 夜雨聆风
夜雨聆风
图,Design Crit 研究封面。
一、AI 会画图了,但它会判断好坏吗
事情是这样的。
Contra Labs 发了一篇很有意思的研究,叫 Design Crit。它想解决的问题非常直白,AI 现在已经很会生成设计图了,但它会不会判断一张设计图到底好不好?
这个问题乍一看像玄学。
大家平时聊设计,经常会说一个词,taste,品味。一个人有没有品味,一个设计是不是高级,一张图是不是对,很多时候好像都靠感觉。
但 Contra Labs 这次的态度很硬。
他们说,大家都在聊 taste,可如果一个东西没法测量,你就没法改进它。所以他们真的去测了。
Design Crit,全称 Criteria-Resolved Image Taste,是一个由设计师标注的 AI 图形设计偏好数据集。里面有 10 位专业设计师,对 4 个前沿图像模型生成的设计作品进行盲评,而且不是只问一句「哪张更好」,而是拆成 9 个真实设计工作里会用到的维度逐项评价。
1. 设计不是一句「哪张更好」
这个点其实很关键。
因为现在的文生图模型已经从早期研究 demo,变成了真的生产工具。海报、社媒图、UI mockup、logo,很多东西已经可以直接从模型里出来。但训练和评估这些模型的偏好数据,大多还是从照片式、场景式生成那里来的。
那种场景里,一个总体判断往往够用。
哪张更清晰?哪张更符合 prompt?哪张看起来更像一张正常照片?
但设计不是这样。
一张平面设计图,可能空间结构很对,但颜色意图完全跑偏。另一张图可能满足了 brief,却把字体层级搞崩了。它们都可能得到同一个整体赞成票,但原因完全不同。
真正设计师在判断时用到的信号,就藏在这些单一标签平均掉的维度里。
所以 Contra Labs 做的事情,可以理解成补了一层判断层。
它不是让 AI 再生成一张更漂亮的图,而是想让系统能像设计师一样,分维度说出这张图哪里对、哪里错、哪里只是看起来对。

图,Design Crit 的核心链路,数据集、评测、训练和结论之间的关系。
二、Design Crit 到底怎么做
他们这次把 4 个当前的文生图模型放到一起比较。
分别是 bfl.ai 的 FLUX.2 max,OpenAI 的 ChatGPT Image 1.5,Google DeepMind / Gemini 的 Nano Banana 2,还有 BytePlus 的 Seedream 5.0 Lite。
所有作品在评审面前都隐藏品牌,只用盲码展示,避免设计师因为模型名字产生预设。
10 位专业设计师来自 Contra 的创意专家网络,被分成两组,每组 5 人。
一组负责审美维度,包括整体偏好、情绪和调性、视觉层级、色彩和谐、字体工艺。
另一组负责描述忠实度,包括整体偏好、颜色准确性、空间准确性,以及 brief 要求出现的文字是否真的被正确渲染。
这 9 个标准不是拍脑袋来的。团队先从更长的标准列表出发,通过 pilot study 和设计师访谈收窄维度,同时参考了 Contra Labs 之前的 Human Creativity Benchmark,最后留下那些设计师会稳定区分开的判断轴。

图,Design Crit 的评测样例、模型来源和评价维度。
2. 数据规模和评分方式
具体数据规模是这样的。
9 个标准,每个标准 80 个 prompt。每个 prompt 由 5 位设计师对 4 个模型生成结果进行评分。每个标准一共 1600 条评分。
设计师还会完成每个 prompt 下 4 个模型之间的 6 组两两比较,然后研究团队把这些 pairwise comparison 聚合成严格的四模型排序。
在两个整体偏好轨道上,设计师还会给每张图标注是否有幻觉。
这些评价来自真正工作的专业设计师,补的是当前模型训练和评估里大家一直在盲飞的那一层。
三、设计判断是玄学吗
说到这里,一个很自然的问题会冒出来。
设计不是主观的吗?设计师之间真的有一致性吗?如果每个人都只是凭个人喜好投票,那这个数据还有什么可学的?
Contra Labs 直接测了这件事。他们检查设计师之间的一致性是否高于随机评审,并且对照精确的零分布。
结果是,有信号。
设计师对好设计的共识,大概类似人们对最喜欢哪部电影的共识。比大家判断哪张照片更清晰要弱,但不是一盘散沙。
而且这种分歧是健康的。
大家共享一个粗略的「好」的方向,上面叠加个人差异。并没有出现两个品味阵营,彼此完全对着干。
这恰好是模型可以学习的模式。
不过,不同维度上的一致性差别很大。
越能和 brief 对照的维度,一致性越高。比如要求的文字有没有被正确渲染,版式空间是否准确,颜色是不是按要求出现。
越接近纯感受的维度,一致性越低。色彩和谐是最低的那个。
最清楚的是成对比较。
设计师们在「文字有没有正确出现」这件事上的一致性,远高于「字体排得好不好」。他们在「要求的颜色有没有出现」上的一致性,也高于「这些颜色放在一起是否和谐」。
同一个主题,能检查的版本一致性高,靠感觉的版本一致性低。
这挺真实的。
设计不是没有信号,只是越靠近 taste,噪声越大。
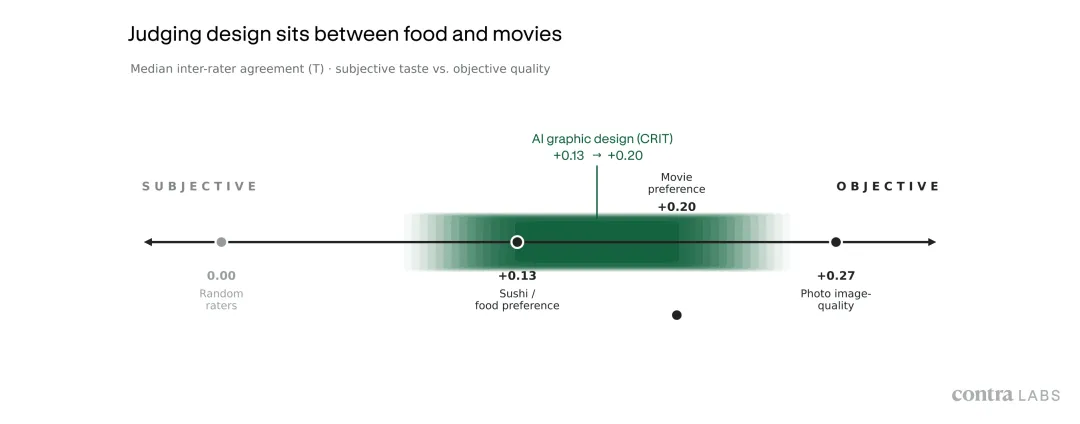
图,设计判断并不等于纯主观偏好,也不等于简单客观质量。
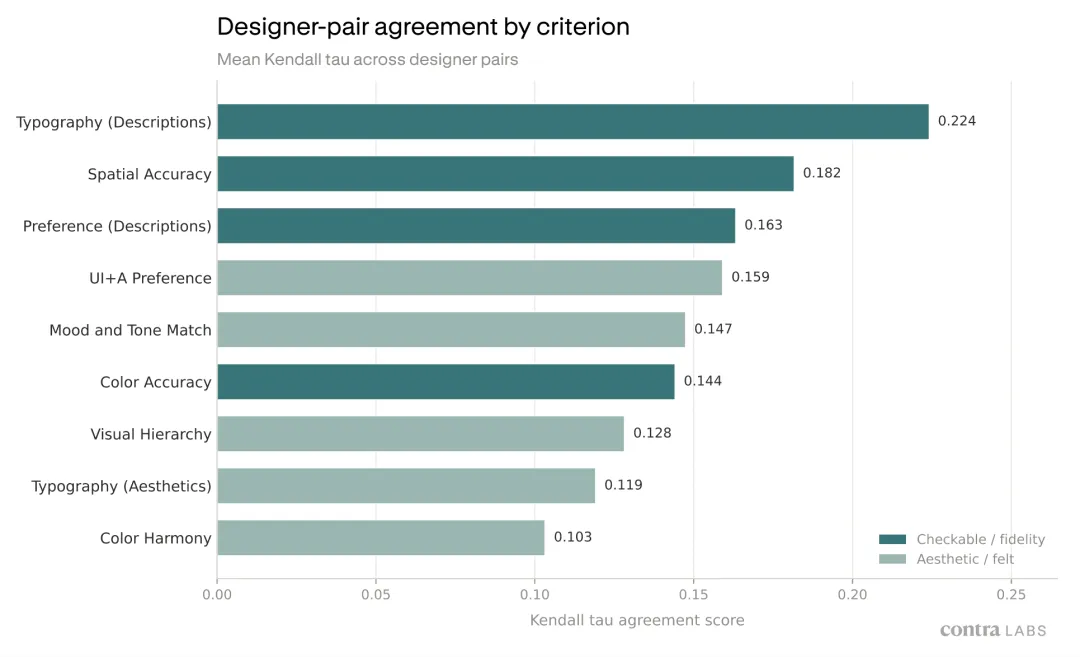
图,不同标准上,设计师之间的一致性差别很大。
四、现在的 AI judge 表现如何
然后问题来了。
既然信号存在,那现在市场上的 AI judge 能不能读出来?
他们测了 9 个预训练系统。里面有 3 个专门的偏好和审美评分器,HPSv 2.1、PickScore-v 1、LAION-Aesthetic-V 2。还有 6 个开源权重视觉语言模型,被 prompt 成二选一评审,让它们判断哪张图更好。
结果有点尴尬。
没有一个系统和 5 位设计师多数意见的一致率超过 55%。
随机猜是 50%。表现最好的 HPSv 2.1,训练时用过超过 64 万组人类图像比较,最后也只有 54.3%。LAION-Aesthetic-V 2 甚至低于随机。
人类设计师和设计师小组多数意见的一致率是 74.1%。
所有机器评审,都卡在比抛硬币好一点点的死区里。
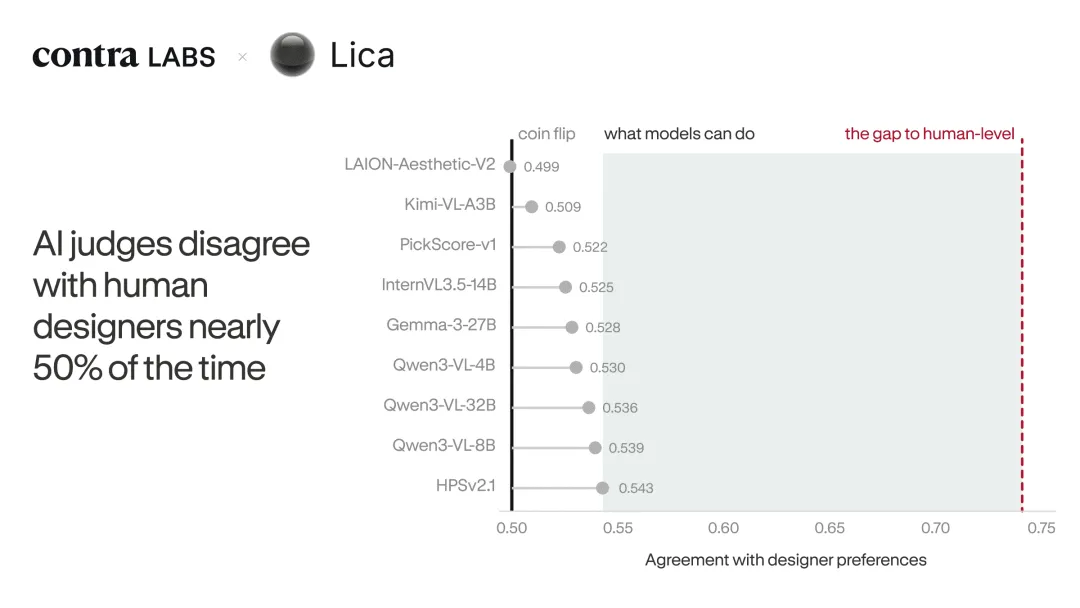
图,现有 AI judge 与人类设计师多数意见之间仍有明显差距。
3. 更大的模型,也没有自动变懂设计
更扎心的是,规模也没救。
他们测了 Qwen 3-VL 的 4 B、8 B、32 B,结果都在 51% 到 54% 之间。
原因不是大模型完全没变化,而是变化被抵消了。
更大的模型位置偏差更少。也就是说,你把两张图左右顺序换一下,它的选择不太会变,所以它更稳定。
但这种稳定没有带来准确率。它真正做出判断时,并没有更接近设计师,甚至略差一点。
小模型更容易受位置影响,但在它不受位置影响、真正做出选择的那些 case 上,反而更锐利。
研究里还有一个很有意思的相关性,模型越依赖位置偏差,在它不依赖位置时判断反而越好,Spearman ρ 等于 +0.94。两个效果互相抵消,整体表现就一直上不去。
瓶颈不是算力,是数据。
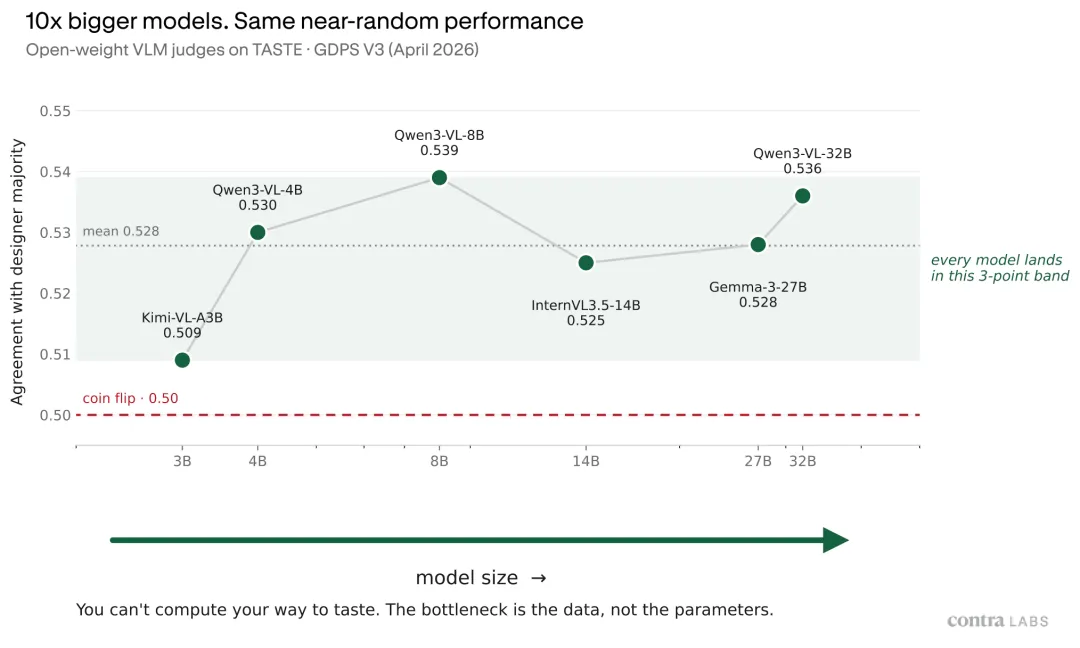
图,模型规模变大,并没有自动带来更好的设计判断。
五、生成模型自己看不见的问题
他们还发现了另一个问题,生成模型会在设计里产生幻觉。
设计师在排序时,同时会给整体偏好轨道上的每张图标记是否有 hallucination,也就是出现了 brief 没要求的元素,或者和任务无关的漂移。
在每组 1600 个标记里,大约 55% 是干净的,35% 是轻微幻觉,10% 是严重幻觉。
也就是说,每 10 张完成设计里,就有 1 张带着重大幻觉。
它可能多了一个 prompt 从没要求的元素,可能文字乱了,可能某个视觉对象跑偏了。
这些东西设计师一眼就能看出来,但生成它的模型自己看不见。
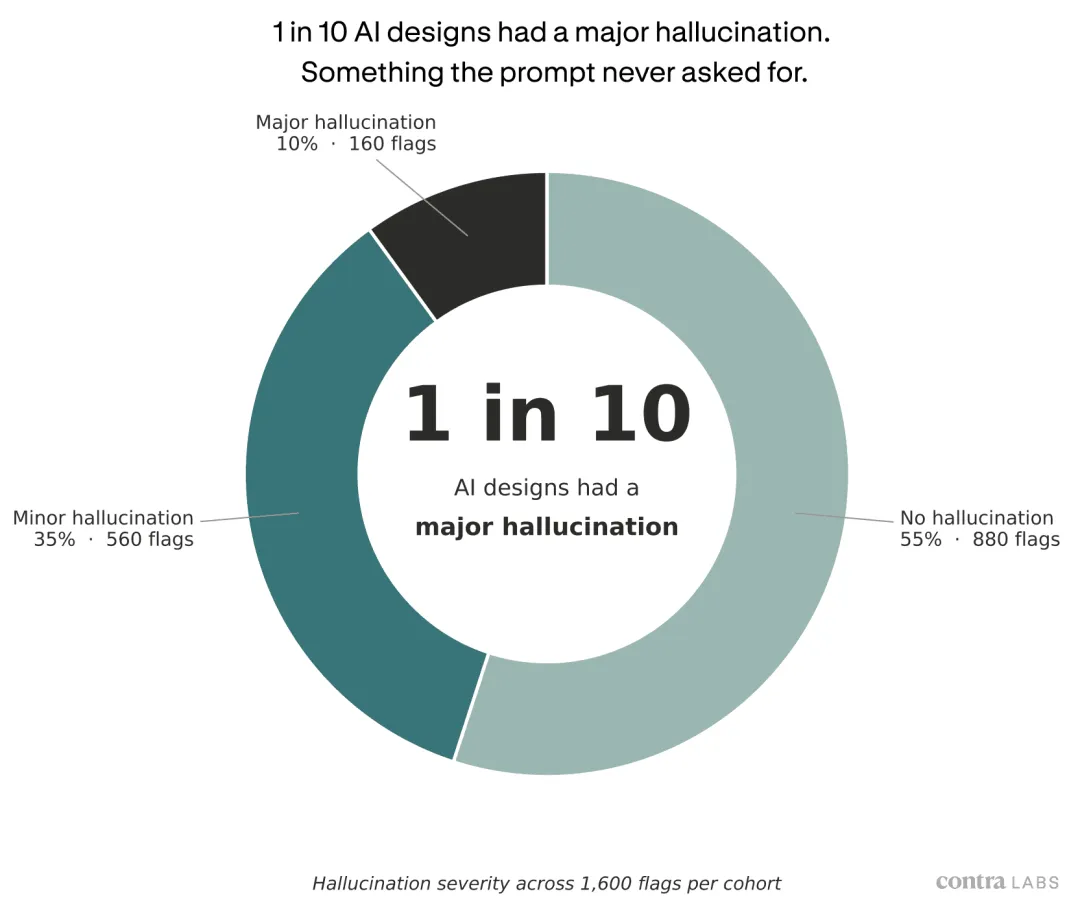
图,AI 生成设计中的幻觉比例。
六、真正的转折,taste 可以被学习
不过这篇研究不是只在吐槽。
真正的转折在后面。
他们训练了一个很小的 pairwise-difference head,放在冻结的视觉语言编码器上。没有微调 backbone,模型故意做得很克制,直接用 Design Crit 数据训练。
结果达到了 0.611 的设计师一致率。
这个数字补上了从随机 0.500 到人类上限 0.741 之间大约 46% 的差距,也是他们 sweep 里第一个越过标准正则化无法推动的噪声地板的配置。
这和前面的 benchmark 形成了反向证明。
信号一直都在。
只是它不能从照片偏好数据里借来,必须从真正的设计判断数据里学。
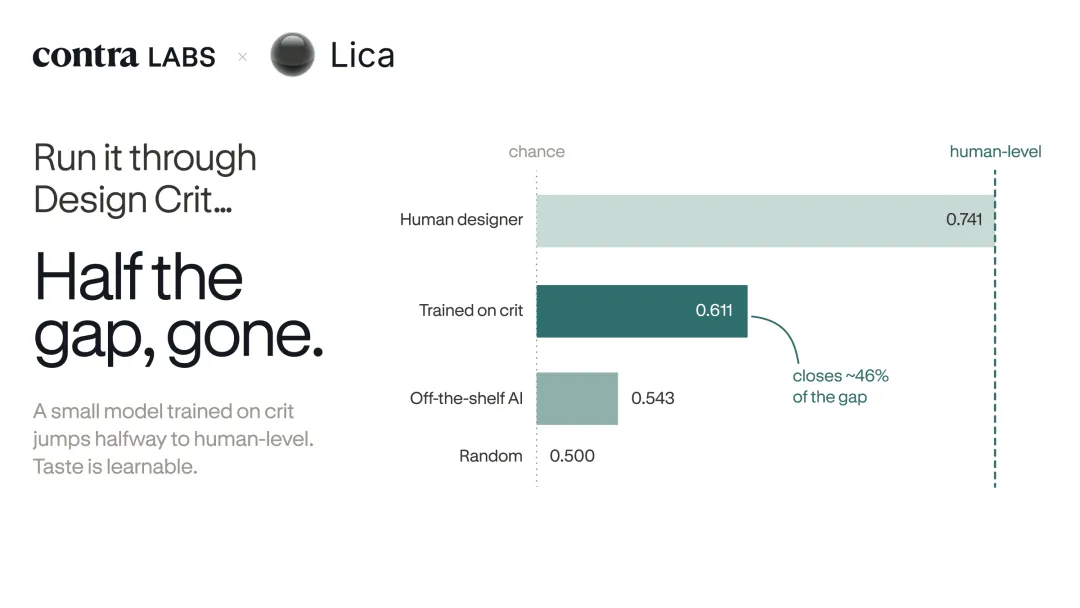
图,用 Design Crit 数据训练后,模型补上了从随机到人类上限之间约一半差距。
4. 最难的样本上,模型反而接近人类
更有意思的是困难样本。
大约一半的 pairwise comparison 是 3 比 2 的分裂,也就是 5 位设计师里 3 个选 A,2 个选 B。这种情况本来就很难,因为设计师自己都接近五五开。哪怕是完美预测器,也有一部分是在猜。
恰恰在这些真正考验判断力的 case 上,用 Design Crit 训练出来的模型拿到了 0.602,而人类上限是 0.600。
当设计师小组分裂成 3 比 2,一个单独设计师和多数意见一致的概率也不过是五次里三次。模型现在已经接近这个水平。
当然,在设计师觉得容易的 case 上,模型和人类之间还有明显差距。但在最难的那些 case 上,差距几乎没了。
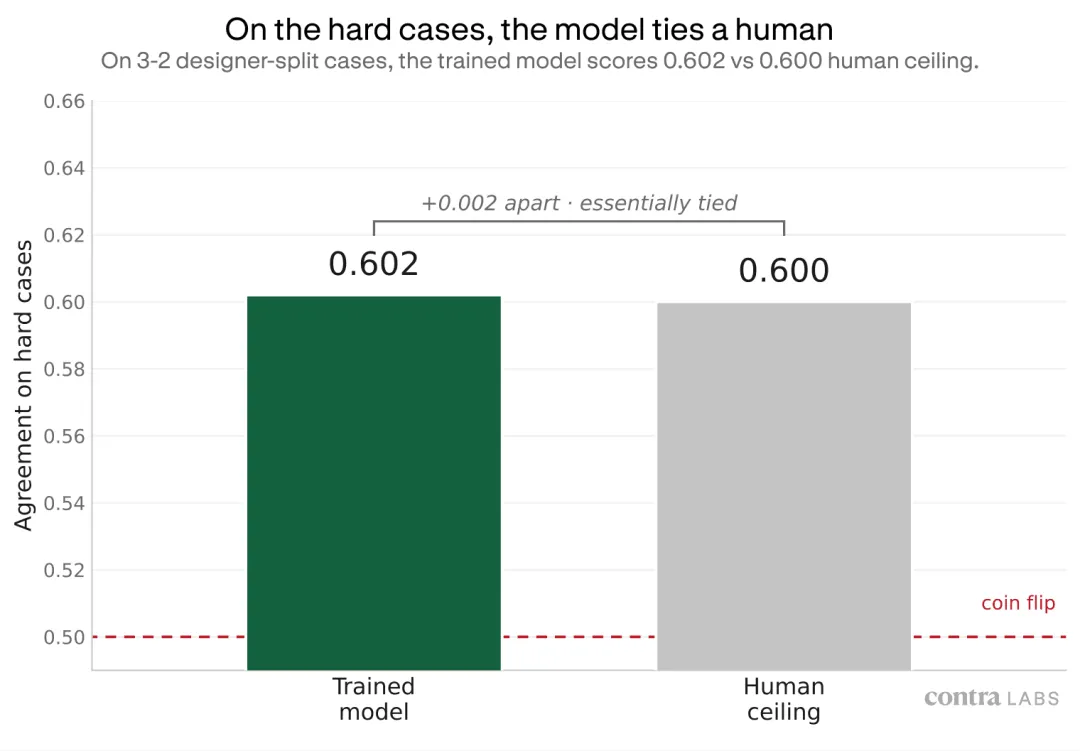
图,在 3 比 2 分裂的困难样本上,模型已经接近单个设计师的人类上限。
七、为什么这件事重要
所以这件事为什么重要?
Design Crit 可以用来给设计生成系统做一个决策层。
因为它是按 criterion 拆开的,所以你可以按任务需要在不同生成模型之间路由。做 logo,就选字体能力更强的模型。做版式,就选空间准确性更强的模型。做品牌氛围图,就更看重 mood、tone 和色彩。
这比相信一个模糊的总分要靠谱很多。
同样的结构,也可以作为训练偏好 judge 和 reward model 的监督信号,让它们优化特定设计维度,而不是优化一个糊成一团的平均分。
原文最狠的一句话,其实就是这句。
AI 可以生成设计,但它还不能可靠地区分好设计和坏设计。而且光靠扩大模型规模,不会自动解决这个问题。
但比较乐观的发现是,那个缺失的信号,也就是 taste,并不是不可学的玄学。它是真实存在的,可以从专家数据里学出来。
Contra Labs 说,这就是他们的网络要提供的那一层,由创意人,为创意 AI 提供的那一层。
这项工作是 world lica 和 Contra Labs 的合作,第一份 Design Crit 数据集 TASTE 已发布在 arXiv,编号 2605.20731。

图,原线程附带动图,已转成 GIF 并转存。
八、我的一点判断
说实话,我觉得这篇最有价值的地方,不是它证明了「AI 可以学会品味」。
这个结论太容易被误读了。
很多人看到这里,可能会下意识觉得,完了,设计师最后一块护城河也要被数据化了。
但我自己的感受刚好相反。
它真正证明的是,设计判断不是一句「好看」能概括的东西。
过去很多 AI 图像评估的问题,就是把复杂的设计判断压成了一个单点偏好。最后模型学到的,往往是更亮、更清晰、更像爆款图、更像训练集里人类点赞的图。
这不是设计。
设计更像一组互相牵制的取舍。
字体要稳,但不能死。颜色要准,但不能脏。空间要对,但不能僵。brief 要满足,但不能只是机械执行。情绪要出来,但不能把信息压没。
这些东西全塞进一个总分里,当然会失真。
所以 Design Crit 的意义,反而是在提醒我们,别再用一个「好不好看」糊弄设计了。
如果未来 AI 真的要进入生产级设计流程,最先成熟的可能不是「一个全能模型直接给你完美稿」,而是一套更像设计总监的系统。
它知道这个任务更看重什么。
它知道这张图字体不行,但色彩可以保留。
它知道这个模型适合做 moodboard,那个模型适合做排版,另一个模型更适合按 brief 还原文字。
它甚至能把反馈拆成可执行的修改意见,而不是只说「再高级一点」。
这才是我觉得真正有用的方向。
九、这项研究的限制
当然,限制也很明显。
原文自己也讲了。
样本还小。每个 prompt 只有 5 位设计师评分,这足够测一致性、排除随机噪声,但还不足以对单个比较做非常确定的判断。
每个标准使用的是各自独立的 80 个 prompt,所以没有同一张设计在多个标准上被同时评价。这样能让每个评分保持干净,但也带来一个问题,我们看不到同一个设计师在同一张图上如何权衡颜色和字体,因为没人对同一张图同时评这两个维度。
所有 prompt 都是英文,所以跨语言 taste 没有被覆盖。
9 个标准覆盖了很多东西,但还不完整。可访问性、品牌一致性、动效、受众匹配,都应该是后续可以加入的自然维度。
十、下一步会走向哪里
未来研究也很清楚。
下一步应该扩大规模,让每个 prompt 有更多设计师,加入更多语言,扩展评价标准。
如果同一批设计能在所有维度上被评价,就能看到设计师如何在颜色和层级、忠实度和感受之间做权衡,而这些 trade-off 正是单一分数会隐藏掉的东西。
目前他们只是证明了这个信号可以被学成一个 judge。还没有回答另一个更重要的问题,它能不能让生成模型真的变成更好的设计师。
如果未来用这些分维度 reward 去训练生成器,直接推动字体、颜色或版式能力,再看最终作品是否真的变好,那才是下一场更有意思的实验。
十一、线程里的几个问题
原推下面的几条回复也挺有意思。
有人说,设计原则可以教,设计惯例可以学,但 taste 属于个人。
我觉得这句话很准确,但它和 Design Crit 并不冲突。
taste 当然有个人性。但个人性不等于完全随机。就像音乐、电影、建筑一样,审美判断里永远有共同结构,也永远有私人偏好。Design Crit 学的不是把所有人变成同一种口味,而是先把那些可讨论、可拆解、可反馈的部分捞出来。
也有人问,我不太理解,为什么这是一个需要解决的问题?
这个问题其实问到了核心。
如果 AI 只是拿来玩图,确实不需要解决。你喜欢哪张就用哪张。
但如果 AI 设计要进入生产流程,要替品牌出图,要进广告投放,要进 UI、包装、logo、社媒和商业素材,那判断层就非常重要。
因为生成只是第一步。
真正花时间的是筛选、诊断、修改、对齐。
如果机器只能批量生成,却不能靠谱地告诉你哪张图为什么不行,那设计师只是从「自己画」变成「在垃圾堆里翻金子」。效率提升会被审核成本吃掉一大块。
所以我觉得 Design Crit 这类工作,可能比单纯发一个更会画图的新模型还重要。
它不性感。
没有一键生成大片那么抓眼球。
但它在补生产系统最缺的那块东西。
判断力。
十二、最后真正要补上的,是判断力
大时代啊,朋友们。
以前我们以为 AI 先学会执行,再慢慢学会创造。
现在看,下一步可能是它必须先学会批评。
不然它生成得越快,人类越累。
资料来源:
原文来源,Contra Labs,Introducing Design Crit 原推链接,https://x.com/contralabs_ai/status/2067642363909144932 研究页,https://contralabs.com/research/design-crit 论文,https://arxiv.org/abs/2605.20731
「更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。」
