 夜雨聆风
夜雨聆风





AI 推荐怎么越算越快?抖音越刷越上瘾背后的“算力黑科技”
一、导语(Lead)
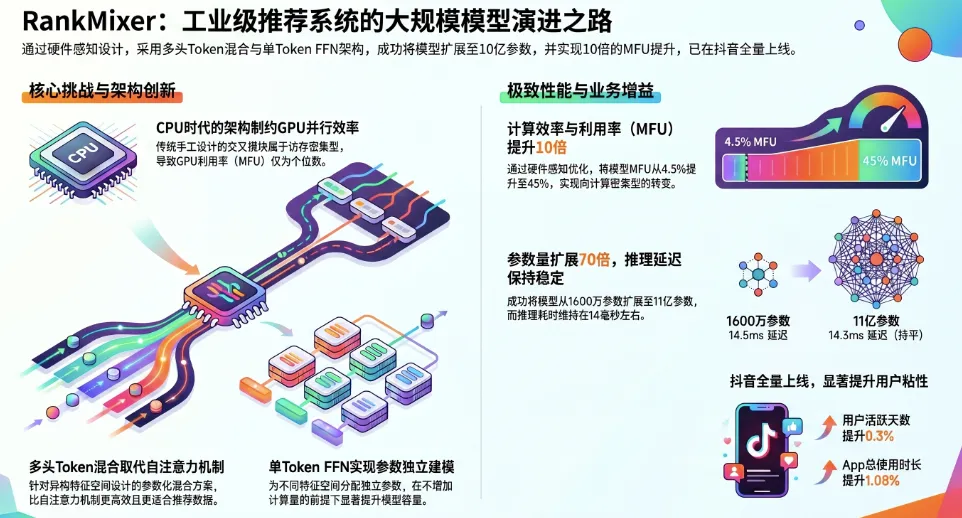
在当今生成式 AI 与大语言模型(LLM)大放异彩的时代,“缩放定律(Scaling Law)” 已经成为共识。然而,这篇由字节跳动团队发表的顶级工业界论文指出,传统的推荐系统排序模型(Ranking Models)要想享受 Scaling Law 的红利,正面临着两座难以逾越的大山:极低的模型算力利用率(MFU)和极其严苛的线上延迟限制。
本文将深度拆解字节跳动提出的全新硬件感知推荐架构——RankMixer。该架构彻底摒弃了 CPU 时代遗留的复杂特征交叉模块,通过首创的无参数多头 Token 混合(Multi-head Token Mixing)、独立 Token 专属前馈网络(Per-token FFN)以及动态稀疏混合专家系统(Sparse-MoE),在抖音真实大盘中实现了惊人的工程奇迹:将模型参数量扩大两个数量级(超过 10 亿),MFU 从 4.5% 暴涨至 45%,且在线推理延迟几乎保持不变!这标志着推荐系统正式迈入了 GPU 高效并行的基础大模型时代。
二、研究背景:为什么要解决这个问题?
在深入剖析 RankMixer 的精妙架构之前,我们必须深刻认知当前工业级推荐系统(Recommender Systems, RS)所经历的底层算力危机。这不仅是一个单纯的算法结构问题,更是一个关乎系统工程、硬件架构与深度学习范式激烈碰撞的世纪难题。
1. 当前领域面临的核心问题:被“延迟限制”锁死的 Scaling Law
大语言模型(如 GPT-4, Llama)的成功,向全行业揭示了一个极其暴力的真理:只要无脑堆叠模型参数和训练数据,模型的智能水平就会呈现出幂律增长(Scaling Law)。学术界和工业界的推荐团队自然也想在深度学习推荐模型(DLRMs)上复刻这一奇迹。
但是,推荐系统面临着与自然语言处理(NLP)截然不同的苛刻生存环境:极端的延迟界限(Strict Latency Bounds)与超高的并发需求(High QPS)。当你打开抖音或淘宝时,后台系统必须在几十毫秒(通常小于 50ms)的时间内,从数以万计的候选视频或商品中,为每一个单独的用户计算出精准的点击率(CTR)排序分数。如果简单粗暴地将推荐模型的参数扩大 100 倍,计算延迟也会成倍增加,这不仅会导致用户体验极其卡顿,更会直接击穿公司机房的服务器预算(Serving Cost)。因此,当前领域面临的核心矛盾是:如何在一个“戴着镣铐跳舞”的严苛计算约束下,寻找模型有效性(参数量)与计算效率(QPS/延迟)的“甜点(Sweet Spot)”?
2. 现有方法的主要局限:CPU 时代的“技术债务”
为了理解现有的推荐模型为什么跑不快,我们需要回顾历史。现有的主流推荐架构(如 DeepFM、DCNv2、xDeepFM,以及阿里、腾讯等大厂早期使用的各种复杂交叉网络),其底层设计哲学深深烙印着 “CPU 时代” 的痕迹。
在 CPU 时代,计算资源相对匮乏,算法工程师们习惯于“精雕细琢”。他们手动设计了各种极其复杂、花哨的特征交叉算子(Handcrafted cross-feature modules),试图让不同特征(如“用户年龄”与“视频类目”)在极小的参数量下进行高阶组合。然而,随着算力步入 GPU 时代,这些精巧的设计反而成为了致命的毒药:
-
• 内存墙困境(Memory-bound vs. Compute-bound):现代 GPU 的计算核心(ALU/Tensor Cores)极其强大,但显存读写带宽相对有限。传统的推荐模型包含大量琐碎的元素级运算(Element-wise operations)、不规则的内存访问和细碎的矩阵乘法。这导致 GPU 的计算核心大部分时间都在“苦等”数据从显存里搬运过来。 -
• 极低的模型算力利用率(Low MFU):在 RankMixer 部署前,字节跳动线上强大的基线排序模型,其 MFU(Model Flops Utilization)仅为可怜的 4.5%。这意味着 GPU 超过 95% 的算力都被浪费在了内存读写和等待中!这不仅是巨大的成本浪费,更意味着模型丧失了通过堆叠算力来提升能力的可能。
另一方面,有人提出:为什么不直接抄作业,用 NLP 领域大获成功的 Transformer(自注意力机制,Self-Attention) 呢?答案是:严重的水土不服。
-
• 在 NLP 中,所有的单词(Tokens)都属于同一个语义空间(语言)。而在推荐系统中,特征空间是极度异构的(Heterogeneous Feature Spaces)。把一个“用户ID(数亿个独立散列值)”和一个“视频时长(连续浮点数)”强行丢进自注意力矩阵中计算内积相似度,在数学上是极其反直觉的。 -
• 此外,自注意力机制的 计算复杂度和庞大的注意力权重矩阵,在极度异构的特征空间下,不仅效果不如人意,还会加剧 GPU 的内存带宽压力(Memory I/O burden)。
3. 为什么这个问题一直没有被很好解决?
长期以来,学术界在推进推荐模型架构时,往往只关注离线 AUC 指标的提升(如 DHEN、Wukong 堆叠各种不同的算子),而严重脱离了工业界的硬件现实。解决这个问题的核心难点在于:它要求设计者必须同时具备极其深厚的深度学习算法功底,以及对底层 GPU 硬件架构(如 CUDA 内存调度、并行计算)极其入微的理解。既要摒弃复杂算子以迎合 GPU 并行化,又必须在简化结构的同时保留模型捕捉几百个不同特征之间“非线性高阶交叉”的敏锐度。这在过去被认为是一个不可能完成的“既要又要”的挑战。
4. 现实世界中的类比帮助理解
我们可以用厨房流水线(模型架构)与厨师团队(GPU算力) 来极其通俗地理解这一痛点。
-
• 传统的 CPU 时代模型(如 DCN、DeepFM):就像是一个拥有几百道极其复杂、繁琐工序的米其林法式餐厅流水线。每个步骤都需要特定的切法和火候。以前只有一个老厨师(CPU)慢慢做,没问题。现在老板花重金请来了 1000 个顶级厨师(GPU)。但因为流水线设计得太琐碎、厨房通道太窄(内存带宽受限),这 1000 个厨师有 950 个都在排队等一口锅(极低的 MFU 4.5%)。 -
• NLP 的 Transformer(自注意力机制):老板看隔壁做快餐的(大语言模型)效率很高,试图直接抄作业。但发现隔壁厨房只用处理牛肉(同质化的自然语言),而自己的厨房里有海鲜、蔬菜、调料、甚至还有塑料包装(极度异构的特征空间)。如果让所有食材无差别地“自我互相混合(Self-attention)”,做出来的是一锅四不像的毒药。
RankMixer 试图解决的问题,就是专门为这 1000 个顶级厨师(GPU)重新设计一条适合处理百味杂陈食材(异构特征)的高速流水线,让大家不用排队,全速运转,并且做出的菜(推荐准确率)比以前更好吃。
三、核心研究问题
问题
论文试图解决的核心问题是:在工业级推荐系统中,如何设计一种“硬件感知(Hardware-aware)”的统一排序模型架构,使得模型在能够充分挖掘异构特征交互的同时,大幅提升 GPU 算力利用率(MFU),从而突破在线推理延迟的红线,成功将大模型 Scaling Law 落地于百亿级流量的推荐系统中?
-
• 输入(Input):包含数亿用户的画像、行为序列、短视频特征以及高维交叉特征在内的数百个维度的异构特征数据(Heterogeneous diverse features)。 -
• 输出(Output):预测用户对短视频或广告的精准转化行为(如:是否完播 Finish、是否滑走 Skip、点赞 Like 等多目标预测概率)。 -
• 当前研究痛点:如何在扩展模型容量(Model Capacity)时,解耦“参数增长”与“推理延迟增加”的强绑定关系。
创新
为了彻底攻克上述难题,字节跳动团队提出了极具颠覆性的 RankMixer 架构。
方法的整体思路:RankMixer 放弃了所有华而不实的复杂交叉算子,转而采用一种极简的、高度类似 Transformer 的规整并行架构,但又极其聪明地避开了 Transformer 在推荐领域的暗礁。它通过在 Token 层面进行巧妙的空间切割与参数隔离,完美平衡了“算力友好度”与“异构特征表达力”。
模型结构与核心创新点:
-
1. 多头 Token 混合(Multi-head Token Mixing):这是替换掉自注意力(Self-attention)的杀手锏。作者发现,既然不同特征空间的 Token 强行计算内积(相似度)不靠谱,不如直接在维度空间上进行无参数的物理切分与拼接。Token Mixing 将每个特征 Token 均匀切分为 个 Head,然后跨 Token 将这些 Head 重新拼接。这种操作完美实现了全局信息的强制流通与交互,不仅表现优于自注意力,而且计算复杂度极低,完全没有权重矩阵的内存负担(Parameter-free operator)! -
2. 独立 Token 前馈网络(Per-token FFN):在传统的 Transformer 中,所有 Token(无论是主语、谓语还是宾语)在经过注意力层后,都会通过同一个共享参数的 FFN(前馈网络)。RankMixer 敏锐地指出:在推荐中,不同的特征子空间(如“人口属性”与“内容标签”)有着天壤之别。因此,RankMixer 为每一个特征 Token 分配了独立的不共享参数的 FFN。这不仅赋予了模型针对异构数据差异化建模的能力,防止高频特征淹没长尾特征,还成倍增加了模型的参数量与学习容量(Model Capacity),完美适配了大规模数据的投喂。 -
3. 基于 ReLU 路由与 DTSI 的稀疏混合专家(Sparse-MoE)扩展:为了进一步将模型推向 10 亿(1B)参数的惊人规模而不增加在线推理开销,作者在 Per-token FFN 的基础上引入了 Sparse-MoE。针对推荐模型常见的专家训练不均和“死专家”问题,独创了 ReLU Routing(动态预算分配) 与 DTSI(Dense-training / Sparse-inference,稠密训练稀疏推理) 策略。
与传统方法的区别:
-
• 相比于传统的多层感知机(DLRM-MLP)和交叉网络(DCNv2):RankMixer 消除了细碎的内存受限算子,采用大矩阵乘法,极致迎合现代 GPU 架构,MFU 翻了十倍。 -
• 相比于采用自注意力机制的推荐模型(如 AutoInt、HiFormer):RankMixer 的 Token Mixing 摒弃了毫无意义的异构空间内积计算,大大降低了显存 IO 开销并提升了准确率。
比较
在极其内卷的大厂指标比拼中,论文将 RankMixer 与业内最具代表性的架构进行了真刀真枪的对比打榜:
-
• 经典浅层与交叉网络(DLRM-MLP, DCNv2, RDCN): -
• 特点:业内最广泛部署的成熟基线。 -
• 差异:参数一旦扩大,由于设计瓶颈,FLOPs 激增,但准确率(AUC)边际收益极低。RankMixer 凭借其可扩展架构,在扩参时实现了远超基线的陡峭收益曲线。 -
• 堆叠式巨无霸模型(DHEN, Wukong): -
• 特点:结合了 DCN、Self-attention、FM、LR 等多种模块的“缝合怪”,在离线评测中表现强劲。 -
• 差异:这种模型在工业界落地是噩梦,极不规律的算子导致 FLOPs 和内存开销成倍爆炸。RankMixer 仅用最规整的矩阵运算就全方位碾压了它们的准确率。 -
• 注意力模型(AutoInt, HiFormer): -
• 特点:尝试将 NLP 架构生搬硬套到推荐领域。 -
• 差异:RankMixer 证实了自注意力在处理异构 ID 特征时的软肋,其创新的 Token Mixing 以更低的计算成本实现了更优异的全局特征交互。
核心理论假设
作者的核心理论假设是:推荐排序模型的 Scaling Law 是切实存在的,但前提是模型架构必须实现“参数增长(Model Capacity)”、“特征交叉有效性(Feature Interaction)”与“底层硬件吞吐(Hardware Throughput)”的彻底解绑与完美协同。
-
• 理论解释:如果依然用 CPU 时代的思维设计网络,扩参就等于增加极慢的定制算子,这就导致 FLOPs 虽然没涨多少,但时间全耗在等内存(Memory-bound)上。只有像 RankMixer 这样,把所有的特征提取抽象为极其纯粹的大规模矩阵乘法(Per-token FFN)和低耗时的张量切分拼接(Token Mixing),才能将模型从“Memory-bound”解放到“Compute-bound”,使得增加的参数真正转化为计算能力的飙升。 -
• 直觉上的理解方式:这就像是城市交通规划。以前是修无数条弯弯曲曲的小路、立交桥和红绿灯(复杂的传统交叉算子),车一多(参数变大)就全城大堵车(延迟爆炸)。RankMixer 直接推平了一切,修建了一条极其宽阔、没有红绿灯的高速公路(规整的张量并行架构)。不同的车(Token)在各自专属的并行车道(Per-token FFN)上狂飙,在特定路口进行极其高效的无缝换道交汇(Multi-head Token Mixing)。因此,即使车流量翻了 100 倍,整体通行速度依然不受影响。
四、研究方法(Methodology)
本节我们将以结构化的方式,自底向上地拆解 RankMixer 极具工程美学的内部工作流(结合论文 Figure 1)。
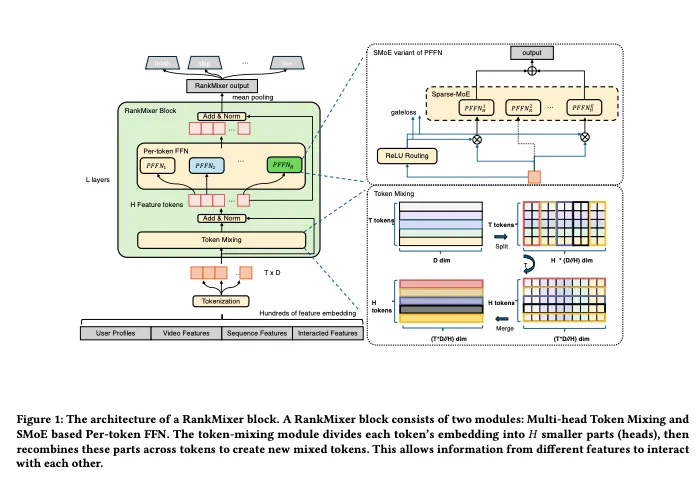
4.1 整体方法框架(工作流程)
RankMixer 的数据管线可以清晰地划分为三个紧密相扣的阶段:
-
1. 语义特征标记化(Semantic Feature Tokenization):将输入的几百个原始异构特征,按照领域知识打包压缩成维度一致的特征向量块(Tokens)。 -
2. 堆叠的 RankMixer 核心区块(RankMixer Blocks):这是整个模型的心脏。在每一层中,特征 Tokens 首先进入 Token Mixing模块进行跨领域的强制信息交融;随后进入Per-token FFN(或 Sparse-MoE)进行深度的专属非线性变换。整个过程不断重复迭代 层。 -
3. 输出池化与任务预测(Output Pooling & Prediction):将最后一层出来的深层特征 Tokens 进行均值池化(Mean Pooling),送入最终的多目标预测头计算概率分布。
4.2 关键技术模块详解
模块一:语义驱动的特征 Token 化(Feature Tokenization)
-
• 问题背景:推荐特征太零碎,如果每个小特征(如用户年龄)算一个 Token,会有几百个 Token 导致 GPU 算不过来;如果把所有特征拼接成一个巨大的 Token 塞进 DNN,又会丧失特征域的独立表达能力。 -
• 核心机制:RankMixer 采用了一种折中的语义聚类(Semantic-based grouping) 策略。它利用业务知识,将语义相近的特征(例如所有描述视频属性的特征归为一类,所有用户画像的归为一类)首先拼接,然后通过各自的映射层(Proj)映射为 个具有固定维度 的标准化语义特征 Token(公式 2)。这为后续极其规整的并行矩阵运算打下了完美的基础。
模块二:无参数的多头 Token 混合(Multi-head Token Mixing)
-
• 作用:替代自注意力机制,以零参数代价实现全局特征交叉。 -
• 底层原理解析:假设我们现在有 个 Token,每个维度是 。为了让不同 Token 之间产生信息传递,RankMixer 将每个 Token 的向量沿着维度切成 个头(Heads)。例如,第一个 Token 变成了 (公式 3)。接下来见证奇迹:在重组阶段,模型将所有不同 Token 的第 1 个 Head 取出来拼接在一起,组成新的 Token 1;把所有 Token 的第 2 个 Head 拼接在一起,组成新的 Token 2… 依此类推(公式 4)。这种操作在物理空间上强制将(比如用户的局部特征和视频的局部特征)融为一体。随后通过一个残差连接(Residual connection)和层归一化(LayerNorm),就完成了一次极其高效的全视野特征杂交。整个过程只涉及张量的 Split 和 Concat,在底层 CUDA 实现中速度快如闪电。
模块三:参数隔离的独立前馈网络(Per-token FFN)
-
• 作用:保障异构特征子空间的独立性,并成倍扩充模型容量。 -
• 底层原理解析:传统架构中,所有输入最后都在同一个多层感知机(MLP)里搅成一锅粥。而 RankMixer 为刚才生成的 个混合 Token,配备了 个各自独立、不共享权重的全连接网络(MLP)(公式 6, 7)。这意味着,代表“用户历史序列”的 Token 拥有自己的专属神经元去提取规律,代表“候选视频特征”的 Token 也有自己的一套独立神经元去消化信息。这种参数隔离极致地保护了长尾信号,同时,由于参数量随 Token 数量线性增加,模型顺理成章地变得“更宽更深”,极大地提升了记忆与泛化能力。
模块四:自适应稀疏混合专家系统(Sparse-MoE with ReLU Routing & DTSI)
-
• 作用:冲击 10 亿大关的核武器。如何在模型参数扩张到 1B 时,依然把计算量死死压住?引入 MoE(混合专家)。 -
• 底层原理解析:常规的 MoE 往往会导致大部分专家(神经元网络)长期不被触发而被“饿死(Dying experts)”。RankMixer 提出了两套组合拳: -
1. ReLU 路由(ReLU Routing):摒弃传统的强制选 Top-K 个专家的做法,改用 ReLU 激活函数加 惩罚项(公式 10, 11)。这就像一个极具弹性的预算分配官。遇到极度复杂的特征(高信息熵 Token),它会同时唤醒多个专家一起来算;遇到简单的特征,它可能只唤醒一个专家,从而把宝贵的算力真正用在刀刃上。 -
2. 稠密训练/稀疏推理(DTSI-MoE):训练时,更新所有的路由器(Routers),确保每个专家都能充分吸收梯度(解决专家训练不足的问题);到了线上推理时,切换回极度稀疏模式,极大降低了计算成本。
五、实验结果与分析
为了验证这一破局之作的实战统治力,字节跳动团队在来自于真实抖音(Douyin)大盘、包含万亿级(Trillion-scale)样本的数据集上,进行了极其硬核的全方位测试。
1. 离线实验指标屠榜:小参数大能量
如 Table 1 所示,在将各大流派模型对齐在约 100M(一亿)参数量级时,RankMixer-100M 展现出了压倒性的优势。
-
• 在 Finish(完播率)和 Skip(滑走率)两大核心推荐指标上,RankMixer 在 AUC(曲线下面积)上不仅完全超越了基于 DCNv2 和 DHEN 的巨无霸基线,更是实现了令人咋舌的相对提升(Finish AUC 提升 +0.64%,Skip UAUC 提升 +1.33%)。在日活数亿的推荐系统中,万分之几(0.01%)的 AUC 提升都极其艰难,这种级别的涨幅堪称断层级领先。 -
• 更为可怕的是效率:达到霸榜精度的 RankMixer-100M,其单批次 FLOPs 仅为 233G,远远低于 HiFormer 的 326G 和 Wukong 的 442G。证明了其架构设计兼顾了极致的准确度与极致的算力性价比。
2. 完美的 Scaling Law 曲线
在 Figure 2 中,作者分别绘制了模型准确率(AUC gain)随着“参数量(Dense #Param)”和“计算量(FLOPs/Batch)”增加的变化曲线。结果极其震撼:在所有测试模型中,RankMixer 呈现出了最陡峭、最持久的 Scaling Law 曲线。当其他老旧架构(如 DLRM, DHEN)在增加参数后准确率很快陷入停滞(边际收益递减)时,RankMixer 的 AUC 随着参数从 10M 一路狂飙至 1B,依然保持着强劲的直线上升趋势,证明它真正解锁了工业级排序大模型的扩参密码。
3. 解密 1B 参数下的“延迟神话”:极致的工程优化
论文中最令人心潮澎湃的工程数据位于 Table 6。当 RankMixer 的参数量从原有线上的 15.8M 暴增 70 倍达到 1.1B(十亿级),并且 FLOPs 增加了近 21 倍时,它的在线推理延迟(Latency)居然从 14.5ms 不升反降,变成了 14.3ms!这奇迹般的数字是如何做到的?作者给出了公式化的拆解(公式:Latency ∝ Param × FLOPs_ratio / MFU):
-
• 极其高效的单位参数算力比(FLOPs/Param ratio):由于架构精简,扩增参数所带来的冗余计算极低,该比值下降了 3.6 倍。 -
• MFU 的十倍暴涨:通过将细碎的跨特征算子融合为一个统一的大型 Token-Mix 矩阵乘法内核,彻底打破了内存墙限制,使得硬件算力利用率从 4.47% 直接飙升了 10 倍达到 44.57%(从 Memory-bound 成功转变为 Compute-bound)。 -
• FP16 半精度量化与硬件协同:完美适配现代 GPU 的 Tensor Core 架构,将理论浮点峰值再翻一倍。
4. 抖音全量 A/B 测试:真金白银的业务增长
经过严苛的在线测试,1B 参数级的 RankMixer 目前已经全面接管了抖音(Douyin)和抖音极速版的 Feed 流推荐大盘。
-
• 大盘核心数据爆发:在万亿流量的冲刷下,RankMixer 为大盘贡献了 +0.3% 的用户活跃天数(Active Days)增长,以及 +1.08% 的 App 整体使用时长(Duration)增长(Table 4)。这在极其内卷的短视频赛道,意味着数以千万计的额外日活和巨额的商业变现增量。 -
• 更为难得的是,模型在低活跃用户(Low-active users) 群体中取得了最为惊人的突破(时长暴涨近 +3.64%),这强有力地证明了参数隔离与大规模容量带来的泛化能力,成功挽救了长尾冷启动用户的体验。
六、对未来研究的启发
RankMixer 以其极其硬核的软硬件协同设计,为推荐系统向“大模型化”演进树立了全新的灯塔。这篇论文也为未来的研究撕开了极具想象力的裂口:
-
1. 向十亿、百亿级乃至融合大模型的冲锋:目前 RankMixer 已经通过 Sparse-MoE 平稳触达 1B 参数。未来,沿着 DTSI 和 ReLU 路由的稀疏化演进路线,推荐排序模型完全可以冲击 10B 甚至千亿级别参数,实现推荐系统认知能力的再跃迁。 -
2. 多模态与生成式推荐(Generative Recommendation)的底层底座:随着短视频场景对视觉、音频理解的深入,以及推荐系统从“判别式”向“生成式”过渡。RankMixer 这种摒弃全量注意力、极其高效的 Token 化架构,为未来处理极其冗长的多模态序列,或作为大规模自回归生成框架的高效 Encoder/Decoder 底座,提供了绝佳的参考。 -
3. 软硬件协同设计(System-Model Co-design)的新范式:未来的算法研究必须告别“纸上谈兵”。RankMixer 深刻教育了行业:一个优秀的 AI 模型,不仅要看数学公式是否优雅,更要看它的计算图是否适配下一代异构计算硬件(如 GPU 的共享内存、张量核心架构)。未来的推荐前沿必将是算法与底层芯片工程深度绑定的超级系统工程。
七、通俗版总结
如果把抖音每天为几亿人推荐视频的过程比作一场超大规模的“猜心游戏”,以前的 AI 大脑虽然聪明,但它的脑回路(模型架构)设计得太复杂了。在面对海量用户的年龄、兴趣、以及上千万个视频特征时,它就像是一个陷入泥潭的巨人——即使你给他配备了最顶级的计算机(GPU),他大部分时间也只能卡在那里等数据读取,导致大脑的运转效率低得可怜(只有不到 5%)。
为了让推荐系统变得更聪明,字节跳动的工程师发明了 RankMixer。他们对这个 AI 大脑进行了一场彻头彻尾的“外科手术”。他们砍掉了所有拖泥带水的复杂计算逻辑,把不同种类的信息变成了统一的积木块(Tokens),并给每一种信息分配了“专属的高级专家(Per-token FFN)”独立处理,最后用一种最简单直接的拼接方式(Token Mixing)让这些信息瞬间完成跨界交流。
更绝的是,他们还引入了一套“弹性值班制度(Sparse-MoE)”,遇到复杂问题多叫几个专家,遇到简单问题少叫几个。这套组合拳下来,整个系统迎来了脱胎换骨的改变:这个 AI 大脑的知识储备(参数量)足足暴增了接近 100 倍(突破十亿),但由于工作流程被优化到了极致,它做出每一次推荐思考的时间,竟然没有增加哪怕一毫秒!最终,这个拥有庞大智慧且反应神速的新大脑,不仅被成功部署到了真实业务中,还让用户在抖音上的平均使用时长实现了超过 1% 的巨大增长,堪称现代推荐系统工程架构的教科书级别实战指南。