 夜雨聆风
夜雨聆风OpenAI模型API调用参数完全解析
文 | AI编程实践
用AI API写了无数行代码,但你真懂这些参数吗?temperature调到0.8和0.2有什么本质区别?top_p和temperature该配合用还是二选一?presence_penalty和frequency_penalty到底谁管"重复话题"、谁管"重复用词"?
更进一步:你知道模型是怎么筛选和决定调用哪个工具的?
多轮对话中 messages 参数如何一步步累积传递?tool_choice="auto" 和 "required" 的背后逻辑是什么?SKILL 框架和 Agent 框架的底层,用的不也是这套 tools 机制吗?
这篇文章一次性讲清楚OpenAI Chat Completions API的核心参数——含义、默认值、最佳实践、常见误区,再用一个完整的"多轮工具调用"实战贯穿所有知识点。
一、先看全景:一个完整的API调用长什么样
from openai import OpenAIclient = OpenAI()response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "你是一个严谨的技术文档作者。"}, {"role": "user", "content": "解释一下什么是API参数temperature?"} ], temperature=0.7, top_p=1.0, max_tokens=1024, frequency_penalty=0.0, presence_penalty=0.0, stop=None, seed=None, stream=False, response_format={"type": "text"})每一行参数都有它的故事。下面逐个拆解。
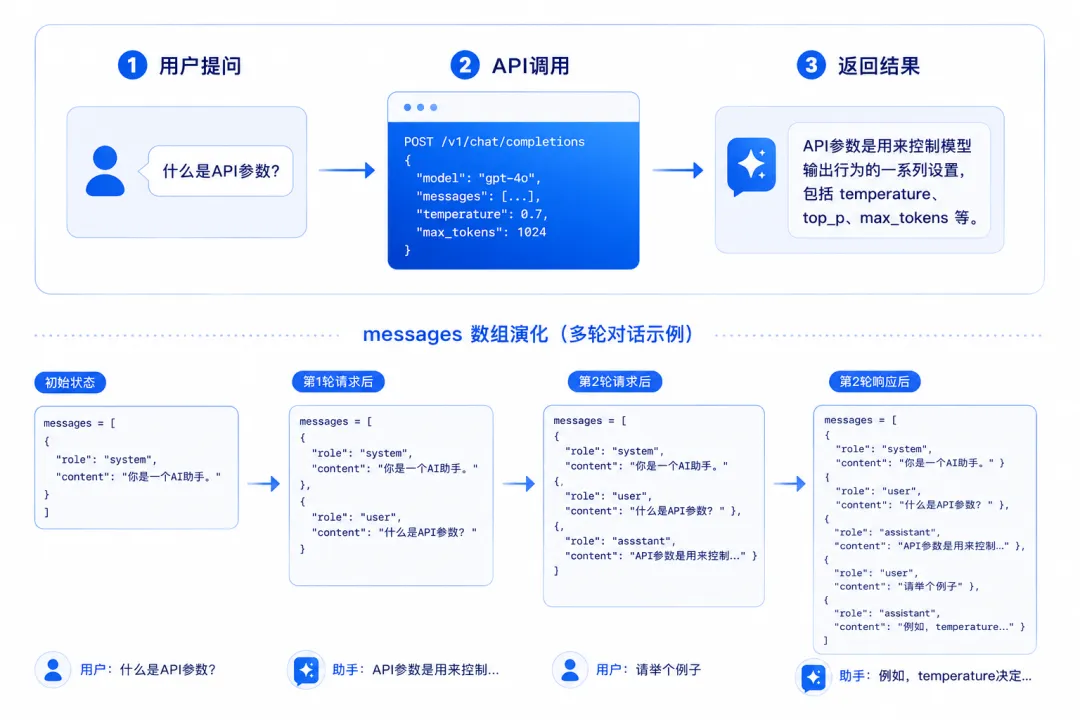
二、核心参数深度解析
2.1 model:选什么模型?
参数:model类型:string(必填)含义:指定要调用的模型ID示例:"gpt-4o", "gpt-4o-mini", "o4-mini", "gpt-4.1"模型选择指南:
| 模型 | 定位 | 适用场景 |
|---|---|---|
💡 关键洞察:选模型不是"越贵越好"。简单分类任务用gpt-4o-mini性价比是gpt-4o的10倍以上,效果基本没差别。
2.2 temperature:控制"脑洞"大小
参数:temperature类型:float,范围 [0, 2]默认值:1含义:控制输出的随机性。越低越确定、越保守;越高越大胆、越有创意。底层原理:temperature影响的是模型在预测下一个token时概率分布的"陡峭程度"。低温度 → 概率分布更集中 → 模型倾向于选最高概率的token → 输出更确定。高温度 → 概率分布更平坦 → 低概率token也有机会被选中 → 输出更丰富但风险更高。
实际效果对比:
| temperature值 | 输出特点 | 适用场景 |
|---|---|---|
最佳实践:代码生成 / 数学推理: temperature=0 → 最确定,每次运行结果一致日常对话 / 客服: temperature=0.7 → 有一定灵活性,不会太死板创意写作: temperature=0.9 → 有创意但不至于跑偏⚠️ 常见误区:temperature=0不代表"完全确定"。由于底层计算存在浮点精度差异,相同prompt在不同请求间仍可能有微小差异。如果需要真正的可复现输出,必须配合
seed参数使用。
2.3 top_p:核采样,给候选词设"门槛"
参数:top_p类型:float,范围 [0, 1]默认值:1含义:核采样(Nucleus Sampling)。只从累积概率达到 top_p 的token中采样,过滤掉长尾低概率token。底层原理:模型预测下一个token时,会为词汇表中每个词计算一个概率。top_p=1表示从所有token中采样;top_p=0.1表示只从累积概率达到10%的那些最可能token中采样——后面的90%直接被截断。
直观理解:
示例:模型预测下一个词的概率分布"我" → 0.4 ← 最可能"我们" → 0.3 ←"大家" → 0.15 ← top_p=0.9 停在这附近"咱" → 0.08 ← 被截断"俺" → 0.05 ← 被截断...(剩余2%分散在大量低概率词中)| top_p值 | 效果 | 适用场景 |
|---|---|---|
💡 关键洞察:temperature和top_p一般不要同时调。OpenAI官方建议二选一——如果调了temperature就保持top_p=1,调了top_p就保持temperature=1。两个一起调容易过度约束,导致输出质量下降。
2.4 max_tokens:控制回答长度
参数:max_tokens(已废弃,改用max_completion_tokens)类型:int含义:限制模型输出的最大token数(包含思考过程)注意:max_tokens已被max_completion_tokens替代,新代码请用后者Token ≠ 字,这一点很多人搞错:
| 语言 | 1个Token约等于 |
|---|---|
实际长度估算:
max_completion_tokens=256 → 约170个中文字,适合简短回答max_completion_tokens=1024 → 约700个中文字,适合段落级回复max_completion_tokens=4096 → 约2800个中文字,适合长文输出max_completion_tokens=16384 → 模型最大输出,适合生成完整文档💡 最佳实践:设置合理的max_completion_tokens有双重好处——既能防止模型"过度输出"烧Token,也能防止模型回答到一半被截断。
2.5 stop:告诉模型"到这里停"
参数:stop类型:string 或 array of strings默认值:null含义:当模型生成的文本中出现这些字符串时,立即停止生成。最多可设置 4 个停止序列。典型用法:
# 单个停止词stop="END"# 多个停止词stop=["\n\n\n", "END", "###"]# 对话中让AI只回复一轮stop=["\nUser:", "\nHuman:"]实战场景:
场景1:结构化输出(不用JSON模式时) stop=["```"] → 防止代码块标记,确保内容干净场景2:单轮Q&A stop=["\nQ:", "\n问:"] → 防止AI模拟下一轮对话场景3:限制长篇输出 stop=["总结", "综上所述"] → AI说出这些词就停2.6 presence_penalty & frequency_penalty:抵制重复
这是最容易搞混的两个参数。
参数:presence_penalty类型:float,范围 [-2.0, 2.0]默认值:0含义:根据token是否已出现过来施加惩罚。惩罚力度与"是否出现过"有关, 与"出现了多少次"无关。正值鼓励模型谈新话题,负值允许模型围绕同一话题。参数:frequency_penalty类型:float,范围 [-2.0, 2.0]默认值:0含义:根据token出现的频率来施加惩罚。出现次数越多,惩罚越重。 正值降低逐字重复,负值允许高频复用同一表述。一句话区分:
presence_penalty → "这个词说过没?说过就罚。"(管话题多样性)frequency_penalty → "这个词说了几次?按次数罚。"(管用词多样性)直观对比:
| 场景 | presence_penalty | frequency_penalty |
|---|---|---|
推荐配置:
创意写作 / 头脑风暴(希望内容丰富多样): presence_penalty=0.3, frequency_penalty=0.3代码生成(公式化重复是正常的): presence_penalty=0, frequency_penalty=0长篇文档(希望避免词汇重复): presence_penalty=0.1, frequency_penalty=0.2严格问答(重复术语可以接受): presence_penalty=0, frequency_penalty=0⚠️ 注意:两个参数设为负值会加剧重复——AI可能会"卡住"一直说同一个词。除非你有明确的特殊需求,否则不要设负值。
2.7 seed:让输出可复现
参数:seed类型:int默认值:null含义:指定随机种子,配合temperature固定值,让模型在相同输入下产生近似相同的输出。不是100%精确复现,但在大多数场景下结果高度一致。使用方式:
response = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": "用50字介绍AI"}], temperature=0, seed=42)# 每次调用,输出基本一致💡 关键洞察:seed必须配合temperature=0使用,否则随机采样会覆盖种子的作用。此外,即使设置了seed,跨模型版本的输出可能仍然不同——它不是跨版本的"快照"。
适用场景:
✅ 自动化测试——需要确定性输出做断言✅ A/B实验——控制变量,只对比prompt变化的影响✅ 缓存优化——相同请求返回已缓存的响应❌ 不适用于需要多样性的创意场景2.8 stream:一个字一个字往外蹦
参数:stream类型:boolean默认值:false含义:是否启用流式输出。启用后,模型以SSE形式逐token返回结果,用户体验类似ChatGPT的打字效果。# 流式调用stream = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": "讲个笑话"}], stream=True)for chunk in stream: if chunk.choices[0].delta.content: print(chunk.choices[0].delta.content, end="")| stream=false | stream=true |
|---|---|
2.9 response_format:让AI输出结构化数据
参数:response_format类型:object默认值:{"type": "text"}含义:指定输出格式。支持text(默认)、json_object、json_schema三种模式。三种模式对比:
| 模式 | 用法 | 适用场景 |
|---|---|---|
{"type": "text"} | ||
{"type": "json_object"} | ||
{"type": "json_schema", "json_schema": {...}} |
json_object示例:
response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "你输出一个JSON对象。"}, {"role": "user", "content": "分析这句话的情感:这个产品太棒了!"} ], response_format={"type": "json_object"})# 输出:{"sentiment": "positive", "confidence": 0.95, "keywords": ["产品", "棒"]}# 但字段名不受控制——每次可能不一样json_schema示例(Structured Outputs):
response = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": "分析:这个产品太棒了!"}], response_format={ "type": "json_schema", "json_schema": { "name": "sentiment_analysis", "strict": True, "schema": { "type": "object", "properties": { "sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"]}, "confidence": {"type": "number"}, "reason": {"type": "string"} }, "required": ["sentiment", "confidence", "reason"], "additionalProperties": False } } })# 输出严格按照schema,字段名和类型100%确定💡 关键洞察:如果你需要把AI输出写入数据库或传给下游系统,务必使用json_schema模式。json_object只保证"是合法JSON"但不保证"字段名对"。Structured Outputs的strict模式还保证
additionalProperties: false——不会多出任何你没收到的字段。
2.10 tools & tool_choice:让模型调用函数
参数:tools类型:array of objects默认值:null含义:定义模型可以调用的函数列表。模型会根据对话上下文决定是否调用某个函数。参数:tool_choice类型:string 或 object默认值:"auto"含义:控制模型如何选择工具。"auto"让模型自己决定, "none"禁止调用工具,"required"强制调用工具。 也可以指定必须调用某个特定函数。完整示例:
response = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": "北京今天天气怎么样?"}], tools=[{ "type": "function", "function": { "name": "get_weather", "description": "获取指定城市的实时天气信息", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "城市名称,如'北京'、'上海'" } }, "required": ["city"] } } }], tool_choice="auto")# 模型会返回一个function_call,而不是直接回答# tool_calls[0].function.name = "get_weather"# tool_calls[0].function.arguments = '{"city": "北京"}'tool_choice的四种策略:
| 值 | 行为 | 适用场景 |
|---|---|---|
{"type": "function", "function": {"name": "xxx"}} |
💡 延伸思考:SKILL框架也是用同样的tools机制实现的
如果你用过Claude Code的SKILL系统,会发现它的底层也是通过
tools参数来注册和调度的本质上,SKILL就是被包装成tools的高级函数。只是SKILL多了一层——它除了函数签名,还绑定了references文档、scripts执行脚本等资源。但从模型视角看,它面对的就是一堆注册好的
tools,然后根据tool_choice策略选择调用哪个。理解了OpenAI的
tools参数,你就同时理解了Agent框架和SKILL框架的底层调用机制。
2.11 其他值得了解的参数
参数速查表:n: 类型:int,默认1 含义:一次请求生成多个候选回复,从中挑选logprobs: 类型:boolean,默认false 含义:返回每个输出token的对数概率,用于分析模型"确定程度"top_logprobs: 类型:int,范围[0, 20] 含义:返回每个位置最可能的几个token及其概率parallel_tool_calls: 类型:boolean,默认true 含义:是否允许并行调用多个工具 提示:依赖顺序的工具调用应设为falsestore: 类型:boolean,默认false 含义:是否将输出存储到OpenAI平台(用于后续查阅)metadata: 类型:map 含义:给请求打标签,最多16个键值对,用于追踪和分析reasoning_effort(o系列模型专用): 类型:string,"low"/"medium"/"high" 默认:"medium" 含义:控制推理模型思考的深度。high质量最高但时间最长modalities: 类型:array,["text"] 或 ["text", "audio"] 含义:输出模态,gpt-4o-audio等模型支持语音输出prediction: 类型:object 含义:Predicted Outputs——预填已知输出内容,降低延迟 典型场景:只修改一个小文件,其余不变三、多轮交互实战演示:从"查天气"到理解完整调用链
前面讲了很多"参数是什么",但只看单个请求很难理解这些参数怎么配合工作。下面用一个完整的查天气多轮对话,把 tools、tool_choice、messages 和 stream 串起来,让你看清每一次 API 调用的参数怎么变、messages 怎么累积。
3.1 整体流程一览
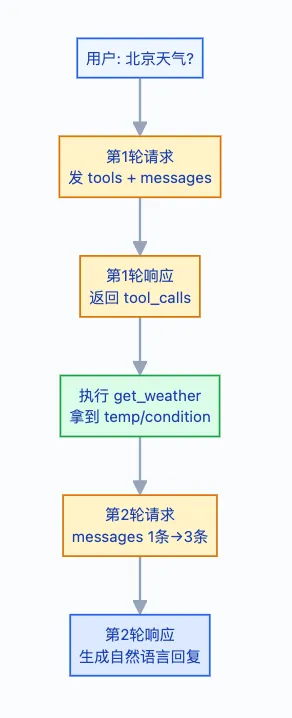
3.2 逐轮代码实现
第1轮:用户提问,模型决定调函数
from openai import OpenAIclient = OpenAI()# 准备函数定义tools = [{ "type": "function", "function": { "name": "get_weather", "description": "获取指定城市的实时天气", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "城市名称" } }, "required": ["city"] } }}]# 初始化 messages(只有用户问题)messages = [ {"role": "user", "content": "北京今天天气怎么样?"}]# 第1轮请求response = client.chat.completions.create( model="gpt-4o", messages=messages, # 只有1条user消息 tools=tools, # 告诉模型:你能调这个函数 tool_choice="auto", # 模型自己决定调不调 temperature=0 # 工具调用场景建议用0)# 关键:查看 finish_reasonprint(response.choices[0].finish_reason)# → "tool_calls" ← 不是"stop"!模型要调函数,没直接回答msg = response.choices[0].messageprint(msg.tool_calls[0].function.name)# → "get_weather"print(msg.tool_calls[0].function.arguments)# → '{"city": "北京"}'中间步骤:你的代码执行真实函数
import json# 将 assistant 回复加入 messagesmessages.append(msg.model_dump())# 执行函数(这里模拟,实际可能调天气API)def get_weather(city): # 实际项目这里调真实API return json.dumps({ "city": city, "temp": 28, "condition": "晴", "humidity": "45%", "wind": "东北风3级" }, ensure_ascii=False)result = get_weather("北京")# 将函数执行结果也加入 messagesmessages.append({ "role": "tool", "tool_call_id": msg.tool_calls[0].id, # 必须对应! "content": result})# 此时 messages 变成了3条:# [user] → [assistant(tool_calls)] → [tool(result)]第2轮:模型基于真实数据回答
# 第2轮请求(参数和第一轮基本一致,但 messages 多了2条)response2 = client.chat.completions.create( model="gpt-4o", messages=messages, # 现在是3条消息了 tools=tools, # 依然要带tools tool_choice="auto", temperature=0.7 # 回答阶段可以适当提高)print(response2.choices[0].finish_reason)# → "stop" ← 这次模型直接回答问题print(response2.choices[0].message.content)# → "北京今天天气不错!晴天,气温28°C,湿度45%,# 东北风3级。适合出门活动,注意防晒哦。"# 最终对话也加入 messages,可以继续多轮messages.append(response2.choices[0].message.model_dump())3.3 messages 的演化过程
多轮对话的核心就是 messages 数组逐步累积。每一轮你都要把完整历史发回给模型:
messages 数组演化(4轮请求 = 4次API调用):第1轮请求时的messages(1条): ┌─────────────────────────────────────┐ │ [0] role: "user" │ │ content: "北京今天天气怎么样?" │ └─────────────────────────────────────┘第1轮响应:assistant返回tool_calls(不加入messages不发下次)第2轮请求时的messages(3条): ┌─────────────────────────────────────┐ │ [0] role: "user" │ │ content: "北京今天天气怎么样?" │ │ [1] role: "assistant" ← 新增 │ │ tool_calls: [{get_weather...}] │ │ [2] role: "tool" ← 新增 │ │ content: '{"temp":28,...}' │ └─────────────────────────────────────┘第2轮响应:assistant返回自然语言content继续提问"那上海呢?"时的messages(5条): ┌─────────────────────────────────────┐ │ [0] user: "北京今天天气怎么样?" │ │ [1] assistant: tool_calls[...] │ │ [2] tool: '{"temp":28,...}' │ │ [3] assistant: "北京今天晴天..." ← 新增 │ │ [4] user: "那上海呢?" ← 新增 │ └─────────────────────────────────────┘每次API调用都带上全部历史——模型不记得上一轮说了什么!💡 关键洞察:messages 数组就是你的"对话内存"。每次 API 调用都要把所有历史拼接好发过去——模型本身是无状态的,不会记住上一轮对话。这也是为什么长对话 token 消耗越来越大的根本原因。
⚠️ 三点很容易踩的坑:
- tool 消息的
tool_call_id必须和 assistant 消息里的id对上,否则 API 直接报错 - 第2轮请求仍然要带
tools参数,否则模型不知道还能继续调函数 messages里 assistant 有了tool_calls就必须跟一条tool消息,否则 API 会拒绝——它认为对话不完整
3.4 流式模式的多轮调用
如果开启 stream=True,处理方式略有不同——需要手动拼接 tool_calls:
# 流式模式下,tool_calls 是分片段返回的stream = client.chat.completions.create( model="gpt-4o", messages=messages, tools=tools, tool_choice="auto", stream=True # 开启流式)# 需要手动收集碎片collected_tool_calls = {}for chunk in stream: delta = chunk.choices[0].delta # 工具调用片段需要逐片拼接 if delta.tool_calls: for tc in delta.tool_calls: idx = tc.index if idx not in collected_tool_calls: collected_tool_calls[idx] = { "id": tc.id or "", "function": {"name": "", "arguments": ""} } if tc.id: collected_tool_calls[idx]["id"] = tc.id if tc.function.name: collected_tool_calls[idx]["function"]["name"] += tc.function.name if tc.function.arguments: collected_tool_calls[idx]["function"]["arguments"] += tc.function.arguments# 拼接完成后,后续多轮逻辑和非流式一样四、场景化参数预设
💡 理论归理论,实际使用时"该设什么值"比"参数什么意思"更重要。以下是5个高频场景的参数预设,直接复制用:
代码生成 & 数学推理
{ "model": "o4-mini", # 或 gpt-4o "temperature": 0.1, "top_p": 1.0, "max_completion_tokens": 4096, "seed": 42, "frequency_penalty": 0, "presence_penalty": 0, "reasoning_effort": "high" # o系列专用}创意写作 & 头脑风暴
{ "model": "gpt-4o", "temperature": 0.9, "top_p": 1.0, "max_completion_tokens": 2048, "presence_penalty": 0.3, "frequency_penalty": 0.3}结构化数据提取
{ "model": "gpt-4o-mini", # 提取任务用小模型就够 "temperature": 0, "top_p": 1.0, "max_completion_tokens": 1024, "response_format": { "type": "json_schema", "json_schema": { "name": "extraction", "strict": True, "schema": { ... } # 你的输出结构 } }}对话 & 客服
{ "model": "gpt-4o-mini", "temperature": 0.7, "top_p": 0.9, "max_completion_tokens": 512, "presence_penalty": 0.1, "frequency_penalty": 0.1}Agent / 函数调用
{ "model": "gpt-4o", "temperature": 0, "top_p": 1.0, "tools": [...], "tool_choice": "auto", "parallel_tool_calls": True, # 无依赖时可并行 "stream": True # Agent场景建议流式}五、最常见配置误区 Top 5
误区1:temperature + top_p 一起调
错误做法: temperature=0.7, top_p=0.8 ← 两个采样策略互相干扰正确做法: temperature=0.7, top_p=1.0 ← 只用temperature控制 或 temperature=1.0, top_p=0.8 ← 只用top_p控制原因:两者同时施加会过度限制候选词,输出容易质量平庸。误区2:temperature=0 = 确定输出
错误认知: temperature=0 就能保证相同prompt永远得到相同结果实际情况: 浮点运算的微小差异可能导致不同请求间结果不完全一致。 如需高度可复现:temperature=0 + seed=固定值误区3:presence_penalty 和 frequency_penalty 同时提高
错误做法: presence_penalty=1.5, frequency_penalty=1.5 ← 双高组合后果: 模型几乎不敢使用任何已出现的词,输出可能语法混乱甚至无意义正确做法: 两个参数建议不超过0.5,通常从0.1~0.3开始尝试误区4:只设max_tokens不管模型上限
错误做法: max_tokens=100000 ← 超出模型上限,请求直接失败正确做法: 每个模型有硬上限,设置前查一下: gpt-4o → 最大输出 16384 tokens gpt-4o-mini → 最大输出 16384 tokens o4-mini → 最大输出 100000 tokens误区5:所有场景都用同一个参数
错误做法: 写代码、写文章、做分析全用一套参数(比如全用temperature=0.7)正确做法: 不同任务的参数需求完全不同,参考第四章的场景预设六、总结
核心要点回顾:1. temperature 和 top_p 二选一,不要同时调2. presence_penalty 管"话题多样性",frequency_penalty 管"用词多样性"3. json_schema > json_object,生产环境务必用前者4. temperature=0 不等于"完全确定",配合 seed 才是5. 不同场景用不同参数预设,不要一套参数走天下一张图记住所有参数:
| 参数 | 一句话 | 默认 | 核心作用 |
|---|---|---|---|
掌握了这些参数,你就从"会用API"升级到了"精通API调优"。别忘了收藏这篇文章,下次调参数时打开看看。
如果觉得有帮助,欢迎点赞和在看!
