用了40年的抗体规范聚类,终于被这个AI工具突破了局限
 摘要:这两天啃完了基因泰克和哈佛团队刚发在mAbs上的最新研究,说实话,做了这么多年抗体研发,我很少见能把经典理论和大模型工具结合得这么落地的工作。他们做了个叫Igloo的抗体环多模态tokenizer,直接解决了困扰行业几十年的CDR环表征难题——覆盖度不够、没法对接蛋白大模型。从环结构检索、亲和力预测,到抗体序列设计、先导文库筛选,全链路都跑出了SOTA结果,做抗体药、蛋白设计的朋友,这篇绝对值得沉下心看。
摘要:这两天啃完了基因泰克和哈佛团队刚发在mAbs上的最新研究,说实话,做了这么多年抗体研发,我很少见能把经典理论和大模型工具结合得这么落地的工作。他们做了个叫Igloo的抗体环多模态tokenizer,直接解决了困扰行业几十年的CDR环表征难题——覆盖度不够、没法对接蛋白大模型。从环结构检索、亲和力预测,到抗体序列设计、先导文库筛选,全链路都跑出了SOTA结果,做抗体药、蛋白设计的朋友,这篇绝对值得沉下心看。
做抗体的,谁没被CDR环的表征难哭过?
抗体的核心,是互补决定区CDR。这些柔性环结构,直接决定了抗原结合的特异性,也是抗体药设计的核心靶点。
经典的规范构象聚类,从Chothia时代用到现在,快40年了。但覆盖度一直是硬伤,光是多样性最高的H3环,就有76.3%的序列找不到对应聚类。
更麻烦的是,这些聚类结果,根本没法直接塞进现在的蛋白语言模型里。等于我们手里攒了几十年的结构数据,根本喂不进大模型。
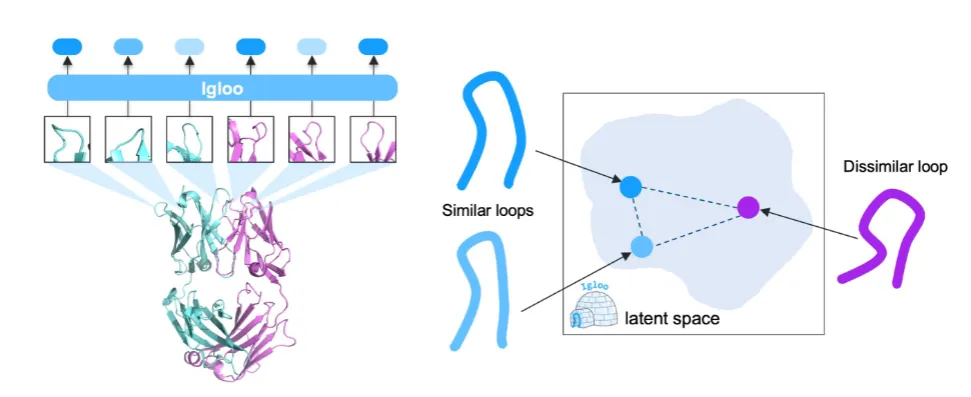
Igloo,到底是个什么样的工具?
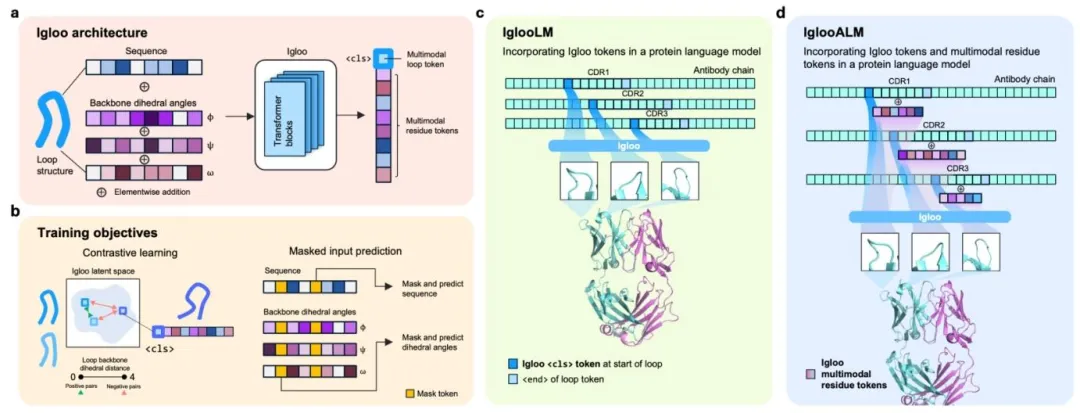
这次团队做的Igloo,全称是免疫球蛋白环tokenizer。它不走氨基酸级别的token化老路,直接在环亚结构层面做编码。
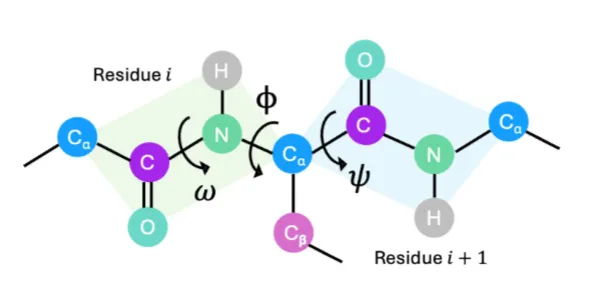
它的输入,是每个氨基酸的骨架二面角φ、ψ、ω,还有对应的氨基酸序列,是真正的多模态编码。
二面角先转成单位圆坐标,和序列编码的embedding加和,完成多模态融合,再用Transformer架构学习整个环的整体表征。
它的核心训练逻辑,是用对比学习,让结构相似的环,在隐空间里靠得更近。训练用了80多万条轻重链的环结构,有实验解析的,也有靠谱的预测结构。
训练用了三个核心目标,多模态掩码重建、骨架对比学习,还有码本学习。这种混合掩码的策略,哪怕只有序列或者只有结构一种模态,它也能跑出靠谱的结果。
实测效果,到底能不能打?
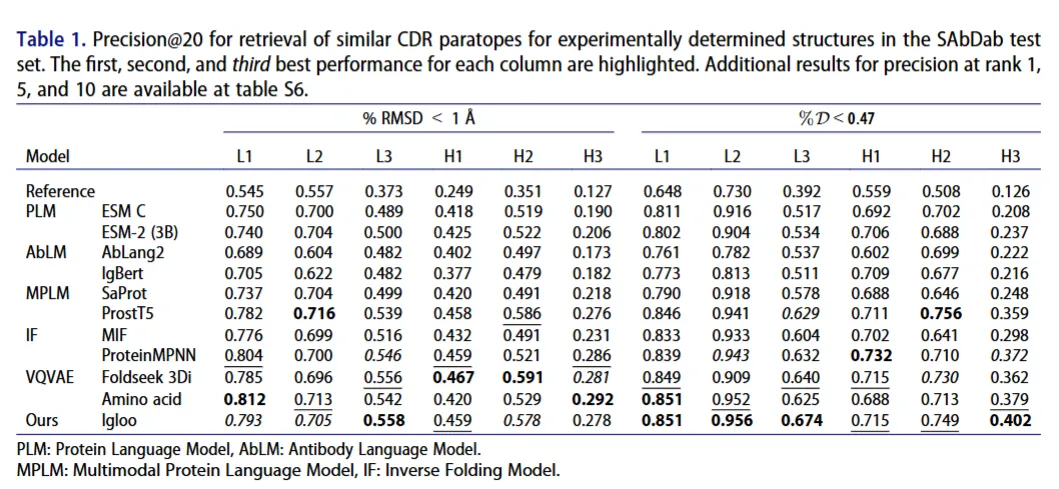
先看最核心的H3环检索。这是抗体里最难搞的部分,序列和结构多样性都拉满,也是所有抗体设计的核心。
Igloo在相似结构检索上,比之前的SOTA模型,精度直接提了6.1%。它还能完美复现经典的规范构象聚类,环类型纯度98.3%,长度纯度96.5%,之前覆盖不到的环,它也能全部分配token。
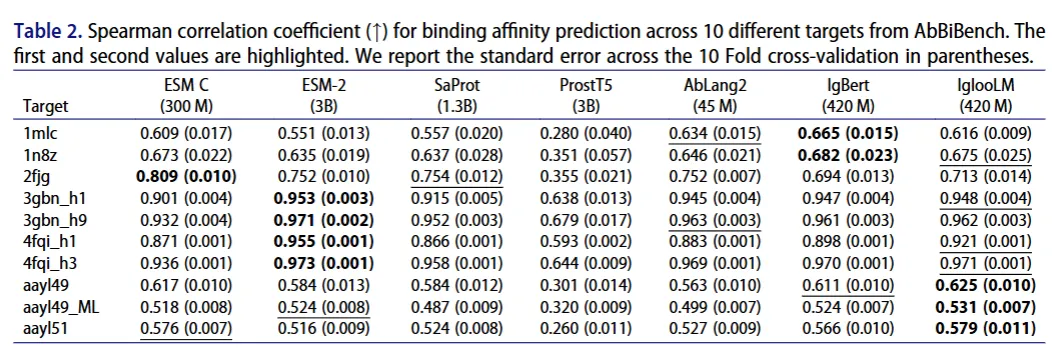
团队把Igloo的token,直接塞进了蛋白语言模型,做了IglooLM。在10个抗体-抗原靶点的亲和力预测任务里,它在8个靶点上,超过了基线模型。
有意思的是,这个420M参数的模型,效果和参数大它7倍多的模型,基本打平。不用堆参数就能拿到更好的结果,对我们这种没那么多算力的团队,太友好了。
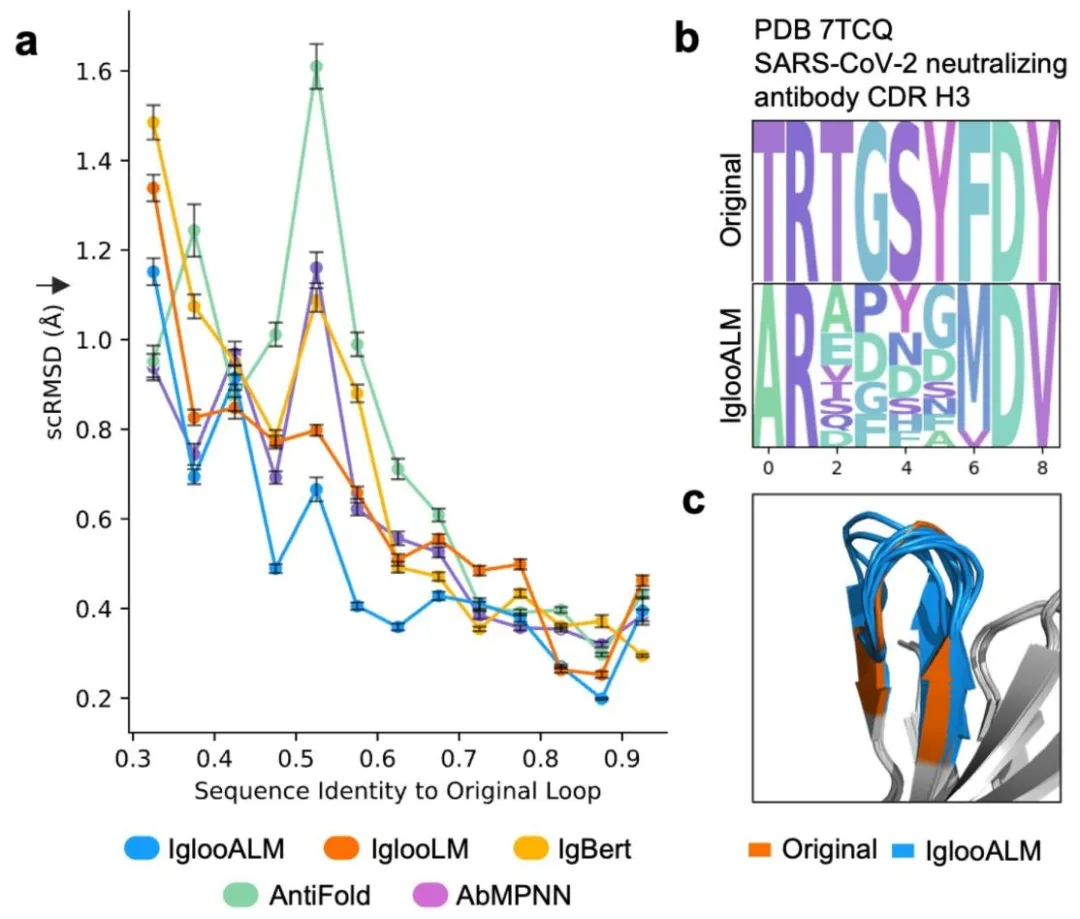
还有IglooALM,用来做抗体环的序列生成。给它一个环的结构,它能生成序列多样性拉满,但结构和原环偏差不到1Å的新序列。比如新冠抗体的H3环,平均序列一致性只有0.27,结构却稳得很。
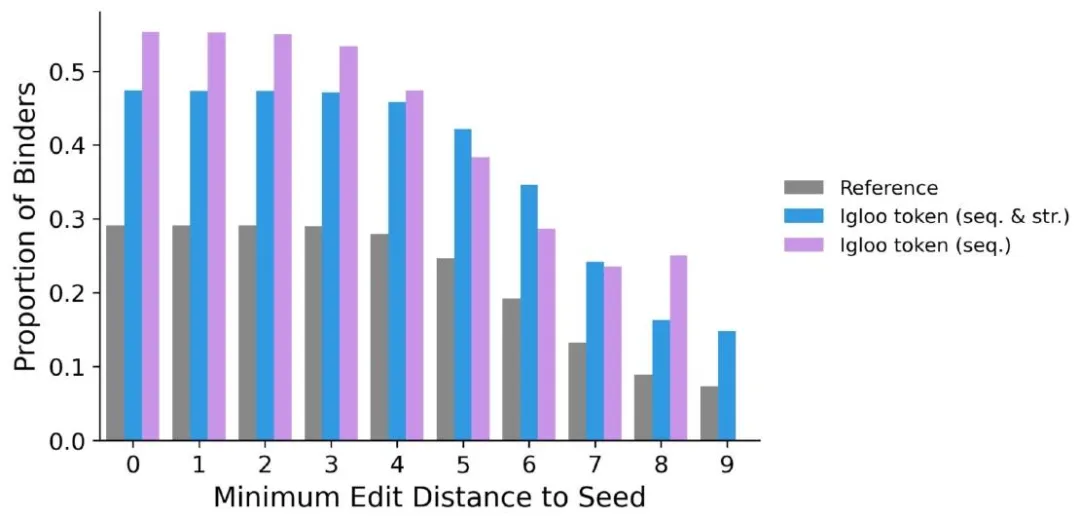
最让我惊喜的是文库筛选的能力。零shot场景下,用它筛HER2靶点的结合体,相同token的序列里,55.3%都是有活性的结合子,富集比直接做到1:9。
我自己跑过类似的筛选流程,3万8千多条序列,全处理完只用了10分钟,这个速度,做先导优化的朋友应该懂有多香。
最后说点我自己的感受
坦白讲,现在蛋白大模型卷得厉害,但大多都在氨基酸级别死磕,很少有人盯着抗体本身的模块化结构做优化。
Igloo最妙的地方,是它没有推翻之前的规范聚类,反而把这个领域几十年的积累,和现在的大模型体系,做了个完美的桥接。
它不是那种只能发论文的花架子,是真的能落到我们日常的研发workflow里,解决真问题的工具。
当然,它现在也只做了抗体和TCR的环,能不能拓展到其他蛋白的功能域,还不好说。但至少在抗体研发这个赛道里,它给我们开了个全新的思路。
识别微信二维码,添加抗体圈小编,符合条件者即可加入
本公众号所有转载文章系出于传递更多信息之目的,且明确注明来源和作者,不希望被转载的媒体或个人可与我们联系(cbplib@163.com),我们将立即进行删除处理。所有文章仅代表作者观不本站。
 夜雨聆风
夜雨聆风