 夜雨聆风
夜雨聆风昨天在COMPUTEX 2026台北展上,高通CEO安蒙说了句话,我琢磨了一晚上:
"词元Token是AI时代的新货币。"
一开始我觉得这是个比喻,但仔细看了看最近发生的事,发现这话一点没夸张——词元Token正在真真切切地变成一种可计价、可交易、可出口的"数字资产"。
先从一个小故事说起
广东汕头,一个以玩具和内衣闻名的沿海城市,上个月干了一件很多人没注意到的大事——
完成了全国首个城市级「词元Token出口」的闭环验证。
什么意思呢?东南亚的用户通过API调用,使用由汕头算力中心生成的AI能力,完成了图片处理、文案生成等任务,然后汕头收到了"出口词元Token"的跨境服务收入。
电力没有离境,服务器没有搬家,模型运行在中国的智算中心里,但价值流向了全球。
国务院发展研究中心的刘晓鸽研究员评价说:词元Token出口已成为"数字服务贸易的全新形态",正在重塑中国在全球价值链中数字服务的地位。
我觉得这句话可以更直白地翻译一下:以前我们出口衬衫、玩具、家电,以后我们出口的是——AI算力本身。
词元Token为什么有资格当"货币"?安蒙在演讲中给出了一个很清晰的递进逻辑:
- 对话式AI
:单次任务约消耗 1万词元Token - 推理式AI
:单次任务约消耗 10万词元Token - 智能体AI
:单次任务约消耗 100万词元Token
两代技术升级,词元Token消耗量翻了100倍。
他还给出了一组预测数据:2026年,全球每10秒的词元Token需求大约是31.7亿;到2030年,这个数字将达到1.27万亿——增长40倍。
黄仁勋在GTC Taipei上说得更直接:词元Token就是资产,是企业获利的营收单位。 因为Token可以制造利润,所以AI公司正在疯狂建造更多"AI工厂",目的就是为了生产更多词元Token。
你看,这不就是"货币"的底层逻辑吗?——有人要,有人产,有价值交换。
中国电信的「词元Token套餐」,你注意到了吗?

这件事可能普通用户感受不深,但我作为业内人士,觉得它意义重大。
中国电信上月底推出了Token套餐:个人用户每月9.9元,获得1000万词元Token;中小企业和开发者39.9元,获得1.5亿词元Token。
你没看错,跟当年手机话费套餐一模一样的形式,但计费单位从"分钟"和"MB"换成了词元Token。
阿里巴巴也成立了新的"Token Hub"事业群,把Token定义为战略资产,三大使命分别是:创造词元Token、传输词元Token、应用词元Token。
这就是一个产业的信号——运营商正在从流量服务商转型为AI算力服务商。
回想一下移动互联网时代:从语音到短信,从短信到流量,每一次计费单位的切换,都伴随着一个万亿级市场的诞生。词元Token取代流量成为新的计费基础,意味着AI时代的商业基础设施正在成形。
硬币的另一面:词元Token也在「烧」
说完了机会,也得说说风险。
36氪今天有一篇文章叫《一天烧1亿:第一次"词元Token大撤退"来了》,读着挺扎心的。
有企业做多AI协同实验,一晚上Token费用突破百万元;有海外大厂一个月在Claude上烧掉5亿美元;开发者平台Entelligence.ai统计了2444家企业数据发现——每投入1美元的AI 词元Token费用,只有18美分产生了触达用户的实际价值,其他都消耗在了返工、修复AI Bug和审查摩擦上。
洋葱集团创始人李淙更是一针见血地指出: "很多员工在用公司的词元Token摸鱼接私活。"
这说明什么?词元Token虽然是新货币,但跟任何货币一样——用得好是生产力,用得差是浪费。
作为行业从业者的几点判断
第一,词元Token经济的底层逻辑已经成立。从国家层面的词元Token出口,到运营商的Token套餐,到芯片巨头的Token定价体系,整个产业链都在为Token定价。
第二,中小企业要抓住这波红利,而不是被词元Token吞噬利润。我的建议很简单:先用开源模型做本地化部署,把高频、低价值的Token调用"内部化",只在核心场景用付费API。这叫"算力降本",跟当年企业自建服务器还是上云的选择是一个道理。
第三,词元Token管理将成为企业的刚需。就像十年前企业开始设"财务总监"管控资金流,未来可能会有"Token运营官"来管控AI算力消耗。这不是玩笑。
写在最后:从贝壳到黄金,从纸币到数字货币,人类社会的"计价单位"一直在进化。词元Token能不能成为AI时代的硬通货,不取决于技术本身,而取决于它能不能帮我们创造出真正的价值。
我的判断是——能。而且这一天比大多数人想的要快。
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
根据OpenRouter最新数据测算,上周(5月25日至5月31日)全球AI大模型总调用量为31.8万亿词元Token,较此前一周增长10%,词元Token调用量已连续六周上涨,大模型词元Token调用需求仍在持续释放,中国大模型的词元Token调用量还在持续高速增长。
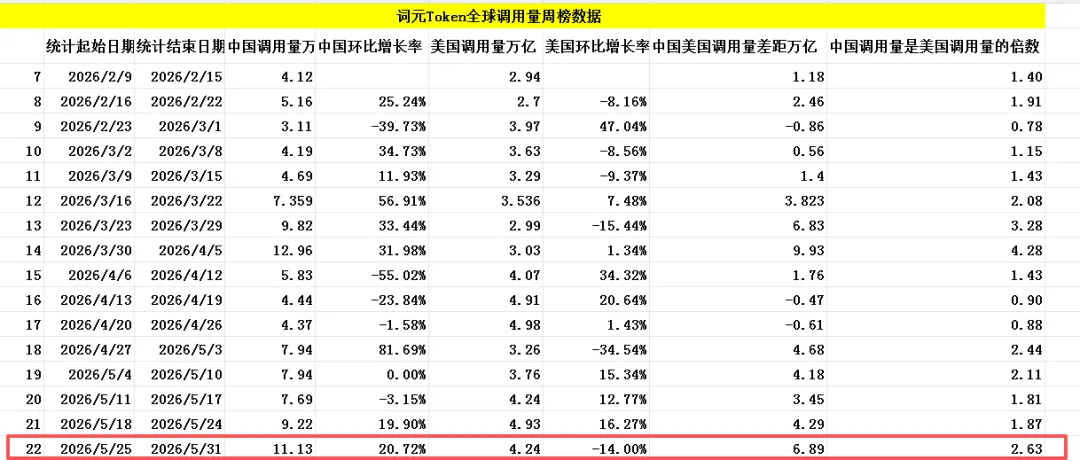
根据粤桂大数据提供的词元Token全球调用量周榜数据汇总,上榜的AI大模型中,中国AI大模型周调用量达11.13万亿词元Token,环比增长高达20.72%,同期美国AI大模型周调用量为4.24万亿词元Token,环比下跌了14%。从数据对比来看,中国大模型周调用量还是远超美国,再次以2.63倍遥遥领先,这已经是连续五周实现反超并稳居全球首位。
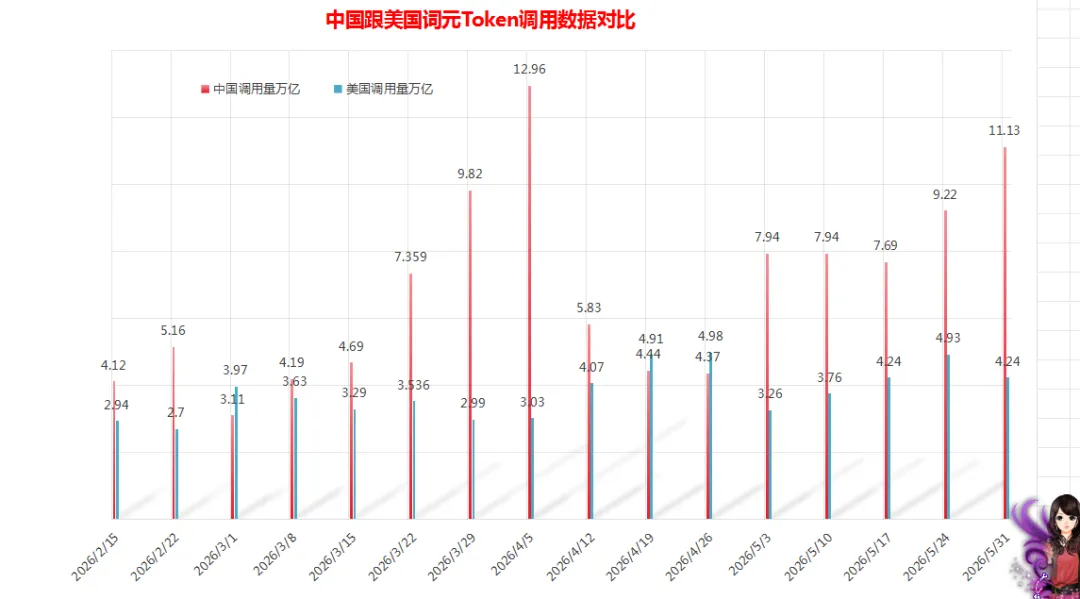
粤桂大数据记录的中国跟美国词元Token调用数据对比
截至目前,DeepSeek-V4-Flash再次霸榜OpenRouter全球AI大模型调用榜榜首位置。值得注意的是,全球调用榜前两名均为国产模型,分别是 DeepSeek-V4-Flash、腾讯 Hy3 preview,没想到DeepSeek和腾讯如此的霸气,稳稳的占据了前两名。
OpenRouter是一个AI模型聚合与调用平台,提供透明的词元token级监控与计费系统,旨在解决开发者在调用多个AI模型时面临的接口碎片化、密钥管理复杂和成本控制等问题。其用户以海外开发者为主,中国开发者仅占约6%。在国内,词元Token调用量大幅增长已不是新鲜事。
看来这是开发者用户在不断的选择模型切换,之前我们分析过,谁的更具备综合优势开发者最终还是会反应在数据上的。
这一数据变化一定程度上反映国内AI应用场景持续普及、用户需求稳步释放,产业落地节奏保持稳定,特别是中国的一些互联网巨头利用自身的互联网资源转化更快的普及;而美国市场调用量快速攀升,也体现出海外AI商业化进程加速推进。在全球AI算力与应用竞争格局中,我国大模型凭借庞大的用户基数、丰富的本土使用场景,持续领跑全球周度调用规模,成为全球AI产业增长的核心动力。
前几周都是腾讯的Hy3 preview霸榜,5月18日至5月24日这周DeepSeek大模型问鼎全球调用榜后,中国AI企业DeepSeek旗下的V4-Flash模型,以周调用3.43万亿词元Token的惊人数据首次问鼎全球,环比暴涨66%。看来还是DeepSeek实力杠杆的,5月25日至5月31日继续霸榜,这次看来会霸榜一段时间了。毕竟DeepSeek的优势还是非常明显的。
像OpenAI GPT、谷歌Gemini、Anthropic Claude,全部被甩在了身后。
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
其实,我们的大模型已经涨价了30%了,市场都疯了!搜索量上涨1850%,“词元Token”涨价潮来了!3月,腾讯云、阿里云和百度智能云,国内三大云厂商接连提高AI算力产品价格,十天之内涨价30%左右。但是人家还是要继续用啊,继续抛弃美国的大模型,优势摆在这里啊,真心是没办法的事情。
人工智能要训练大模型、跑推理服务,表面上拼的是算力,但是算力的尽头是电力啊,最终拼的就是电力,这个玩意烧电太严重了。中国拥有全球独一无二的电力架构——特高压输电网络覆盖全国,最要命的是我们西部风光水电便宜啊,并且可以直接送上给东部数据中心,这些绿电成本远低于欧美。当美国科技公司为电费发愁时,中国数据中心能以更低成本支撑海量词元Token计算。根据数据显示,中国算力中心平均PUE(能耗效率)已降至1.2以下,部分西部集群甚至接近1.1了,这个是可以吊打美国好几条街的。
坚持并购思维的老李认为,这个词元Token数据调用量简直就是吊打美国好几条街!!!看来中国的电力在未来远远不够用啊,算力出海开始大赚了!从老美搅乱中东开始想以石油+美元的方式来收割全球,殊不知中国用了电力+算力进行反击,这个在全球绝无仅有,中国独一份,这个不用卷了吧,想提价就提价,提价后仍然比美国便宜很多。

如果说互联网时代信息传输的核心度量是“流量”,流量就是字节字节(B),
流量在网络通信领域指设备在网络上传输或接收的数据量,即用户上网时产生的数据交换总量。
计算单位:
基本单位是字节(B),常用单位有千字节(KB)、兆字节(MB)、吉字节(GB)、太字节(TB)。
换算关系为:1KB = 1024B,1MB = 1024KB,1GB = 1024MB,1TB = 1024GB。
我们都知道在互联网时代,谁掌握了流量谁就掌握了财富,互联网时代最早的,从最早的雅虎,新浪,网易,搜狐到后面的百度、微信,今日头条等。
无论是雅虎的门户、盛大的游戏、百度的搜索,还是腾讯的社交,其商业内核高度一致:先以免费、好用的服务占领用户的时间和注意力(流量),再通过广告、游戏或增值服务完成“流量变现”,这个核心理念,至今仍是互联网商业的基石。
那现在进入人工智能时代,未来会以什么来表征人工智能的财富呢?
在人工智能时代,这一关键指标正变为词元Token——用户输入的每一个字,模型生成的每一段话、识别的每一幅图像,都在消耗词元Token。
怎么理解词元Token?简单来说,词元是人工智能大模型为了高效处理数据,把数据进行拆分后的“最小信息载体”,可以理解为“字/词片段/符号”等。比如“我爱中国!”,可拆分成“我”“爱”“中国”“!”4个词元,大家注意到没有,中国两个字居然是一个词元Token。
3月17日,2026年的英伟达GTC大会上,黄仁勋在两个小时的演讲,提到了超过了70次词元Token。如果你看最近的AI相关的文章,会发现词元Token这个词出现的频率也极高。不少人把黄仁勋的演讲,概括为“词元Token经济学”来传播。要是把Token翻译成中文,该是什么?网上之前的翻译都是令牌。


网上翻译代币的比较多。后面觉得这些都难以表达对Token的真正渊源。
之前对于Token这个名字中午名字如何定,网络上吵翻天:
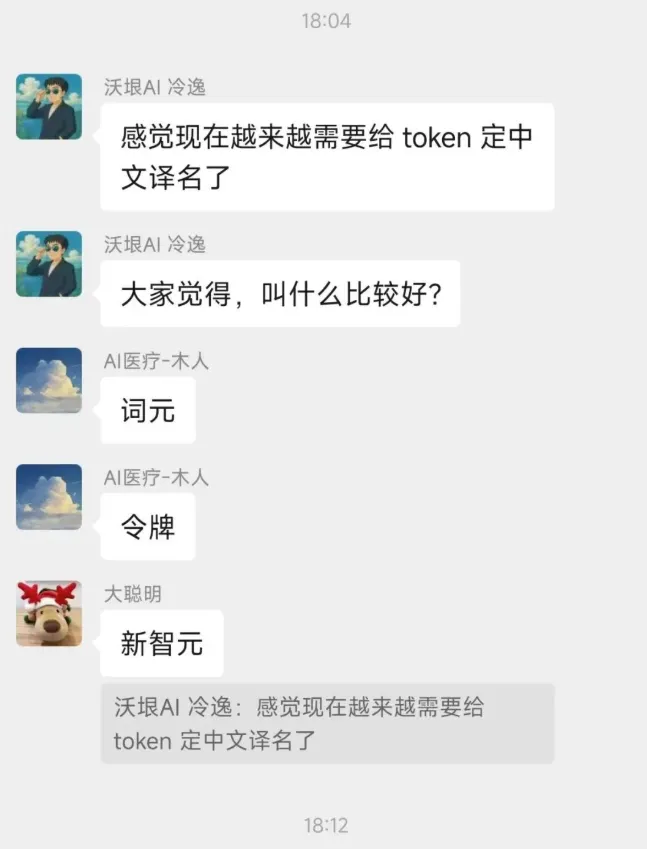
直到前几天(3月24日),国家数据局给Token起了个名字,叫“词元”。
刘烈宏24日在国新办举行的新闻发布会上表示,到今年3月,我国日均词元(Token)调用量已超过140万亿,相比2024年初的1000亿增长了1000多倍,相比2025年底的100万亿,三个月时间又增长了40%多。
“日均词元调用量的大量增加,充分表明中国的人工智能发展进入了快速增长阶段。”刘烈宏表示,人工智能应用场景在不断深化,从能对话到能决策执行的智能体,中国人工智能产业的竞争力在显著增强,现在备受关注的Token出海,就是产业竞争力增强的一个标志。
据刘烈宏介绍,在各方共同努力下,我国高质量数据集的建设工作取得了阶段性成效,截止到2025年底,全国已建成的高质量数据集超过10万个,总体量超过890PB,这相当于中国国家图书馆数字资源总量的310倍左右。
下一步,国家数据局将持续推进数据赋能人工智能创新发展,协同各方深入实施新一轮的高质量数据集建设行动计划,以场景需求为牵引,加快推进先行先试的工作,打造技术可行、实用便捷、质量保障的AI-Ready(AI就绪度)高质量数据集,实现高质量数据集供给的量质提升。
就是国家统计局给Token终于定名为词元了!
当全球大模型日均词元token消耗达30万亿、中国调用量占全球60%以上时,术语已不是翻译问题,而是基础设施问题;建议由科技部、工信部联合成立AI术语治理工作组,将"词元"纳入《人工智能术语国家标准》修订案,并同步推动在GTC中国分会、世界人工智能大会等平台形成中文术语传播主阵地。
中国AI大模型调用词元Token量缘何连续霸榜?

中国AI大模型调用词元(Token)量连续霸榜,主要有以下几方面原因:
一、成本优势显著
中国大模型在推理成本上远低于国际主流模型。例如,部分国产模型每百万词元输入成本约0.3美元,输出成本约0.28美元,而美国同类模型成本可达5-15美元。低廉的成本吸引了全球开发者和企业大规模调用,尤其在预算敏感的中小企业和初创项目中更具吸引力。
二、电力与算力基础设施支撑
中国拥有全球最庞大、最先进的电力供应体系,中西部地区丰富的风电、光伏、水电资源为数据中心提供了低成本、绿色能源。同时,“东数西算”工程和算电协同布局优化了算力资源分配,使大模型能高效处理海量词元计算,降低了单位算力成本。
三、开源生态与技术创新
中国大模型厂商如DeepSeek、通义千问、MiniMax等积极开源模型,推动技术共享和生态建设。通过优化模型架构(如混合专家模型、稀疏注意力机制等),在保持性能的同时提升了计算效率,缩短了与国外顶尖模型的技术代差,增强了全球竞争力。
四、应用场景丰富与需求驱动
中国庞大的用户市场和完整的产业链为AI应用提供了丰富场景,如金融风控、跨境电商、短视频生成、工业自动化等。这些场景对AI的调用需求持续增长,推动了词元调用量的爆发式增长,形成了“数据供给—价值释放”的良性循环。
五、开发者生态与用户基础
微信、钉钉、飞书等超级应用触达十亿级用户,为AI模型提供了广泛的调用入口。开发者通过简单集成即可调用AI能力,降低了使用门槛,进一步扩大了词元调用规模。综上,中国AI大模型在成本、基础设施、技术、应用和生态等多方面的综合优势,使其在全球词元调用量榜单中连续霸榜,体现了中国AI产业在规模化应用和商业化落地方面的强大实力。
总之一句:中国人工智能发展迅速,以大模型调用量的大爆发来说,这里面隐藏了未来更多的投资机会,在人工智能特别是算力领域我们的机会才刚刚开始。


希望牛市走得更远!更多牛股分析交流学习在这里。
热门话题人工智能领域算力之词元Token:
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
稳居全球首位!中国大模型词元Token用周调用量连续四周超越美国:DeepSeek大模型问鼎全球调用榜!数据背后隐藏了哪些造富机会?
利好来了!全线大涨!美伊,突传大消息!科创板盛宴你参与了吗?华为 “韬(τ)定律”影响深远!
稳居全球首位!中国大模型词元Token用周调用量连续三周超越美国:腾讯Hy3 preview大涨210%登顶!数据背后隐藏了哪些造富机会?
时隔两周,词元Token调用中国再超美国!腾讯混元Hy3 Preview大模型霸榜!数据背后隐藏了哪些造富机会?
国家数据局:指数级增长 2025年我国词元调用量约21100万亿
全球上周(4月20日至26日)词元TokenAI大模型调用量回升,美国模型调用量继续领先中国,DeepSeek这周能否力挽狂澜?
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
厉害了!指数级增长 2025年我国词元Token调用量约21100万亿!数据背后隐藏了哪些造富机会?
全球上周(4月20日至26日)词元TokenAI大模型调用量回升,美国模型调用量继续领先中国,DeepSeek这周能否力挽狂澜?
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
国家数据局:拟探索词元交易等新型交易模式,词元Token未来到底有哪些机会?
全国首个!“词元(Token)”级城市综合算力运行服务平台在天河上线,中国大模型调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!
词元Token第一股市值涨破1000亿,上市百日股价狂飙513.86%!中国大模型调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!
腾讯云一个月内涨价两次!源于需求旺盛!中国大模型调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!背后隐藏着巨大机会!
中国调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!背后隐藏着巨大的机会!
词元Token调用中国大模型霸榜!前六全部是中国的大模型!最新数据仍然暴增,中国调用量居然是美国的4倍多!
这家上市公司发布“炸裂”数据!厉害了词元Token!最新数据仍然暴增,提价后仍然具备竞争力!
厉害了词元Token!最新数据仍然暴增,提价后仍然具备竞争力!
词元Token搜索量飙涨1850%!一文带你搞懂什么是词元Token!
超600亿!德国砸钱加码风电,购车补贴向中国品牌敞开大门,再议词元调用量暴增推动算力大涨价!
在人工智能领域,词元(token)主要用来计量以下几方面:
1.信息处理量
词元(token)是大语言模型处理信息的基本单位,用于衡量输入文本(如用户提问)和输出文本(如模型生成的回答)的规模。例如,一段文字被拆分为多个词元(Token),词元(token)数量越多,表示处理的信息量越大。词元(token)正成为衡量AI工作量的核心单位,其经济价值推动算力产业链变革,上游芯片与服务器厂商受益,下游企业则面临成本压力,倒逼技术优化与国产算力替代进程加速。
2.算力消耗
模型每处理一个词元(token),都需要消耗一定的计算资源(如GPU算力、内存等)。因此,词元(token)数量直接反映了模型运行时的算力消耗程度,是衡量计算成本的重要指标。
3.服务计费依据
在AI服务商业化场景中,词元(token)通常作为计费单位。服务提供商根据用户消耗的词元(token)数量收取费用,用户使用越复杂、越长的任务,消耗的词元(token)越多,费用也越高。简而言之,词元(token)既是技术层面衡量信息处理和算力使用的单位,也是商业层面衡量AI服务价值和成本的核心指标。
你对股市上涨及A股下跌是什么样的心态及心情?
欢迎评论区留言交流
以上所有内容仅供投资者学习交流用,不作为投资建议。股市有风险投资需谨慎!
