 夜雨聆风
夜雨聆风





具身智能相关论文开源代码推荐20260403
点击下方卡片,关注【具身智能小站】公众号
📅 2026年4月
👋 大家好!
来了!2026 年新开始的一个系列,主要是整理具身智能领域最近发表的提供开源代码或数据集的项目(论文),希望对相关领域的小伙伴有所帮助。获取这些论文的开源项目链接,可以直接在本文中查看。欢迎转发和关注!!👇
📊 今日数据统计
|
|
|
|---|---|
|
|
|
🤖 开源论文(重点板块)
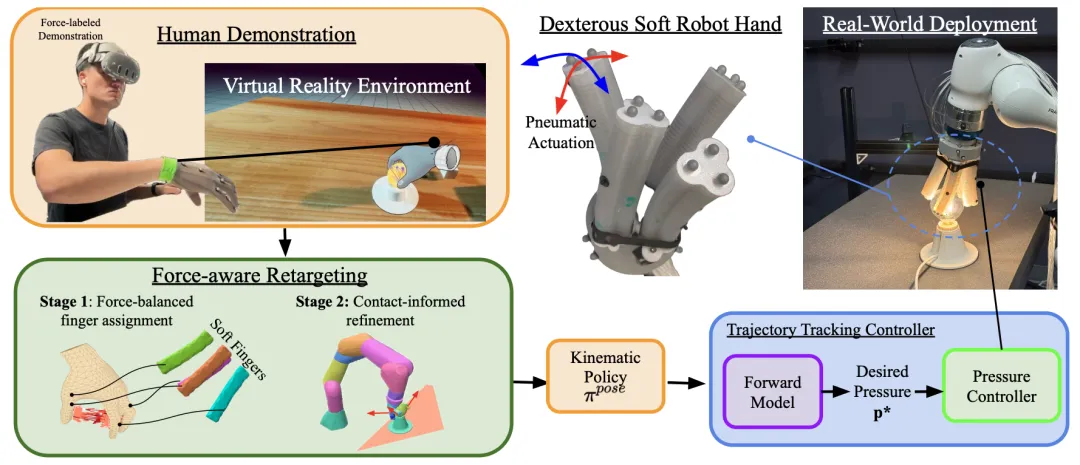
🔬 SoftAct:从虚拟人演示到软体机器人策略的功能性力觉感知重定向
📌 Soft Robotics · Learning from Demonstration · Force-aware Retargeting · Contact-rich Manipulation
✨ 通过显式建模接触力而非运动学相似性,将人类操作技能成功迁移到非拟人化软体手
📖 SoftAct针对将人类灵巧操作技能迁移到形态、驱动与控制方式差异巨大的软体机器人手这一难题,提出了一种基于接触力的重定向框架。该方法利用VR采集包含手部运动、物体状态、密集接触面与接触力信息的人类演示。其核心是两阶段算法:第一阶段根据演示中的接触力分布,将软体手指按负载均衡原则分配给人类手指;第二阶段在执行时,结合基线末端执行器轨迹与基于测地线距离加权的接触细化,实时调整指尖目标。实验证明,该方法在多种接触丰富的任务中,在轨迹跟踪精度与任务成功率上显著优于运动学或纯学习基线,并在真实机器人上实现了零样本部署。
💡 在巨大的形态差异面前,接触力比运动轨迹更能传递操作的“功能意图”。
🔗 项目链接:https://soft-act.github.io/
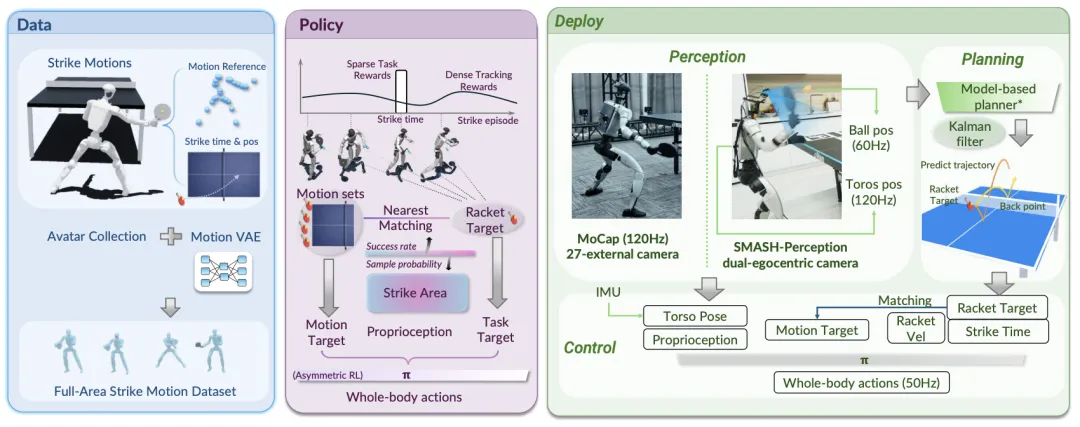
🔬 SMASH:基于机载视觉掌握可扩展全身技能的人形乒乓球机器人
📌 Humanoid Robot · Whole-Body Control · Egocentric Vision · Motion Generation
✨ 首个仅靠机载视觉实现户外连续对打并完成全身扣杀动作的人形乒乓球系统
📖 SMASH系统为人形机器人打乒乓球提供了完整的解决方案。它首先通过运动VAE模型增强和扩展了稀缺的动作捕捉数据,生成了覆盖广泛击打工作空间的全身击球运动库。然后,通过任务导向的运动匹配机制,将任务目标(击球点、速度、时间)与运动先验紧密结合,训练一个全身强化学习策略。该系统还构建了基于机载视觉的实时感知管道(YOLO+HSV+AEKF),实现了对球和自身体态的稳定估计。真实世界实验验证了SMASH在仅使用机载摄像头的情况下,能够执行包括爆裂扣杀和低姿救球在内的多样化全身击球动作,并首次实现了户外连续对打。
💡 任务对齐的运动先验与可扩展的生成模型,是释放人形机器人动态、敏捷全身技能潜力的关键。
🔗 项目链接:https://mmlab.hk/Smash/

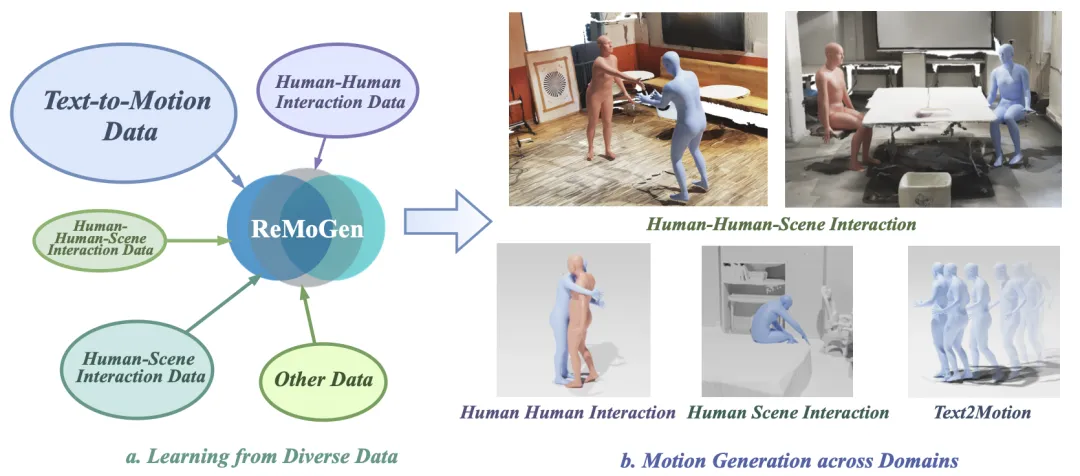
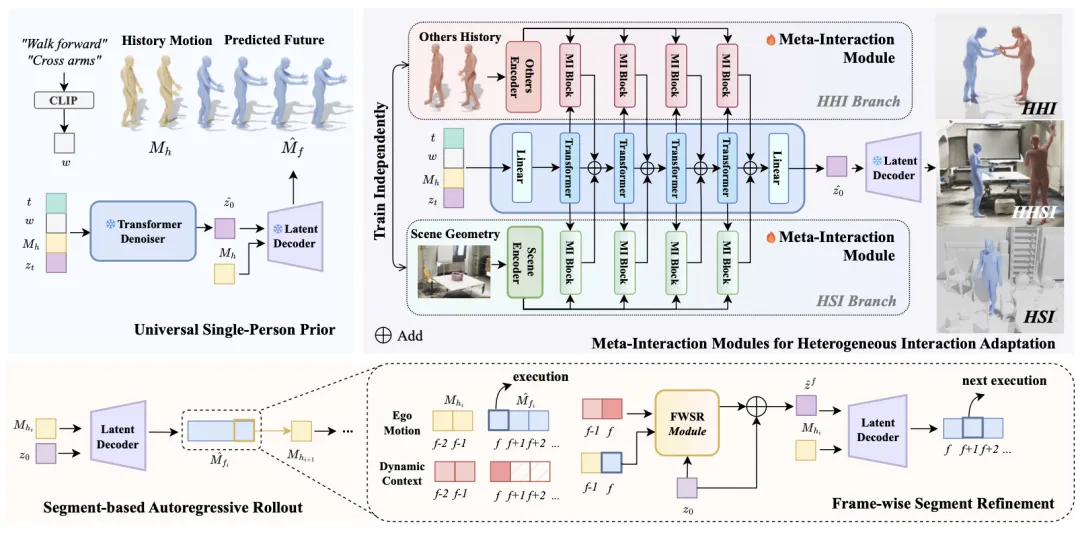
🔬ReMoGen:通过模块化学习从异构数据中实现实时人体交互-反应生成
📌 Human Motion Generation · Modular Learning · Real-time · Interaction
✨ 模块化解耦通用运动先验与交互适配,结合帧级片段精炼,实现数据高效且低延迟的实时交互反应
📖 ReMoGen针对实时人体交互-反应生成任务,解决了数据稀缺异构与实时响应两大挑战。其核心是一个模块化框架:首先在大规模单人运动数据上预训练一个通用的文本条件运动先验并冻结;然后针对不同交互域(如人-人、人-场景)独立训练轻量级的元交互模块,将动态交互线索注入到冻结的先验中。为兼顾实时性,ReMoGen采用片段级生成与轻量级帧级片段精炼模块,仅对当前帧进行低成本修正。实验表明,ReMoGen在人-人、人-场景及混合交互场景下均能生成高质量、连贯且实时的反应运动。
💡 将通用运动知识与特定交互能力分离,是实现数据高效、可扩展且实时响应的交互行为生成的关键。
🔗 项目链接:https://4dvlab.github.io/project_page/remogen/
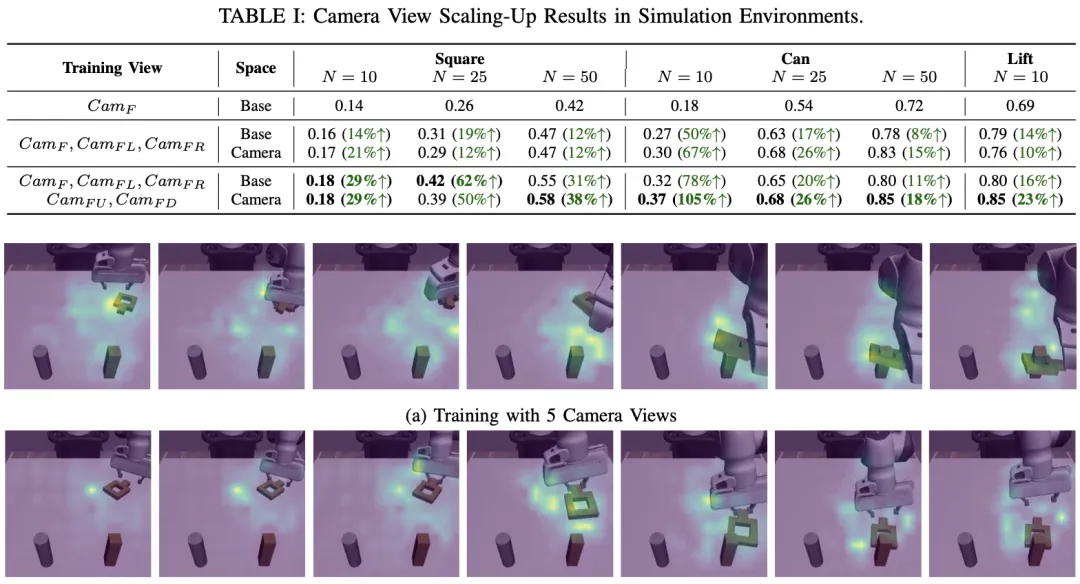
🔬 通过缩放相机视角实现高效的模仿学习
📌 Imitation Learning · Multiview Learning · Data Efficiency · Manipulation
✨ 无需额外收集演示数据,仅通过多视角相机生成伪演示,即可大幅提升策略泛化性
📖 该工作指出,模仿学习策略的泛化能力受限于专家演示的场景多样性,而收集不同环境下的演示成本高昂。为此,本文提出一种简单高效的策略:在采集演示时,利用多个同步相机视角,将单条专家轨迹扩展为多条伪演示轨迹,从而在不增加人力成本的前提下极大丰富了训练数据的视觉多样性。通过系统分析动作空间(基座、末端执行器、相机空间)与视角缩放的关系,并提出一种在推理时融合多视角动作的聚合方法,该方法在仿真和真实机器人操作任务中显著提升了数据效率与泛化性能。
💡 场景的内在视觉多样性是免费的宝藏,而缩放相机视角正是挖掘这一宝藏的最直接钥匙。
🔗 项目链接:https://yichen928.github.io/robot_multiview/
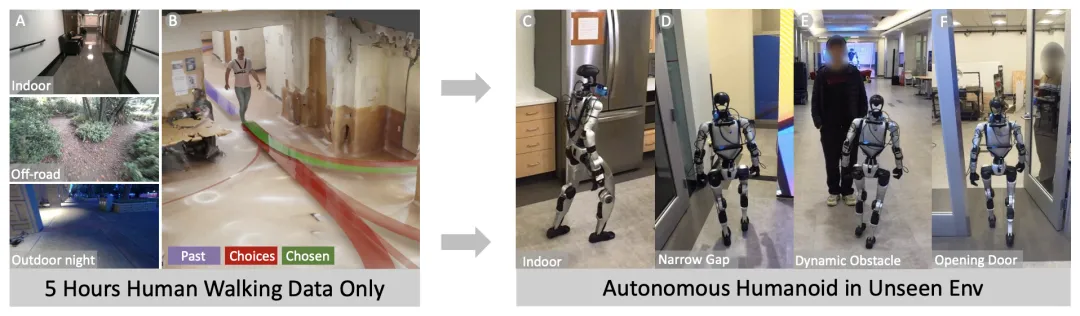
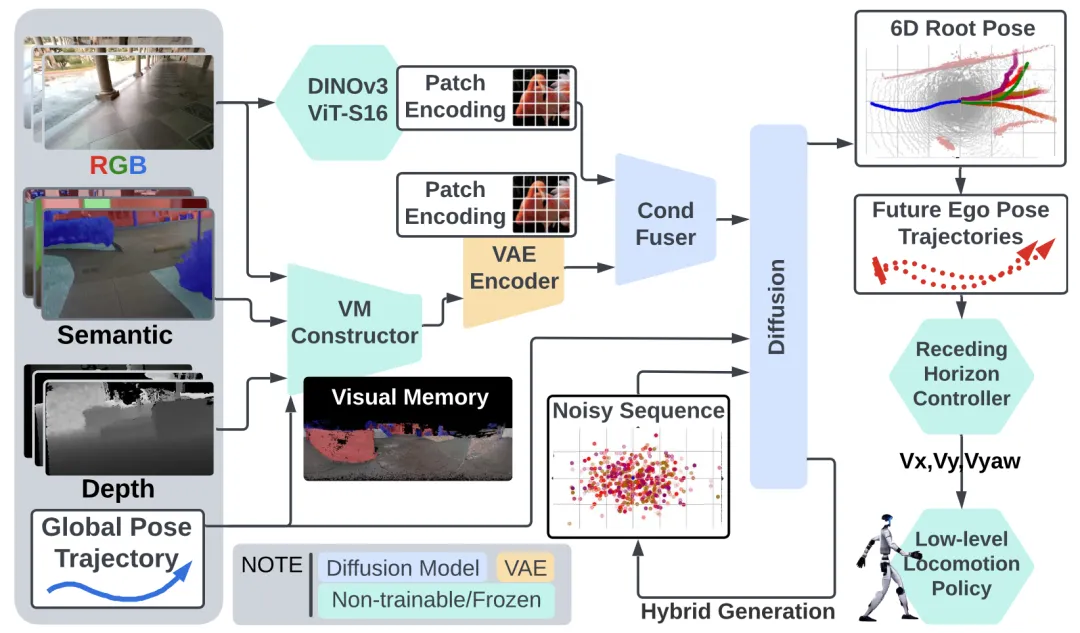
🔬 EgoNav:从人类行走数据中学习人形机器人导航
📌 Humanoid Navigation · Diffusion Model · Zero-shot Transfer · Egocentric Vision
✨ 仅用5小时人类行走数据训练扩散先验,零样本部署到人形机器人,涌现出避障、等待开门等智能行为
📖 EgoNav提出了一种纯从人类行走数据中学习导航先验,并零样本部署到人形机器人的系统。该方法利用360度视觉记忆(融合彩色、深度与语义)和DINOv3视频特征,训练了一个条件扩散模型来生成多模态的未来轨迹分布。通过混合采样策略实现实时推理,并采用滚动时域控制器选择路径。在真实Unitree G1上的实验表明,EgoNav无需任何机器人数据或微调,即可在未见过的室内外环境中实现自主导航,并涌现出如等待开门、避让人群和避开玻璃墙等复杂行为。
💡 导航的核心是学习“在哪里走”的常识分布,而非执行“如何走”的特定指令,这使其成为连接高层规划与底层运动控制的理想中间层。
🔗 项目链接:https://egonav.weizhuowang.com/
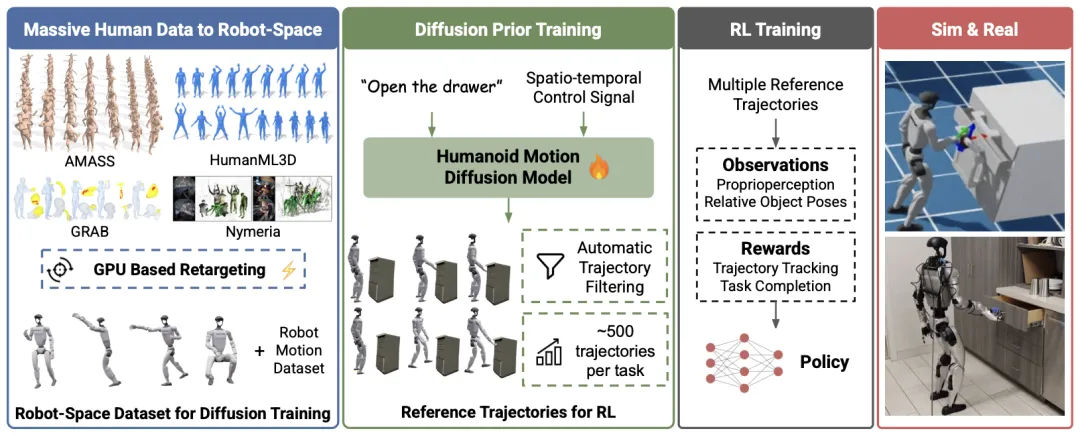
🔬 DreamControl-v2:通过可训练引导扩散先验实现更简单且可扩展的自主人形技能
📌 Humanoid Learning · Diffusion Prior · RL · Loco-manipulation
✨ 直接在机器人动作空间训练扩散模型,消除后处理重定向,实现全自动化与技能扩展
📖 DreamControl-v2提出了一种改进的人形机器人技能学习框架。针对DreamControl依赖“生成-后重定向”流程(先在人体空间生成运动再映射到机器人)带来的空间约束失效与手动调参问题,DreamControl-v2通过将多样化的异构人类运动数据集预重定向到目标机器人形态,并直接在机器人状态空间中训练引导式扩散模型,从而消除了繁琐的后处理重定向与手动筛选。该方法生成的参考轨迹可直接用于下游强化学习策略的跟踪。实验表明,该框架在仿真与真实Unitree-G1机器人上均展现出更优的技能覆盖范围、自动化程度与任务成功率。
💡 消除“仿真-现实”鸿沟的关键在于让生成先验与机器人物理本体对齐,而非与人类形态对齐。
🔗 项目链接:https://genrobo.github.io/DreamControl-v2/
一般的星球时间限制是1年,我们是终身制星球,进来就是长期陪伴,还能遇见同频的朋友
🎁 公众号粉丝专属 50元优惠券 已备好点击领取,直接锁定终身席位 👇
