 夜雨聆风
夜雨聆风





具身智能相关论文开源代码推荐20260321
点击下方卡片,关注【具身智能小站】公众号
📅 2026年3月
👋 大家好!
来了!2026 年新开始的一个系列,主要是整理具身智能领域最近发表的提供开源代码或数据集的项目(论文),希望对相关领域的小伙伴有所帮助。获取这些论文的开源项目链接,可以直接在本文中查看。欢迎转发和关注!!👇
📊 今日数据统计
|
|
|
|---|---|
|
|
|
🤖 开源论文(重点板块)
🔬 RAPiD:面向通用可变形物体移动操作的粒子动力学快速适应
📌 Robot Learning · Deformable Object Manipulation · Mobile Manipulation · Sim-to-Real · Rapid Adaptation
✨ 利用粒子位置捕捉物体形状变化,将快速运动适应方法扩展至可变形物体操作,实现80%以上的真实世界任务成功率
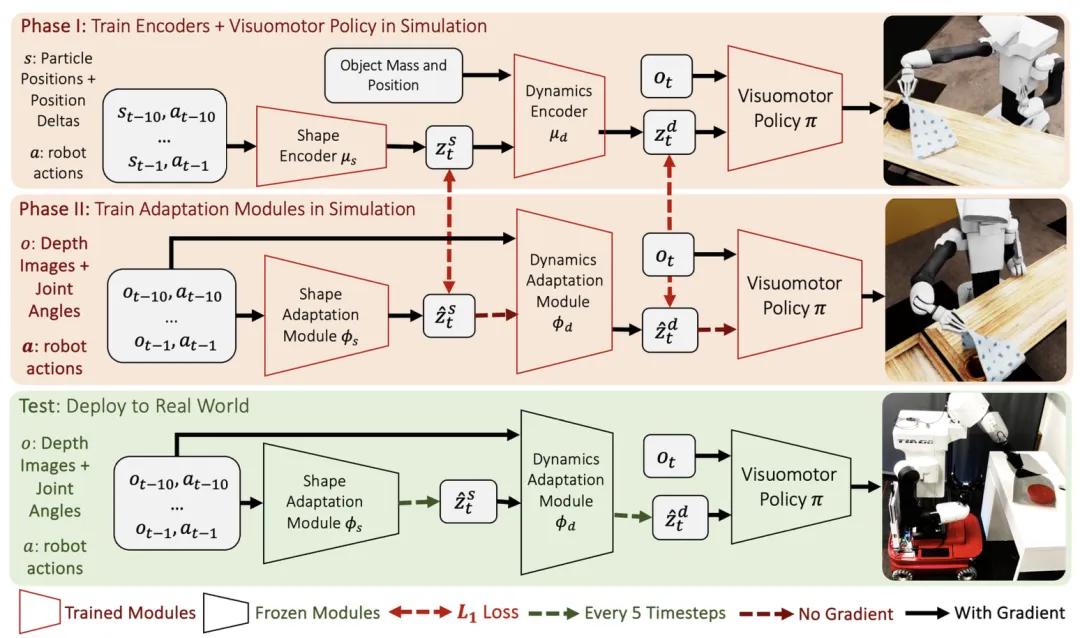
📖可变形物体的动力学参数(如刚度、质量)对其操作策略至关重要,但难以预先获知。本文提出RAPiD,一种两阶段学习方法:首先在仿真中,利用物体的特权信息(如粒子位置、质量)训练一个以动力学嵌入为条件的视觉运动策略;然后,学习一个适应模块,仅使用机器人的视觉观测和动作来推断该嵌入。在22自由度移动机器人上的真实世界实验表明,RAPiD在两个可变形物体操作任务(1D插入和2D覆盖)上,面对未见过的物体动力学、类别和实例,实现了80%以上的成功率。
💡 该方法的核心是将“粒子位置”作为形状变化的表征,从而将快速运动适应框架拓展到可变形物体领域,为学习通用、高效的物体操作策略提供了新路径。
🔗 项目链接:https://sites.google.com/view/rapid-robotics
🔬 ManiDreams:基于不确定性感知任务特定直觉物理的鲁棒物体操作开源库
📌 Robotic Manipulation · Uncertainty-Aware Planning · World Models · Caging Constraints · Open-Source Library
✨ 通过统一的分布性状态表示、后端无关的动力学预测和声明式约束,将感知、参数和结构三种不确定性纳入规划循环,显著提升策略鲁棒性
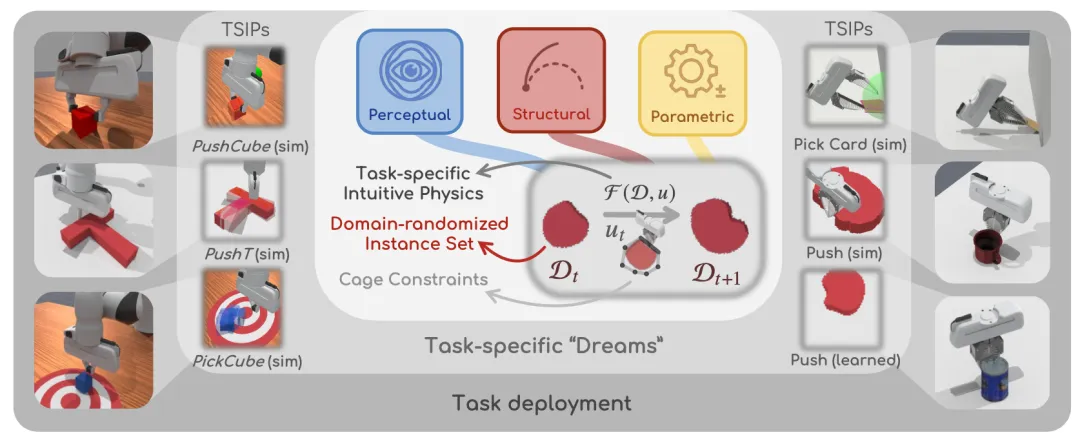
📖 现有动力学模型通常只关注最小化预测误差,而忽视了真实世界操作中固有的不确定性。本文提出并开源了ManiDreams,一个模块化框架,通过三个可组合的抽象层来显式地处理不确定性:分布性状态表示(DRIS)、后端无关的动力学预测(TSIP)和约束优化。该框架将任何基础策略包装在一个“采样-预测-约束”循环中,在无需重新训练的情况下增强了鲁棒性。在ManiSkill任务上的实验表明,ManiDreams在多种扰动下仍能保持稳健性能,而标准强化学习基线则显著退化。
💡 将不确定性作为一等公民进行表示、传播和约束,而非在训练中压制,是实现鲁棒机器人操作的关键。
🔗 项目链接:https://github.com/Rice-RobotPI-Lab/ManiDreams
🔬 MemoAct:受Atkinson-Shiffrin模型启发的记忆增强型机器人操作视觉运动策略
📌 Robotic Manipulation · Imitation Learning · Memory-Augmented Policy · Long-Horizon Tasks · Hierarchical Memory
✨ 通过无损耗短期记忆与压缩长期记忆的协同,同时实现精准任务状态跟踪与鲁棒的长视野信息保持
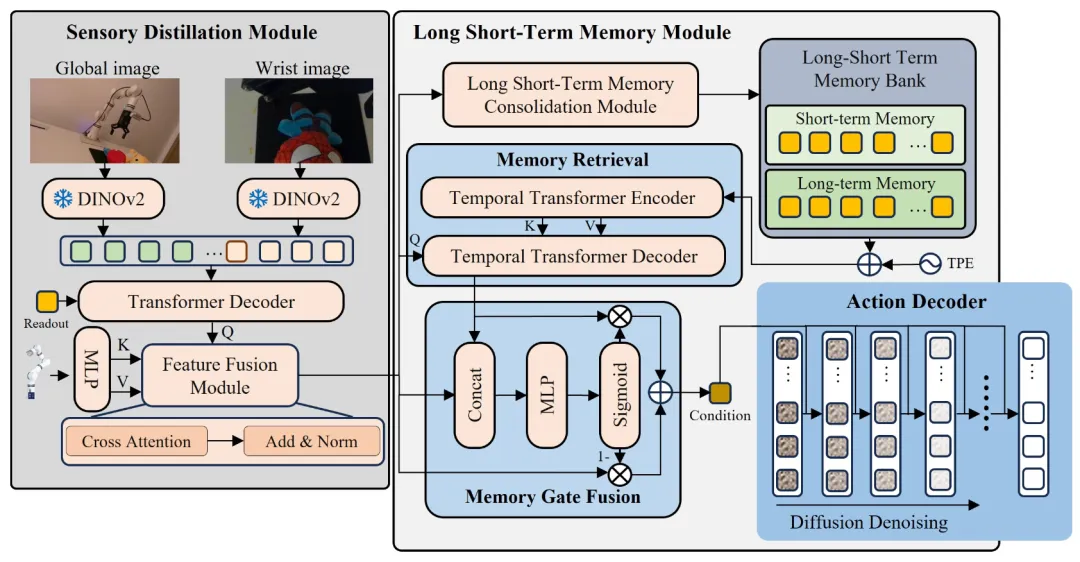
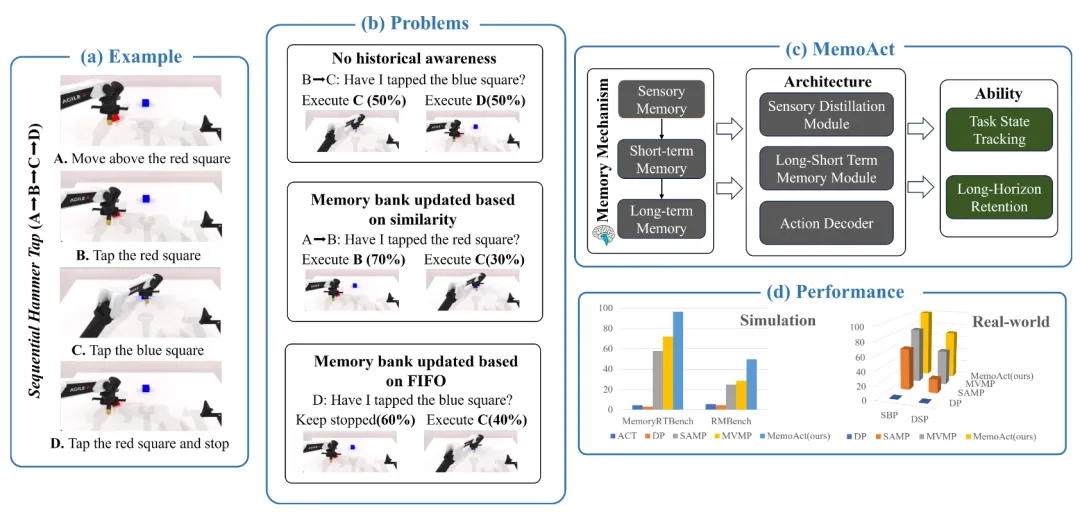
📖 针对现有记忆增强策略在任务状态跟踪和长视野保持上的权衡问题,本文受认知科学中Atkinson-Shiffrin记忆模型启发,提出MemoAct。该策略包含三个模块:感觉蒸馏模块、长短时记忆模块和动作解码器。其中,长短时记忆模块维护一个无损耗的短期记忆库和一个压缩的长期记忆库。在专门构建的MemoryRTBench和RMBench基准测试及真实世界任务中,MemoAct在需要严格顺序执行和初始状态回忆的任务上,显著优于现有的马尔可夫策略和基于历史信息的策略。
💡 模拟人类多级记忆系统,为机器人提供了同时处理近期精确细节和远期背景信息的能力,为攻克长时序、高精度操作任务开辟了新思路。
🔗 项目链接:https://tlf-tlf.github.io/MemoActPage/
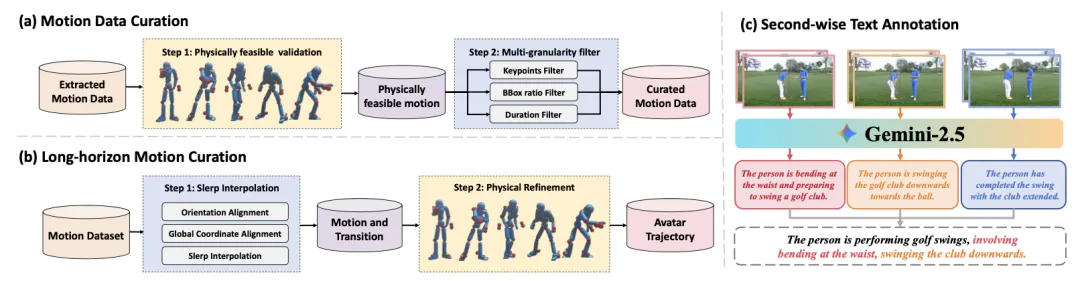
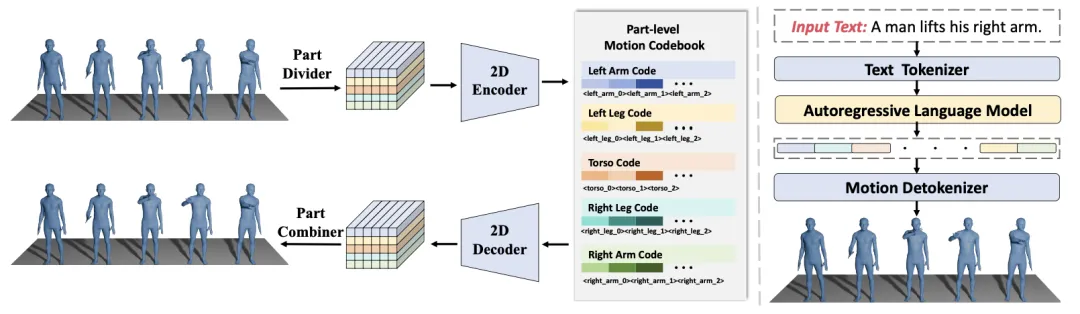
🔬 OpenT2M:百万级高质量开源人体运动数据集与部件级运动标记器
📌 Text-to-Motion · Motion Generation · Large-Scale Dataset · Motion Tokenization · Humanoid Robot
✨ 构建首个百万级、高保真、开源的文本-运动数据集,并引入2D-PRQ部件级运动标记器,显著提升运动生成模型的泛化能力
📖 当前文本生成运动模型泛化能力差,主要受限于现有运动数据集规模小、多样性不足,且存在严重的数据泄露问题。本文推出OpenT2M,一个包含超过2800小时、超过一百万段序列的开源运动数据集。通过物理可行性验证和多粒度过滤保证数据质量,并提供细粒度的文本标注和长序列合成。基于该数据集,本文提出MonoFrill模型,其核心是2D-PRQ运动标记器,通过将人体划分为生物学部件并利用2D卷积捕捉时空依赖,实现卓越的重建和零样本性能。
💡 OpenT2M通过数据质量与规模的突破,揭示了当前模型性能评估中的过拟合问题,并为构建真正的“大运动模型”奠定了数据基础。
🔗 项目链接:https://research.beingbeyond.com/opent2m
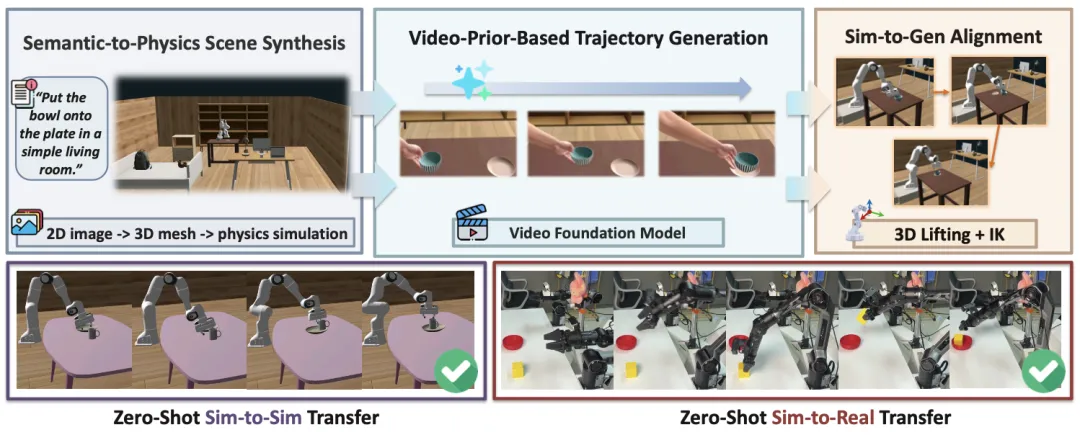
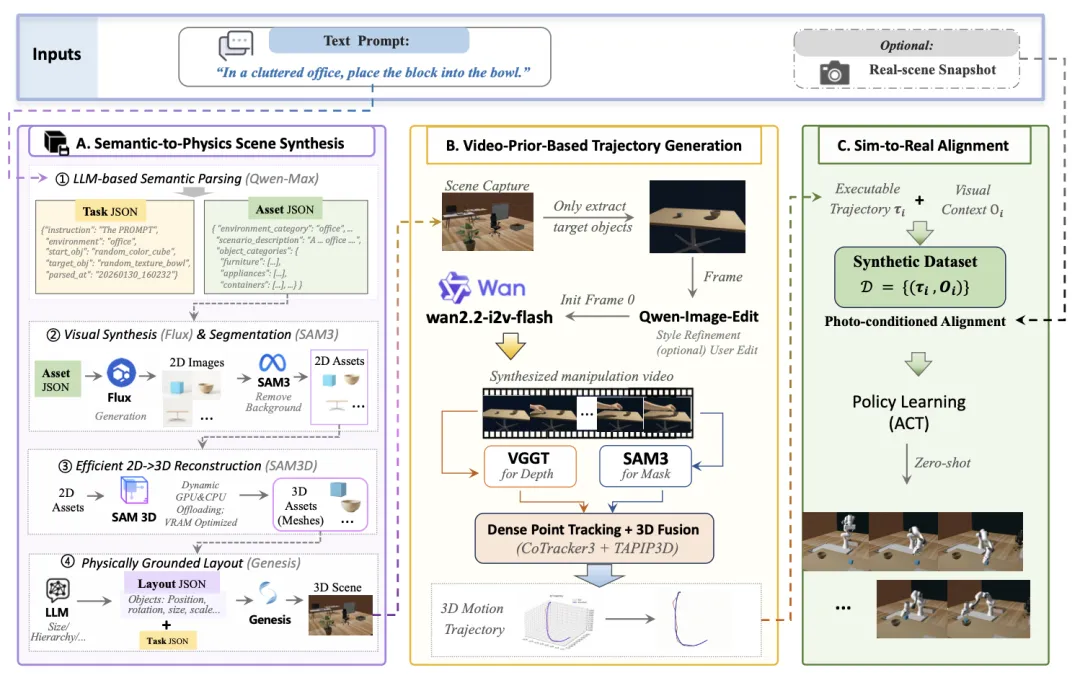
🔬 V-Dreamer:指令驱动的开放式词汇机器人数据合成全自动流水线
📌 Data Synthesis · Robot Learning · Video Generation · Sim-to-Real · Generative AI
✨ 首次实现从自然语言指令到可执行仿真环境和专家轨迹的端到端自动生成,支持从单一合成演示中零样本迁移到真实机器人
📖 训练通用机器人需要海量数据,但真实世界采集成本高昂,现有仿真器受限于固定资产库。本文提出V-Dreamer,一个全自动框架,它利用大语言模型和3D生成模型构建物理合理的3D场景,并创新性地将视频生成模型作为运动先验,通过鲁棒的视觉-运动对齐模块,将生成的视觉运动转化为可执行的机器人轨迹。实验证明,在Piper机械臂上,仅用V-Dreamer合成的单一演示轨迹训练的策略,即可在真实世界中零样本执行推-抓等任务,并对外观和空间扰动表现出一定鲁棒性。
💡 将生成式AI的创造力与物理引擎的确定性相结合,为自动化、规模化生成训练数据提供了全新范式,有望从根本上解决机器人学习的数据瓶颈。
🔗 项目链接:https://jia-handsome.github.io/v-Dreamer/
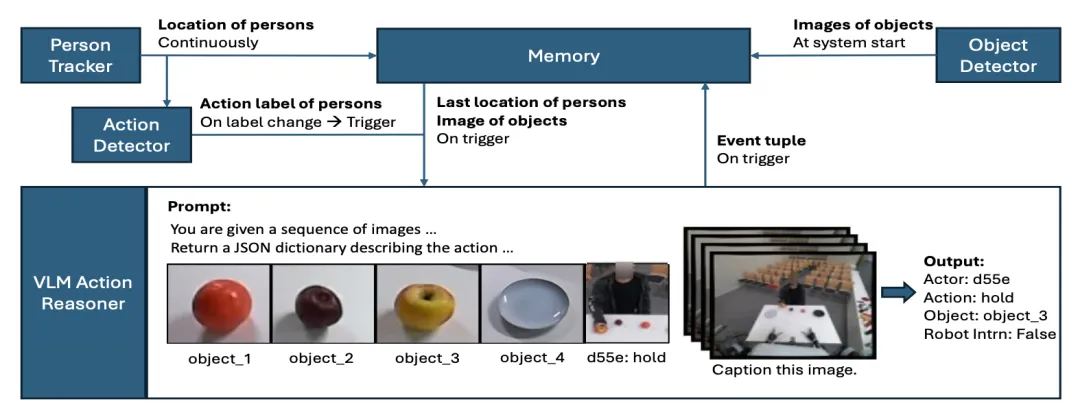
🔬 MERGE:面向人机交互中多参与者事件推理与锚定的引导式视觉-语言模型
📌 Human-Robot Interaction · Vision-Language Models · Situational Grounding · Multi-Actor Reasoning · Event Understanding
✨ 通过轻量级感知模块持续跟踪并选择性调用VLM,将结构化事件元组的生成准确率提升2倍,同时推理速度提升4倍
📖 协作式人机交互中,机器人需要持续跟踪“谁在何时、何地、对何物、做了何事”。然而,现有的VLM难以维护实例级别的身份一致性,且逐帧分析成本高昂。本文提出MERGE系统,通过一个轻量级感知模块持续跟踪人和物体,仅在检测到状态变化时触发VLM进行语义判断,并结合结构化的事件元组生成。为评估该方法,作者发布了GROUND数据集,其中包含多人-人机协作的细粒度交互标注。实验结果表明,MERGE在事件锚定准确率和运行效率上均显著优于GPT-4o、GPT-5等VLM基线。
💡 将VLM的高层推理能力与基于感知的、持续更新的结构化世界状态相结合,是实现复杂、动态的多参与者人机交互的关键。
🔗 项目链接:https://www.github.com/HRI-EU/merge
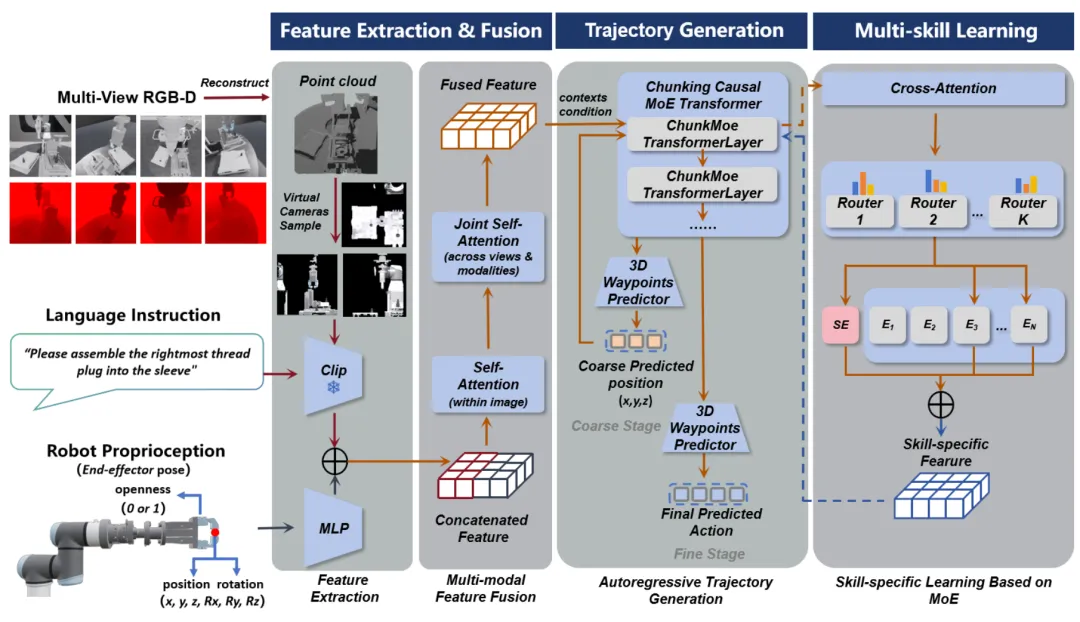
🔬 ATG-MoE:面向装配技能学习的混合专家自回归轨迹生成
📌 Assembly Skill Learning · Learning from Demonstration · Autoregressive Model · Mixture of Experts · Multi-Skill Learning
✨ 端到端地将多模态输入直接映射到机械臂轨迹,通过混合专家架构实现多技能的统一学习,在8个工业装配技能上平均成功率超过91%
📖 传统机器人装配编程灵活性差,现有学习方法要么泛化能力弱,要么设计复杂。本文提出ATG-MoE,一种端到端的自回归轨迹生成方法,将RGB-D观测、自然语言指令和机器人本体感知直接映射到操作轨迹。该方法集成了多模态特征融合、自回归序列生成和混合专家架构。其中,混合专家架构通过共享专家学习技能间的公共知识,通过独立的路由网络学习技能特定的专有知识。在模拟和真实世界减压阀装配任务(8个代表性技能)上的实验表明,ATG-MoE在平均抓取成功率和平均总体成功率上均达到90%以上,并展现出强大的位置泛化和多技能集成能力。
💡 通过将视觉、语言和轨迹生成统一在一个端到端的模型中,并利用混合专家架构平衡知识共享与技能专有化,为实现灵活、可扩展的工业机器人装配提供了有效方案。
🔗 项目链接:https://hwh23.github.io/ATG-MoE
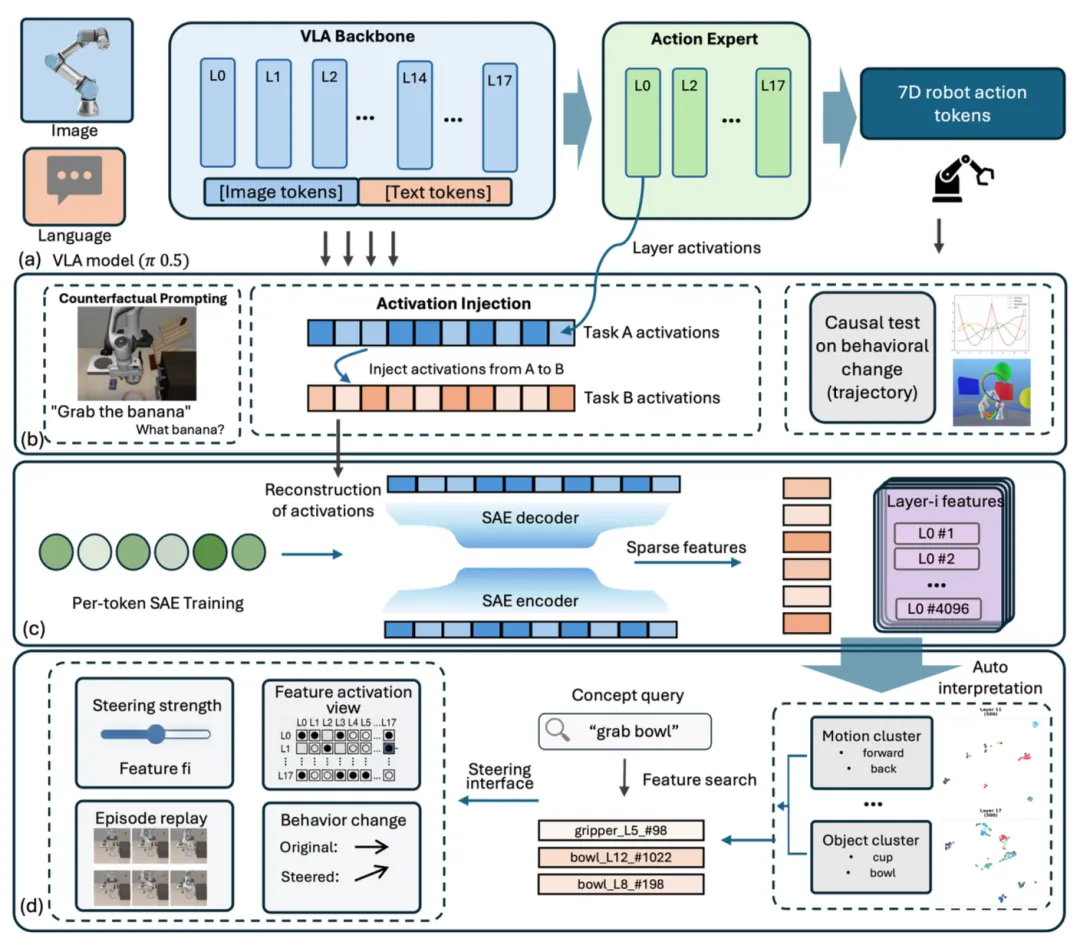
🔬 Dr. VLA:视觉-语言-动作模型的机制可解释性研究
📌 Vision-Language-Action Models · Mechanistic Interpretability · Sparse Autoencoders · Feature Steering · Robot Learning
✨ 首次系统性地揭示了VLA模型内部的特征构成,发现其视觉通路主导行为、语言指令使用取决于任务结构、专家与VLM通路功能分化等核心机制
📖 VLA模型在机器人操作中展现出巨大潜力,但其内部工作原理尚不明确。本文运用激活注入、稀疏自编码器和线性探针等技术,对6个不同架构和规模的VLA模型进行了大规模的机制性研究。研究发现:视觉通路在所有模型中均主导行为;语言指令的敏感性由任务结构决定,而非模型设计;在多通路架构中,专家通路编码运动程序,而VLM通路编码目标语义。此外,作者还发布了Action Atlas交互式平台,用于探索VLA模型的内部表征。
💡 理解VLA模型内部“如何”工作,是诊断其失败模式、提升其鲁棒性和可控性的前提。这项研究为构建更可靠、可解释的机器人策略迈出了重要一步。
🔗 项目链接:https://cwru-aism.github.io/vla-interp-page/
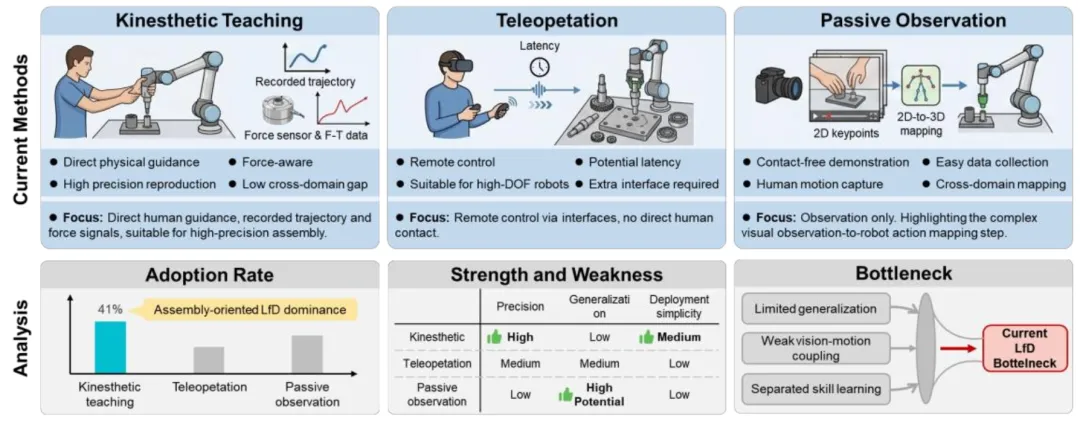
🔬 ViTac-Tracing:可变形物体追踪的视觉-触觉模仿学习
📌 Imitation Learning · Deformable Object Manipulation · Tactile Sensing · Visual-Tactile Fusion · Teleoperation
✨ 通过融合局部中心损失和全局任务损失,首次在模仿学习框架中统一了1D和2D可变形物体的追踪策略,并在未见物体上实现65%的成功率
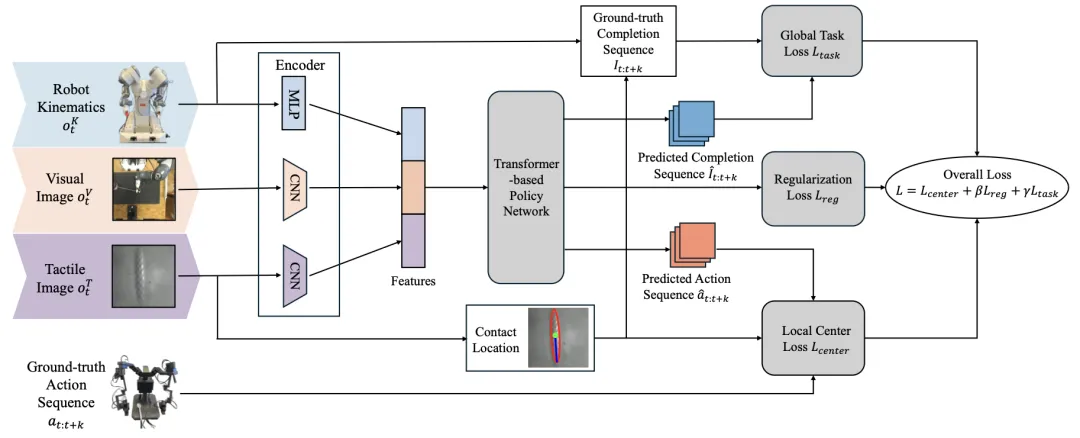
📖 可变形物体的追踪是将其从无序状态转变为延展状态的关键步骤。现有方法缺乏对多种物体类别的通用性或在真实世界中表现不佳。本文提出一种新的视觉-触觉模仿学习方法,通过一个统一的模型实现对1D和2D可变形物体的追踪。方法设计了局部中心损失,引导策略维持物体在触觉图像中心以增强抓取稳定性;以及全局任务损失,帮助策略感知任务进度,实现精确终止。在低成本的视觉-触觉遥操作系统上收集数据,并在ABB YuMi机器人上进行实验,验证了该方法在多种未见物体上的有效性和泛化能力。
💡 将触觉的局部高精度信息与视觉的全局上下文信息结合,并通过任务相关的损失函数引导,是解决高度不确定的接触丰富操作任务的有效路径。
🔗 项目链接:https://sites.google.com/view/vitac-tracing
🔬 FASTER:重新思考流式视觉-语言-动作模型的实时性
📌 Vision-Language-Action Models · Real-Time Robotics · Flow Matching · Action Chunking · System Efficiency
✨ 通过引入“视野感知调度”,将流式VLA模型的首个动作生成时间压缩到单步采样,在动态任务中实现10倍加速,解锁了实时响应能力
📖 实时性是VLA模型部署到物理世界的关键瓶颈。现有异步推理方法主要优化轨迹平滑度,但忽视了反应延迟。本文重新定义了反应时间,并提出FASTER方法,旨在加速流式VLA模型中即时动作的生成。核心创新在于“视野感知调度”,它根据动作索引自适应分配去噪步骤,优先处理近期的、对反应至关重要的动作,同时保持长视野轨迹的生成质量。结合流式客户端-服务器接口和早停策略,FASTER在真实机器人的乒乓球任务中,成功将反应延迟压缩至单步采样,并在消费级GPU上实现了实时闭环控制。
💡 通过重新思考流匹配的采样策略,将计算资源从“均匀分配”转向“按需分配”,是解锁VLA模型在动态、时敏场景中应用潜力的关键。
🔗 项目链接:https://innovator-zero.github.io/FASTER