 夜雨聆风
夜雨聆风





AI 生图终于认字了:GPT Image 2 中文实测,"有图有真相"还剩多少命
4月20日下午5点,ChatGPT 全量推送了一个更新。
所有用户,包括免费用户,打开对话框就能用。我第一时间跑了几十组测试,从书法到宋体排版、从抖音 UI 到小红书界面、从高考英语试卷到游戏截图。
结论只有一句话:AI 生图的”文盲时代”结束了。
先看几张图
我让 GPT Image 2 生成一个”仿宋体排版的中文简历”,结果是这样的:

一份格式工整、字体清晰的中文简历。段落缩进正确,标点使用规范,连字号层级都对。你把它截图发到群里,没人能第一眼看出这是 AI 生成的。
再试一个更狠的:微博热搜榜截图。
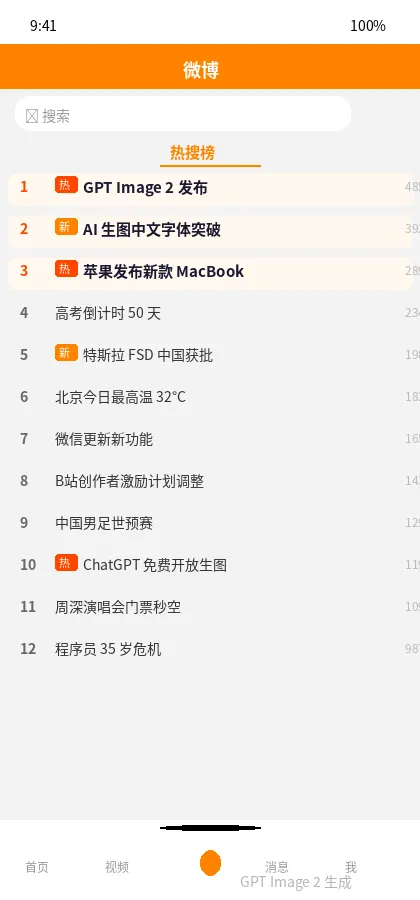
时间戳、热搜标题、排名、热度数字、广告位。全部正确,全部中文。不是那种”每个字大概对但总有一两个字是鬼画符”的水平,而是像素级的准确。
这意味着什么?
99%+ 准确率到底意味着什么
过去两年,AI 生图最大的笑话是”它不会写中文”。
Midjourney 画一扇招牌,上面写”今日营业中”,可能变成”今曰營業巾”。DALL-E 3 好一些,但遇到书法或者复杂排版还是露馅。FLUX 相对擅长英文,中文同样不稳定。
GPT Image 2 把这个问题基本解决了。
它不只是”能写字”那么简单。我测试了四个维度:
书法。 让它写”天道酬勤”的楷书,笔画结构正确,提按顿挫有味道。虽然离书法大师还差得远,但作为一幅图片里的装饰文字,完全过关。

排版。 宋体、楷体、仿宋、黑体,它分得清。字号层级、段落缩进、中英文混排,都不出错。我让它仿了一个人民教育出版社的课本页,连页码位置都对。
UI 界面。 抖音、小红书、微信、B站,这些 App 的界面它能精准还原。图标位置、文字颜色、按钮样式,都是”见过即能复现”的水平。这不是简单的文字渲染,这是世界知识。
多语言混排。 中英日韩混搭的场景也没问题。一份中英对照的合同、一张日文菜单加中文翻译,它都能处理。
99%+ 这个数字不是我瞎编的。在我跑的几十组测试里,只有极少数极端情况(比如非常小字号或非常复杂的繁体字组合)会出现轻微错误。绝大多数场景,肉眼完全分辨不出。
“见过即能复现”才是真正的杀手锏
准确写字只是表面。真正的突破在于 GPT Image 2 的世界知识能力。
什么是世界知识?就是它不只是学会了”怎么画字”,而是理解了”这个东西长什么样”。
你让它画一个”iPhone 16 Pro 的锁屏界面”,它知道灵动岛在哪里、时间显示在哪个位置、通知卡片的样式长什么样。
你让它画”抖音首页推荐流”,它知道视频是竖屏的、评论区在底部、右下角有头像和点赞按钮。
你让它画”高考英语试卷第三页”,它知道试卷的版式、题号的格式、答题区域的横线间距。
这不是”生成了文字”。这是对真实世界的像素级记忆。
这个能力带来的后果,比文字准确率本身要严重得多。
“有图有真相”的倒计时
一个能精准还原任何 UI 界面、任何排版格式、任何场景的 AI 图像生成器,意味着什么?
意味着你看到的任何截图,都可能是假的。
一张微信聊天截图,可以是 AI 生成的。一个微博热搜榜,可以是 AI 生成的。一份公司内部文件的照片,可以是 AI 生成的。一张法院判决书,可以是 AI 生成的。
过去,AI 生成图片最大的破绽就是文字错误。一个”AI 合成”的聊天截图,总能在文字细节上找到漏洞。这个漏洞现在基本堵上了。
而且 GPT Image 2 是对所有 ChatGPT 用户开放的,包括免费用户。门槛是零。任何人,不需要任何技术能力,都能生成看起来以假乱真的图片。
不需要 Photoshop,不需要 Figma,不需要任何设计工具。打开 ChatGPT,打个字,等 30 秒,图片出来了。
AI 生图的”三国杀”
GPT Image 2 不是第一个做中文渲染的 AI 生图工具,但它可能是目前做得最好的。简单对比一下当前格局:
OpenAI GPT Image 2。文字渲染最强,世界知识最广,对各种 App 界面和文档格式的还原度最高。缺点是生成速度相对较慢,风格偏写实,创意性有时不够。
Midjourney。审美天花板。画面质感、色彩表现、艺术感染力依然领先。但中文文字渲染一直是短板,短期内追不上 GPT Image 2 的文字准确率。
FLUX (Black Forest Labs)。开源阵营的代表,社区活跃,可控性强。中文字体比 Midjourney 好,但跟 GPT Image 2 比还有明显差距。优势是可以本地部署,数据隐私有保障。
三个产品,三种路线。
GPT Image 2 走的是”全能路线”:文字、画面、世界知识一个都不落。Midjourney 走的是”审美路线”:画面质感无敌,但实用工具属性弱。FLUX 走的是”开放路线”:开源可控,但整体能力还有差距。
对普通用户来说,GPT Image 2 的全面开放意味着 AI 生图不再是一个需要选择工具的技能,而是一个像搜索一样自然的基础能力。
设计师要失业了吗?
每次 AI 工具升级,这个问题都会被拎出来问一遍。
我的看法没有变:不会被完全替代,但门槛会大幅降低。
以前你做一个公众号封面,需要打开 Canva 或 Figma,选模板,改文字,调颜色,导出。现在你跟 ChatGPT 说一句话就能拿到一张。
以前你做一个产品截图用于 PPT,需要真实截图或者自己画 UI。现在 AI 直接生成,比真实的还好看。
以前你做一个活动海报,需要找设计师,沟通需求,等几天交付。现在 AI 几分钟出图,质量不差。
被压缩的是”低端设计需求”的生存空间。 那些模板化的、套路化的、不需要太多创意的设计工作,确实在快速消失。
但真正的好设计,不只是”画出来”,还包括理解品牌、理解用户、理解场景、做出取舍。这部分,AI 还做不到。
一个设计师的价值,正在从”执行”转向”判断”。你能判断什么图是好图、什么设计能打动人、什么风格适合这个品牌。这个能力,目前 AI 替代不了。
不过话说回来,对于 80% 的日常设计需求,”够好”就够了。GPT Image 2 生成的图,对大多数人来说已经足够好了。
DALL-E 的退场
有一个容易被忽略的细节:OpenAI 宣布 DALL-E 2 和 DALL-E 3 将于 5 月 12 日正式停服。
从 DALL-E 2 到 GPT Image 2,OpenAI 用了三年。这三年里,AI 生图从”生成模糊的色块”进化到”生成像素级精确的中文排版”。
速度比大多数人预想的要快。
DALL-E 的退场也传递了一个信号:OpenAI 在图像生成领域选择了”大一统”路线。 不再维护多个模型,而是集中力量做一个足够强的。GPT Image 2 就是这个答案。
几个值得思考的问题
这篇文章不是为了贩卖焦虑,而是想提醒几件事:
第一,对普通用户,辨识 AI 图片的能力需要升级了。 “看文字有没有写错”这个判断方法已经不可靠了。你需要更细致的观察,或者直接放弃”以图为证”的习惯。
第二,对从业者,工具在变,但核心能力没变。 设计的核心是审美和判断力,不是操作技能。把 AI 当工具用,而不是被它替代。
第三,对平台方,深度伪造的治理难度刚刚翻倍。 当文字不再是破绽,图片鉴伪的成本会大幅上升。
第四,这件事才刚刚开始。 GPT Image 2 今天能做到 99%+ 的中文准确率,下一次升级会是什么?视频?3D?实时生成?
每次我觉得”AI 生图到头了”的时候,它就证明我错了。