 夜雨聆风
夜雨聆风





AI agent 最大的问题,可能不是模型不够强,而是根本没脑子

这件事为什么突然又被拿出来聊
前段时间,Karpathy 发了一篇东西,讨论度很高。
大意其实很简单。
与其每次问问题都临时从一堆资料里翻,不如先把资料整理成一个持续维护的知识库,以后都在这上面用。
这个想法大家其实不陌生,很多人也一直在探索。
但真正做出来,而且能接进日常工作流的,很少。
因为嘴上说做知识库是一回事,真让 agent 能长期用、能持续更新、还能越用越顺手,是另一回事。
我自己很早也折腾过类似的东西,也看过不少别人做的方案。
最后的感觉都差不多。
思路没人反对,但很多实现不是太简陋,就是太难用,要么就是定制得太狠,只适合高度定制化的场景。
为什么这件事一直没做好
为什么这件事一直没做好。
有一个很常见的情况。
你让 agent 帮你处理事情,这次做完了,内容就留在聊天记录里。
下次再遇到类似的问题,它不记得上次发生过什么,又从头开始。
你手里明明已经有不少东西,markdown 笔记、整理过的资料、以前做过的判断,但真到要用的时候,还是得自己去翻,翻完再重新喂给 agent。
就像一个助理,每天上班都是第一天来,所有背景都得再交代一遍。
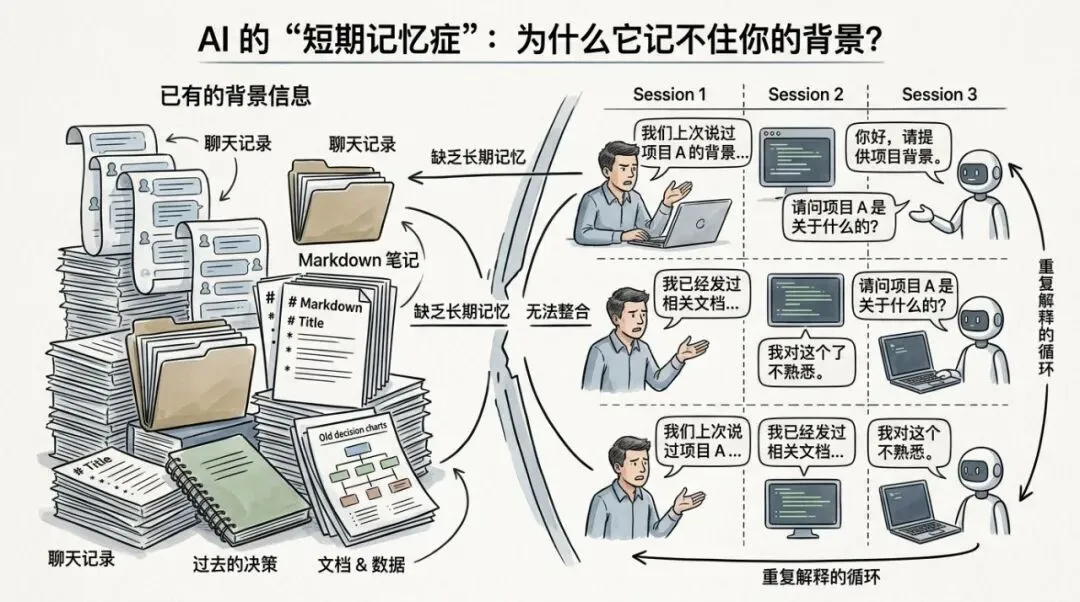
大家都知道这是个问题。
只是过去一直没有一个真正像样的方案,把这件事整体做通。
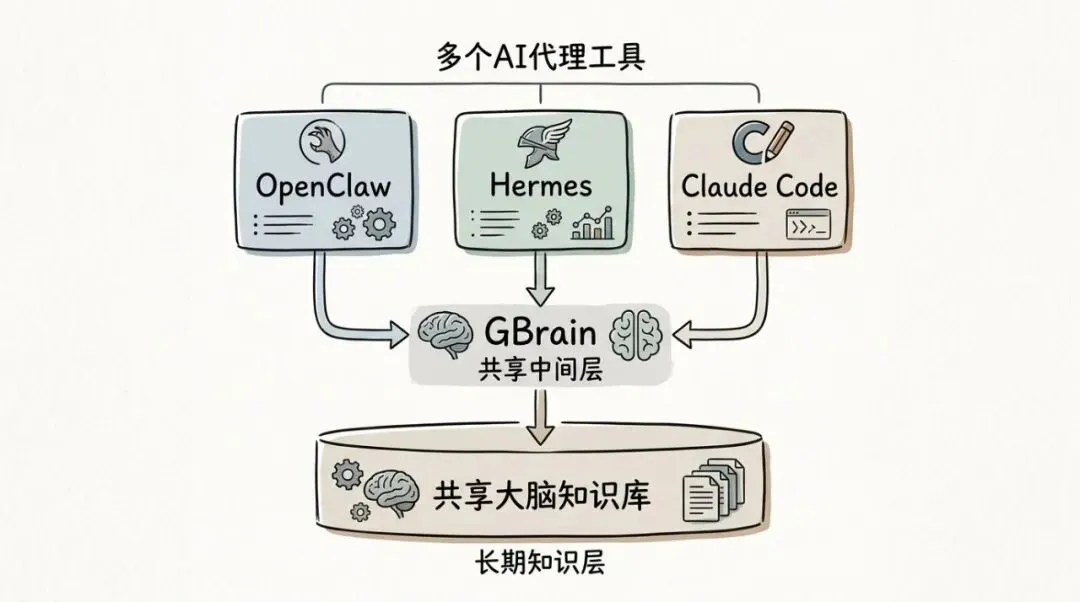
GBrain
然后我看到 Garry Tan 开了个叫 GBrain 的项目。
项目地址:https://github.com/garrytan/gbrain
他在仓库首页写得很直接,给你健忘的agent换个大脑。
我之前用过他做的 GStack,而且用得非常高频,Garry哥出品,必属精品。
看完这个项目,第一感觉是,这东西跟以前那批确实不太一样。
他更完整,更容易接入自己的agent。接入后,就像自己原装的。
GBrain 想做的事,如果用最直白的话说,有点类似装了魂骨,完全不影响行动,却又能加攻加防,嘎嘎猛。
不是那种只能记住你喜欢什么风格、平时说话偏好是什么的小记忆。
他把你的笔记、资料、人物信息、公司信息、项目背景、时间变化,全都放进一个能持续更新的脑子里,以后 agent 问事、做事、查资料,都先从这里过一遍。
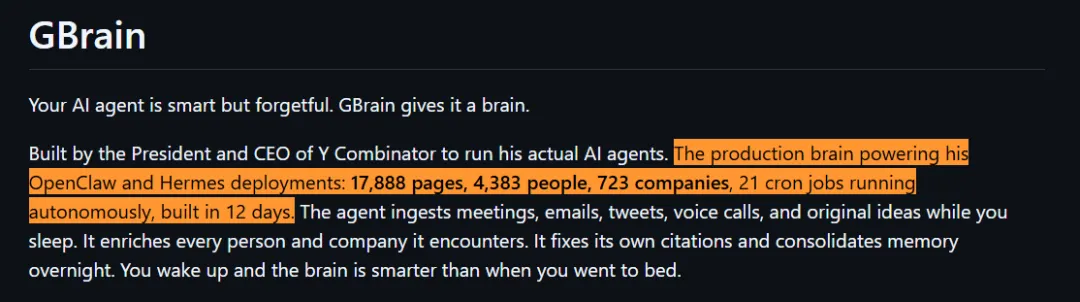
官方首页给的数据很夸张。
Garry Tan 自己那套部署里,已经有 17888 个页面、4383 个人、723 家公司,还有 21 个定时任务在后台自己跑。
你睡觉的时候,它会继续吃进会议、邮件、推文、语音通话和你自己的想法,然后在后台补关系、修引用、整理记忆。第二天起来,这个脑子比前一天更聪明。
我觉得它最有价值的五个点
我看完之后,觉得它最有价值的地方,不是一个功能,而是下面这五件事。
1. 它不是把资料堆起来给你搜
它会自己把里面的人和事连成一个立体网络,有点类似 obsidian 的关系图谱。
2. 它不是单纯存历史
它会先把你现在能下的结论整理出来,再把前面的变化过程留在后面。
3. 它会自己看出来谁重要
不用你一开始就手动给每个人建档。
4. 它把很多后台杂活单独拿出来跑
不交给 AI 临场发挥,所以更稳,也更省。
5. 你修过一次的问题,它会尽量留下来
下次别再犯一遍。
举几个具体的例子。
先说第一个点
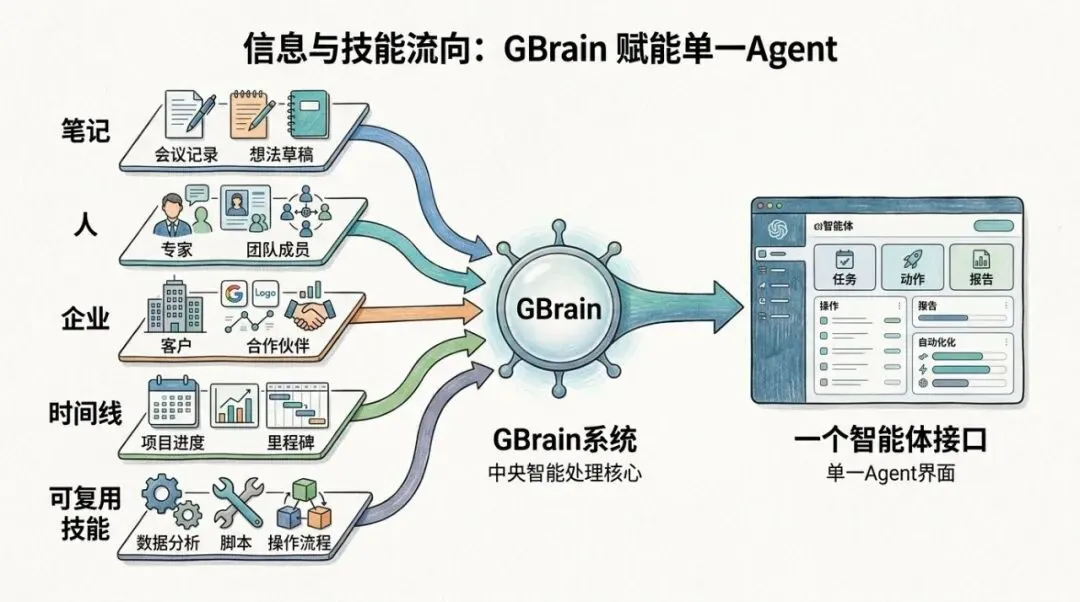
你对接了几十家供应商。
有些是同一个中间商介绍的,有些工厂之间其实互相认识,还有些人虽然名字不同,背后其实是一家公司的人。
正常情况下,这些关系你自己都不一定记得清楚。
普通搜索工具能做的,是你搜某个词,然后把包含这个词的几篇笔记翻出来。
GBrain 想做的不是这件事。
它在每次写入页面的时候,会自动提取实体引用,再建出带类型的关系,比如谁参加过会议、谁在哪家公司、谁投过哪个公司、谁创立了什么项目。
所以你以后问的就不只是这几个字在哪出现过,而是这家厂是谁介绍的、这个人和哪家公司有关系、这条线是怎么串起来的。
官方 README 甚至直接举了这种问题,像 who works at Acme AI,或者 what did Bob invest in this quarter,这类问题单靠向量搜索其实是答不到的,因为它要走的是关系,不是相似文本。
这个就很厉害了,因为我们有时候想到的不是具体的词,而是大概意思。
他不是把搜索做得更花,是真的开始把有关联的事物和数据连到一起,让你能够以点及面。
第二个点为什么有意思
第二个让我觉得有意思的点,是它不是把历史一股脑堆在那里。
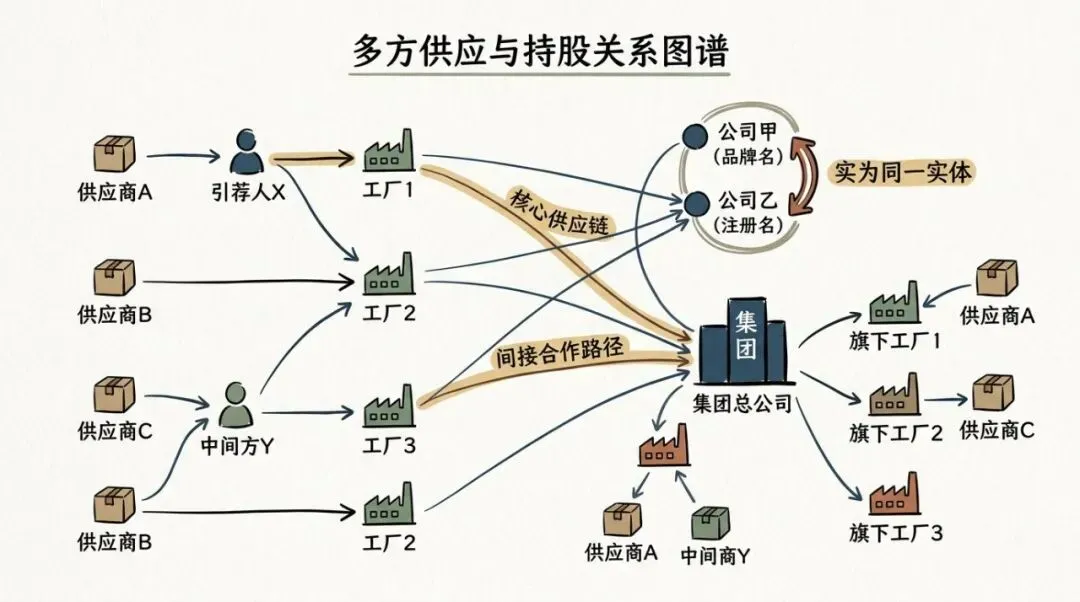
它把每个页面分成了两层。
上面是你现在最好的判断,下面是按时间排下来的变化记录,让你能追溯来时路。
官方把上面这层叫 compiled truth,意思不是最终真理,而是你到这一刻为止,整理出来的最好版本。
下面那层时间线不是装饰,它是证据。
你现在为什么会得出这个结论,中间改过几次,为什么改,原始依据在哪,全部都留着。
这个设计很适合那种会反复变化的事。
比如你某个月停掉了一个品类,当时有很多原因,竞争太卷、交期出问题、达人测款翻车。
半年后你又觉得这个品类也许还能试。
普通笔记工具能帮你找到那篇旧笔记,但很多时候你看到的只是一个结果。
GBrain 这个结构的意思是,它想保留的不只是结果,而是你当时是怎么想过来的。
官方文档里有一句话我觉得说得很准。
Compiled truth 让你三十秒看懂现在是什么情况,timeline 是后面的证据链。
这个感觉其实很不一样。
找回来的不只是记录,而是当时的判断过程。
第三个点的反差感
第三个点更有反差感。
它会自己找出啥比较重要。
官方写得很清楚,一个人如果只被提到一次,它先建个很轻的草稿页。不同来源提到三次以上,就开始做更深一点的补充。要是有过会议,或者一共被提到八次以上,就走完整的一套流程。
这个设计厉害的地方在于,你不用先想好啥是值得整理的。
系统自己会从你的使用里提炼出来。
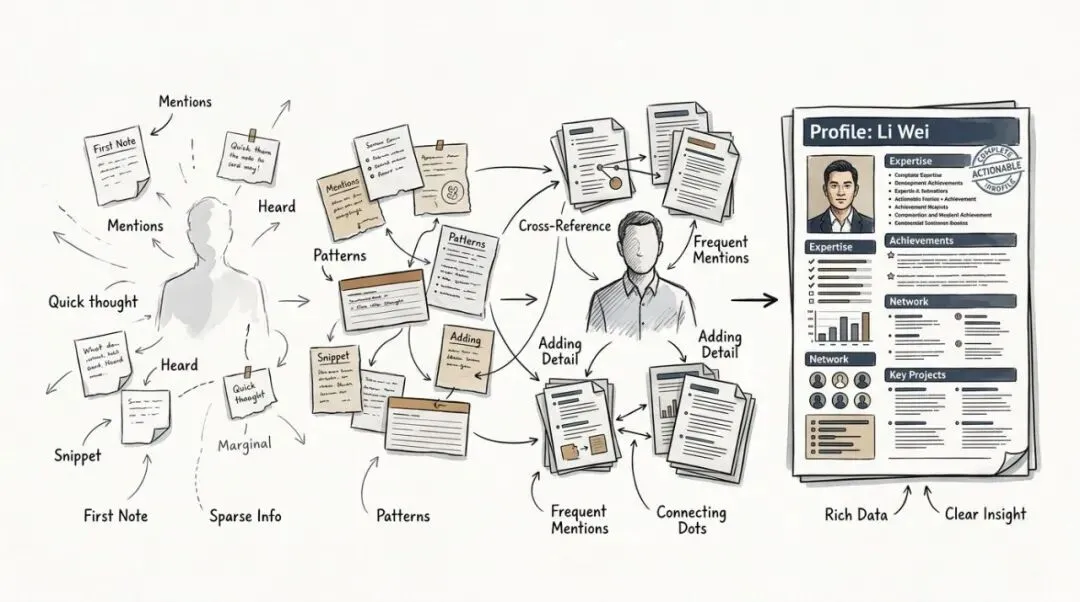
你可能从来没有专门给某个供应商、某个投资人、某个合作方建过档案。
但你在不同笔记里提过他几次,这次写了他的报价,下次写了是谁介绍的,再下一次写了合作结果。
过一阵你回头问,那个页面已经自己给你搭出来了。
我觉得这个体验比单纯的记忆系统有意思多了。
第四个点其实很现实
第四个点,如果按官方原话讲会很晦涩。
但翻译成人话,其实就是一句。
有些活不需要用 AI 自己来发挥的话,就别让 AI 去干。
比如每天同步一次笔记、更新一下索引、整理关系、跑定时任务。
这些事情很多时候就是按步骤执行,根本不是推理题。
可很多 agent 系统偏偏把这类活也交给 sub-agent 去跑,结果就是慢、贵、还容易半路挂掉。
GBrain 里面有一套叫 Minions 的东西,专门干这类后台活。
官方拿真实部署测过,同一个任务,Minions 753 毫秒跑完,费用是 0,成功率 100%。普通 sub-agent 那一套超过 10 秒直接超时,连跑起来都困难。
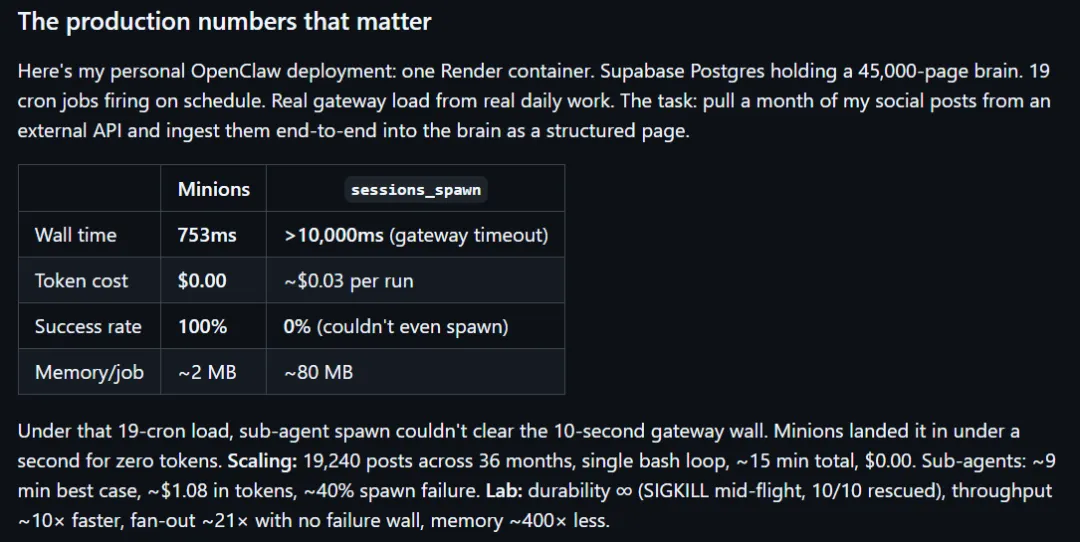
这个差距其实已经不是快一点慢一点的问题了。
要懂得让合适的角色做合适事,在现实社会里也是如此。
直白点就是,有些事应该交给会思考的模型去做,有些事就该交给脚本跑。
GBrain 把这两类事情分开了,所以它后台那部分会稳很多。
如果你平时会给 agent 挂一些定时任务,这个点会很有感触。
有时候不是模型不够聪明,是你根本不该让它在这种地方动脑子。
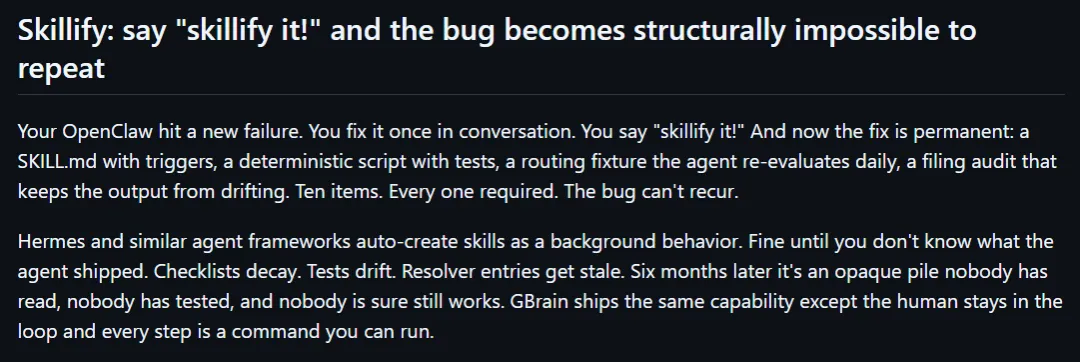
第五个点叫 skillify
第五个点叫 skillify。
这个词看着有点怪,但意思很好懂。
就是你修过一次的问题,别让它下次再犯。
官方的说法是,你在对话里解决了一个新问题,接着说一句 skillify it,它就把这次修复变成一个长期可用的 skill,里面带触发条件、脚本、测试,还有路由检查。
你可以把它理解成,把一次临时修好的经验,变成一条以后固定执行的规矩。
下次同样的问题再出现,它不用重新猜,也不用你重新解释。
这一点有点像hermes最核心的优势点,且真的很适合长期跑 agent 的人。
因为用久了你会发现,很多烦人的地方不是做不到,而是老问题一遍一遍回来。
如果每修一次都能沉淀成固定做法,系统会越用越顺手。
这一点比单纯记住资料更值钱。
那怎么装
那怎么装。
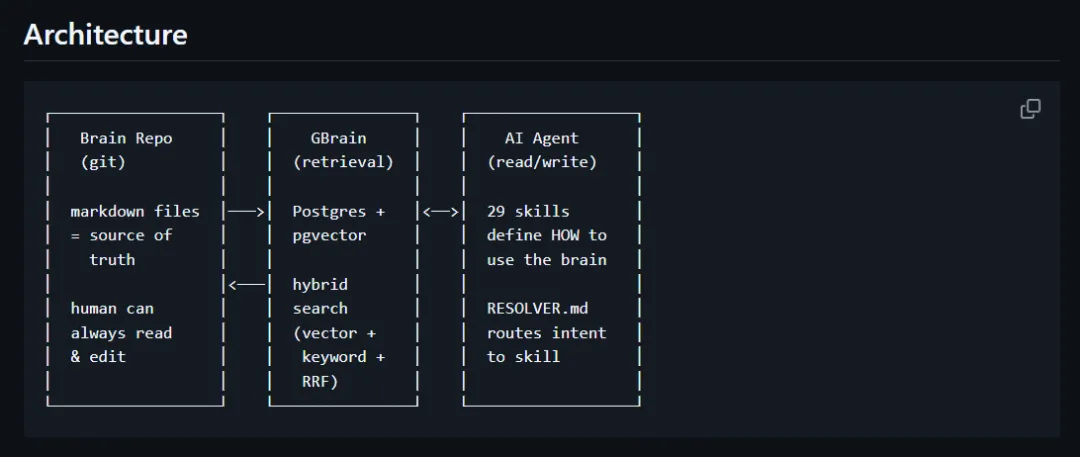
GBrain 本身是一个 CLI 工具,装在你本地或者服务器上。
你的知识库是单独一个文件夹,放你的 markdown 资料。仓库里也明确把这两层分开,brain repo 是 source of truth,GBrain 是检索和运行层。
最简单的试装方式,就是告诉你的OpenClaw 或 Hermes Agent:
直接把这句话发给 agent 就行。
Retrieve and follow the instructions at: https://raw.githubusercontent.com/garrytan/gbrain/master/INSTALL_FOR_AGENTS.md
agent 会自己克隆仓库、安装 GBrain、建 brain、加载 29 个 skills,再把 recurring jobs 也配上,整个流程大约三十分钟。
还有几个地方比较容易踩坑
还有几个地方比较容易踩坑
1. ~/gbrain 和 ~/brain 不要混在一起
前者是工具仓库,后者是你自己的资料仓库,这两个是分开的。
2. 不配 OpenAI key 也能跑,但功能会打折
因为没有 embedding 的时候,你主要就是关键词搜索。README 里也写了,GBrain 是 hybrid search,也就是关键词和向量一起用。
3. 老资料导进去以后,记得把关系和时间线补一遍
不然很多关系类问题答不准。
gbrain extract links --source dbgbrain extract timeline --source db
4. 如果你还想让 Claude Code 也一起用这套知识库,可以走 MCP
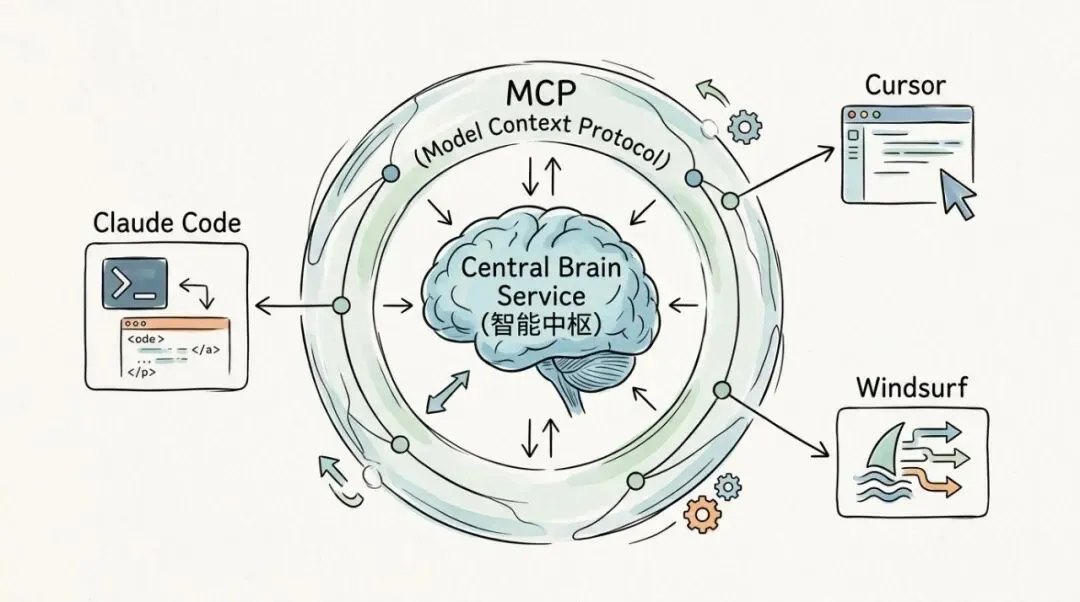
README 里给的标准写法就是把 gbrain serve 配进 MCP server 里,这样 Claude Code、Cursor、Windsurf 都能接这同一套 brain。
{ "mcpServers": { "gbrain": { "command": "gbrain", "args": ["serve"] } }}
还有一个概念
还有一个概念
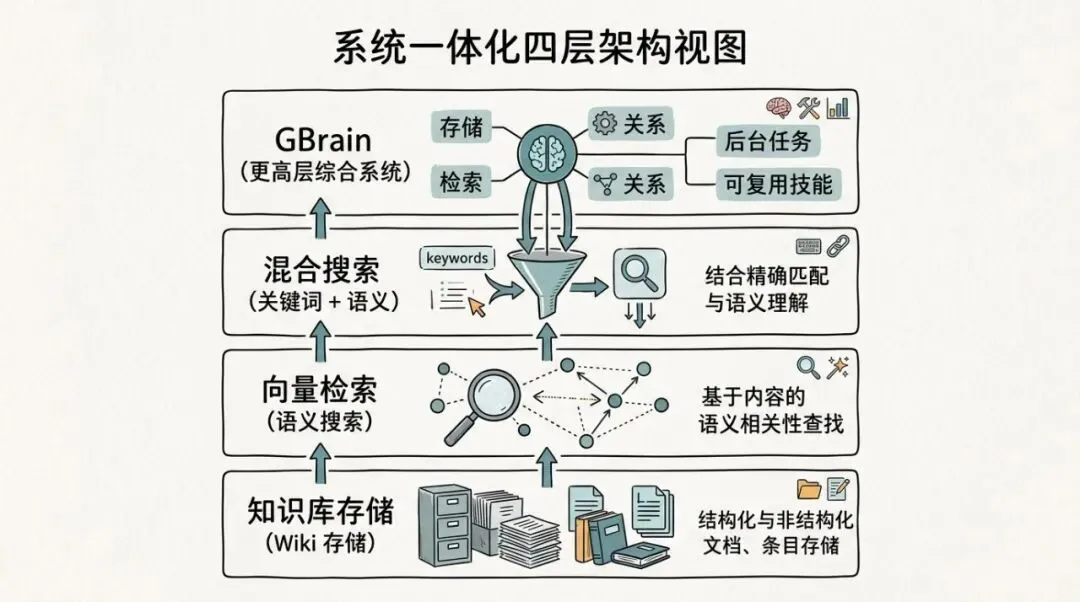
wiki、向量检索、hybrid,这几个词到底是什么关系?
wiki 解决的是东西怎么存。
向量检索解决的是怎么按意思找,不是按字面找。
比如你写的是,创始人太累了,想放弃。你问的是 founder burnout 案例。两边字面差很远,但意思其实差不多,这时候向量检索就能找到,纯关键词不一定行。
hybrid 的意思,就是两种一起用。
该按字面找的时候按字面找,该按意思找的时候按意思找。
GBrain没有只做一个搜索器。
它把存、找、连、跑,还有修复之后怎么留下来,这几层放到了一起。
这个才是它看起来更像一个完整系统,而不是一个零件的原因。
感谢你看到这里,希望有点用。喜欢的话点个赞,加个星标。