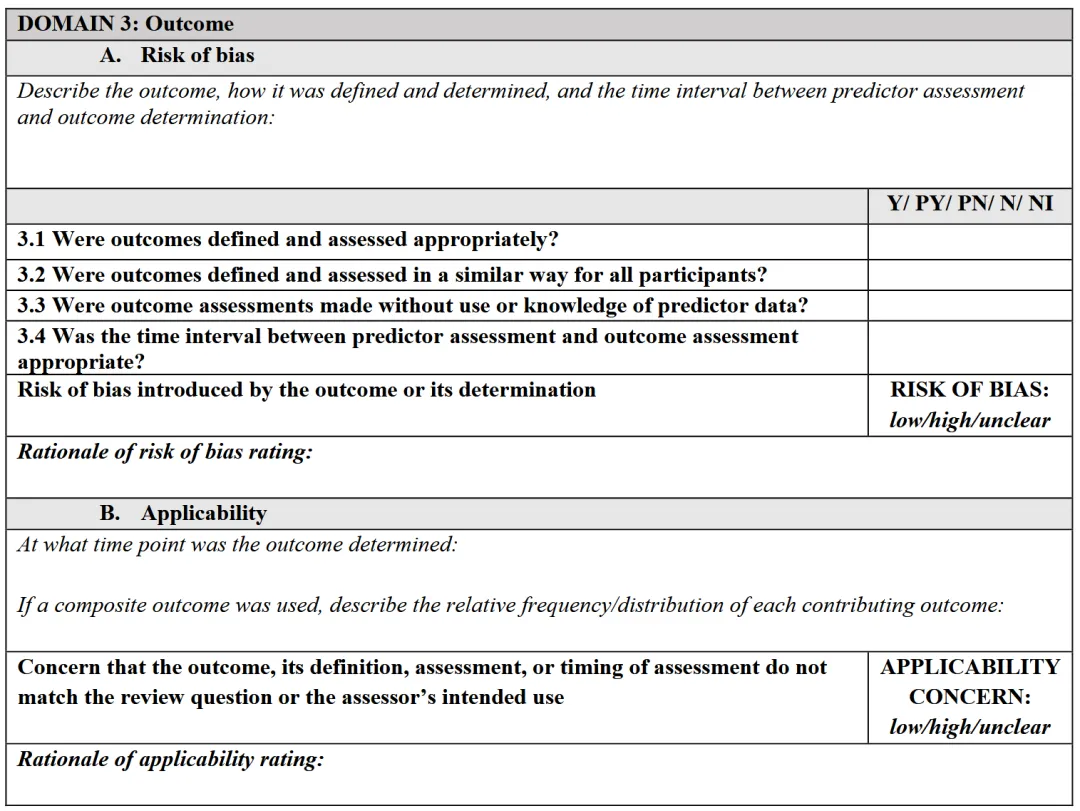
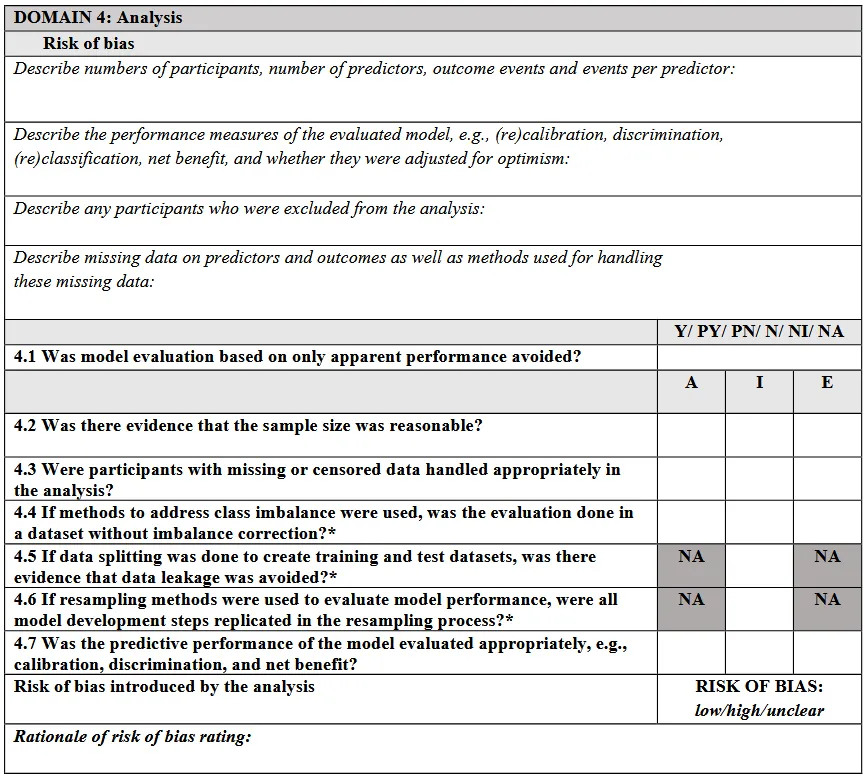 表观性能(A,同数据开发 + 评估)、内部验证(I)、外部验证(E)
表观性能(A,同数据开发 + 评估)、内部验证(I)、外部验证(E)
步骤四
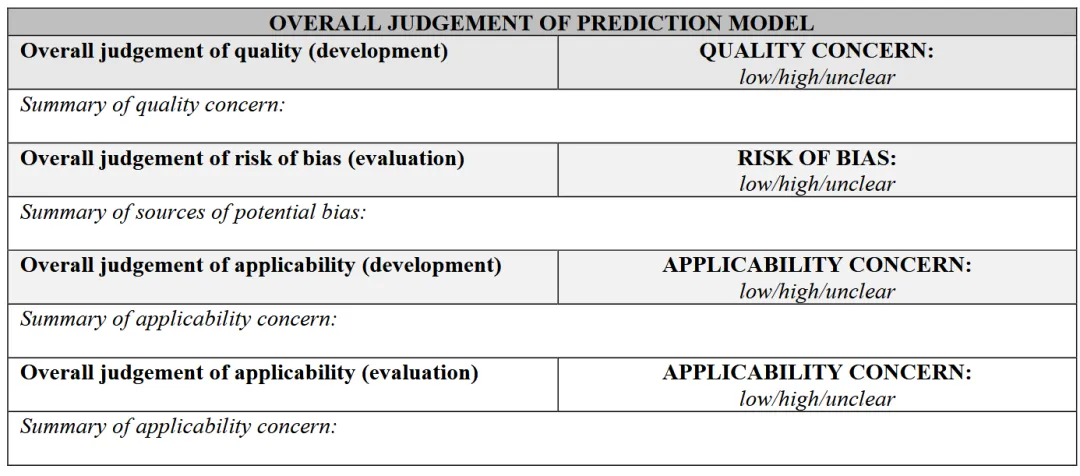
评估预测模型的质量、偏倚风险及适用性的总体担忧(overall concern)