 夜雨聆风
夜雨聆风今天早上翻资讯,看到一条让我这个干大数据的老兵特别提气的消息——
人民日报头版发了篇文章,标题叫《开源之路,通向的是创新与共赢》。能让官媒头版为一个技术路线发声,这事本身就说明,风向真的变了。
具体什么事呢?两个数字,你们感受一下:
41% ——全球开源平台大模型的下载量中,41%来自中国研发的模型。
全球第一——去年中国开源模型全球下载量首次超过美国。
你没看错,不是"接近",不是"追赶",是超过。
百万词元Token的「超长上下文」,意味着什么?
这次引爆话题的主角是DeepSeek最新开源的V4模型。技术圈的朋友可能已经刷屏了,但我用大白话翻译一下它最牛的一个能力:百万词元Token超长上下文窗口。
什么叫"百万词元"?你可以理解为,它能一口气"读完"三部《三体》总和的体量,然后准确回答你任何细节问题。
以前的大模型处理长文本,就像一个记忆力不太好的人——看到后面忘了前面。DeepSeek V4相当于给AI装了个"过目不忘"的大脑。这个突破,放在企业级应用里价值巨大:一份几百页的合同、一整年的财务报表、一套完整的技术方案文档,它都能一次性吃进去、理清楚、给出判断。
而且,它把模型权重和底层代码全部免费开放。这意味着全球任何一家公司、任何一个开发者,都可以拿它来搭建自己的AI应用,不需要付版权费,不需要给授权费。
为什么中国选择了「开源」这条路?
这就要说到一个根本性的选择题了。
AI大模型的研发路径,目前全球主要分两派:一派走"闭源商用",典型代表是OpenAI的GPT系列;另一派走"开源共享",以DeepSeek、通义千问、月之暗面为代表的中国阵营是主力。
有人说,闭源才能赚钱,开源不是傻吗?
我的理解刚好相反——开源不是情怀,而是一种更高维度的商业策略。
你想想看,当全球几十万开发者都在用你的模型做二次开发,当你的模型成为各种AI应用的"地基",那你就不是卖产品的,你是定义标准的。标准一旦确立,生态一旦形成,护城河比闭源产品深得多。
马来西亚《星报》有句话说得特别到位:中国的AI产品注重实际落地,在整合资源方面已达到世界领先水平。
6000多家AI企业,覆盖从智能芯片到算力集群、从模型研发到场景应用的完整产业链——这不是某一家公司的成功,而是一个国家的产业协同能力在发挥作用。
从行业一线视角聊几句
我做大数据这些年,最深的一个感受是:数字经济不是口号,是每家企业都要面对的现实。
现在我们粤桂大数据服务的中小企业客户,很多都在问同一个问题:AI来了,我们怎么用?
说实话,一年前我还不太好回答——那时候大模型要么太贵(按调用量收费,中小企业用不起),要么太封闭(你没法根据自己的业务需求做定制)。
但现在不一样了。
DeepSeek V4开源了,阿里的通义千问开源了,Kimi也开源了……这些国产模型的水平已经达到甚至在某些维度超越了国际一线水平。中小企业要做的不是自己研发大模型,而是在这些开源模型的基础上,搭自己的应用。
这就是我常说的:普通人不要想着去炼钢,要学会用钢造工具。
我们服务的一家制造业客户,去年在开源模型上搭了一套质检系统,缺陷识别率从人工的85%提升到98%,每天节省8个人工。这不是科幻,这是已经发生的事。
开放,才能走得更远
人民日报那篇文章有段话我看了好几遍,忍不住抄下来:
"中国已成为世界上开源软件和开放模型重要贡献者,并将'推进开源体系建设'写入'十五五'规划纲要。"
把一个技术路线写进国家五年规划,这在全球范围内都是极其罕见的。
这意味着,"开源"在中国已经不是一个民间行为,而是一个国家层面的基础设施战略。
个别国家筑起技术壁垒,想通过封锁来遏制中国AI的发展。但从今天的数据看,效果恰恰相反——封锁倒逼出了更强的自主创新能力,开源路径反而帮中国绕开了所有封锁,直接触达全球开发者。
用一句话总结今天想说的:中国AI开源的势能,已经不可逆转。这不是某个模型的胜利,是一个时代的选择。
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
根据OpenRouter最新数据测算,上周(5月25日至5月31日)全球AI大模型总调用量为31.8万亿词元Token,较此前一周增长10%,词元Token调用量已连续六周上涨,大模型词元Token调用需求仍在持续释放,中国大模型的词元Token调用量还在持续高速增长。
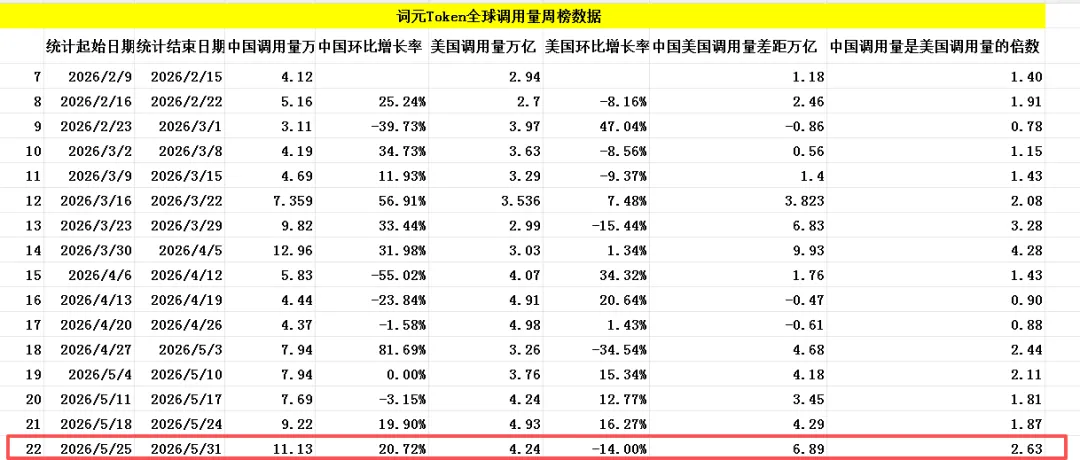
根据粤桂大数据提供的词元Token全球调用量周榜数据汇总,上榜的AI大模型中,中国AI大模型周调用量达11.13万亿词元Token,环比增长高达20.72%,同期美国AI大模型周调用量为4.24万亿词元Token,环比下跌了14%。从数据对比来看,中国大模型周调用量还是远超美国,再次以2.63倍遥遥领先,这已经是连续五周实现反超并稳居全球首位。
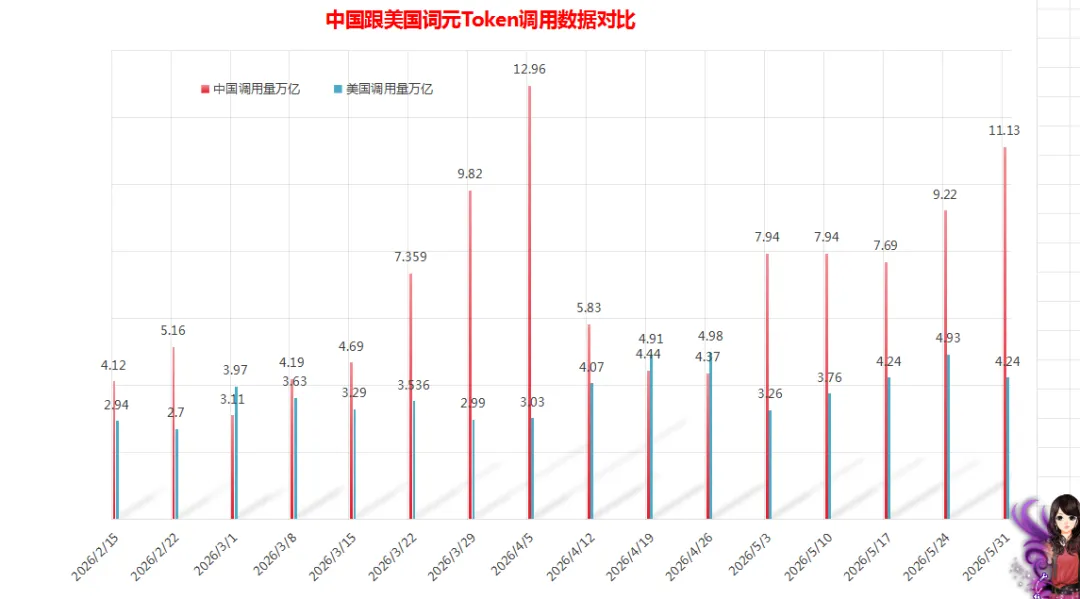
粤桂大数据记录的中国跟美国词元Token调用数据对比
截至目前,DeepSeek-V4-Flash再次霸榜OpenRouter全球AI大模型调用榜榜首位置。值得注意的是,全球调用榜前两名均为国产模型,分别是 DeepSeek-V4-Flash、腾讯 Hy3 preview,没想到DeepSeek和腾讯如此的霸气,稳稳的占据了前两名。
OpenRouter是一个AI模型聚合与调用平台,提供透明的词元token级监控与计费系统,旨在解决开发者在调用多个AI模型时面临的接口碎片化、密钥管理复杂和成本控制等问题。其用户以海外开发者为主,中国开发者仅占约6%。在国内,词元Token调用量大幅增长已不是新鲜事。
看来这是开发者用户在不断的选择模型切换,之前我们分析过,谁的更具备综合优势开发者最终还是会反应在数据上的。
这一数据变化一定程度上反映国内AI应用场景持续普及、用户需求稳步释放,产业落地节奏保持稳定,特别是中国的一些互联网巨头利用自身的互联网资源转化更快的普及;而美国市场调用量快速攀升,也体现出海外AI商业化进程加速推进。在全球AI算力与应用竞争格局中,我国大模型凭借庞大的用户基数、丰富的本土使用场景,持续领跑全球周度调用规模,成为全球AI产业增长的核心动力。
前几周都是腾讯的Hy3 preview霸榜,5月18日至5月24日这周DeepSeek大模型问鼎全球调用榜后,中国AI企业DeepSeek旗下的V4-Flash模型,以周调用3.43万亿词元Token的惊人数据首次问鼎全球,环比暴涨66%。看来还是DeepSeek实力杠杆的,5月25日至5月31日继续霸榜,这次看来会霸榜一段时间了。毕竟DeepSeek的优势还是非常明显的。
像OpenAI GPT、谷歌Gemini、Anthropic Claude,全部被甩在了身后。
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
其实,我们的大模型已经涨价了30%了,市场都疯了!搜索量上涨1850%,“词元Token”涨价潮来了!3月,腾讯云、阿里云和百度智能云,国内三大云厂商接连提高AI算力产品价格,十天之内涨价30%左右。但是人家还是要继续用啊,继续抛弃美国的大模型,优势摆在这里啊,真心是没办法的事情。
人工智能要训练大模型、跑推理服务,表面上拼的是算力,但是算力的尽头是电力啊,最终拼的就是电力,这个玩意烧电太严重了。中国拥有全球独一无二的电力架构——特高压输电网络覆盖全国,最要命的是我们西部风光水电便宜啊,并且可以直接送上给东部数据中心,这些绿电成本远低于欧美。当美国科技公司为电费发愁时,中国数据中心能以更低成本支撑海量词元Token计算。根据数据显示,中国算力中心平均PUE(能耗效率)已降至1.2以下,部分西部集群甚至接近1.1了,这个是可以吊打美国好几条街的。
坚持并购思维的老李认为,这个词元Token数据调用量简直就是吊打美国好几条街!!!看来中国的电力在未来远远不够用啊,算力出海开始大赚了!从老美搅乱中东开始想以石油+美元的方式来收割全球,殊不知中国用了电力+算力进行反击,这个在全球绝无仅有,中国独一份,这个不用卷了吧,想提价就提价,提价后仍然比美国便宜很多。

如果说互联网时代信息传输的核心度量是“流量”,流量就是字节字节(B),
流量在网络通信领域指设备在网络上传输或接收的数据量,即用户上网时产生的数据交换总量。
计算单位:
基本单位是字节(B),常用单位有千字节(KB)、兆字节(MB)、吉字节(GB)、太字节(TB)。
换算关系为:1KB = 1024B,1MB = 1024KB,1GB = 1024MB,1TB = 1024GB。
我们都知道在互联网时代,谁掌握了流量谁就掌握了财富,互联网时代最早的,从最早的雅虎,新浪,网易,搜狐到后面的百度、微信,今日头条等。
无论是雅虎的门户、盛大的游戏、百度的搜索,还是腾讯的社交,其商业内核高度一致:先以免费、好用的服务占领用户的时间和注意力(流量),再通过广告、游戏或增值服务完成“流量变现”,这个核心理念,至今仍是互联网商业的基石。
那现在进入人工智能时代,未来会以什么来表征人工智能的财富呢?
在人工智能时代,这一关键指标正变为词元Token——用户输入的每一个字,模型生成的每一段话、识别的每一幅图像,都在消耗词元Token。
怎么理解词元Token?简单来说,词元是人工智能大模型为了高效处理数据,把数据进行拆分后的“最小信息载体”,可以理解为“字/词片段/符号”等。比如“我爱中国!”,可拆分成“我”“爱”“中国”“!”4个词元,大家注意到没有,中国两个字居然是一个词元Token。
3月17日,2026年的英伟达GTC大会上,黄仁勋在两个小时的演讲,提到了超过了70次词元Token。如果你看最近的AI相关的文章,会发现词元Token这个词出现的频率也极高。不少人把黄仁勋的演讲,概括为“词元Token经济学”来传播。要是把Token翻译成中文,该是什么?网上之前的翻译都是令牌。


网上翻译代币的比较多。后面觉得这些都难以表达对Token的真正渊源。
之前对于Token这个名字中午名字如何定,网络上吵翻天:
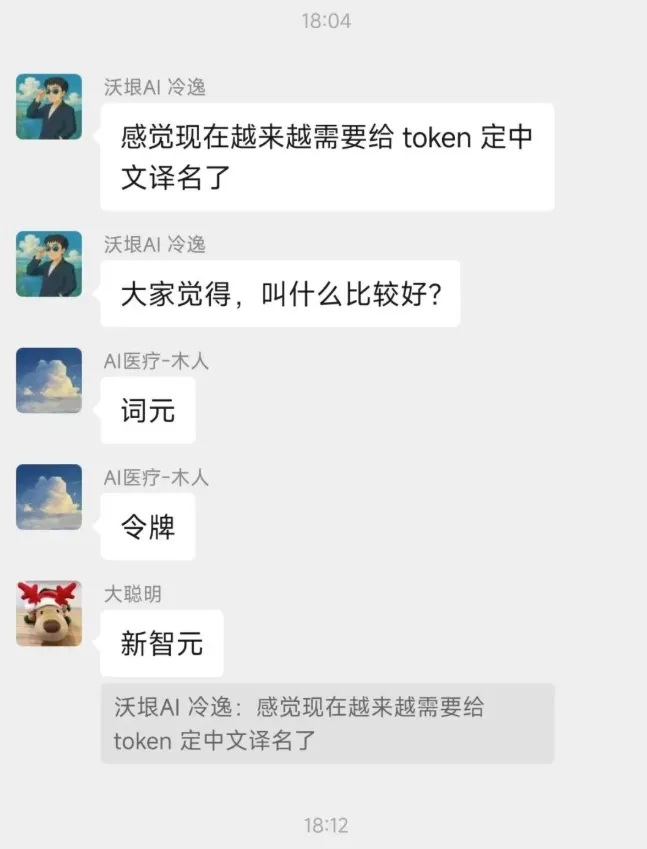
直到前几天(3月24日),国家数据局给Token起了个名字,叫“词元”。
刘烈宏24日在国新办举行的新闻发布会上表示,到今年3月,我国日均词元(Token)调用量已超过140万亿,相比2024年初的1000亿增长了1000多倍,相比2025年底的100万亿,三个月时间又增长了40%多。
“日均词元调用量的大量增加,充分表明中国的人工智能发展进入了快速增长阶段。”刘烈宏表示,人工智能应用场景在不断深化,从能对话到能决策执行的智能体,中国人工智能产业的竞争力在显著增强,现在备受关注的Token出海,就是产业竞争力增强的一个标志。
据刘烈宏介绍,在各方共同努力下,我国高质量数据集的建设工作取得了阶段性成效,截止到2025年底,全国已建成的高质量数据集超过10万个,总体量超过890PB,这相当于中国国家图书馆数字资源总量的310倍左右。
下一步,国家数据局将持续推进数据赋能人工智能创新发展,协同各方深入实施新一轮的高质量数据集建设行动计划,以场景需求为牵引,加快推进先行先试的工作,打造技术可行、实用便捷、质量保障的AI-Ready(AI就绪度)高质量数据集,实现高质量数据集供给的量质提升。
就是国家统计局给Token终于定名为词元了!
当全球大模型日均词元token消耗达30万亿、中国调用量占全球60%以上时,术语已不是翻译问题,而是基础设施问题;建议由科技部、工信部联合成立AI术语治理工作组,将"词元"纳入《人工智能术语国家标准》修订案,并同步推动在GTC中国分会、世界人工智能大会等平台形成中文术语传播主阵地。
中国AI大模型调用词元Token量缘何连续霸榜?

中国AI大模型调用词元(Token)量连续霸榜,主要有以下几方面原因:
一、成本优势显著
中国大模型在推理成本上远低于国际主流模型。例如,部分国产模型每百万词元输入成本约0.3美元,输出成本约0.28美元,而美国同类模型成本可达5-15美元。低廉的成本吸引了全球开发者和企业大规模调用,尤其在预算敏感的中小企业和初创项目中更具吸引力。
二、电力与算力基础设施支撑
中国拥有全球最庞大、最先进的电力供应体系,中西部地区丰富的风电、光伏、水电资源为数据中心提供了低成本、绿色能源。同时,“东数西算”工程和算电协同布局优化了算力资源分配,使大模型能高效处理海量词元计算,降低了单位算力成本。
三、开源生态与技术创新
中国大模型厂商如DeepSeek、通义千问、MiniMax等积极开源模型,推动技术共享和生态建设。通过优化模型架构(如混合专家模型、稀疏注意力机制等),在保持性能的同时提升了计算效率,缩短了与国外顶尖模型的技术代差,增强了全球竞争力。
四、应用场景丰富与需求驱动
中国庞大的用户市场和完整的产业链为AI应用提供了丰富场景,如金融风控、跨境电商、短视频生成、工业自动化等。这些场景对AI的调用需求持续增长,推动了词元调用量的爆发式增长,形成了“数据供给—价值释放”的良性循环。
五、开发者生态与用户基础
微信、钉钉、飞书等超级应用触达十亿级用户,为AI模型提供了广泛的调用入口。开发者通过简单集成即可调用AI能力,降低了使用门槛,进一步扩大了词元调用规模。综上,中国AI大模型在成本、基础设施、技术、应用和生态等多方面的综合优势,使其在全球词元调用量榜单中连续霸榜,体现了中国AI产业在规模化应用和商业化落地方面的强大实力。
总之一句:中国人工智能发展迅速,以大模型调用量的大爆发来说,这里面隐藏了未来更多的投资机会,在人工智能特别是算力领域我们的机会才刚刚开始。


希望牛市走得更远!更多牛股分析交流学习在这里。
热门话题人工智能领域算力之词元Token:
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
稳居全球首位!中国大模型词元Token用周调用量连续四周超越美国:DeepSeek大模型问鼎全球调用榜!数据背后隐藏了哪些造富机会?
利好来了!全线大涨!美伊,突传大消息!科创板盛宴你参与了吗?华为 “韬(τ)定律”影响深远!
稳居全球首位!中国大模型词元Token用周调用量连续三周超越美国:腾讯Hy3 preview大涨210%登顶!数据背后隐藏了哪些造富机会?
时隔两周,词元Token调用中国再超美国!腾讯混元Hy3 Preview大模型霸榜!数据背后隐藏了哪些造富机会?
国家数据局:指数级增长 2025年我国词元调用量约21100万亿
全球上周(4月20日至26日)词元TokenAI大模型调用量回升,美国模型调用量继续领先中国,DeepSeek这周能否力挽狂澜?
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
厉害了!指数级增长 2025年我国词元Token调用量约21100万亿!数据背后隐藏了哪些造富机会?
全球上周(4月20日至26日)词元TokenAI大模型调用量回升,美国模型调用量继续领先中国,DeepSeek这周能否力挽狂澜?
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
国家数据局:拟探索词元交易等新型交易模式,词元Token未来到底有哪些机会?
全国首个!“词元(Token)”级城市综合算力运行服务平台在天河上线,中国大模型调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!
词元Token第一股市值涨破1000亿,上市百日股价狂飙513.86%!中国大模型调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!
腾讯云一个月内涨价两次!源于需求旺盛!中国大模型调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!背后隐藏着巨大机会!
中国调用量居然是美国的4倍多!词元Token调用中国大模型霸榜!背后隐藏着巨大的机会!
词元Token调用中国大模型霸榜!前六全部是中国的大模型!最新数据仍然暴增,中国调用量居然是美国的4倍多!
这家上市公司发布“炸裂”数据!厉害了词元Token!最新数据仍然暴增,提价后仍然具备竞争力!
厉害了词元Token!最新数据仍然暴增,提价后仍然具备竞争力!
词元Token搜索量飙涨1850%!一文带你搞懂什么是词元Token!
超600亿!德国砸钱加码风电,购车补贴向中国品牌敞开大门,再议词元调用量暴增推动算力大涨价!
在人工智能领域,词元(token)主要用来计量以下几方面:
1.信息处理量
词元(token)是大语言模型处理信息的基本单位,用于衡量输入文本(如用户提问)和输出文本(如模型生成的回答)的规模。例如,一段文字被拆分为多个词元(Token),词元(token)数量越多,表示处理的信息量越大。词元(token)正成为衡量AI工作量的核心单位,其经济价值推动算力产业链变革,上游芯片与服务器厂商受益,下游企业则面临成本压力,倒逼技术优化与国产算力替代进程加速。
2.算力消耗
模型每处理一个词元(token),都需要消耗一定的计算资源(如GPU算力、内存等)。因此,词元(token)数量直接反映了模型运行时的算力消耗程度,是衡量计算成本的重要指标。
3.服务计费依据
在AI服务商业化场景中,词元(token)通常作为计费单位。服务提供商根据用户消耗的词元(token)数量收取费用,用户使用越复杂、越长的任务,消耗的词元(token)越多,费用也越高。简而言之,词元(token)既是技术层面衡量信息处理和算力使用的单位,也是商业层面衡量AI服务价值和成本的核心指标。
你对股市上涨及A股下跌是什么样的心态及心情?
欢迎评论区留言交流
以上所有内容仅供投资者学习交流用,不作为投资建议。股市有风险投资需谨慎!
