 夜雨聆风
夜雨聆风





肿瘤医生的AI助手来了?看CancerLLM如何从260万份临床记录中学习,实现诊断与表型提取双高精度,推动AI临床落地迈出关键一步.
蓝字关注(联系方式见文末)


在《Npj Digital Medicine》期刊上发表的最新研究成果《CancerLLM: a large language model in cancer domain》,研究针对当前医学大语言模型普遍缺乏癌症领域专业知识、模型参数量大导致临床部署困难以及缺乏高质量评估数据集的现状,开发了一个专用于癌症领域的、参数规模为70亿的大语言模型CancerLLM。该模型以Mistral 7B为基础架构,分两阶段进行训练:首先利用来自明尼苏达大学临床数据仓库的超过260万份临床记录和51.5万份病理报告进行持续预训练,以注入癌症知识;随后,在专门构建的癌症表型提取与诊断生成指令数据集上进行微调。评估结果表明,CancerLLM在内部测试中表现优异,在诊断生成和表型提取任务上的平均F1分数分别达到86.81%和91.78%,显著优于包括13B和70B参数模型在内的16个现有医学大语言模型基线。此外,该模型在独立患者队列中展现出良好的泛化能力(平均F1 85.08%),并且在反事实与拼写错误鲁棒性测试中表现稳健,同时其推理时间与GPU内存占用远低于参数量更大的模型,体现了高效性。此项工作为临床医生和医学研究者提供了一个专注于肿瘤学、兼具高性能与高可部署性的AI工具,并为基于真实世界电子健康记录开展癌症信息提取与辅助诊断研究提供了新的基准和可行路径。

研究成功开发并验证了一个专用于肿瘤学领域的70亿参数大语言模型。该研究精准定位了当前通用医学大模型在癌症领域面临的核心挑战:专业知识匮乏、高质量评估数据集缺失以及大规模模型临床部署困难。其核心创新论点在于,通过基于大规模癌症领域真实世界文本(超过260万份临床记录与51.5万份病理报告)的持续预训练注入深度领域知识,并结合针对表型提取与诊断生成任务的指令微调,能够构建一个参数规模相对较小、但在专业任务上性能卓越、且兼顾推理效率的专用模型。研究提供了坚实的数据驱动型论据:CancerLLM在内部测试中表现优异,诊断生成与表型提取任务的平均F1分数分别达到86.81%与91.78%;在与16个不同参数规模的基线模型对比中,其性能显著领先于多数7B/13B模型,并可媲美或超越部分70B模型;此外,在独立的患者队列测试以及针对反事实标注和拼写错误的鲁棒性测试中,模型进一步验证了其良好的泛化能力和对临床噪声的稳定性。该研究的学术价值突出,它不仅首次提出了一个覆盖17种癌症类型的高性能、易部署的肿瘤学专用大语言模型,为领域提供了重要的基础工具,还配套构建了公开的基准测试数据集,推动了标准化评估;更重要的是,它通过实证成功验证了“领域聚焦、小规模优化”的技术路径在医疗AI中的巨大潜力,为开发适用于实际临床场景的高效、可靠辅助诊断工具提供了关键的技术范式与可行性方案。
研究提出的核心模型架构是一个基于Mistral 7B基础模型、通过两阶段训练(领域知识注入与指令任务对齐)构建的癌症领域专用大语言模型。其整体设计思路是:首先通过在海量癌症临床文本上继续预训练,将领域知识深度注入模型;随后,使用专门构建的指令数据集对模型进行微调,使其精准掌握癌症表型提取与诊断生成两项核心临床任务。整个工作流程是一个清晰的四阶段管道,如图2所示:(1) 癌症知识注入(预训练),(2) 监督指令微调,(3) 多指标生成能力评估,(4) 应用于下游任务。
功能:这是模型获得癌症领域知识的基础模块。其目标不是从零开始训练,而是在一个优秀的通用基础模型(Mistral 7B)之上,进行领域自适应。
输入数据:模块使用来自明尼苏达大学临床数据仓库的2,676,642份癌症临床笔记和515,524份病理报告,覆盖17种癌症类型。这些文本构成了模型的“领域语料库”。
核心算法:采用标准的自回归语言建模目标(下一词预测)进行持续预训练。为提升训练效率,采用了低秩适配(LoRA) 技术,而非更新全部模型参数。LoRA的秩(rank)设为8,Alpha设为16,在10张A100 GPU上训练了47小时。
功能:将预训练后具备领域知识的模型,对齐到具体的临床信息处理任务。本研究针对两个任务构建了专用的指令数据集。
任务一:癌症表型提取
-
数据预处理:将现有的CancerBERT数据集(专注于乳腺癌的命名实体识别)转化为问答(QA)格式。给定一个病理报告或临床笔记中的句子(上下文),模型需要回答8个预定义的关于实体类型的问题(如“肿瘤大小是多少?”),答案即为对应实体。若上下文中不相关,则输出“不相关”。
指令模板:
{“instruction”: “你是一名优秀的肿瘤学家,此任务涉及根据提供的上下文或文本回答问题。”, “context”: “输入的句子”, “question”: “具体问题”, “response”: “实体答案”}任务二:癌症诊断生成 数据预处理:从临床笔记中提取结构化的关键字段,包括就诊原因、治疗部位、主观信息、护理系统评估、客观观察和实验室结果,共同作为输入上下文。
诊断标签构建:以“诊断:”后的文本结合ICD编码作为目标输出。。
指令模板:
{“instruction”: “你是一名医学专家。此任务涉及根据提供的上下文或文本生成诊断。”, “context”: “结构化临床信息”, “response”: “癌症诊断”。微调配置:此阶段同样使用LoRA,秩设置为64。在单张A100 GPU上,以2e-4的学习率训练4小时。
功能:这不是模型的前向应用模块,而是用于全面衡量模型性能的内部测试框架,包含两个子模块。
生成能力评估子模块:使用Exact Match、BLEU-2和ROUGE-L三种指标,从精确匹配、2-gram重叠和最长公共子序列角度综合评价模型生成文本的质量。
鲁棒性测试床子模块:这是本研究的创新模块,用于测试模型在非理想数据下的稳定性。
-
反事实鲁棒性测试:在表型提取任务的训练数据中,随机将20%、40%、60%、80%样本的答案替换为错误实体,模拟标注错误,测试模型的抗干扰能力。
拼写错误鲁棒性测试:在诊断生成任务的输入上下文中,随机对2%-8%的单词引入字符级错误(交换、删除、重排字母),模拟临床笔记中的笔误,评估模型对噪声输入的容忍度。
功能:为进一步提升性能,研究还探索了检索增强生成架构。这是一个可选的、包裹在核心模型之上的模块。
工作流程:
-
步骤1:使用检索器(如MedCPT、Contriever、Specter2等)将输入句子编码为向量。
步骤2:将训练集构建为检索数据库,其中每个实例(上下文-答案对)都被编码。
步骤3:计算输入句子与数据库中所有实例的相似度,检索出最相关的top-k个示例。
步骤4:将这些检索到的示例作为参考,与原始输入一起拼接成新的提示,输入给CancerLLM,从而辅助其生成更准确的预测。
二、总结
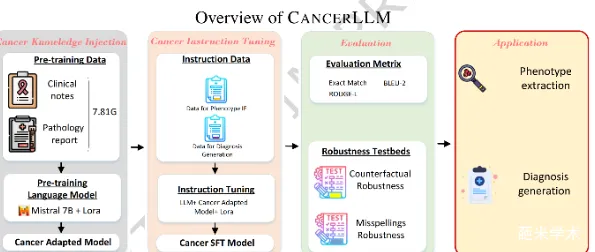
CancerLLM的架构并非一个全新的模型骨架,而是基于Mistral 7B,通过领域特异性数据注入和任务特异性指令微调这两大核心模块进行深度定制的结果。其创新性主要体现在针对癌症领域精心构建的两阶段训练数据管道,以及系统性的鲁棒性评估框架。最终的模型是一个能够高效处理临床文本、输出关键病理信息和诊断结论的专用工具。
研究结果
研究的结果部分通过一系列系统的实验,全面评估了CancerLLM在核心任务上的性能、泛化能力、鲁棒性及效率。结果展示遵循了从核心任务性能比较,到细分维度深入验证的逻辑顺序。
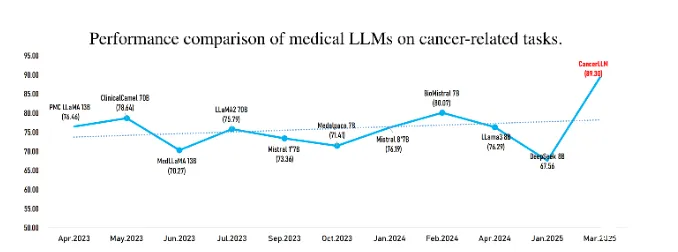
研究首先在与16个不同规模医学大语言模型的对比中,验证了CancerLLM的优越性。如图1所示,该图以平均F1分数(综合Exact Match, BLEU-2, ROUGE-L)直观展示了各模型在癌症表型提取与诊断生成两个任务上的综合表现。CancerLLM(图中最右侧柱状图)取得了最高的平均性能(89.30%),显著超越了所有同等规模(7B/8B)及大部分更大规模(13B, 70B)的基线模型,这确立了其作为高效能专用模型的地位。
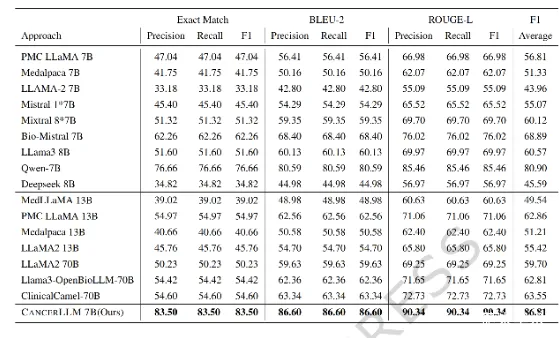
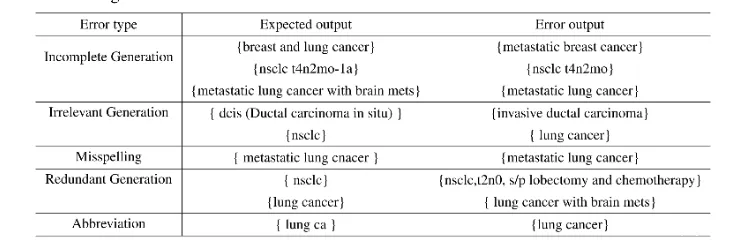
具体到癌症诊断生成任务(文章表1),CancerLLM取得了平均F1分数86.81%的优异表现,其Exact Match, BLEU-2和ROUGE-L的F1分数分别为83.50%, 86.60%和90.34%。与最强的7B基线模型Bio-Mistral 7B(平均F1 68.89%)相比,性能提升了17.92个百分点;与通用基础模型Mistral 1 * 7B(平均F1 55.07%)相比,提升幅度更高达31.74个百分点。这直接证明了领域专精化训练的有效性。
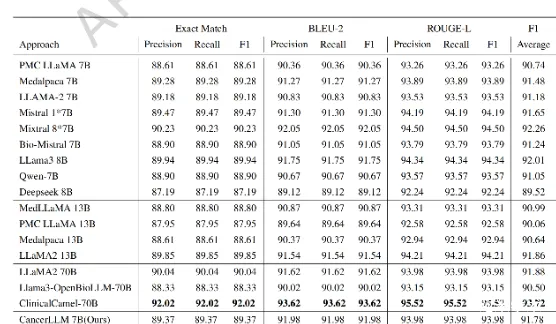
在癌症表型提取任务上(文章表3),CancerLLM同样表现出色,平均F1分数达到91.78%,与参数量大得多的LLaMA2 13B(91.86%)和LLaMA3 8B(92.01%)性能相当,但远高于其基础模型Mistral 1 * 7B(91.65%)。虽然拥有700亿参数的ClinicalCamel-70B在此任务上取得了最佳性能(93.72%),但CancerLLM以仅十分之一的参数量实现了可比拟的性能,凸显了其效率优势。
为检验模型在未见过的患者数据上的泛化能力,研究构建了一个与训练集完全无患者重叠的独立测试队列。在此严格设定下,CancerLLM再次展现了最强的泛化性能(文章表2),平均F1分数为85.08%。它显著优于其他表现较好的基线模型,如LLaMA3 8B(73.51%)和Bio-Mistral 7B(71.07%)。统计检验(Bootstrap置信区间与McNemar检验)结果进一步证实,CancerLLM相对于这些基线的性能提升具有统计显著性(p值远小于0.05),表明其学到的知识具有强大的泛化性,而非对训练数据的简单记忆。
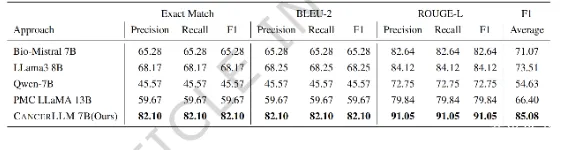
研究设计了两个测试来评估模型对现实世界数据缺陷的鲁棒性。首先,在反事实鲁棒性测试中,研究向表型提取训练数据中注入不同比例(20%, 40%, 60%, 80%)的错误标注。如图3(左)所示,随着错误标注率上升,所有模型性能均下降,但CancerLLM在所有错误率下均稳定优于其基础模型Mistral 1 * 7B。尤其在80%的高错误率下,CancerLLM的性能优势更为明显,表明其从正确样本中学习有效模式、抵抗错误标签干扰的能力更强。
其次,在拼写错误鲁棒性测试中,研究在诊断生成任务的输入中引入不同比例(2%-8%)的字符级拼写错误。如图3(右)所示,随着错误率增加,CancerLLM与Bio-Mistral 7B的性能均下降,两者在平均F1分数上接近。然而,在8%的高错误率下,CancerLLM在Exact Match(0.27% vs. 0.09%)和ROUGE-L(25.81% vs. 23.80%)上优于Bio-Mistral 7B,显示其在面对严重文本噪声时,仍能保持相对稳定的语义理解与生成能力。
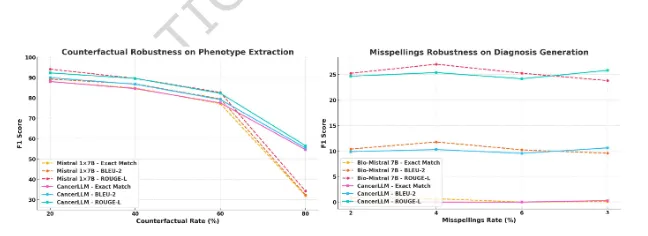
研究对比了不同模型在实际推理中的资源消耗(文章表4)。在表型提取任务中,尽管700亿参数的ClinicalCamel-70B性能最佳,但其推理耗时(2:50:16)和GPU内存占用(37,716 MB)极高。相比之下,CancerLLM在取得优秀性能(F1 91.78%)的同时,仅需约十分之一的时间(1:14:12)和七分之一的GPU内存(5,550 MB)。在诊断生成任务中,CancerLLM以86.81%的F1分数大幅领先,而其资源消耗仍与普通7B模型相当,远低于13B/70B模型。这证明了CancerLLM是兼顾高性能与高部署可行性的解决方案。
研究还探索了结合不同检索器对模型性能的影响(文章表5)。在诊断生成任务中,检索高质量相关示例能带来显著提升,其中Specter2检索器效果最佳,将平均F1从基础版CancerLLM的86.81%提升至89.12%。然而,在表型提取任务中,无检索器的基础模型(91.78%)表现反而略优于大多数检索增强版本。分析认为,这是因为表型提取是细粒度的实体识别任务,检索到的示例若不完全相关,反而会引入噪声。这一对比结果说明,检索增强的有效性高度依赖于任务特性,对于需要复杂推理的诊断生成任务助益明显。
04
在理论上,本研究有力证实了在医疗AI中“领域专业化”大型语言模型(LLM)的理论优势与可行性。此前,虽然通用医学LLM不断发展,但文档指出,专门针对复杂、专业的癌症领域的高性能模型仍属空白。CancerLLM的成功构建表明,通过对通用基础模型进行大规模领域特定数据(临床笔记与病理报告)的持续预训练,能够将深度的肿瘤学知识有效“注入”模型,使其在专业任务上达到甚至超越参数规模大得多的通用模型。这为“小而专”的AI模型发展路径提供了坚实的实证支持,挑战了“参数规模决定性能”的简单认知,丰富了医疗大模型发展的理论范式。
在方法学上,本研究做出了两大关键贡献。首先,构建并开源了高质量的专业数据集与评估基准。针对癌症表型提取和诊断生成任务精心构建的指令数据集,解决了文档中提到的“缺乏高质量、任务相关的评估数据集”这一领域关键挑战,为后续研究提供了宝贵的公共资源与可比对的基准。其次,引入了系统化的鲁棒性评估框架。所设计的“反事实鲁棒性”与“拼写错误鲁棒性”测试床,超越了传统纯净数据下的性能评估,将临床文本中常见的标注错误、拼写噪声纳入考量,为评估医疗AI模型在真实、嘈杂环境下的实用性与可靠性设立了新的方法论标准。
在临床应用层面,本研究的贡献直接指向解决实际医疗工作的痛点。CancerLLM展现出在癌症诊断生成(平均F1 86.81%) 和关键表型信息提取(平均F1 91.78%) 上的高精度,表明其有潜力成为辅助临床医生快速、准确归纳诊断和梳理病理报告的智能工具。更重要的是,该研究明确针对“大规模模型难以在资源有限的医疗机构部署”这一现实问题,通过打造7B参数的轻量级模型,并验证其在大幅降低推理时间与GPU内存消耗的同时保持卓越性能,真正推进了先进AI技术向临床一线部署的可行性,有助于缩小医疗资源差距。
本研究精准呼应了当前肿瘤学AI领域从“通用”走向“专科化”、从“追求规模”到“兼顾效率”的发展趋势。它不仅提供了一个可直接应用或进一步优化的强大工具(CancerLLM模型及代码已开源),更通过其检索增强实验揭示了不同任务对上下文增强技术的差异化需求,为未来研究指明了方向。同时,文档中分析的模型局限性(如对罕见亚型、复杂缩写和拼写错误的处理能力仍有提升空间)实际上清晰地勾勒了未来的研究重点:包括融合多中心、多模态数据以提升泛化能力,以及开发更强大的临床文本规范化与纠错前置模块。总之,这项研究通过其理论验证、方法创新与工具贡献,显著推动了计算肿瘤学与临床信息学的发展,为下一代面向真实世界临床场景的专科AI辅助系统奠定了坚实基础。
葩米AI—专注于医疗大模型科研、影像组学与人工智能算法的科研探索者。我们面向医疗场景致力于AI科研算法服务,专注于将前沿人工智能技术融入医学研究和临床应用,产品包括面向医生的影像组学科研平台,医疗多模态大数据中心以及医疗AI大模型研发平台。联系我们,开启您的医疗AI科研之旅,一起成为医疗AI的探路者。

微信号:radiomier
邮箱:pami2018@163.com