 夜雨聆风
夜雨聆风





AI 时代,数据治理到底应该怎么做?

导读本文主题为 AI 时代,数据治理到底应该怎么做?
1. 正在发生什么:数据的消费主体正在发生根本性变化
2. AI 时代传统数据治理的五大变革
3. 三大治理策略:语义丰富、全模态覆盖、AI 可消费
4. 落地中的常见挑战
5. Dataphin 的视角:我们正在做什么过去
以 Quick BI智能小Q为例,它每天帮业务人员回答成百上千个数据问题——查销售额、看流失率、分析转化漏斗,已经大幅提升了一线团队获取数据的效率。但在实际使用中,我们也观察到一个普遍现象:业务人员问“上个月的客户流失率是多少“,小 Q 迅速返回了结果,可不同部门对“流失“的定义本就不同——是 30 天未登录,还是合同到期未续约?
问“北区销售额“,小 Q 查到了一张字段名叫 amt 的表,但 amt 究竟是含税金额、退款后金额、还是成交金额,底层数据本身就没有给出清晰的标注。

问题不在 AI 的能力,而在它所依赖的数据基础。当口径不统一、语义不清晰,再强的智能体也难以发挥更大的业务价值。
这不是 AI 的问题。这是数据治理的问题。
更准确地说,这是传统数据治理体系在 AI 时代集体失效的缩影。
当下,模型开源即可用,算力按需即可买——AI 的基础设施正在快速商品化。对企业而言,真正决定 AI 能否落地赋能业务的,已不再是“用哪个模型“,而是“喂给模型的数据是否可信、可用、可治理“。谁能从散落在各系统中的复杂业务资料里,沉淀出口径统一、语义清晰的高质量数据资产,谁就拥有了驱动精准决策的差异化壁垒。数据治理能力,正在成为智能化竞争中真正的主动权。
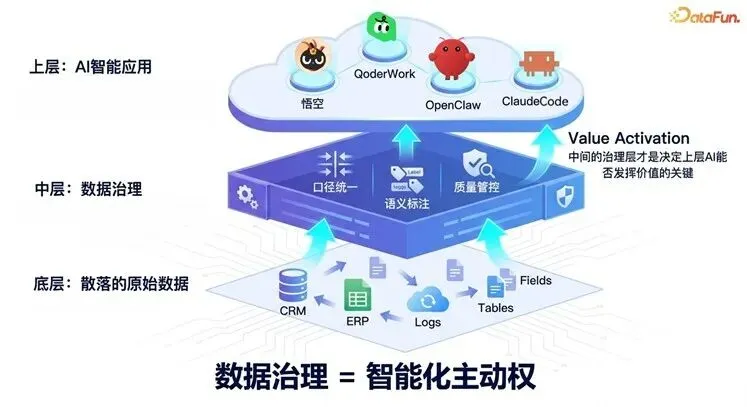
01
正在发生什么:数据的消费主体正在发生根本性变化
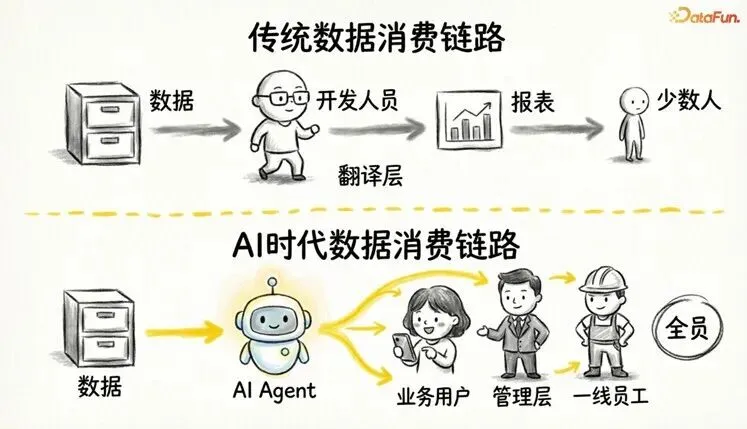
过去十年,企业数据治理体系是围绕一个基本假设设计的——数据的消费者是人。
链条很清晰:开发人员写 SQL,分析师做报表,业务人员看 Dashboard。数据从底层到用户之间,有一层“翻译层“——开发人员。他们理解数据的含义,知道哪些字段有坑,在加工过程中修正瑕疵、美化输出。
但现在,一个新的“物种“闯入了这条链路:AI Agent。
业务用户不再需要打开报表系统,而是直接用自然语言提问:“上个月华东区 Top 10 客户的复购率是多少?” AI Agent 接到问题后,自主解析意图,查询底层数据,组装结果返回。
数据的消费主体,正在从“少数技术人员“变成“AI Agent + 全体业务人员“。Gartner 在 2025 年报告中预测,到 2028 年,企业内超过 33% 的业务应用交互中将嵌入 AI Agent 驱动;IDC 的调研同样显示,已有45% 的亚太区企业开始在数据分析场景中试点 AI Agent。

所以本质上是数据消费主体变了,整个治理体系的假设就不成立了。
02
AI 时代传统数据治理的五大变革
从传统 BI 到 AI Agent,数据治理面临五个维度的深刻变革。理解这五个变化,是重新设计治理体系的起点。
1. 变化一:消费资源——从“人消费报表“到“人直接消费数据“
过去,普通用户接触到的是报表、Dashboard——经过开发人员精心加工的“成品“。数据中有些瑕疵?没关系,开发人员在加工过程中可以修正、美化。数据在到达用户之前,有一层“翻译层“做质量兜底。
现在,AI Agent 绕过了这层“翻译层“,直接查询底层数据。字段命名不规范?Agent 理解不了。数据有空值?Agent 可能返回错误结论。
从“开发兜底“到“数据裸奔“——原来可以被容忍的数据瑕疵,现在变成了直面用户的错误答案。数据质量的标准必须从“开发可用“提升到“终端用户可用“:完整性、准确性、时效性都需要大幅度拉高。
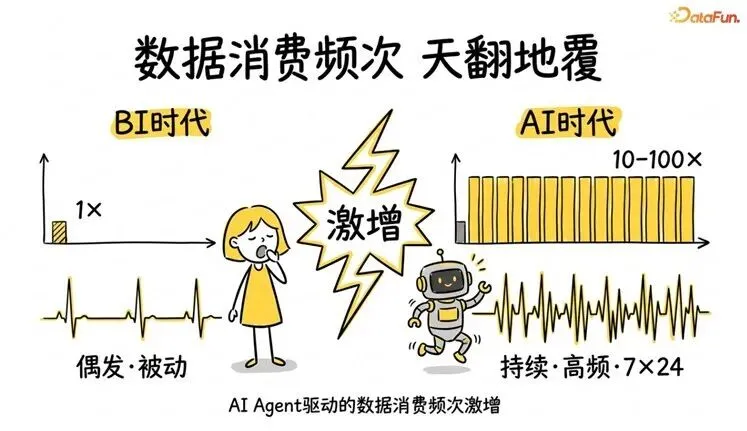
2. 变化二:消费频次——从被动低频到主动高频
传统模式下,数据消费是被动的、低频的:有需求了才去看报表,最高频的场景不过是定时刷新 Dashboard。
AI Agent 不一样。它是 7×24 小时不间断运行的。一个企业可3能同时有上百个 Agent 在跑——客服 Agent 查客户画像,销售 Agent 分析成交趋势,运营 Agent 监控实时指标。数据查询的频次可能是过去的10 到 100 倍。
从“偶发被动“到“持续高频“——数据服务化成为刚需。你需要实时/近实时的数据 API,需要 SLA 管理(即服务等级协议,定义数据接口的可用性、响应时间等承诺)、限流、监控、版本管理。数据资产需要像微服务一样被运维。
3. 变化三:语义要求——从“人能懂“到“AI 能懂“
这是最容易被忽视、但影响最深远的变化。
你的数仓里有一张表叫 dwd_order_di,里面有个字段叫 amt。开发团队约定俗成,知道这是“每日订单明细表的金额字段“。这个约定从没写进元数据——因为“大家都知道“。
但 AI Agent 不知道。它看到 amt,不确定这是交易金额、退款金额,还是含税金额。没有完整的元数据描述,AI 就像一个入职第一天的新员工,面对一堆缩写和行话,完全懵了。
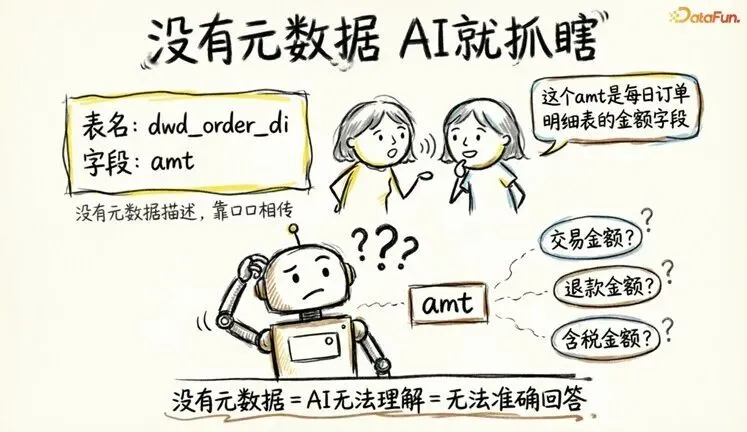
从“口口相传“到“机器可理解“——治理的核心从“管住数据“升级为“让数据自解释“。这需要四项关键能力:
-
命名规范化:表名、字段名清晰自解释
-
描述完整化:每个表/字段/指标都有完整业务含义与计算口径
-
关系显性化:表关联、指标派生关系显式管理
-
语义标准化:同一业务概念(如“活跃用户“)跨系统统一定义,消除二义性,让每个数据资产都有“AI 能看懂的说明书“
这四项不再是“锦上添花“的能力,而是 AI 能否正确工作的前提条件。
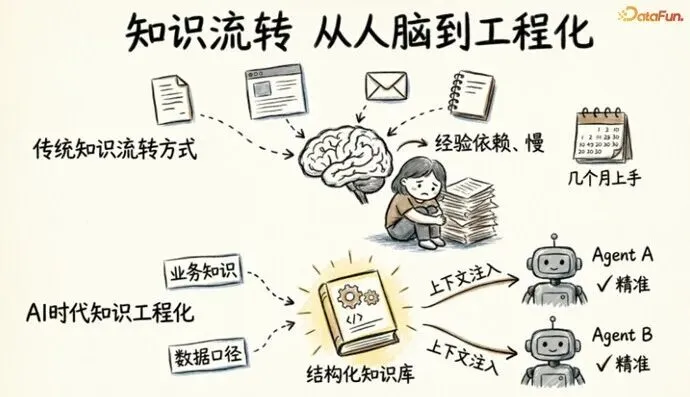
4. 变化四:知识库——从“人脑存储“到“知识工程化“
在传统数据团队中,大量的业务知识散落在文档、Wiki、邮件甚至微信群聊里。
“这个指标怎么算?问老张。”
“那个口径有特殊逻辑,看看飞书上有没有记录。“
这套靠人脑记忆和经验传递的体系勉强能运转——代价是新人需要几个月才能上手。
AI Agent 没有“几个月“的试用期去慢慢学习。它每次查询都需要精准的知识上下文:分析“客户流失率“,需要知道流失的定义是什么、不同行业的计算口径有什么差异、同比环比的基准期怎么算。
从“人脑记忆“到“知识工程化“——业务知识需要像数据资产一样被盘点、分类、版本管理。从“给人看的文档“变成“可被 AI 消费的结构化知识“。
治理要求也随之升级:知识资产需要系统化管理,每个数据资产需要关联口径说明和使用注意事项,知识需要以结构化形式精准提供给大模型上下文。
5. 变化五:数据模态——从结构化数据到全模态数据
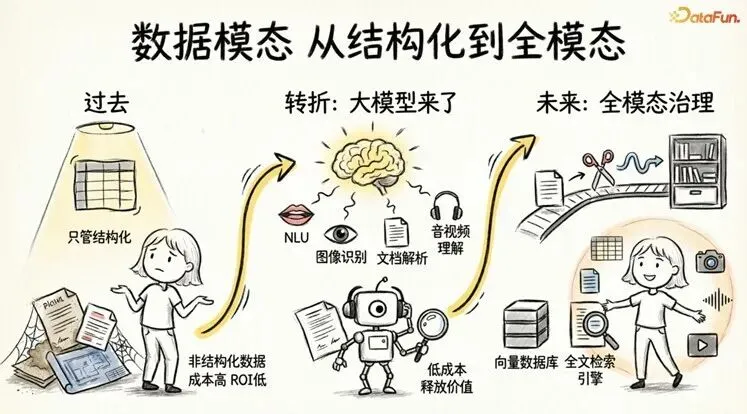
过去十几年,数据治理的重心一直在结构化数据上:数据库表、数仓模型、指标体系。企业里同样大量存在的非结构化数据——合同、研究报告、会议纪要、产品图纸,往往因为提取成本太高、ROI 算不过来,基本被排除在治理范围之外。
大模型改变了这个现状。NLU(自然语言理解)、图像识别、文档解析、音视频理解……大模型让非结构化数据的价值可以被低成本释放。你的 Agent 可以直接理解一份合同的关键条款,从会议录音中提取行动项,解析工程图纸上的参数,费结构化数据的价值可低成本释放。
从“只管结构化“到“全模态覆盖“——数据治理范围必须扩展。文档、图片、音视频都需要纳入元数据管理体系,需要经历解析、切片、向量化(即将文本或图片转化为数学向量,以便 AI 进行语义搜索和匹配)、索引的全链路处理。存储层也需要从传统数据库扩展到向量数据库与全文检索引擎。
03
三大治理策略:语义丰富、全模态覆盖、AI 可消费
面对这五大变化,企业的数据治理升级可以围绕三个核心方向展开。
1. 策略一:丰富语义——让 AI 能自主理解每一个数据资产
核心目标:每张表、每个字段、每个指标都有完整的、AI 可消费的语义描述。
具体做法:
-
完整元数据描述:为核心业务表的每个字段添加中文名、业务含义、数据类型、取值范围、计算口径说明。优先从高频使用的 Top 100 张表开始,逐步覆盖全量。
-
清晰命名规范:建立统一的命名规范(如 dwd/dws/ads 分层前缀 + 业务域 + 实体 + 时间粒度),对存量不规范命名进行清理和别名映射。
-
指标体系标准化:用统一语义层定义全公司的指标口径——让“销售额“在市场部、财务部、管理层只有一个含义。
-
显式关系图谱建设:显式管理表之间的关联关系、指标的派生关系,让AI 能自主“导航“数据资产间的逻辑链路。
预期效果:以某零售企业的实践为参照,在完成 200+ 核心指标的语义标注后,AI Agent 的查询准确率从约 60% 提升到了 85% 以上,业务人员自助取数的比例从不足 20% 提升到了 55%。
2. 策略二:全模态覆盖——释放非结构化数据的沉睡价值
核心目标:将文档、图片、音视频等非结构化数据纳入统一治理体系,让 AI Agent 能够跨越数据模态获取完整信息。
具体做法:
-
治理范围扩展:将合同、研报、会议纪要、产品手册等高价值非结构化资产纳入元数据管理,建立统一的分类和标签体系。
-
加工链路建设:构建“解析→切片→向量化→索引“的标准化处理流水线,让非结构化数据变成 AI 可检索、可理解的知识片段。
-
跨模态元数据体系:在结构化数据和非结构化数据之间建立关联——比如一份客户合同关联到该客户在 CRM 中的结构化数据,一份产品技术文档关联到对应的产品指标。
预期效果:企业的数据资产覆盖面从“只有结构化表“扩展到“结构化 +非结构化“,AI Agent 回答问题时不仅能查数据库里的数字,还能引用文档中的背景信息,答案的完整度和可信度显著提升,关键的非结构化数据也能沉淀并应用。
3. 策略三:AI 可消费——让数据和知识可以被 Agent 直接理解和调用
核心目标:将数据资产从“被动存储“转变为“主动服务“,让 AI Agent 能像调用 API 一样安全、高效地消费数据和知识。
具体做法:
-
数据服务化:将核心数据资产封装为标准化 API,配备服务等级协议(SLA)、访问控制、限流和监控能力。数据资产需要像微服务一样被运维——有版本管理、灰度发布、健康检查。
-
知识工程化:将散落在各处的业务知识结构化管理,建立知识与数据资产的关联关系。每个指标关联其计算口径、使用注意事项、适用场景说明。
-
上下文注入:支持将结构化的知识上下文自动注入大模型的推理过程。Agent 发出一个查询请求,不仅能拿到数据,还能拿到理解这些数据所需的全部背景知识。
预期效果:AI Agent 从“能查数据但不理解数据“进化为“既能查数据又能理解数据“。回答不再是冷冰冰的数字,而是带有业务语境的完整洞察。
04
落地中的常见挑战
坦率地说,这条路并不轻松。在实际推进中,企业通常会面临几个现实挑战。
第一,“数据债务“的清理成本。大多数企业的数仓积累了数年甚至十年以上的历史数据,命名混乱、口径不清的表可能成千上万。全量治理不现实,关键是建立优先级——先治理 AI Agent 最常用的核心表,用“最小可用集“快速见效,再逐步扩展覆盖面。
第二,组织协同的难度。 语义治理不是数据团队一个部门能完成的事。“销售额“的口径统一需要市场、财务、管理层共同参与。这需要自上而下的推动力,也需要一个所有人都能看到、都愿意用的协作平台。
第三,非结构化数据治理的技术成熟度。 全模态治理目前仍处于快速发展期,文档解析和向量检索的准确性在不同行业、不同文档类型上表现参差不齐。建议从标准化程度高的文档类型(如合同、财报)入手,逐步积累经验后再扩展到更复杂的模态。
第四,ROI 的验证周期。 治理本身不直接产生收入,短期内业务部门可能感知不到变化。建议选择 1-2 个高频使用的 AI Agent 场景作为试点(如智能客服问答、管理层数据助手),用 Agent 回答准确率的提升作为可量化的 ROI 指标,快速证明治理的价值。
05
Dataphin 的视角:我们正在做什么
作为瓴羊旗下的智能数据平台,Dataphin 从 2018 年起就在践行数据治理工程化的理念。OneModel 方法论让数据建模和指标管理有了标准化框架,为企业提供了一套从业务过程到数据模型的规范化路径;全域数据融合架构解决了多源异构数据的统一治理问题;DataOps(数据工程流水线)实践让治理从“运动式“变成了“流水线“——不再是每年集中清理一次,而是嵌入日常开发流程的自动化动作。
面向 AI 时代,Dataphin 正在三个方面持续迭代:
一是强化语义层建设,让元数据描述不仅“人能懂“,更“AI 能懂“。通过统一语义标准和结构化描述,让 Agent 无需“猜“就能理解每个数据资产的含义。
二是扩展非结构化数据的全生命周期管理能力,覆盖从文档解析、内容切片、向量化到索引检索的全链路。让散落在企业各处的文档、图片、音视频不再是数据孤岛,而是可被 AI 消费的知识资产。
三是开放数据服务化接口,让企业的数据资产可以被 AI Agent 安全、高效地调用,支持服务等级管理、访问控制和上下文注入。
我们很清楚,这些能力仍在快速演进中,尤其是非结构化数据治理和大模型上下文注入,还有大量的工程问题需要解决。但方向是确定的:数据治理的终局不是“管住数据“,而是“释放数据“。 在 AI 时代,释放的对象从人扩展到了 AI Agent,释放的范围从结构化数据扩展到了全模态数据。
让数据为 AI 而治理,让 AI 为业务而服务。
如果你也在思考这个方向,我们整理了一份《AI 时代数据治理白皮书》,扫码即可领取,同时可预约 Dataphin 1v1 场景诊断,一起探索从“人用数据“到“AI 理解数据“的治理新范式。


往期推荐

点个在看你最好看
SPRING HAS ARRIVED
