 夜雨聆风
夜雨聆风





009.什么是模型参数?举例说明

模型参数是机器学习模型在训练过程中从数据中学习并内部存储的变量,用于定义模型的具体行为和决策方式。这些参数是模型“知识”的核心载体,其数值通过优化算法(如梯度下降)自动调整,以最小化预测误差。
1、核心概念解析
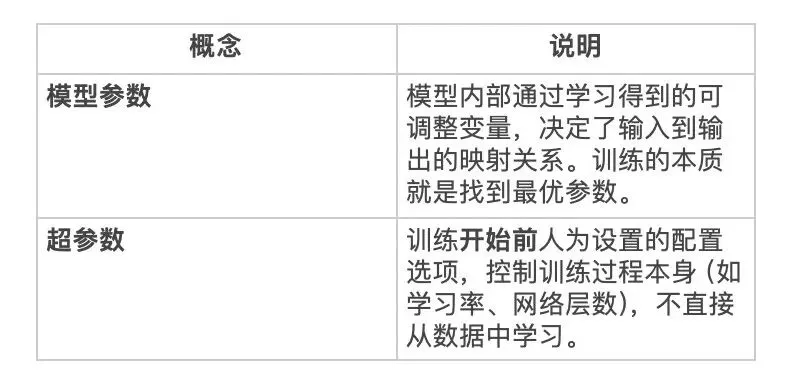
简单比喻:构建一个“披萨烤箱”(模型)。
- 超参数= 你手动设定的烤箱“温度”和“烘烤时间”。
- 模型参数= 烤箱内部通过多次烘烤自动学会的“热量分布规律”——这是它自己掌握的“知识”。
2、不同类型模型中的参数举例
例1:线性回归模型
- 模型公式:y = w * x + b
- 参数意义:
- w(权重):表示特征 x对输出 y的影响程度。例如在“房价预测模型”中,w可能表示“房屋面积每增加1平米,房价增加多少元”。
- b(偏置):表示基础值。如上例中,可能代表“零面积时的基础房价”(实际是模型拟合的截距)。
- 训练过程:通过大量房屋面积和价格的数据,算法自动调整 w和 b,使预测房价最接近真实房价。
例2:神经网络(以图像分类为例)
- 参数构成:
- 权重:神经元之间的连接强度。例如,在识别猫的模型中,某些权重可能对应“检测边缘”、“识别胡须”的特征。
- 偏置:允许神经元在输入为零时也能被激活的偏移量。
- 直观理解:一个用于识别手写数字的简单神经网络可能有数万个甚至更多参数,它们共同构成一个复杂的“特征检测网络”,能识别从简单笔画到复杂数字组合的模式。
例3:大语言模型(如GPT系列)
- 参数规模:GPT-3有1750亿个参数。
- 参数作用:
-
这些参数分布在海量的“注意力头”和前馈网络中,编码了语言的语法、语义、常识甚至推理模式。 -
例如,某些参数组合可能专门用于学习“主谓一致”规则,另一些则可能存储“巴黎是法国首都”这类事实关联。 - 关键特性:参数数量巨大且高度互联,使得模型具备强大的泛化和生成能力,但可解释性很低,常被称为“黑箱”。

3、参数如何被学习与影响模型
3.1学习过程模型初始参数通常随机初始化。训练时:
-
计算当前参数下的预测结果与真实标签的误差。 -
通过反向传播计算误差对每个参数的梯度(即“调整方向”)。 -
用优化器沿梯度反方向微调参数,逐步降低误差。
3.2参数量与模型能力的关系
- 不足:参数太少(模型太简单)可能导致“欠拟合”,无法捕捉数据中的复杂模式。
- 过剩:参数太多(模型太复杂)可能导致“过拟合”,即完美记忆训练数据但泛化到新数据时性能差。
- 平衡:需要在模型容量与数据量之间寻求最佳匹配。
4、重要注意事项
- 参数 ≠ 记忆的数据:参数并不直接存储训练数据,而是学习数据中抽象的统计规律和模式。例如,语言模型的参数中不会完整存储某本书的原文,但能学会该书作者的写作风格。
- 参数共享:在卷积神经网络中,同一组参数(卷积核)会滑动扫描整个图像,极大减少参数量并提升效率,这是其能高效处理图像的关键。
- 参数微调:在迁移学习中,可在一个大型预训练模型(如BERT)的基础上,用特定领域的小数据微调其部分参数,使其快速适应新任务(如法律文书分析)。
结语
模型参数是AI模型从数据中沉淀下来的“数字化的经验与知识”。理解参数的本质,有助于我们更好地设计、训练、解释和优化模型。从简单的线性模型到千亿参数的大语言模型,参数的演进史本身就是AI技术从“手工特征”走向“自动学习抽象表示”的能力跃迁史。
