 夜雨聆风
夜雨聆风





AI代码生成会如何影响软件生态
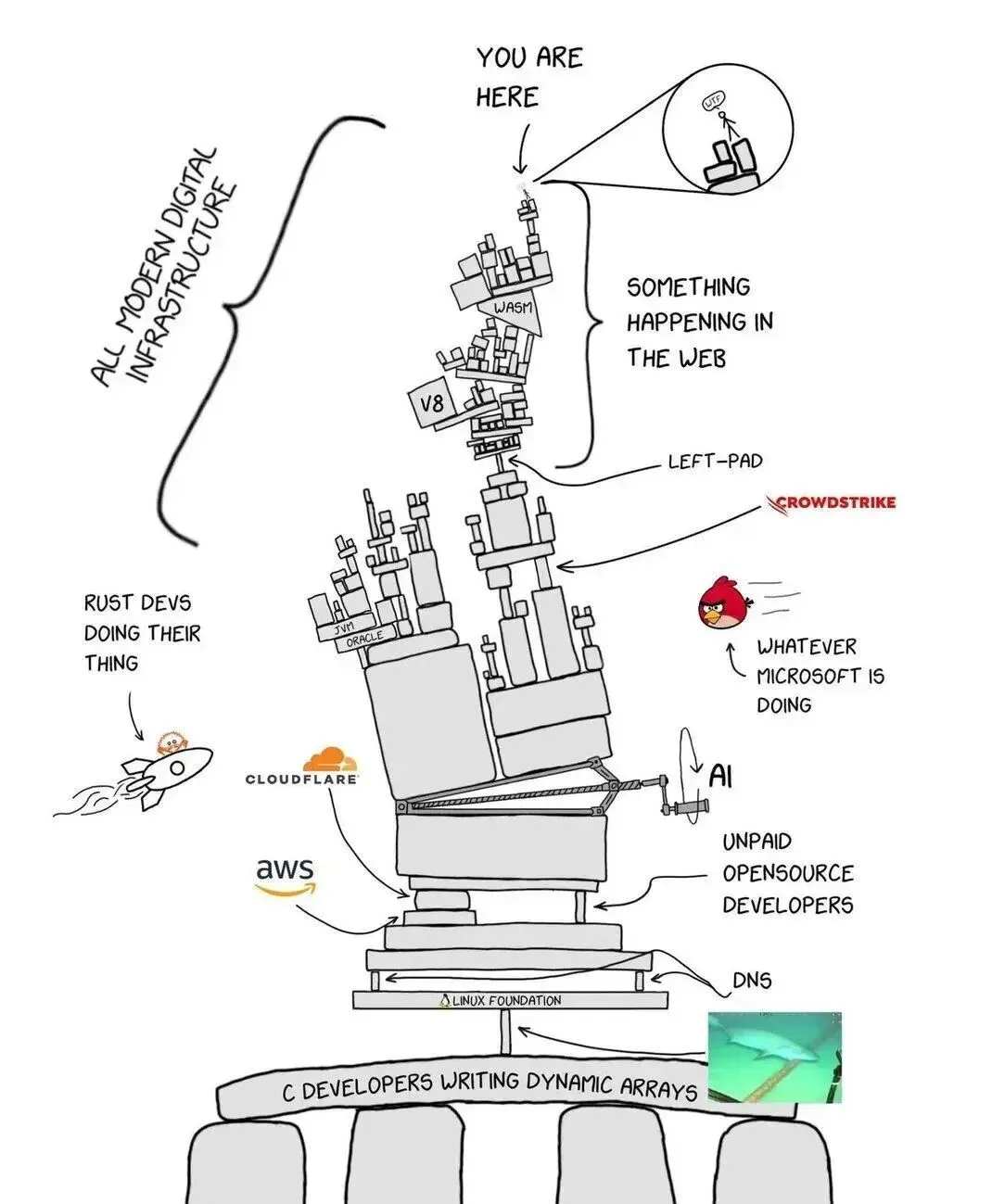
 。是这样:
。是这样:
Anthropic 显然清楚,“AI 参与开源贡献”在很多社区依然是敏感话题,所以它的做法不是提高透明度,而是先把身份隐藏起来。在这种前提下,一个更值得追问的问题是:他们内部究竟已经对多少开源代码库造成了多大破坏。
Tina,公众号:InfoQClaude Code 泄露的代码里,处处写着:这家公司人品不行

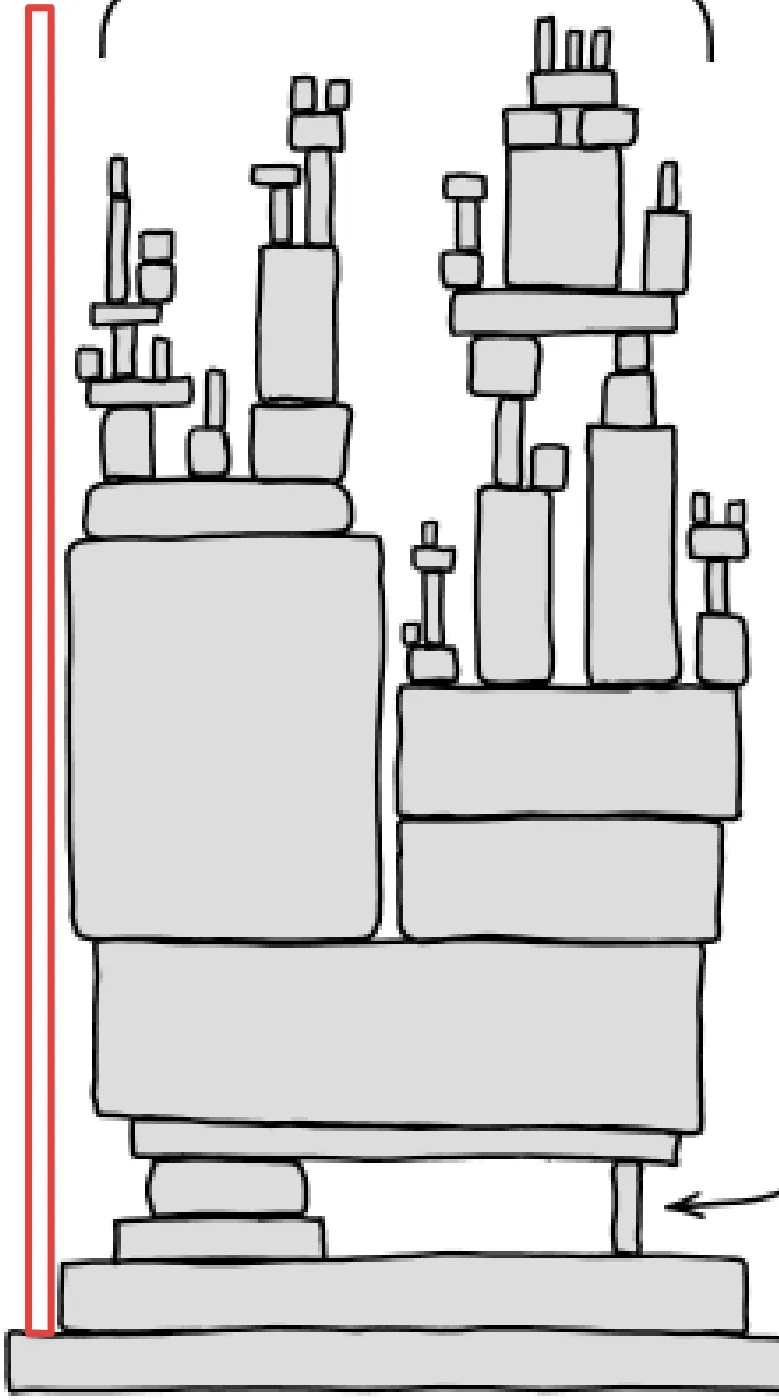
 :
:
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. (调试的难度是初次编写代码的两倍。因此,如果你以尽可能巧妙的方式编写代码,按定义来说,你就不够聪明来调试它。)
Kernighan’s Law
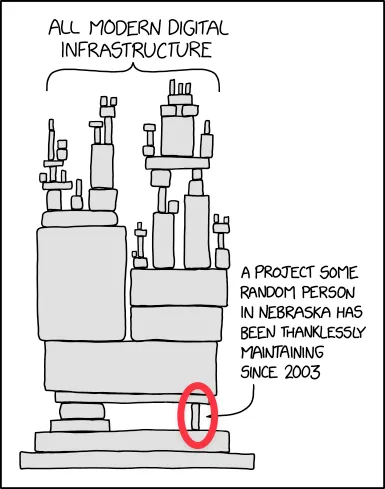
[1] SWE-Bench Pro
https://labs.scale.com/leaderboard/swe_bench_pro_public