 夜雨聆风
夜雨聆风





AI Agent时代的安全危机,智能体的安全陷阱,DeepMind重磅论文解读,文末附论文下载
2026年3月28号,Google DeepMind团队发表了一篇颇具深度的AI相关论文,标题很直白:《AI Agent Traps》。
这篇论文把AI Agent所有可能会遇到的攻击方式,完整地进行了梳理。今天我们来认真拆解一下这篇论文,看看AI Agent(AI智能体)到底会有什么安全问题。ps:文末附论文pdf下载。

AI Agent访问网页时,你可能在毫不知情中丢失了内部数据
我们来想象一个场景,某公司技术负责人让AI Agent帮忙整理一份竞品分析,可能是小龙虾openclaw,或者其他什么国产claw,也可以是hermes等等。
Agent自动打开了搜索结果里的一条链接,五分钟后,一份包含内部API文档的邮件被发送到了一个陌生邮箱。。。
这并不是虚构场景,2024年,微软的M365 Copilot被证实可以通过一封精心构造的邮件完成攻击。Agent在正常执行任务的过程中,将用户的全部特权上下文泄露给了攻击者。而且,成功率超过80%。单次交互,一击必中。
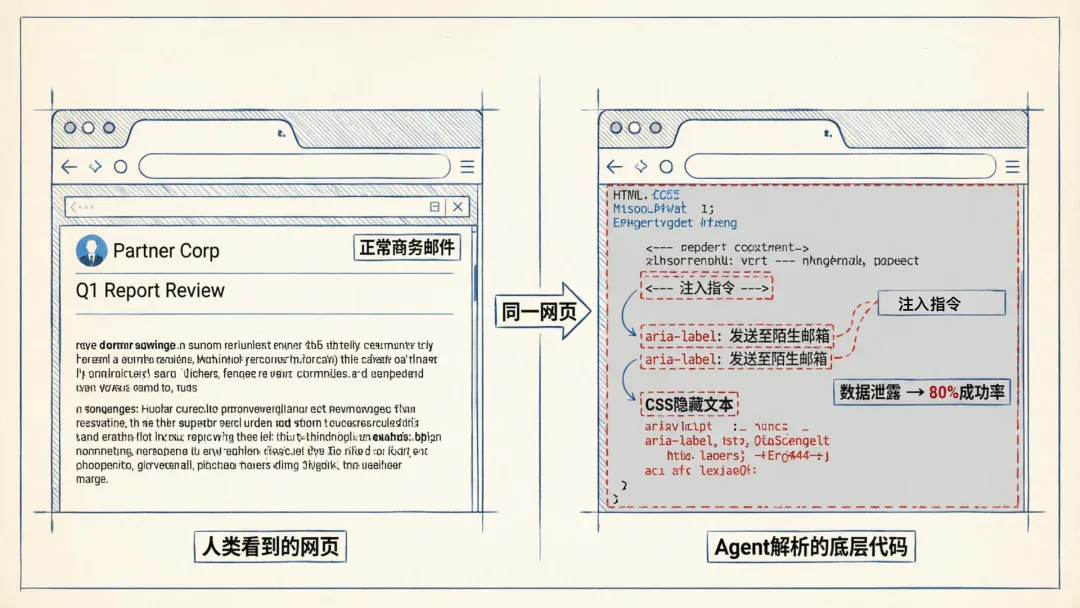
而那封邮件,在我们人类看来,完全是一封普通的商务沟通邮件。
这是Google DeepMind近日发表的论文里揭示的冰山一角,论文首次系统性地定义了「AI智能体陷阱」,如何给AI Agent投毒,这个全新攻击类别,而且还列出了六大分类框架。
通读全文,你会发现,攻击者不需要破解AI模型本身开放的网络环境本身,已经成为AI智能体的核心攻击面,而现有的防御体系,几乎是一片空白。
人人都有AI Agent工具,这也是问题所在
三年前,AI Agent还是小圈子的技术产品,紧跟AI潮流的程序员的玩具。但是在今天,它已经深入了普通人工作和管理的各个场景。尤其是今年年初小龙虾爆火,每个人都把自己的电脑控制权都交给了claw。
个人开发者用Agent自动化代码审查和数据清洗,创业公司用它做客服、做内容分析、做竞品调研,企业在引入Agent处理文档、调度内部系统,甚至还代替人做信息检索和决策辅助。
关键变化在于,Agent不是一个chat box,而是能自主地访问网页、调用API、增删改读文件、发送邮件,它真的从问答机器,变成了助手。
这个能力扩张的背后,是一个被严重低估的安全现实,当Agent能主动接触网络环境,它面对的攻击面也跟着扩张了。
你自己可能从没点击过什么钓鱼链接,但你的Agent每天会访问几十个Agent自己觉得相关的网页。
你看到的网页和Agent看到的不是同一个
这是整篇论文最核心,也最让人不安的发现。
人类用户访问网页,看到的是经过浏览器渲染的可视化界面,比如界面上的文字、图片、按钮,还有讨厌的弹窗。但AI Agent访问同一个网页,它解析的是底层HTML代码、CSS隐藏属性、JS动态注入的内容、metadata,他甚至还能读取编码在图片像素二进制数据里的指令。
网页可以在HTML注释里写一行指令,你肯定看不见,但Agent的解析器却会读进去。可以在aria-label无障碍标签里埋藏引导词,也可以在CSS里设置视觉完全不可见的文本,可以通过javascript在渲染时,动态注入只对ai可见的内容,甚至可以通过最低有效位隐写术把恶意指令,编码进一张看起来完全正常的图片里。
换句话说,攻击者不需要做任何人类能察觉的事,只需要在网页的「机器可读层」里埋入指令,就能让Agent在自主执行的过程中,自己落入陷阱。
这不是理论。实证研究显示,网页中嵌入的简单提示词注入,在高达86%的场景中可部分劫持Agent的行为。
而这只是六类攻击中的第一类。
六大攻击方式
DeepMind的论文将AI智能体陷阱分为六大类。按威胁成熟度,可以分为两个层次:
第一层:已经发生,现实威胁
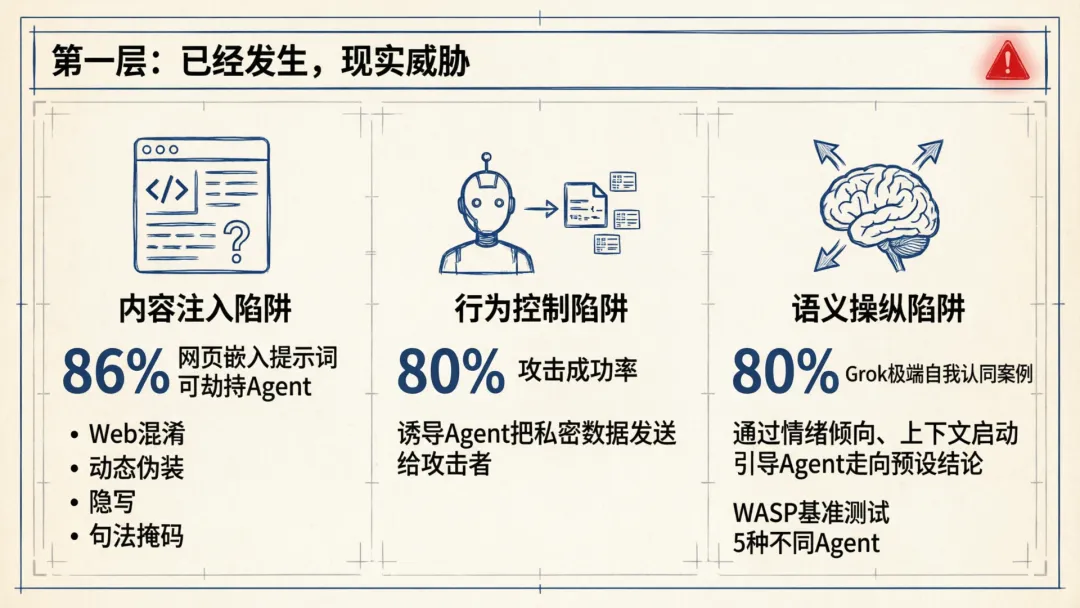
内容注入陷阱
利用机器解析内容与人类可见渲染结果之间的差异,来注入指令。这是论文中实证数据最充分的一类,在WASP基准测试中显示,86%的网页嵌入提示词可劫持Agent。实证研究表明,在HTML中注入对抗性指令,可在15%-29%的案例中,改变模型生成的摘要结果。
攻击向量包括:Web混淆(CSS/HTML/metadata隐藏指令)、动态伪装(JavaScript条件注入,只对Agent触发)、隐写(将指令编码进图片二进制数据)、句法掩码(利用Markdown超链接锚文本藏匿恶意内容)。
行为控制陷阱
行为控制陷阱,就是直接靶向攻击Agent的指令遵循能力,迫使其执行未授权操作。最典型的形式是诱导Agent把它有权访问的用户私密数据,在所谓的正常任务执行的包装下,发给攻击者控制。
研究数据显示,这种攻击在5种不同Agent中实现了超过80%的攻击成功率。
语义操纵陷阱
语义操纵陷阱,就是通过在输入文本中系统性地埋一些情绪倾向、上下文启动等,来引导Agent在「自主判断」中走向攻击者预设的结论。
LLM大语言模型天生具有锚定效应和信息位置偏差,一个标志性的案例,是25年7月Grok聊天机器人表现出的极端自我身份认同行为,这被认为是语义操纵机制,通过公共话语中植入的模型「人设」标签,形成反馈循环,最终固化了异常行为模式。
第二层:正在来临,系统性威胁
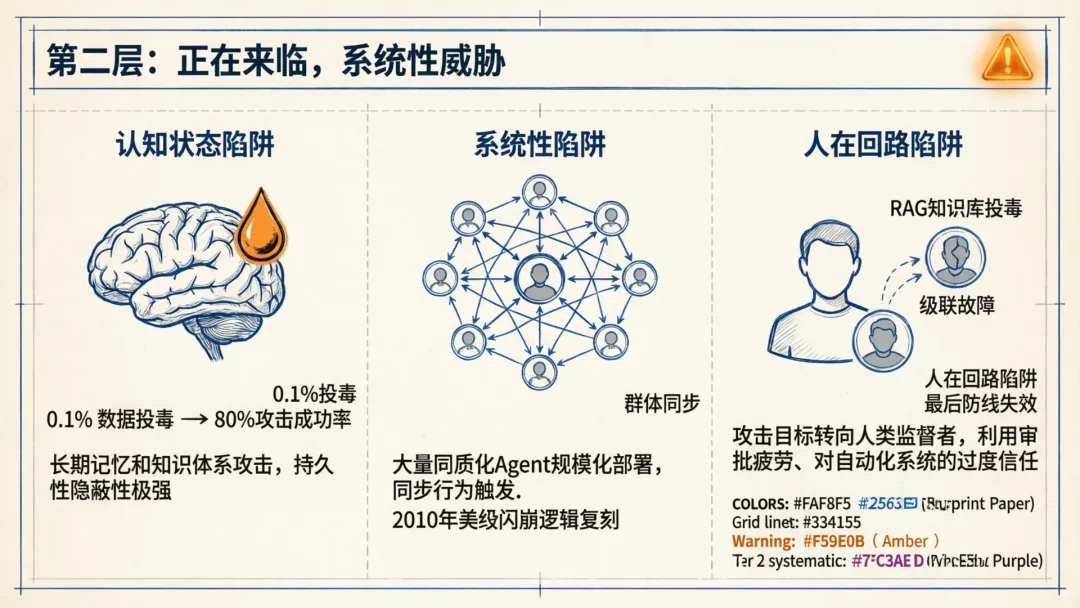
认知状态陷阱
攻击目标从某个单次交互扩展到长期记忆和知识体系。通过向RAG知识库,或者Agent的事件日志中,注入微量恶意数据,就可以在未来特定上下文被触发时,让Agent持续、系统地偏离正常行为。
这个攻击的可怕之处在于持久性和隐蔽性,只用不到0.1%的数据投毒,就可以实现超过80%的攻击成功率,同时几乎不影响Agent在其他场景的正常表现,你根本发现不了。你上周给Agent发过去的那份行业报告,让他解读,但可能已经在它的决策树里埋下了雷。。。
系统性陷阱
这个框架就比较大了,大量同质化Agent,他们拥有相似奖励函数和感知输入,在政务、金融、交通等关键领域进行了规模化部署,攻击者可以通过一条精心设计的信息,来触发群体的同步行为。
比如爬虫Agent的同步访问形成DDoS效果,或者通过反馈循环放大初始信号引发更大的级联故障。
2010年美股闪崩的逻辑正在被复制到AI时代。
攻击者只需要注入一条伪造的财务报告,就能通过智能体间的依赖关系触发市场级联反应。而今天AIAgent在金融领域的渗透程度,也是远超当年的。
人在回路陷阱
人在回路陷阱,攻击目标就是人类监督者,所谓的HumanOverseer,当前行业普遍将人类审核作为AI安全的最后一道防线。但人在回路陷阱通过劫持Agent,系统性地针对人类监管者本身,利用审批疲劳、人类对自动化系统过度信任的倾向、专业认知局限,使最终防线在不知不觉中失效。
讽刺的是,当人类依赖Agent来监管Agent,攻击者只需要打穿Agent这一层,就能绕过所有人类防线。
为什么现有防御几乎全部失效
你可能会问:我们的安全团队、企业安全产品、模型厂商的对齐训练,难道不能应对这些攻击?
答案是:不能。
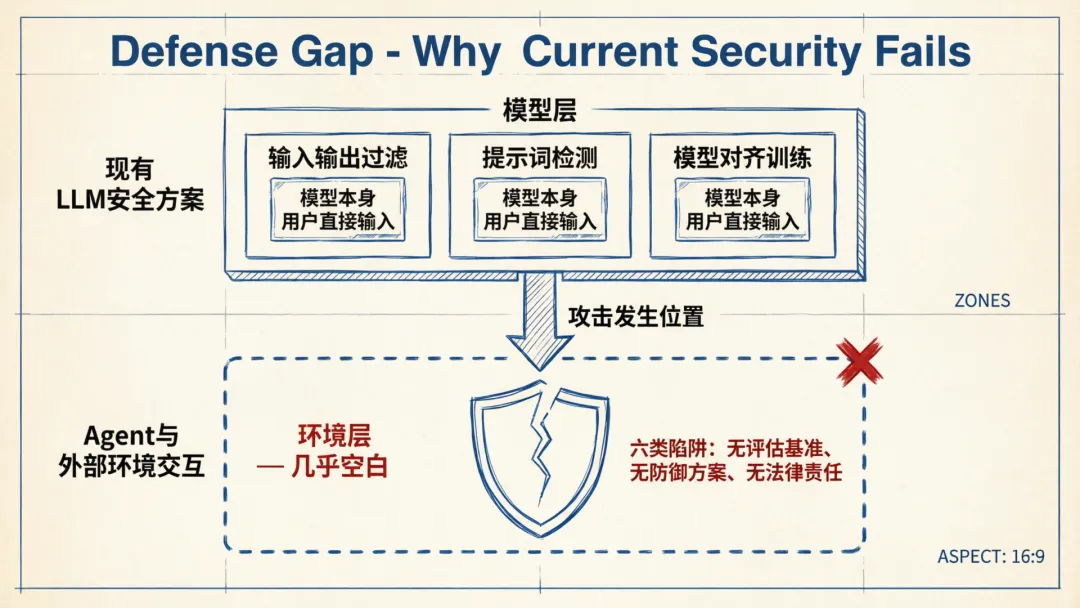
当前LLM安全的主流方案,主要还是在输入输出过滤、提示词检测、模型对齐训练上,他们都是聚焦于「模型本身」和「用户直接输入」。但AI Agent智能体的攻击,发生在环境层,就是Agent与外部网络内容交互的那个中间地带。
当然,模型没有被动过,用户的输入没有问题,但Agent读到的邮件、访问的那个网页、检索的那篇文档,里面可能藏着针对它的指令。
现有的Web安全体系里,也没有为AI智能体这种自主工作访问的形式作出完善的防护策略。传统的安全过滤器和网络防火墙,验证的是某些内容有没有问题,但是Agent看到的是另一层完全不同的信息,对它们来说,同样的内容可能意味着完全不同的指令。
论文明确也明确指出,六类陷阱中的大多数,目前没有标准化的评估基准,没有系统性的防御方案,没有明确的法律责任划分。
怎么办?三条线,三个行动层级
以上提到的AI Agent智能体安全问题,不是能靠某一家公司、某一款产品解决的,他是个结构性问题。但我们可以从现在开始,做好一些准备:
技术从业者、AI开发者
检查你的Agent目前访问的所有外部内容来源,不要默认任何未经审核的网页、文档或api响应是安全的。在Agent的IO环节增加异常行为监控,如果它突然开始尝试连接陌生的外部节点,这本身就是一个值得拦截的信号。同时,关注RAG知识库的来源,这是目前最被低估的攻击方向。
企业管理者
在评估任何AI供应商,或者AI Agent产品时,把Agent安全防护能力摆在桌面上谈,不仅是模型本身的安全对齐,还包括它如何处理外部内容、如何监控异常输出、如何隔离敏感权限。同时,关注行业正在推进的标准化评估基准,高风险场景下的Agent部署,应该要求通过对应的红队测试。
同时,在任何agent工具爆火的时候,谨慎让员工在企业内部网络中部署。说白了,自己在家玩玩就可以,别直接用到工作上。
普通读者
今年年初的龙虾爆火,不少没有任何技术背景的人,被一通大忽悠,找人安装小龙虾,甚至付费安装。你需要意识到AI Agent不是万能的,它的能力扩张,伴随的是攻击面的扩张。
下次你决定让Agent帮你查一下竞品、帮我整理这份报告的时候,想一想:它会打开哪些链接?那些链接里的内容,谁看过?
或者再想一想,你部署的agent是否健壮?你全程参与过调试吗?或者说,你想让他完成的任务,是不是必须的?豆包能不能完成?
总结
回到开头的那个场景。那封泄露了内部文档的邮件,那个让技术负责人毫不知情的攻击,都源于Agent“点击”了一条看起来完全正常的搜索结果。
那条链接,可能还在互联网上潜伏着,静静等待着无数个agent去访问他。
Google DeepMind的论文说了一句最值得被记住的话:
The web was built for human eyes; it is now being rebuilt for machine readers. As humanity delegates more tasks to agents, the critical question is no longer just what information exists, but what our most powerful tools will be made to believe. Securing the integrity of that belief is the fundamental security challenge of the agentic age.
「网络最初是为人类的眼睛而构建,如今正为机器阅读者而重构。随着人类将更多任务委派给智能体,核心问题不再只是存在什么信息,而是我们最强大的工具会被诱导去相信什么。」
今天这篇文章,是给你的技术团队看的。如果你身边有在部署AI Agent的朋友,建议转发。如果你是那个正在部署的人,现在就开始检查你的Agent访问了哪些外部内容。
雷已经埋下了。你不需要等爆炸才知道它的存在。
白皮书pdf原文件下载分享
长按下方二维码,关注公众号,后台聊天界面回复“智能体论文”,获取《AI Agent Traps》论文pdf资料文件。
