夜雨聆风
夜雨聆风





以下文章来源于微信公众号:爱罗AI说
作者:Aleo
链接:https://mp.weixin.qq.com/s/JE4jFdRm0NZDlNRIhPvpBA
本文仅用于学术分享,如有侵权,请联系后台作删文处理

01
—
开篇
在日常工作以及互联网上,经常有人问,该如何做好一个AI项目?为啥我的模型效果一直不行?AI看似那么牛,为啥时常犯傻?我该在项目上怎么用好AI这个工具?工作这么多年,听到过新毕业的小白同学在问;也有资深的产品以及技术大咖在问;甚至很多不了解AI但想引入AI到他们业务流中的“老板们”也想知道。
作为一个在这个行业里摸爬滚打了八、九年的老油条,有一些自己的看法,想分享给大家,也想从大家那里获取到一些不一样的理解。以前零零碎碎写过一些文章,也获得过一些同学的认可,回过头来看,却是有些太琐碎,也不系统,不太利于自己的沉淀,也不利于别人系统的了解AI的落地过程。大家工作过的都知道,在实战中学习和积累的是最快的,所以寻思着,是不是可以向大家展示一下,作为一个技术同学,实际落地一个AI项目是什么样的一个过程,这样大家了解的更系统,我自己也可以通过咀嚼下过往,理解的更深刻。
基于上面的考虑,寻思着可以出个这样的系列,作为实战项目,希望能涵盖AI落地的基础路径,理解成本也没那么高,就选择了一个常规的安防场景-车流量统计。下面让我们以一个算法工程师的角度,看如何研发一套可用的车流量统计算法系统。

需求分析
车流量即单位时间内通过某路段或交通点的车辆数目。在交通规划中,车流量的统计数据是设计道路、制定交通政策和评估交通项目效果的重要依据。通过对车流量的监测和分析,有关部门可以了解道路的拥堵状况,从而采取相应的措施。本项目的输入为道路上监控摄像头的视频流数据,输出为统计时间段内的车流量均值。
车流量的定义
任何一个算法项目,需求定义清楚是可以进行后面研发的基础,所以,首先要确认什么叫“车流量”,这部分的定义不是上面的那种名词解释,而是面向计算机可以理解的了的定义。定义好问题,也是算法工程师非常重要的技能。
这个项目关注场景为安放在道路中间的摄像头,视野可涵盖正向(即迎着摄像头方向)和反向(即顺着摄像头方向)行驶的车辆,需分别统计客户指定时间段内,正向和反向主路上车流量均值。在关注行驶方向上定义与道路垂直的横截线,越过该线的车辆即计数,并用于统计车流量。

性能指标要求
车流量统计值与真实偏差5%以内;处理效率为单服务器同时处理10路数据。
数据输入输出
系统对接前端管理平台,输入数据为前端摄像头采集的RTSP流,分辨率为1080P,帧率25FPS;统计开始信号;统计结束信号;触发车流量统计的横截线;均由管理平台下发。系统输出统计时间段内的平均车流量,反馈管理平台。
系统部署平台
ubuntu20.04服务器,搭配3080显卡,16核 单核3.6G Hz CPU处理器。
方案选型
算法方案选型
本项目适用目标跟踪后提取轨迹线,利用轨迹线与道路横截线的相对关系统计车流量。在
视觉识别算法方面,该场景关注的车辆属于常规的目标,使用YOLOv11做目标检测,ByteTrack做目标跟踪,即可满足需求。
业务算法方面,车辆跟踪后以车尾边的中心点形成轨迹线,判断轨迹线是否跨越横截线,跨越哪条横截线,即对应行驶方向的车流数量加一。
系统方案选型
算法工程化方面,采用 TensorRT 量化推理实现模型的前向推理加速。多路数据同时接入,多batch推理后再拆分跟踪的方式实现资源的最大化利用,提升算法运行效率。
视频流数据接入方面,采用ffmpeg库执行多路数据的实时解码。
指令数据接入方面,使用gRPC做数据通讯交互。
系统部署方案选型
选用docker作为系统部署的载体,系统部署后,以一个常驻的服务形式存在,开机自启,启动后即可实时响应管理平台的指令调度。
在工作之余抽时间总结这些东西,时间有限,但也会尽最大努力保证质量,按照一般先粗后细的模式,先会尽快将项目的全部链路打通,使全链路功能闭环,可以正常运行,然后再逐个技术点拆解,并分享一些算法优化的经验。
02
—
车流量统计项目-YOLO模型的部署
考虑实际落地中部署推理资源消耗,速度与模型精度之间的均衡,同时,车辆属于比较通用场景的目标检测,我们将YOLOV11作为最终的模型选择,目前官方开源的模型基于coco数据集训练,里面已经包含了车辆相关类别,经测试,在监控视角下效果基本可用,所以,在落地过程中,我们先用这个模型来打通部署链路,后面再逐步优化模型性能。
在Nvidia的硬件下做部署,部署框架优先选择官方框架TensorRT,下面重点讲述如何用TensorRT部署YOLOV11模型。主要分为:训练框架下模型的推理验证,中间件模型onnx的转换,中间件到TensorRT模型转换,以及C++部署四个部分,每一步都会穿插着精度对齐,最后会做推理性能测试。

训练框架下模型的推理验证
一般思路下讲一个模型的应用会按模型理论知识,训练优化,推理部署这样的思路来。我们以项目推进角度整个流程就反过来了,先讲部署,项目上急着用呢,模型的部署要关注三个部分,即模型的前处理,模型的推理以及模型的后处理部分,一般会在推理框架上先做验证,确认没问题后再向后面的部署框架迁移。这三部分我们最关注的是前处理和后处理,推理更多的是框架自己搞定。
模型前处理
YOLOV11的默认模型前处理过程为不变形resize,默认尺寸为640*640,即:
计算缩放比例,原始图像宽大于高,则将宽设置为640,高度自适应到相应的值;原始图像宽小于高,则高设置为640,宽度自适应到相应的值;
使用opencv自带的resize函数将图片按上述计算缩放尺寸进行缩放,方式选择“双线性差值”。然后再构建一个640*640的底图,像素值均初始化为(114,114,114),并将已缩放好的原始图片居中贴在底图上。
将opencv的BGR格式图片数据转换为RGB,并进行归一化操作,并转换为维度格式为[N,C,H,W]四维向量输入模型,本期推理默认batch为1。
具体代码参考:
defpreprocess_warpAffine(image, dst_width=640, dst_height=640):"""图像预处理函数,用于将输入图像变形并缩放到指定大小。该函数首先计算缩放因子,以确保图像按比例缩放到目标尺寸,然后计算偏移量,以确保缩放后的图像居中。使用计算得到的缩放和偏移参数对图像进行仿射变换,并对变换后的图像进行颜色反转、归一化和维度转换,以适应深度学习模型的输入要求。参数:image: 输入的图像,通常是一个二维或三维的numpy数组。dst_width: 目标图像的宽度,默认值为640像素。dst_height: 目标图像的高度,默认值为640像素。返回:img_pre: 预处理后的图像,是一个四维的PyTorch张量。IM: 逆仿射变换矩阵,用于将变形后的图像恢复到原始状态。"""# 计算缩放因子,确保图像按比例缩放到目标尺寸scale = min((dst_width / image.shape[1], dst_height / image.shape[0]))# 计算偏移量,确保缩放后的图像居中ox = int((dst_width - scale * image.shape[1]) / 2)oy = int((dst_height - scale * image.shape[0]) / 2)# 构建仿射变换矩阵M = np.array([[scale,0, ox],[0,scale, oy]],dtype=np.float32)# 对图像进行仿射变换,设置目标尺寸、插值方法和边界填充方式img_pre = cv2.warpAffine(image, M, (dst_width, dst_height), flags=cv2.INTER_LINEAR,borderMode=cv2.BORDER_CONSTANT, borderValue=(114, 114, 114))# 计算逆仿射变换矩阵,用于将变形后的图像恢复到原始状态IM = cv2.invertAffineTransform(M)# 对变换后的图像进行颜色反转和归一化处理img_pre = (img_pre[...,::-1] / 255.0).astype(np.float32)# 调整图像数据的维度顺序,适应深度学习模型的输入要求img_pre = img_pre.transpose(2, 0, 1)[None]# 将处理后的图像数据转换为PyTorch张量img_pre = torch.from_numpy(img_pre)# 设置PyTorch打印选项,提高输出精度torch.set_printoptions(precision=6)# 返回预处理后的图像和逆仿射变换矩阵returnimg_pre, IM
模型后处理
模型经推理后,输出格式为[1, 84, 8400],其中84表示[cx,cy,w,h,class×80],即检测框的中心点坐标,宽,高,以及coco数据集80个类别的置信度;8400表示三个不同尺度的输出,即20×20+40×40+80×80。
按设置的置信度阈值过滤8400个候选框,默认0.25;
对于过滤后的候选框执行NMS,iou阈值默认0.45,剩下的即为输出检测框。
具体代码参考:
# 计算两个边界框的交并比(Intersection over Union,IoU)defiou(box1, box2):# 内部函数,用于计算边界框的面积defarea_box(box):return (box[2] - box[0]) * (box[3] - box[1])# 计算交集的左上角和右下角坐标left = max(box1[0], box2[0])top = max(box1[1], box2[1])right = min(box1[2], box2[2])bottom = min(box1[3], box2[3])# 计算交集的面积cross = max((right-left), 0) * max((bottom-top), 0)# 计算并集的面积union = area_box(box1) + area_box(box2) - cross# 如果交集或并集的面积为0,则返回0if cross == 0or union == 0:return0# 返回交并比return cross / union# 非极大值抑制(Non-Maximum Suppression,NMS)算法,用于去除多余的边界框defNMS(boxes, iou_thres):# 初始化一个标记列表,用于标记是否移除某个边界框remove_flags = [False] * len(boxes)# 初始化一个列表,用于保存保留下来的边界框keep_boxes = []# 遍历所有边界框for i, ibox in enumerate(boxes):# 如果当前边界框已被标记为移除,则跳过if remove_flags[i]:continue# 将当前边界框添加到保留列表中keep_boxes.append(ibox)# 继续遍历其余的边界框for j in range(i + 1, len(boxes)):# 如果当前边界框已被标记为移除,则跳过if remove_flags[j]:continue# 获取下一个边界框jbox = boxes[j]# 如果两个边界框的类别标签不同,则跳过if(ibox[5] != jbox[5]):continue# 如果两个边界框的交并比大于设定的阈值,则标记第二个边界框为移除if iou(ibox, jbox) > iou_thres:remove_flags[j] = True# 返回保留下来的边界框列表return keep_boxes# 后处理函数,用于处理模型的预测结果defpostprocess(pred, IM=[], conf_thres=0.25, iou_thres=0.45):# 初始化一个列表,用于保存处理后的边界框boxes = []# 遍历模型的预测结果for item in pred[0]:# 提取边界框的中心坐标、宽度、高度cx, cy, w, h = item[:4]# 提取类别标签和置信度label = item[4:].argmax()confidence = item[4 + label]# 如果置信度低于设定的阈值,则跳过if confidence < conf_thres:continue# 计算边界框的左上角和右下角坐标left = cx - w * 0.5top = cy - h * 0.5right = cx + w * 0.5bottom = cy + h * 0.5# 将边界框的坐标、置信度和类别标签添加到列表中boxes.append([left, top, right, bottom, confidence, label])# 将边界框列表转换为NumPy数组boxes = np.array(boxes)# 如果没有边界框,则返回空列表if0 == len(boxes):return []# 应用图像的缩放比例和偏移量,将边界框坐标转换回原始图像的坐标系lr = boxes[:,[0, 2]]tb = boxes[:,[1, 3]]boxes[:,[0,2]] = IM[0][0] * lr + IM[0][2]boxes[:,[1,3]] = IM[1][1] * tb + IM[1][2]# 根据置信度降序排序边界框boxes = sorted(boxes.tolist(), key=lambda x:x[4], reverse=True)# 应用非极大值抑制,去除多余的边界框return NMS(boxes, iou_thres)
数据集下的推理验证
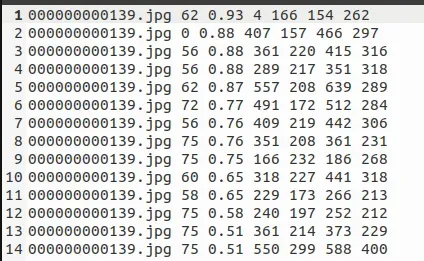
上述做完后,需要做一下测试集上的推理验证,我们选择coco数据集自带的5000张测试集,验证下来结果基本没有问题。

同时,按“图片名称,类别索引,置信度,检测框”格式,保存识别结果,用于后面模型转换精度保持的精度分析。
中间件模型onnx的转换
本次使用pytorch转TensorRT的常规方式,通过转换中间件onnx进行转换,这步还比较简单,不BB,直接见代码:
model = YOLO(model='yolo11x.pt') # load a pretrained model (recommended for training)model.export(format="onnx", opset=16, imgsz=640, simplify=True, save_dir='.')
onnx的前后处理也pytorch一样,只是推理调用部分有所区别,这部分不放代码了,后面大家自己在代码仓库中看即可。
中间件到TensorRT模型转换
中间件模型转换完以后,正式到转TensorRT模型的阶段了,我们这次采用的是调用TensorRT的python接口的方式转换(方式有很多,选合适的即可),为快速跑通链路,我们选择了FP16精度做部署,后面细化调优的时候,会跟大家讲讲INT8,这里面可能遇到的坑比较多,到时候细聊。同样不BB,直接上代码:
defbuild_engine(onnx_model_path, engine_path, precision_set="fp16"):"""从ONNX模型生成TensorRT引擎。参数:onnx_model_path: str,ONNX模型的路径。engine_path: str,生成的TensorRT引擎的保存路径。precision_set: str,精度设置,默认为"fp16"。返回:无"""# 创建TensorRT日志记录器TRT_LOGGER = trt.Logger(trt.Logger.WARNING)# 创建TensorRT构建器builder = trt.Builder(TRT_LOGGER)# 创建网络定义,并设置显式批处理标志network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))# 创建ONNX解析器parser = trt.OnnxParser(network, TRT_LOGGER)# 打开ONNX模型文件并解析with open(onnx_model_path, "rb") as model:ifnot parser.parse(model.read()):# 如果解析失败,打印错误信息for error in range(parser.num_errors):print(parser.get_error(error))# 创建构建配置config = builder.create_builder_config()# 设置最大工作空间大小为1GBconfig.max_workspace_size = 1 << 30# 1GB# 如果精度设置为fp16,启用FP16模式if precision_set == "fp16":config.set_flag(trt.BuilderFlag.FP16)# 如果引擎文件不存在,构建并保存引擎ifnot os.path.exists(engine_path):engine = builder.build_engine(network, config)with open(engine_path, "wb") as f:# 序列化引擎并写入文件f.write(engine.serialize())
模型转换完,也要做个这部分的单元测试,TensorRT模型的前后处理和pytorch模型不太一样,不过差异不大,主要是:
预处理阶段转成[N,C,H,W]四维向量后,需要拉成一维传给模型;
模型推理完成以后,也是以一维的方式输出,同样要转换为[1, 84, 8400]格式后,接前面的后处理算法。
C++部署
最终算法将以C++的方式部署在客户机器上,所以需要将TensorRT模型python部分的推理代码移植成c++,同时顺带做了些推理优化,主要是将前处理和后处理的代码用cuda重写了,以提升推理性能。
前处理的cuda移植
双线性差值的不变形resize,做灰边填充部分的代码如下:
__global__ voidletterbox(const uchar* srcData, constint srcH, constint srcW, uchar* tgtData,constint tgtH, constint tgtW, constint rszH, constint rszW, constint startY, constint startX){int ix = threadIdx.x + blockDim.x * blockIdx.x;int iy = threadIdx.y + blockDim.y * blockIdx.y;int idx = ix + iy * tgtW;int idx3 = idx * 3;if ( ix > tgtW || iy > tgtH ) return; // thread out of target range// gray region on target imageif ( iy < startY || iy > (startY + rszH - 1) ) {tgtData[idx3] = 114;tgtData[idx3 + 1] = 114;tgtData[idx3 + 2] = 114;return;}if ( ix < startX || ix > (startX + rszW - 1) ){tgtData[idx3] = 114;tgtData[idx3 + 1] = 114;tgtData[idx3 + 2] = 114;return;}float scaleY = (float)rszH / (float)srcH;float scaleX = (float)rszW / (float)srcW;// (ix,iy)为目标图像坐标// (before_x,before_y)原图坐标float beforeX = float(ix - startX + 0.5) / scaleX - 0.5;float beforeY = float(iy - startY + 0.5) / scaleY - 0.5;// 原图像坐标四个相邻点// 获得变换前最近的四个顶点,取整int topY = static_cast<int>(beforeY);int bottomY = topY + 1;int leftX = static_cast<int>(beforeX);int rightX = leftX + 1;//计算变换前坐标的小数部分float u = beforeX - leftX;float v = beforeY - topY;if (topY >= srcH - 1 && leftX >= srcW - 1) //右下角{for (int k = 0; k < 3; k++){tgtData[idx3 + k] = (1. - u) * (1. - v) * srcData[(leftX + topY * srcW) * 3 + k];}}elseif (topY >= srcH - 1) // 最后一行{for (int k = 0; k < 3; k++){tgtData[idx3 + k]= (1. - u) * (1. - v) * srcData[(leftX + topY * srcW) * 3 + k]+ (u) * (1. - v) * srcData[(rightX + topY * srcW) * 3 + k];}}elseif (leftX >= srcW - 1) // 最后一列{for (int k = 0; k < 3; k++){tgtData[idx3 + k]= (1. - u) * (1. - v) * srcData[(leftX + topY * srcW) * 3 + k]+ (1. - u) * (v) * srcData[(leftX + bottomY * srcW) * 3 + k];}}else// 非最后一行或最后一列情况{for (int k = 0; k < 3; k++){tgtData[idx3 + k]= (1. - u) * (1. - v) * srcData[(leftX + topY * srcW) * 3 + k]+ (u) * (1. - v) * srcData[(rightX + topY * srcW) * 3 + k]+ (1. - u) * (v) * srcData[(leftX + bottomY * srcW) * 3 + k]+ u * v * srcData[(rightX + bottomY * srcW) * 3 + k];}}}
颜色通道转换以及归一化部分的代码如下:
__global__ voidprocess(const uchar* srcData, float* tgtData, constint h, constint w){int ix = threadIdx.x + blockIdx.x * blockDim.x;int iy = threadIdx.y + blockIdx.y * blockDim.y;int idx = ix + iy * w;int idx3 = idx * 3;if (ix < w && iy < h){tgtData[idx] = (float)srcData[idx3 + 2] / 255.0; // R pixeltgtData[idx + h * w] = (float)srcData[idx3 + 1] / 255.0; // G pixeltgtData[idx + h * w * 2] = (float)srcData[idx3] / 255.0; // B pixel}}
后处理的cuda移植
数据解码的cuda化
// ------------------ decode ( get class and conf ) --------------------__global__ voiddecode_kernel(float* src, float* dst, int numBboxes, int numClasses, float confThresh, int maxObjects, int numBoxElement){int position = blockDim.x * blockIdx.x + threadIdx.x;if (position >= numBboxes) return;float* pitem = src + (4 + numClasses) * position;float* classConf = pitem + 4;float confidence = 0;int label = 0;for (int i = 0; i < numClasses; i++){if (classConf[i] > confidence){confidence = classConf[i];label = i;}}if (confidence < confThresh) return;int index = (int)atomicAdd(dst, 1);if (index >= maxObjects) return;float cx = pitem[0];float cy = pitem[1];float width = pitem[2];float height = pitem[3];float left = cx - width * 0.5f;float top = cy - height * 0.5f;float right = cx + width * 0.5f;float bottom = cy + height * 0.5f;float* pout_item = dst + 1 + index * numBoxElement;pout_item[0] = left;pout_item[1] = top;pout_item[2] = right;pout_item[3] = bottom;pout_item[4] = confidence;pout_item[5] = label;pout_item[6] = 1; // 1 = keep, 0 = ignore}voiddecode(float* src, float* dst, int numBboxes, int numClasses, float confThresh, int maxObjects, int numBoxElement, cudaStream_t stream){cudaMemsetAsync(dst, 0, sizeof(int), stream);int blockSize = 256;int gridSize = (numBboxes + blockSize - 1) / blockSize;decode_kernel<<<gridSize, blockSize, 0, stream>>>(src, dst, numBboxes, numClasses, confThresh, maxObjects, numBoxElement);}
nms的cuda化
__device__ floatbox_iou(float aleft, float atop, float aright, float abottom,float bleft, float btop, float bright, float bbottom){float cleft = max(aleft, bleft);float ctop = max(atop, btop);float cright = min(aright, bright);float cbottom = min(abottom, bbottom);float c_area = max(cright - cleft, 0.0f) * max(cbottom - ctop, 0.0f);if (c_area == 0.0f) return0.0f;float a_area = max(0.0f, aright - aleft) * max(0.0f, abottom - atop);float b_area = max(0.0f, bright - bleft) * max(0.0f, bbottom - btop);return c_area / (a_area + b_area - c_area);}__global__ voidnms_kernel(float* data, float kNmsThresh, int maxObjects, int numBoxElement){int position = blockDim.x * blockIdx.x + threadIdx.x;int count = min((int)data[0], maxObjects);if (position >= count) return;// left, top, right, bottom, confidence, class, keepflagfloat* pcurrent = data + 1 + position * numBoxElement;float* pitem;for (int i = 0; i < count; i++){pitem = data + 1 + i * numBoxElement;if (i == position || pcurrent[5] != pitem[5]) continue;if (pitem[4] >= pcurrent[4]){if (pitem[4] == pcurrent[4] && i < position) continue;float iou = box_iou(pcurrent[0], pcurrent[1], pcurrent[2], pcurrent[3],pitem[0], pitem[1], pitem[2], pitem[3]);if (iou > kNmsThresh){pcurrent[6] = 0; // 1 = keep, 0 = ignorereturn;}}}}voidnms(float* data, float kNmsThresh, int maxObjects, int numBoxElement, cudaStream_t stream){int blockSize = maxObjects < 256?maxObjects:256;int gridSize = (maxObjects + blockSize - 1) / blockSize;nms_kernel<<<gridSize, blockSize, 0, stream>>>(data, kNmsThresh, maxObjects, numBoxElement);}
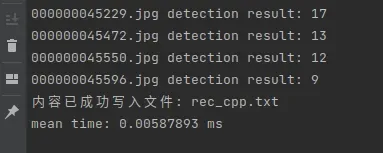
基于c++的推理部署与cuda加速后,相应的模型和代码将作为最终的产出集成进产品里,使用测试集测试确定:
单帧推理耗时5.88毫秒,即一秒推理170帧,粗略估计实时处理10路数据问题不大。(还没有发力,指标就达到了,没意思,后面再手动给自己加戏吧,一堆优化策略没上呢)
下一步逐步做完性能保持的测试,确保量化部署后的模型和原始模型没有大的精度损失,即可对外发布了。
量化精度损失评估
以最终目标为导向,进行量化后目标精度损失的评估,即这一批数据中每一张图应该出几个框,统计下量化后这些框还在不在,在的话即认为没有精度损失,否则认为有精度损失,简单高效。具体方法如下:
逐类别拆分,分析每个类别的量化精度损失;
定义IOU阈值为0.5,进行量化前后的目标框匹配,最匹配目标IOU大于0.5即认为匹配上,以量化前作为真值,统计匹配上目标的准确率和召回率,进而判断是否有不可接受的精度损失。
精度保持测试:
pytorch模型和c++版本TensorRT模型
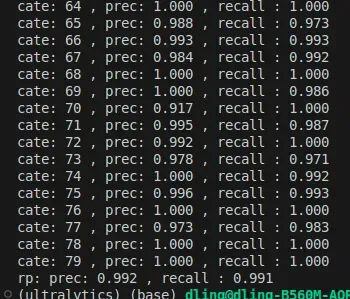
有精度损失但差异不大,整体可以用,后续可以着重看损失点在哪里,进行相关优化。
到这为止,YOLOV的量化部署就结束了,达到了基本可用的程度,后续再继续优化,其实整体链路早就打通了,只是在做一致性测试的时候,一直有一些问题,仔细排查后才对齐,而这一块也是做模型部署很重要的一部分工作,后续再着重讲吧。
备注:
c++部署部分的代码参考了 https://github.com/emptysoal/TensorRT-YOLO11,这里面有较多的yolo系列的工程实现,大家也可以访问支持。
03
—
多路视频推拉流服务
工具安装
上面三个工具OpenCV属于常规工具,我就不介绍了,重点介绍 mediamtx 和 FFmpeg 在ubuntu20.04上的安装方式。
mediamtx
下载地址:https://github.com/bluenviron/mediamtx/releases,选择 mediamtx_v1.9.1_linux_amd64.tar.gz,这个版本是验证过可以直接用的。
下载后直接解压即可,里面主要就俩文件,一个 mediamtx 的可执行文件,一个 mediamtx.yml 的配置文件
使用默认配置就行,如需配置相关端口,可在 mediamtx.yml 内修改
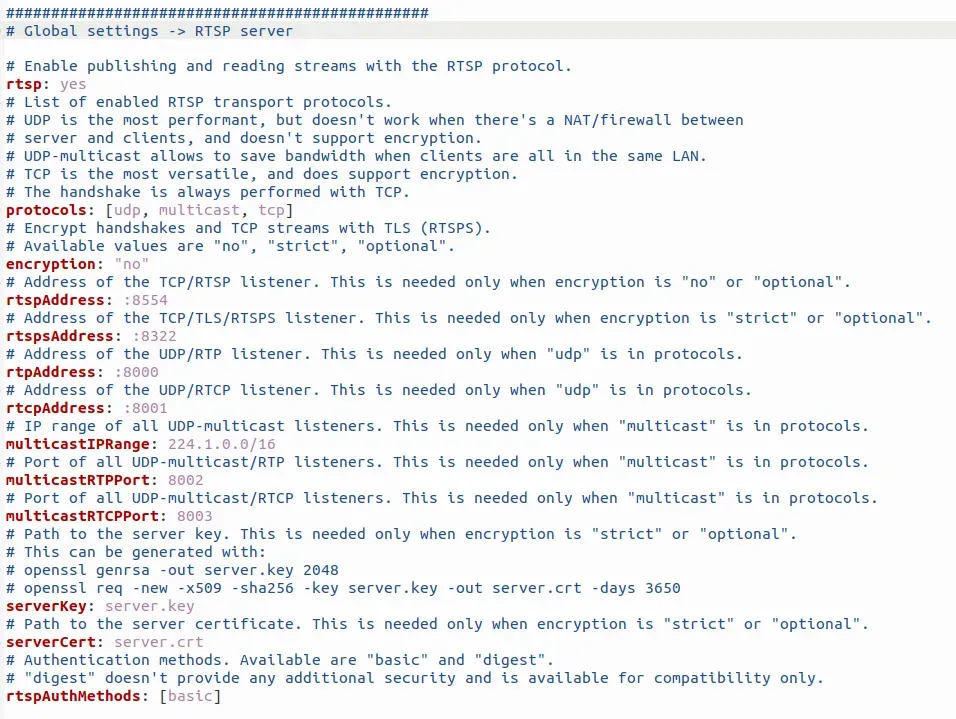
相关配置确认后,直接终端执行 “./mediamtx”即可。
FFmpeg
FFmpeg常规安装可以支持apt,我们本次安装走的是源码编译,一个是我个人习惯,源码编译可以解决很多环境兼容性问题,一个是为后面解码性能提升做准备,我们编译支持cuda的版本。
源码下载
git clone -b release/7.1 git@github.com:FFmpeg/FFmpeg.git
https://github.com/FFmpeg/nv-codec-headers/releases 内下载 nv-codec-headers-12.2.72.0 这个要和nvidia-smi里的cuda version匹配,我选的12.2
wget http://ftp.videolan.org/pub/videolan/x265/x265_2.6.tar.gz
x264安装
sudo apt-get install libx264-dev
sdl 安装,ffplay依赖
sudo apt-get install libsdl2-dev
x265编译
解压安装包
cd x265_v2.6/build/linux/
sh ./make-Makefiles.bash
make
make install
默认安装在系统目录下,这个目录要记下来,后面部署时候可能要用。
nv-codec-headers 编译
cd nv-codec-headers-12.2.72.0/
make
make install
默认安装在系统目录下,这个目录要记下来,后面部署时候可能要用。

ffmpeg源码编译
在工程目录下,./configure --prefix=/usr/local/ffmpeg --enable-shared --disable-static --disable-doc --enable-gpl --enable-libx265 --enable-libx264 --enable-cuda --enable-cuvid --enable-nvdec --disable-x86asm
make
make install
默认安装在系统目录/usr/local/ffmpeg下,这个目录要记下来,后面部署时候可能要用
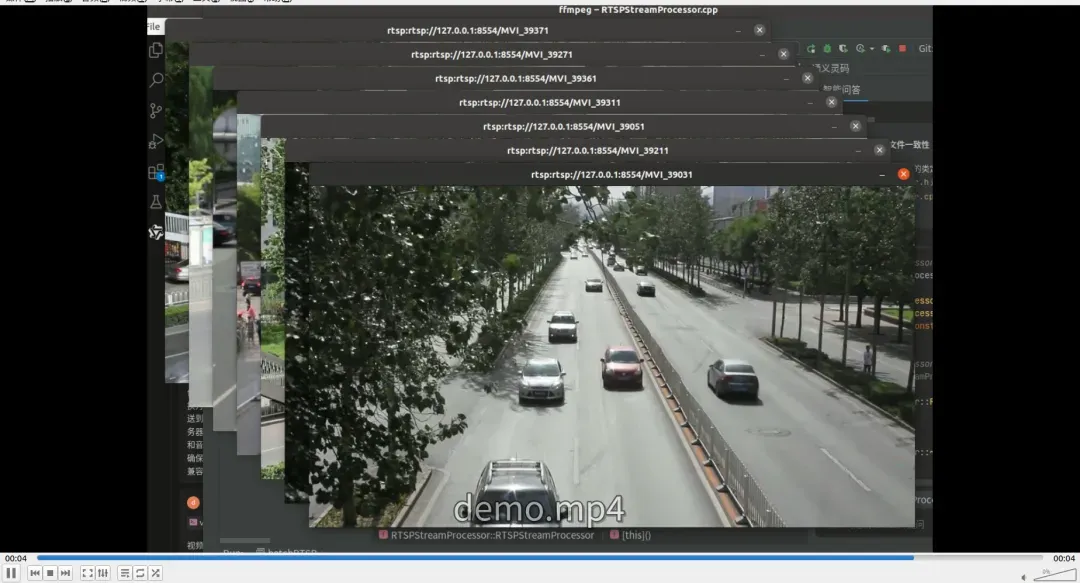
模拟推流
一般情况下RTSP流的源头来自于相机,系统侧主要关注拉流解码即可,但在研发和测试阶段没有那么多真实数据可以接入,所以需要搭建一套模型的推流服务,该推流服务支持多路数据的推送。
核心代码就这一句:
ffmpeg -re -i "${INPUT_MP4}" -c:v libx264 -preset veryfast -maxrate 3000k -bufsize 6000k -pix_fmt yuv420p -g 50 -c:a aac -b:a 160k -ac 2 -ar 44100 -f rtsp "${RTSP_URL}"基本参数包括
-re 以输入文件的原始帧率读取输入文件。通常用于模拟实时流。
-i "${INPUT_MP4}": 指定输入文件路径
视频编码参数包括:
ultrafast:编码速度非常快,但输出视频质量不高。
superfast:编码速度非常快,输出视频质量比ultrafast略微高一些。
veryfast:编码速度较快,输出视频质量较好。
fast:编码速度较快,输出视频质量较好。
medium:编码速度适中,输出视频质量非常好,这是默认值。
slow:编码速度较慢,但输出视频质量比medium更好。
slower:编码速度比slow略微慢一些,但输出视频质量更好。
veryslow:编码速度最慢,但输出视频质量最好。
-c:v libx264: 使用 H.264 编码器对视频进行编码, H.264 编码器,兼容性好,压缩效率高。适合大多数应用场景。如果需要更高的压缩比和更好的质量,可以考虑使用 H.265/HEVC 编码器(-c:v libx265),但编码速度会更慢,硬件要求也更高。
-preset veryfast: 设置编码速度为非常快(veryfast),这会牺牲一些压缩效率以换取更快的编码速度。-preset 参数设置参考:
-maxrate 3000k: 设置最大比特率为 3000 kbps(3 Mbps)。确保该值与目标网络带宽匹配,避免过高导致网络拥塞或过低影响视频质量。可以结合 -minrate 和 -bufsize 参数进一步优化比特率控制。
-bufsize 6000k: 设置缓冲区大小为 6000 kbps(6 Mbps),用于平滑比特率波动。一般建议 -bufsize 至少是 -maxrate 的两倍,以确保稳定的比特率输出。对于网络条件较差的情况,可以适当增大缓冲区。
-pix_fmt yuv420p: 设置像素格式为 YUV 4:2:0,大多数设备和播放器支持的格式。
-g 50: 设置 GOP(Group of Pictures)大小为 50,即每隔 50 帧插入一个关键帧(I 帧)。
音频编码参数包括(本项目不太关注):
-c:a aac: 使用 AAC 编码器对音频进行编码。
-b:a 160k: 设置音频比特率为 160 kbps。
-ac 2: 设置音频声道数为 2(立体声)。
-ar 44100: 设置音频采样率为 44100 Hz。
输出格式
-f rtsp: 指定输出格式为 RTSP 流协议。
"${RTSP_URL}": 指定 RTSP 流的 URL。
支持多路视频推送的shell脚本代码如下:
#!/bin/bash# 检查参数数量if [ "$#" -ne 2 ]; thenecho "Usage: $0 <input_folder> <rtsp_base_url>"exit 1fi# ffmpeg路径export PATH=../../3rd/ffmpeg/bin:$PATHexport LD_LIBRARY_PATH=../../3rd/ffmpeg/lib# 输入的文件夹路径INPUT_FOLDER="$1"# 输出的RTSP URL基础RTSP_BASE_URL="$2"# 检查输入文件夹是否存在if [ ! -d "$INPUT_FOLDER" ]; thenecho "Error: Input folder $INPUT_FOLDER not found!"exit 1fi# 遍历输入文件夹中的所有MP4文件for INPUT_MP4 in "$INPUT_FOLDER"/*.mp4; do# 检查文件是否存在if [ ! -f "$INPUT_MP4" ]; thenecho "No MP4 files found in $INPUT_FOLDER!"continuefi# 获取文件名(不带路径)FILENAME=$(basename "$INPUT_MP4")# 去掉文件扩展名BASENAME="${FILENAME%.*}"# 构建RTSP URLRTSP_URL="${RTSP_BASE_URL}/${BASENAME}"# 使用 FFmpeg 将 mp4 流转换为 RTSP 流function mp4_to_rtsp {ffmpeg -re -i "${INPUT_MP4}" -c:v libx264 -preset veryfast -maxrate 3000k -bufsize 6000k -pix_fmt yuv420p -g 50 -c:a aac -b:a 160k -ac 2 -ar 44100 -f rtsp "${RTSP_URL}"}# 启动推送MP4文件的FFmpeg进程echo "Starting to push MP4 file $INPUT_MP4 to RTSP server at $RTSP_URL..."mp4_to_rtsp &done# 等待所有后台任务完成waitecho "All processes have finished."
实时解码
实时解码部分的技术方案采用的是C++的线程池技术,用于适应不同路数视频数据的实时接入,解码库依旧使用的是FFmpeg,这个部分使用的是FFmpeg的C++接口函数,不废话,直接上代码:
线程池解码的类头文件:
#ifndef RTSPSTREAMPROCESSOR_H#define RTSPSTREAMPROCESSOR_H#include"common.h"class RTSPStreamProcessor {public:// 构造函数,初始化线程池RTSPStreamProcessor(int numThreads, BlockingQueue<sSingleFrameInfo>& queue);// 析构函数,停止线程池并等待所有线程结束~RTSPStreamProcessor();// 将RTSP URL添加到任务队列中voidenqueue(const std::string& rtspUrl);private:// 处理单个RTSP流voidprocessRTSPStream(const std::string& rtspUrl);// 工作线程池std::vector<std::thread> workers;// 任务队列std::queue<std::function<void()>> tasks;// 保护任务队列的互斥锁std::mutex queue_mutex;// 条件变量,用于线程间的通信std::condition_variable condition;// 标志位,指示是否停止处理任务bool stop;uint32_t mGlobalFrameNum = 0;BlockingQueue<sSingleFrameInfo> &frameQueue;};#endif// RTSPSTREAMPROCESSOR_H
线程池解码的类源文件:
#include"RTSPStreamProcessor.h"// 构造函数,初始化线程池RTSPStreamProcessor::RTSPStreamProcessor(int numThreads, BlockingQueue<sSingleFrameInfo>& queue) :stop(false), frameQueue(queue) {for (int i = 0; i < numThreads; ++i) {workers.emplace_back([this] {for (;;) {std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);// 等待任务或停止信号this->condition.wait(lock, [this] { return this->stop || !this->tasks.empty(); });if (this->stop && this->tasks.empty()) {return;}// 获取任务并移除task = std::move(this->tasks.front());this->tasks.pop();}// 执行任务task();}});}}// 析构函数,停止线程池并等待所有线程结束RTSPStreamProcessor::~RTSPStreamProcessor() {{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}// 通知所有线程停止condition.notify_all();for (std::thread& worker : workers) {worker.join();}}// 将RTSP URL添加到任务队列中voidRTSPStreamProcessor::enqueue(const std::string& rtspUrl){{std::unique_lock<std::mutex> lock(queue_mutex);// 将处理RTSP流的任务添加到队列tasks.emplace([this, rtspUrl] { processRTSPStream(rtspUrl); });}// 通知一个线程有新任务condition.notify_one();}// 处理单个RTSP流voidRTSPStreamProcessor::processRTSPStream(const std::string& rtspUrl){AVFormatContext *pFormatCtx = nullptr;AVCodecContext *pCodecCtx = nullptr;AVFrame *pFrame = nullptr, *pFrameBGR = nullptr;AVPacket *packet = nullptr;uint8_t *outBuffer = nullptr;SwsContext *imgConvertCtx = nullptr;int videoStream;bool bConnected = false;while (true){if (!bConnected) {avformat_network_init();AVDictionary *avdic=NULL;av_dict_set(&avdic, "buffer_size", "655360", 0);av_dict_set(&avdic,"rtsp_transport","tcp",0);av_dict_set(&avdic, "max_delay", "500000", 0);av_dict_set(&avdic, "stimeout", "5000000", 0);if (avformat_open_input(&pFormatCtx, rtspUrl.c_str(), nullptr, &avdic) != 0){std::cout << "can't open the file." << std::endl;bConnected = false;continue;}if (avformat_find_stream_info(pFormatCtx, nullptr) < 0){std::cout << "can't find stream infomation" << std::endl;bConnected = false;continue ;}videoStream = -1;for (unsigned int i = 0; i < pFormatCtx->nb_streams; i++){if (pFormatCtx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_VIDEO){videoStream = i;}}if (videoStream == -1){std::cout << "can't find a video stream" << std::endl;bConnected = false;continue ;}const AVCodec *pCodec = avcodec_find_decoder(pFormatCtx->streams[videoStream]->codecpar->codec_id);if (pCodec == NULL){std::cout << "can't find a codec" << std::endl;bConnected = false;continue ;}pCodecCtx = avcodec_alloc_context3(pCodec);if (avcodec_parameters_to_context(pCodecCtx, pFormatCtx->streams[videoStream]->codecpar) < 0) {std::cerr << "Failed to allocate codec context." << std::endl;}pCodecCtx->thread_count = 4;pCodecCtx->thread_type = FF_THREAD_SLICE;if (avcodec_open2(pCodecCtx, pCodec, NULL) < 0){std::cout << "can't open a codec" << std::endl;bConnected = false;continue ;}pFrame = av_frame_alloc();pFrameBGR = av_frame_alloc();imgConvertCtx = sws_getContext(pCodecCtx->width, pCodecCtx->height,pCodecCtx->pix_fmt, pCodecCtx->width, pCodecCtx->height,AV_PIX_FMT_BGR24, SWS_BICUBIC, NULL, NULL, NULL);int numBytes = av_image_get_buffer_size(AV_PIX_FMT_BGR24, pCodecCtx->width, pCodecCtx->height, 1);outBuffer = (uint8_t *) av_malloc(numBytes * sizeof(uint8_t));av_image_fill_arrays(pFrameBGR->data, pFrameBGR->linesize, outBuffer, AV_PIX_FMT_BGR24,pCodecCtx->width, pCodecCtx->height, 1);packet = (AVPacket *) malloc(sizeof(AVPacket));av_new_packet(packet, pCodecCtx->width * pCodecCtx->height);bConnected = true;}uint32_t frameCount = 0;while (av_read_frame(pFormatCtx, packet) >= 0){if (packet->stream_index == videoStream){int ret = avcodec_send_packet(pCodecCtx, packet);if (ret < 0) {// fprintf(stderr, "Error sending a packet for decoding: %s\n", av_err2str(ret));continue;}else{ret = avcodec_receive_frame(pCodecCtx, pFrame);if (ret < 0) {// fprintf(stderr, "Error during decoding: %s\n", av_err2str(ret));}else{sws_scale(imgConvertCtx,(uint8_t const * const *) pFrame->data,pFrame->linesize, 0, pCodecCtx->height, pFrameBGR->data,pFrameBGR->linesize);cv::Mat img(pFrame->height,pFrame->width,CV_8UC3,pFrameBGR->data[0]);// sSingleFrameInfo frameInfo;// frameInfo.frame = img.clone();// frameInfo.rtspUrl = rtspUrl;// frameInfo.localFrameNum = frameCount;queue_mutex.lock();cv::imshow("rtsp:" + rtspUrl, img);if (cv::waitKey(1) == 27) break;queue_mutex.unlock();std::cout << "rtsp:" << rtspUrl << "frameCount: " << frameCount << std::endl;// std::vector<std::string> rtspUrls = splitString(rtspUrl, '/');// const std::string savePath = "/media/dling/data_1/ubuntu/everyDay/20241230/" + rtspUrls.back() + "/";// createDirectories(savePath);// std::string saveName = savePath + std::to_string(frameCount) + ".jpg";// cv::imwrite(saveName, img);frameCount++;}}}av_packet_unref(packet);}bConnected = false;av_free(outBuffer);outBuffer = nullptr;av_freep(&pFrameBGR);av_freep(&pFrame);sws_freeContext(imgConvertCtx);imgConvertCtx = nullptr;avcodec_free_context(&pCodecCtx);pCodecCtx = nullptr;avformat_close_input(&pFormatCtx);pFormatCtx = nullptr;av_packet_free(&packet);packet = nullptr;usleep(1000000);}}
运行展示
深耕企业安全管理+AI领域,通过“技术+商业+内容”的融合视角,深度参与AI产业化落地。
全网20W+粉丝AI知识博主,人工智能技术文章超1000W+阅读,《30天入门人工智能》课程,全网2000+名学员。
主导构建的AI知识平台www.jiangdabai.com累计访问已超800万次;
思想阵地(深度洞察):知乎、CSDN @江大白
内容阵地(视频解读):抖音、快手、小红书 @江大白讲AI
实战阵地(产品纪实):抖音、快手、小红书 @安生江大白 | 记录“1年10个AI产品100个项目应用”的极限挑战

大家一起加油!