 夜雨聆风
夜雨聆风





具身智能相关论文开源代码推荐20260410
点击下方卡片,关注【具身智能小站】公众号
📅 2026年4月
👋 大家好!
来了!2026 年新开始的一个系列,主要是整理具身智能领域最近发表的提供开源代码或数据集的项目(论文),希望对相关领域的小伙伴有所帮助。获取这些论文的开源项目链接,可以直接在本文中查看。欢迎转发和关注!!👇
📊 今日数据统计
|
|
|
|---|---|
|
|
|
🤖 开源论文(重点板块)
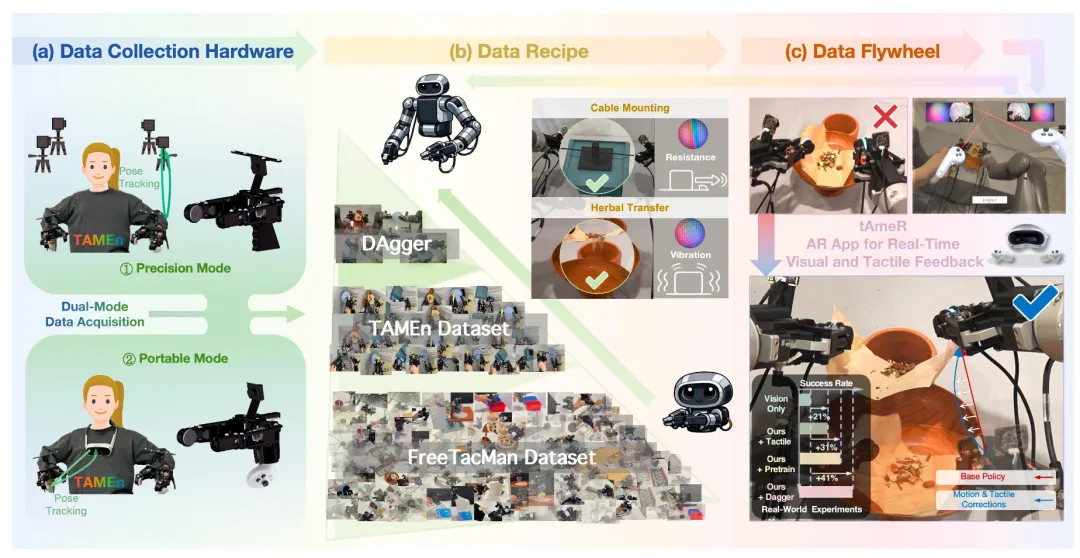
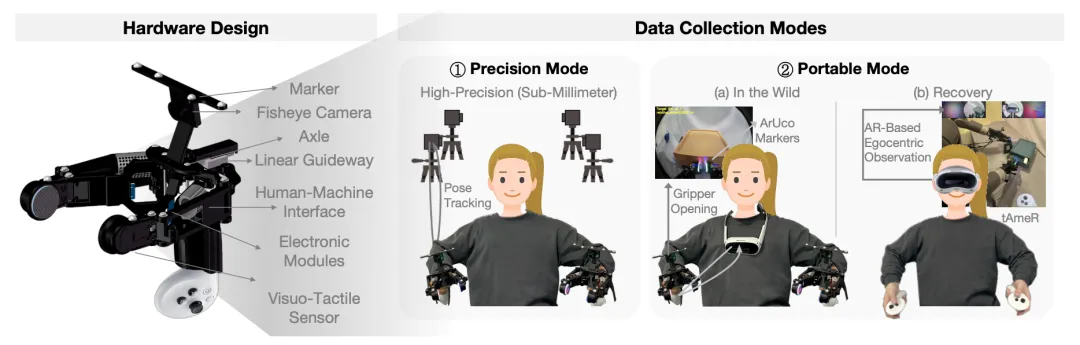
🔬 TAMEn:面向接触丰富双手操作的触觉感知闭环数据采集引擎
📌 Visuo-Tactile Learning · Bimanual Manipulation · Data Collection · Teleoperation
✨ 构建双模数据采集与AR遥操作闭环系统,通过金字塔式数据策略实现接触丰富双手操作的策略学习与持续优化
📖 本文提出TAMEn,一套面向接触丰富双手操作的触觉-视觉数据采集与学习系统。硬件支持高精度动捕与便携VR跟踪双模切换,并在线验证演示的可复现性。数据组织为金字塔结构:大规模单臂触觉预训练、任务特定双手演示、以及基于AR触觉遥操作(tAmeR)的恢复数据。实验表明,该方法将演示复现率提升至100%,并在四项双手任务上将平均成功率从34%提升至75%,且对未见物体与光照干扰具有较强鲁棒性。
💡 将在线可行性验证、触觉预训练与基于真实失败的恢复数据相结合,是实现鲁棒双手接触丰富操作的一条可行闭环路径。
🔗 项目链接:https://opendrivelab.com/TAMEn
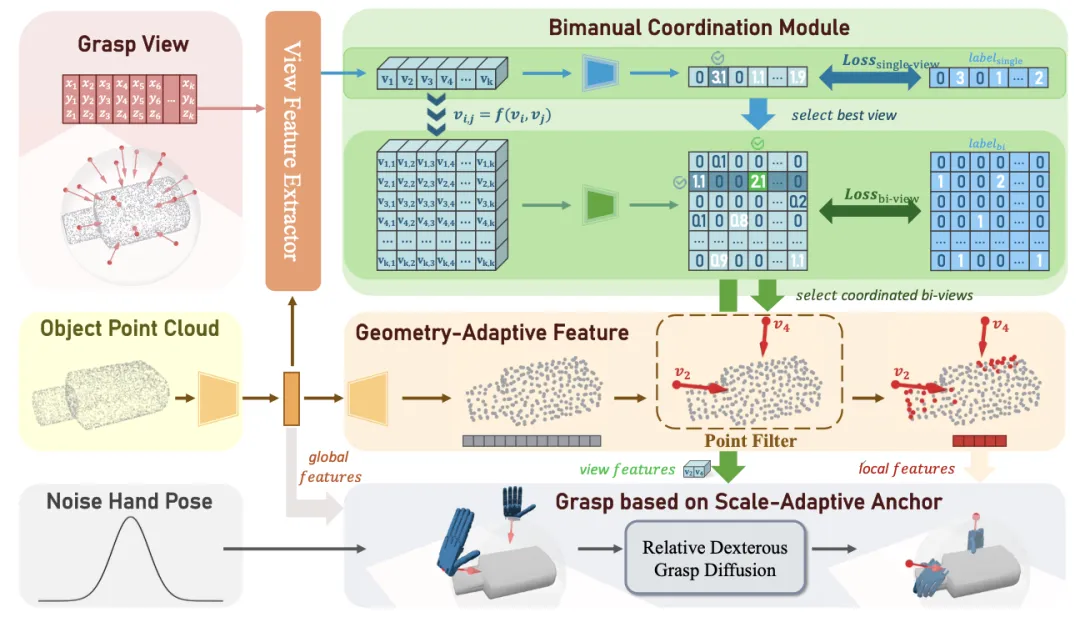
🔬 BiDexGrasp:跨几何与尺寸的协调双手灵巧抓取
📌 Bimanual Dexterous Grasp · Grasp Synthesis · Generative Model · Force Closure
✨ 构建大规模双手灵巧抓取数据集,并提出几何-尺寸自适应生成框架,实现高成功率双手抓取
📖 本文提出BiDexGrasp,包含一个大规模双手灵巧抓取数据集(涵盖6351个物体、970万抓取样本)与一个生成框架。数据合成采用“区域初始化+解耦力闭合优化”两阶段策略,效率提升30倍以上。生成框架引入双手协调模块与几何-尺寸自适应策略,在仿真与真实实验中显著优于现有方法,成功实现对大尺寸、多样几何物体的稳定双手抓取。
💡 将双手抓取解耦为区域预选与单手握持优化,是实现高效、高质量双手灵巧抓取合成的关键。
🔗 项目链接:https://frenkielm.github.io/BiDexGrasp.github.io/
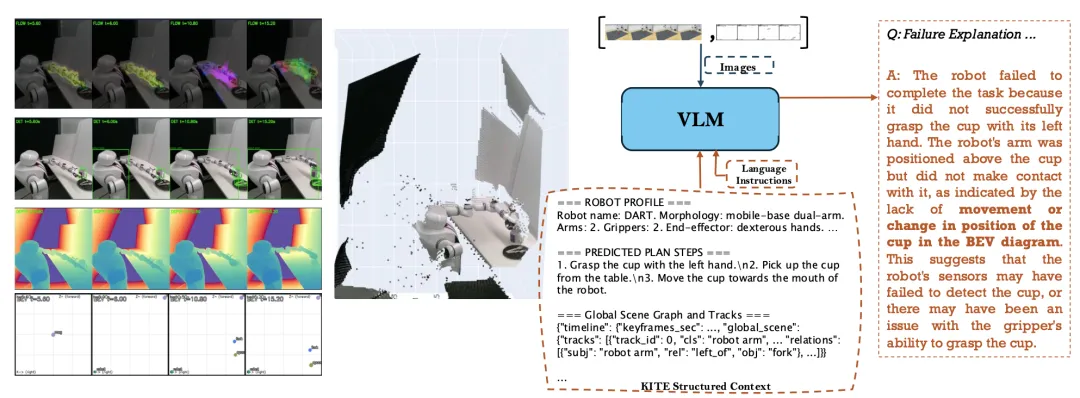
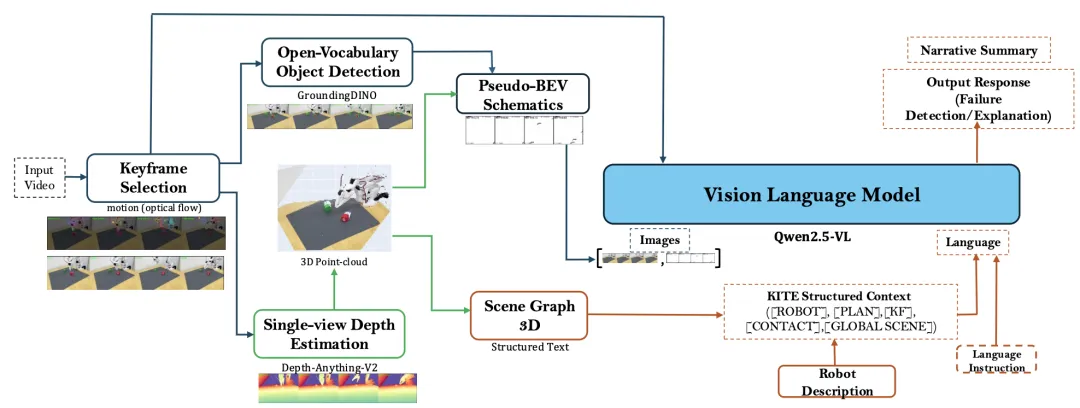
🔬KITE:基于关键帧与鸟瞰图的机器人故障解释框架
📌 Failure Analysis · Vision-Language Model · Robot Execution · Keyframe Indexing
✨ 将长时机器人执行视频压缩为关键帧与伪BEV示意图,使通用VLM能够无需训练即可进行故障检测与解释
📖 本文提出KITE,一种无需训练的前端框架,将长时机器人执行视频转化为关键帧、伪BEV布局图、场景图与机器人描述等紧凑证据,供VLM直接消费。在RoboFAC基准上,KITE+Qwen2.5-VL大幅提升故障检测、识别与定位能力,并通过QLoRA微调进一步提升解释与修正质量。在真实双臂机器人上的定性结果展示了其实际应用潜力。
💡 将密集视频蒸馏为结构化、可索引的证据链,是释放通用VLM在机器人故障分析中潜力的有效途径。
🔗 项目链接:https://m80hz.github.io/kite/
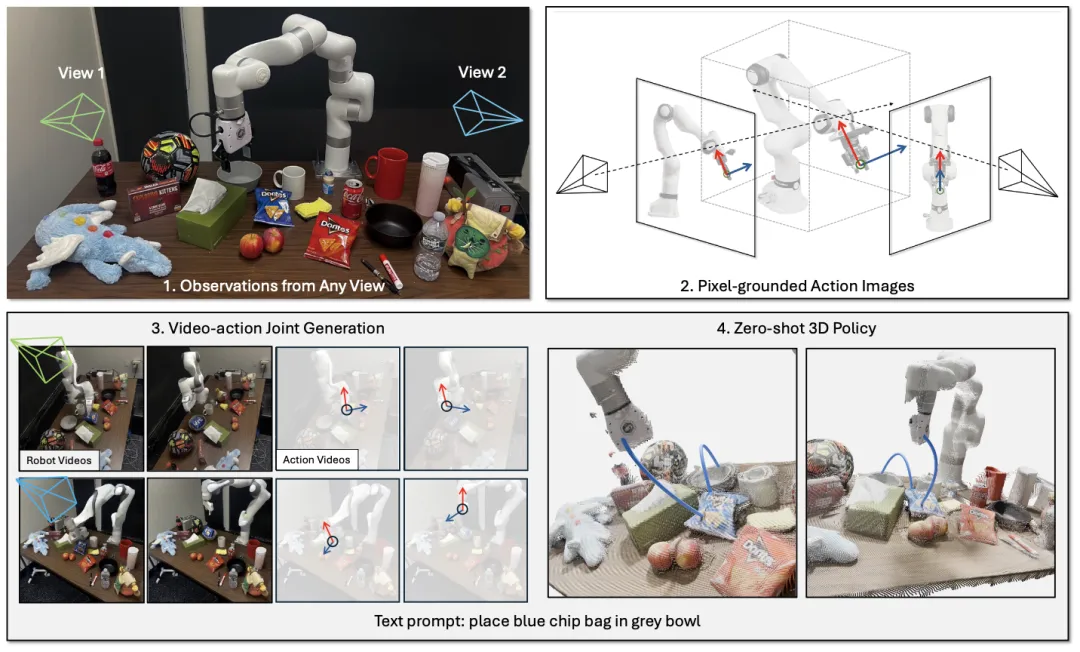
🔬 Action Images:基于多视角视频生成的端到端策略学习
📌 World Action Model · Video Generation · Policy Learning · 7-DoF Control
✨ 将7自由度机器人动作转化为像素级“动作图像”,使视频生成模型本身成为零样本策略
📖 本文提出Action Images,一种将机器人动作转化为多视角“动作图像”的世界模型框架。该方法将7自由度动作编码为像素级表征,使视频生成模型能够同时建模观察与动作,无需额外策略头即可实现零样本策略。在RLBench和真实环境评估中,该方法在零样本成功率与视频-动作联合生成质量上均优于先前方法,并支持动作条件视频生成与动作标注等多种任务。
💡 将动作“图像化”是实现视频模型与策略学习统一的一条有前景的路径,可提升策略在不同视角与 embodiment 间的泛化能力。
🔗 项目链接:https://ActionImages.github.io
🔬 Delta6:一种低成本、6自由度力觉柔性末端执行器
📌 Robotic End-effector · 6-DOF Force Sensing · Flexible Parallel Mechanism · Cost-effective Design
✨ 结合拮抗弹簧与磁编码器,实现低成本的6自由度力觉感知,并支持基于轻量化序列模型的误差补偿
📖 本文提出Delta6,一种结合拮抗弹簧与磁编码器的低成本、6自由度力觉/力矩末端执行器。该设备完全由3D打印和现成部件组装,可承受峰值力超过±14.4 N、力矩±0.33 N·m。未校准时误差为7% FS,经轻量化序列模型(LSTM、GRU、Transformer)优化后可降至3.8% FS。结合力阻抗控制,Delta6成功完成了曲面抛光与精密装配任务,验证了其鲁棒性与实用性。
💡 Delta6展示了低成本、易装配的柔性机构结合学习型补偿,可以成为传统高成本6自由度力觉传感器的有效替代方案。
🔗 项目链接:https://wings-robotics.github.io/delta6

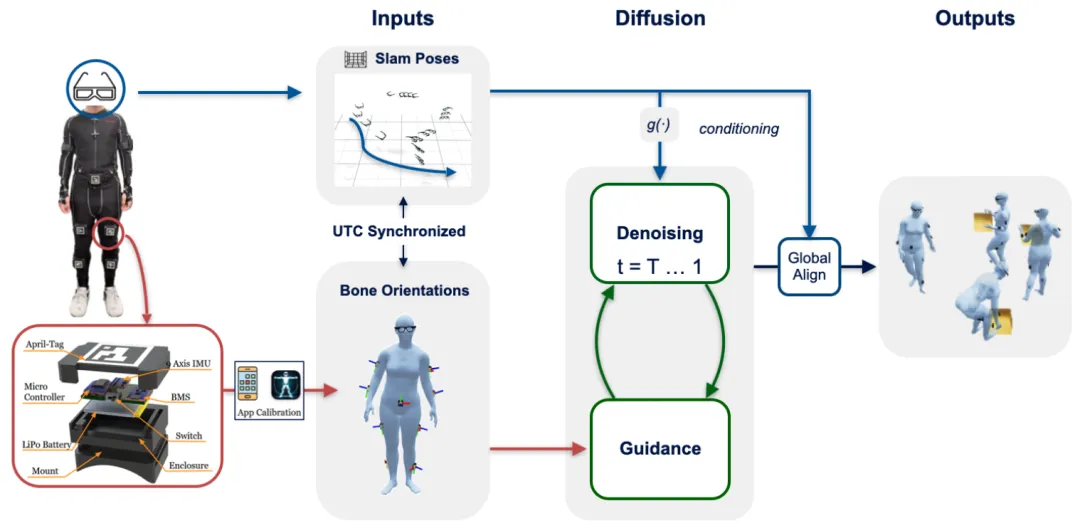
🔬 RoSHI:面向野外人类数据的机器人化套装
📌 Humanoid Learning · Motion Capture · Egocentric Vision · IMU Fusion
✨ 融合稀疏IMU与AR眼镜,实现野外全局一致的全身动捕,并成功部署至人形机器人
📖 机器人策略学习亟需野外环境下丰富、长时程的人类数据,但现有采集系统在便携性、遮挡鲁棒性与全局一致性上难以兼得。本文提出RoSHI,一种低成本、便携式混合穿戴系统,结合9个稀疏IMU与Project Aria眼镜,融合惯性数据与第一人称视觉SLAM,实现全局坐标系下的3D全身姿态、根轨迹与RGB视频同步采集。在包含多种动态活动的数据集上,RoSHI在MPJPE与关节角度误差上优于现有第一人称基线,并达到与第三人称SOTA相当的性能。此外,采集到的动作数据可成功重定向至Unitree G1人形机器人,通过强化学习训练出跳跃、鞠躬等可部署的全身控制策略。
💡 系统设计优先考虑“可靠性”与“长时程稳定性”,而非单帧精度——这正是人形机器人策略学习对数据接口的核心需求。
🔗 项目链接:https://roshi-mocap.github.io/

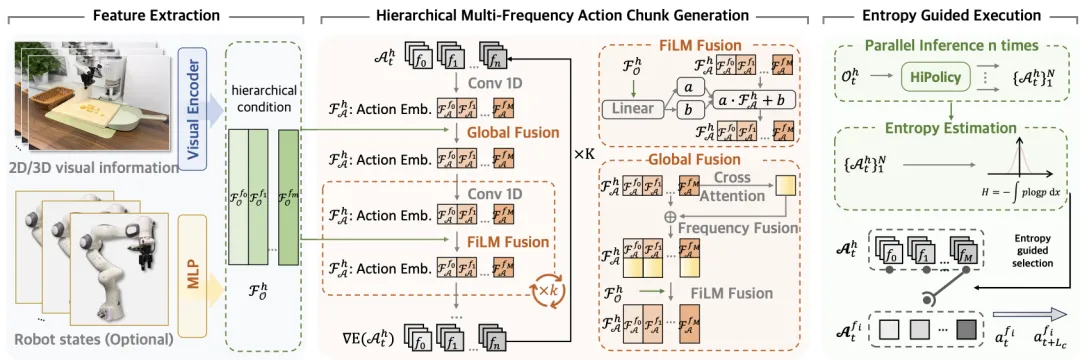
🔬 HiPolicy:用于策略学习的分层多频率动作分块框架
📌 Imitation Learning · Hierarchical Policy · Action Chunking · Diffusion Policy
✨ 联合预测多频率动作序列,并基于动作熵自适应选择执行频率,兼顾长视野依赖与精细闭环控制
📖 机器人模仿学习中,固定频率的动作分块方法难以同时建模长时程依赖与实现精细的闭环控制。受人类运动控制多频特性启发,本文提出HiPolicy,一种分层多频率动作分块框架,同时预测低频(粗粒度高层规划)与高频(精粒度反应式调整)动作序列。通过分层特征提取与融合,并引入基于动作熵的自适应执行机制,策略可根据当前动作不确定性动态选择执行频率。在RoboTwin等仿真基准及真实Franka Panda操作任务中,HiPolicy可无缝集成至Diffusion Policy与3D Diffusion Policy,显著提升任务成功率(最高+42%)与执行效率(最高+25%)。
💡 让机器人像人类一样“分频协作”——低频定方向,高频微操作,熵值决定何时切换,这是实现长程灵巧操作的关键结构。
🔗 项目链接:https://hipolicy.github.io
一般的星球时间限制是1年,我们这个进去就是终身进去了,不会有时间限制。还有可以结合更多志同道合的朋友
