 夜雨聆风
夜雨聆风Unlimited-OCR:3B 小模型,一次性吃掉 40+ 页 PDF 的长文档 OCR 新范式
一句话版:这不是又一个“能 OCR 的大模型”,而是一个把长文档 OCR 工程问题彻底打通的、真正可以落地的端到端方案。

1. 为什么又需要一个「Unlimited」OCR?
做过长文档知识库、RAG 或文档中台的同学,大概率都踩过这些坑:
每页单独 OCR,后处理重新拼装:段落错序、跨页表格断裂、页眉页脚乱入正文。
多模块管线(检测-识别-版面分析-结构重建):模型越叠越多,调参和容错地狱。
想上端到端 DocVLM,又被长序列的二次注意力、KV Cache 炸显存劝退。
传统 Transformer 自注意力的复杂度是 O(n2)O(n^2)O(n2),序列长度翻倍,时间和显存直接翻四倍,长文档场景基本是「能跑就不错了」,谈不上优雅。 Unlimited-OCR 走的是另一条路:
模型只有 3B 参数(有效激活约 500M)。
用创新的 R-SWA(Reference Sliding Window Attention) 解决长上下文「记不住」的问题。
用 DeepEncoder 做 16× 视觉压缩,从源头上解决长文档图像 token 爆炸。
一次前向就能解析 40+ 页 PDF,而不是“逐页跑 + 离线拼接”。
更关键的是,它在 OmniDocBench v1.6 上拿到 93.92% 的端到端文档理解 SOTA,文本编辑距离降到 0.038,对公式和表格尤其友好。
2. Unlimited-OCR 到底是什么?
官方一句话定位:
迎接单次长时程解析的时代
核心信息(偏工程视角):
模型规模:约 3B 参数,BF16 权重,激活约 500M。
能力范畴:端到端文档解析(文本、表格、公式、布局整体理解)。
上下文长度:官方配置到 32768 token,配合 R-SWA 可以稳定吃下 40+ 页 PDF。
推理形态:
HuggingFace Transformers 本地推理。
SGLang 部署为 OpenAI 风格 Chat Completions API。
开源资源:
GitHub:<https://github.com/baidu/Unlimited-OCR>
所以,你可以把它当成:
一个可直接部署的 长文档 OCR 专用 DocVLM;
也是一个对现有知识库、RAG 系统几乎零侵入即可「升级成长文档一把梭」的组件。
3. R-SWA:把 Sliding Window Attention 用到极致的「人类式抄写」
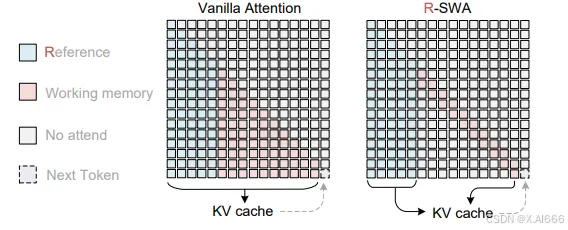
3.1 先复习一下 SWA 在长序列里干了什么
标准自注意力:每个 token 看全局,复杂度 O(n2)O(n^2)O(n2)。 Sliding Window Attention(SWA) 的思路是:
每个 token 只看自己两侧固定窗口大小 www 的邻居。
复杂度变成 O(n⋅w)O(n \cdot w)O(n⋅w):对 n 线性,对 w 线性。
堆多层 SWA 后,有效感受野 ≈ L⋅wL \cdot wL⋅w(L 是层数),可以间接覆盖长距离依赖。
SWA 已经被广泛用在各种长上下文 LLM 里,用来让 KV Cache 从「炸死你」变成「还能用」。 但在文档 OCR 上,单纯 SWA 有两个硬伤:
跨页 / 跨段的远距依赖(比如长公式、跨页表格)容易被切断。
对一些“锚点信息”(页眉、页脚、章节标题)无法做稳定的长程对齐。
3.2 R-SWA 的直觉:像人类一样抄长文档
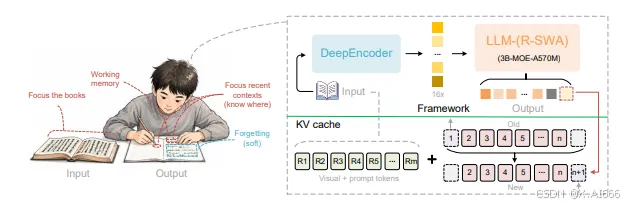
官方的描述很形象:
模型在生成时,只看「原始文本」和「刚刚抄过的几行」,像人一样抄长文档。
可以粗暴理解为:
SWA + 参考通路(Reference) = R-SWA
在具体实现上,它仍然保持局部窗口的线性复杂度,但通过「Reference 路径」给模型一个全局 anchor,例如原始页面特征、历史关键信息等。这样一来:
局部窗口负责当前 token 周围的细节一致性(行内、邻近段落)。
Reference 通路负责跨页、跨段、全局结构的一致性。
工程含义是:
KV Cache 大小和计算复杂度 依然近似线性,不会像全注意力那样炸。
模型不会再出现典型 SWA 的「只记得局部,看不见远处」问题,特别在长 PDF 中,能稳定保持章节 / 表格 / 公式跨页的一致性。
如果你平时玩 LLM 长上下文,R-SWA 可以当成是:
介于「只用 SWA」和「加周期性全局注意」之间的折中;
通过“人类抄写式” reference 机制,在保持结构简单的前提下,实现更强的全局感知。
4. DeepEncoder:先把视觉 token 压到 1/16,再谈长文档
长文档 OCR 的另一个老大难问题,是视觉 token 数量:
一页 300dpi 的 A4 PDF,切成 patch 很容易就是几千甚至上万个视觉 token。
多页拼起来,Transformer 还没开始“理解”,显存已经顶满。
Unlimited-OCR 的做法是加了一个专门为长文档设计的 DeepEncoder,把视觉特征先压一遍,做到大约 16× 的压缩。 这里的关键点是:
不只是简单 pooling,而是结合布局线索,尽量保留:
表格网格线、单元格边界。
公式结构、上下标对齐。
列表层级、缩进、章节结构这些 layout cue。
这样一来,后面的 R-SWA 注意力层面对的是「压缩后的结构 token」,而不是原始高分辨率 patch。
既节省了显存和算力,又不给表格/公式/结构理解挖坑。
从 VLM 设计视角看,这其实是把“Layout-aware Visual Pooling”内置成了一个标准组件。 对工程师来说意味着:你不再需要在上游手搓一堆表格检测、版面分析模块,再想办法 hack 到 LLM 里。
5. 性能:3B 模型打穿端到端文档 SOTA
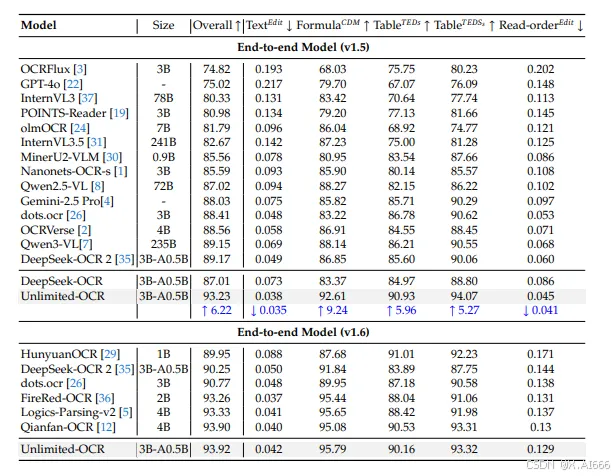
几个硬指标值得单独拎出来说:
模型规模:3B 参数,激活约 500M。
OmniDocBench v1.6:93.92%,端到端文档理解 SOTA。
文本编辑距离:0.038,公式、表格部分改进显著。
推理性能:
在保持接近常数级显存的情况下,比前一代方案快约 35%。
单次前向稳定处理 40+ 页长文档,延迟随页数近似线性增长,而不是二次爆炸。
这些指标对落地的意义:
硬件侧:很多场景可以从“大卡 + 大模型”降级到“中卡 + 3B BF16 模型”,成本立刻可见。
SLA 侧:文档变长只是线性变慢,很容易做扩容策略和队列调度。
质量侧:跨页表格、长公式、附录编号这些过去最容易翻车的地方,端到端模型天然更稳,不需要你写一堆规则硬拼接。
6. 实战上手效果
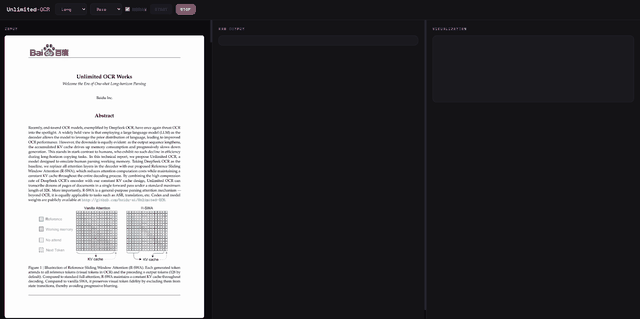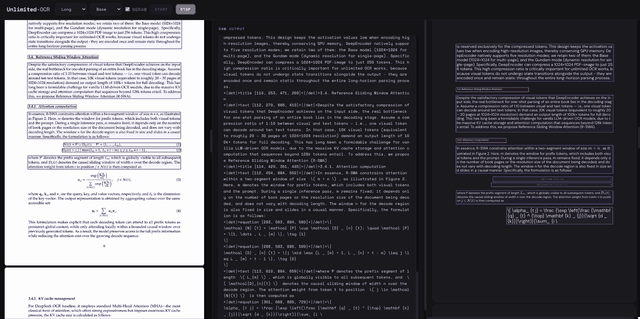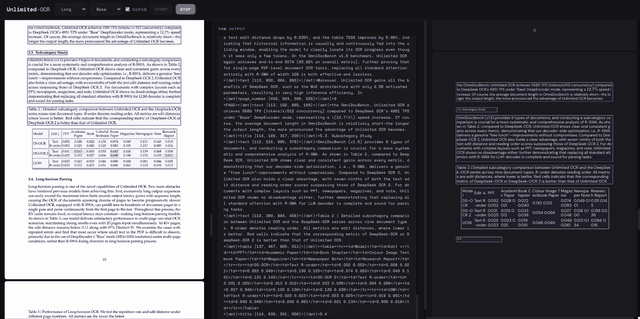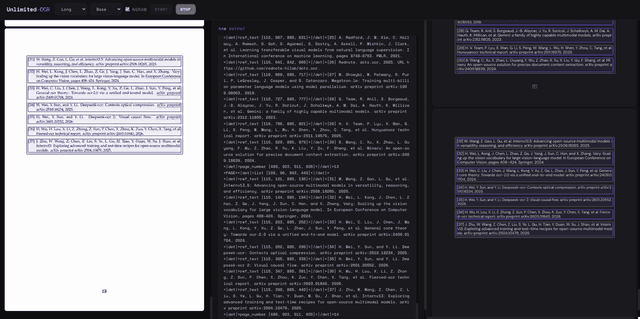
可以看到速度相当快而且是连续解析,实时结果生成
7. 和现有方案怎么配合 / 取代?
7.1 和传统 OCR 管线
适合直接替代的场景:
长报告、年报、招股书、说明书、论文集这类「结构复杂 + 页数多」的文档。
之前靠 PaddleOCR / Tesseract 做检测+识别+版面分析再手搓规则拼表格的项目。
适合共存的场景:
超大规模批量短文档(比如发票、送货单),传统轻量 OCR 仍然成本更低。
对实时性要求极高、单页简单的场景。
7.2 和通用 VLM / LLM
大模型的优势是「多任务 + 多模态 + 复杂推理」,但在专用长文档 OCR上:
通用 VLM 容易「能看懂但抄不准」,结构化输出不稳定,格式经常乱。
Unlimited-OCR 属于对文档场景高度对齐的专用 DocVLM:
DeepEncoder:为文档视觉优化。
R-SWA:为长文档高效注意优化。
解码约束:为文本抄写 / 结构输出优化。
比较自然的架构是:
下游问答 / RAG / Agent:继续用通用 LLM(DeepSeek, Qwen, GPT 等)。
上游文档解析:统一收敛到 Unlimited-OCR,产出结构化文本 / Markdown / 中间 schema。
8. 对工程 / 产品的启发
从 Unlimited-OCR 的设计,可以提炼出几个对我们做系统设计有用的思路:
先把视觉压缩和注意力结构写对,再谈模型规模 3B + 高效结构,能完成很多以前认为需要几十 B 的事情。
长文档不必死磕「全局注意」 通过 R-SWA 这类「参考式」注意力 + 合理的训练范式,完全可以在近似线性复杂度下拿到全局一致的结果。
部署统一用 Chat Completions 是条好路 SGLang + OpenAI 接口,把所有模型变成「兼容 OpenAI」之后,上层只写一次编排逻辑,以后换模型等价于改 environment config。
把文档解析当成一个独立产品能力,而不是 OCR 子模块 Unlimited-OCR 的设计把「长文档端到端解析」提升到和 LLM/RAG 同一个层级,这对很多企业知识中台是一个很重要的观念转变。
如果你觉得这篇文章对你有帮助,也欢迎给我一个三连击:点赞、转发和在看;如果可以,再帮我点一个⭐️。谢谢你看到这里,我们下篇再见。
