 夜雨聆风
夜雨聆风





原力注入 Agent Skill 合集
原力注入 Agent Skill 合集
本项目收录了由“原力注入博主”使用和维护的优秀认知技能。这些技能旨在通过自动化的工作流和多智能体协作机制,帮助开发者深入理解代码库结构、提取核心业务逻辑并生成结构化的技术文档。
相关文章:
给 Claude 写本“标准操作手册”:Agent Skills 实战与深度解析 v2
Agent 设计模式:从理论到工程落地——以 OpenClaw 架构为实证
项目地址:https://github.com/ForceInjection/awesome-skills
1. 核心技能介绍
本章节将详细介绍当前项目中包含的核心技能,包括它们的设计目标、工作原理以及使用方式。
1.1 深度代码阅读
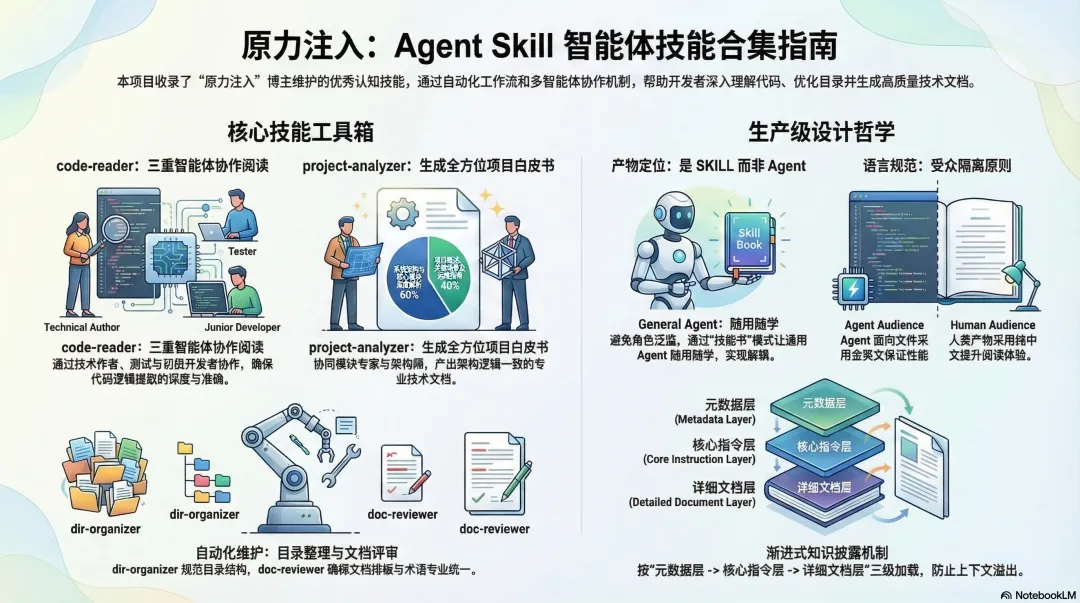
code-reader 技能旨在系统性地阅读和理解陌生的代码库,并通过严格的验证机制生成可复用的认知技能文件。
该技能引入了类似软件工程团队的三重智能体协作模式(技术作者、测试工程师和初级开发者)。通过 QA 工程师生成测试题并由初级开发者仅根据文档进行解答的“闭卷考试”式验证循环,有效避免了浅尝辄止的代码总结,确保所提取的模块能力、设计逻辑、数据结构和状态流等信息具有极高的准确性和深度。
使用示例如下:
# 触发深度代码阅读工作流# 参数 source: 本地路径或 GitHub 仓库地址# 参数 output-dir: 技能文件的输出根目录# 注意:该工作流会在 output-dir 下为每个识别出的模块生成一个独立目录(如 {project-name}-fj-{module-name}),并包含对应的 SKILL.md 等技能文件。/code-reader <source> <output-dir>1.2 深度项目分析
project-analyzer 技能在 code-reader 的基础上进行了扩展,用于对整个代码仓库进行全面的分析,并生成综合性的项目白皮书。
该技能协同了模块专家、运维工程师和首席架构师三个角色的多智能体协作模式。它不仅关注代码级别的逻辑,还深入解析构建、测试和部署等工程实践。通过首席架构师汇总代码逻辑和基础设施配置,确保最终输出的架构图和文档在逻辑上保持一致且专业严谨。最终生成的文档中,根据该技能的设计规范设定,系统架构和核心模块深度解析约占 60% 的篇幅,其余 40% 涵盖项目概述、关键场景和运维指南。
使用示例如下:
# 触发深度项目分析工作流# 参数 source: 本地路径或 GitHub 仓库地址# 参数 output-dir: 白皮书及中间分析文件的输出目录# 注意:该工作流会在 output-dir 下生成以下内容:# 1. 最终输出文件:<actual-project-name>-WHITEPAPER.md(包含 8 个标准章节的综合性白皮书文档)# 2. 中间分析文件(基础设施):由 DevOps 工程师提取生成的构建、测试和部署策略报告# 3. 中间分析文件(代码模块):底层调用的 code-reader 生成的各个模块独立目录(如 {project-name}-fj-{module-name})及包含的 SKILL.md/project-analyzer <source> <output-dir>1.3 目录整理
dir-organizer 技能旨在帮助用户规范化和优化项目目录结构,从而提升工程的可维护性。
该技能支持对目录和文件进行基础及高级操作,如创建、重命名和移动文件。在执行时,它遵循严格的状态收集与方案审核流程,必须先在回复中完整打印出重构计划,并经用户同意后方可执行。此外,整理完成后该技能还会自动扫描并更新内部引用链接,确保文件间关联的准确性。
使用示例如下:
# 触发目录整理技能# 根据用户对话中的上下文或明确指定的路径,执行目录结构优化与文件分类清理。/dir-organizer1.4 文档评审
doc-reviewer 技能用于审查技术文档的准确性、一致性、结构规范和专业性,以确保项目文档的高质量。
该技能通过标准的评审闭环流程,逐项检查目标文档的排版结构(如中英文空格、章节编号)与内容质量(如术语统一、脱敏处理)。在明确指出具体问题和修改建议后,它还支持在用户授权下自动应用修复,极大提升了文档维护的效率。
使用示例如下:
# 触发文档评审技能# 根据用户对话中指定的 Markdown 技术文档路径或文本段落进行审查。/doc-reviewer2. 核心设计理念
本章节概述了上述技能在设计过程中遵循的核心哲学,包括语言规范与产物定位。
2.1 语言规范:受众隔离
为了在保证 AI 推理性能的同时提供良好的用户阅读体验,本项目中的技能严格遵循以下受众隔离的语言规范:
-
• Agent/LLM 面向文件(全英文):所有作为外挂知识库供 Agent 读取的 SKILL.md文件,以及控制工作流的*-prompt.md模板文件,均保持纯英文。这能最大化大模型的指令遵循能力和理解准确度。 -
• 人类面向文件(全中文):最终交付给开发者阅读的产物(如通过 project-analyzer生成的《项目白皮书》),被严格限制为使用纯中文输出,并要求符合专业的技术文档排版规范。
特例说明:中文技能文档:
尽管底层提示词通常建议使用英文,但如 dir-organizer 和 doc-reviewer 等技能的 SKILL.md 采用了全中文编写。这是因为这些技能的核心目标是直接指导开发者制定重构计划或审查中文技术文档规范。采用中文编写能有效降低开发者的理解门槛,同时更精确地传达针对中文语境的排版与组织规则。
2.2 产物定位:为什么是生成 SKILL 而非 Agent?
code-reader 的核心输出是针对每个模块的 SKILL.md,而不是创建专门负责该模块的 Agent。这一设计的巧思在于:
-
• 解耦与轻量化:如果为每个模块生成一个 Agent,会导致角色泛滥且业务逻辑被硬编码在提示词中。生成 SKILL.md则相当于提取了“技能书”。 -
• 按需挂载:开发者只需要让任何一个通用的 Agent(如默认的编程助手)在需要时加载对应模块的 SKILL.md,该 Agent 就能瞬间“学会”该模块的底层逻辑和修改规范。
3. Agent Skill 最佳实践
本章节提炼了构建和维护 AI 智能体技能时的核心规范。以下实践均参考自 给 Claude 写本“标准操作手册”:Agent Skills 实战与深度解析 文档。
3.1 生产级目录结构
合理的目录结构能够有效解耦指令与实现,提升技能的可维护性。
建议将核心指令、执行脚本与参考资料进行分离,标准结构如下:
-
• SKILL.md:核心标准操作手册,文件名必须大写。 -
• scripts/:存放具体执行原子操作的可执行脚本。 -
• references/:存放按需加载的补充参考文档。 -
• assets/:存放各类静态资源。
3.2 精准的触发描述
准确的技能描述是大模型进行逻辑推理和决策触发的关键依据。
SKILL.md 头部 Frontmatter 中的 description 字段是系统判断是否加载该技能的唯一标准。编写时应遵循以下黄金公式:
[功能描述] + [触发场景] + [关键词]
确保描述具体且场景明确,避免使用过于宽泛或模糊的表述。
3.3 渐进式知识披露
渐进式加载机制能够有效避免多个技能同时注册导致的上下文窗口溢出。
系统通常采用三层渐进式的知识加载策略:
-
1. 元数据层(常驻加载):仅加载所有技能的名称与描述,用于大模型建立可用能力的索引。 -
2. 核心指令层(按需加载):当技能被触发时,才将 SKILL.md的正文指令注入当前上下文。 -
3. 详细文档层(引用加载):执行过程中遇到特定需求时,再读取 references/目录下的外部文档。
3.4 状态管理与流程编排
理解技能的状态属性有助于避免多任务执行时的上下文冲突。
-
• 非并发安全:与无状态的函数调用不同,Agent Skills 本质上是动态修改当前的对话上下文。因此它是有状态的,在一段对话线程中建议一次只激活一个技能。 -
• 复杂工作流:技能非常适合作为“指挥官”来编排复杂工作流,例如多工具(MCP)协同、自我迭代纠错以及基于上下文的条件判断。
3.5 技能测试金字塔
系统化的测试是确保技能从可用走向稳定可靠的重要保障。
为了验证技能的健壮性,应建立多维度的评估体系:
-
• 触发测试:包含正向测试(确保目标场景下能被触发)和负向测试(确保无关对话中不被误触发)。 -
• 功能测试:验证技能调用的底层脚本或 API 能否正确返回预期结果。 -
• 性能评估:对比引入技能前后的大模型 Token 消耗情况与交互轮数。
3.6 技能命名规范
规范的命名有助于开发者和系统快速理解技能的用途与角色定位。
推荐使用 名词/执行者(Doer) 形式,而非动词(Action)形式。例如,应使用 agent-skill-reviewer 而不是 agent-skill-review,使用 pdf-translator 而不是 translate-pdf。多个单词之间应使用 kebab-case(短横线)连接。这种命名方式与技能作为“拟人化”智能体角色的定位高度一致。