 夜雨聆风
夜雨聆风





全国知识产权宣传周 | 我用AI画了张图,怎么就成被告了?——训练数据版权合规“避坑指南”






开篇小故事
某设计公司为抢占AI创作风口,用爬虫抓取了全网10万+设计师的原创作品,训练出一款“AI绘画生成器”,上线3个月就收获百万用户。正当公司准备融资扩张时,却收到了数十位设计师的联合起诉,指控其未经授权使用原创作品作为训练数据,侵犯著作权;同时,市场监管部门也介入调查,认定其爬虫抓取行为涉嫌不正当竞争,公司最终不仅下架产品、赔偿千万、前期所有研发投入全部付诸东流,还丧失了核心融资机会。
这不是个例,而是AI时代企业创新的“高频雷区”。上一篇我们提到,AI模型的核心竞争力在于数据,但很多企业只关注“数据够不够多、模型够不够准”,却忽略了训练数据背后的版权风险——你的AI创新,可能从一开始就建立在侵权的“沙滩”上。
在知识产权宣传日来临之际,我们结合“AI绘画被诉第一案”等典型案例,拆解训练数据版权合规的核心要点,帮企业避开侵权陷阱,守住AI创新的合法底线。
一
训练数据也能惹官司?先绕开这3个误区

很多企业觉得“网上的内容随便用”“我只是用来训练,又不直接复制”,殊不知这些想法正是侵权的根源。先厘清3个高频误区,再谈合规:
误区1:“非商用就不侵权”
不少企业认为,只要AI模型不用于盈利,抓取他人作品训练就没问题。但根据《著作权法》,未经著作权人许可,即使是“非商用”的复制、使用行为,也可能构成侵权——除非符合“合理使用”(如个人学习、研究),而企业用于研发AI产品,显然不属于合理使用范畴。
误区2:“抓取公开内容就是合法的”
网页、公众号、设计平台上的公开作品,并不等于“可以随意抓取使用”。很多平台的用户协议中明确约定,“未经平台或作者许可,禁止爬虫抓取、批量下载内容”,企业擅自爬虫抓取,不仅侵犯作者著作权,还可能违反平台规则,构成不正当竞争。
误区3:“AI生成内容和我无关,侵权也是模型的事”
AI生成内容的版权归属虽有争议,但“训练数据侵权”的责任,明确由模型训练方(企业)承担。无论是自己抓取数据,还是使用第三方提供的训练数据集,只要数据存在侵权,企业作为模型的研发、使用方,就要承担赔偿、下架等法律责任。
二
两个典型案例,看清训练数据侵权的“坑”与“防”

结合近期司法实践,两个案例帮你直观理解:哪些行为会踩雷,该如何正确规避。
案例1:“AI绘画大模型训练被诉第一案”——未经授权用他人作品训练,必赔!
某AI科技公司研发的AI绘画工具,在训练过程中使用了某插画师的数百幅原创作品,且未获得任何授权。插画师发现后起诉,法院认定:AI模型训练本质是对作品的“复制+改编”,公司未经许可使用作品,侵犯了插画师的复制权、信息网络传播权,判决公司赔偿经济损失及合理开支近160万元。
关键细节:法院明确,即使AI生成的作品与原作品不完全一致,只要训练过程中使用了原作品的核心元素,就构成侵权;且企业无法以“不知道数据侵权”“数据来自第三方”为由免责。
教训:训练数据的“合法性”,必须由企业主动核查,不能依赖“第三方提供”就掉以轻心。
案例2:使用开源模型微调,因违反协议被判侵权
某企业为快速研发AI文本生成工具,使用了一款开源预训练模型进行微调,却未遵守开源协议中“非商用授权”“必须标注来源”的要求,将微调后的模型用于商业服务并收取费用。模型开源方起诉后,法院判决企业停止侵权、赔偿损失,并公开道歉。
教训:开源不等于“免费商用”,使用任何开源模型或开源数据,都必须先仔细阅读开源协议,严格遵守授权范围和要求。
三
企业AI训练数据合规“三步法”

掌握以下三步,就能有效规避训练数据版权风险,让AI创新更安心,企业可对照自查、执行,从源头规避侵权风险。
第一步:数据来源“三核查”,拒绝“来路不明”的数据
核心原则:所有训练数据,必须明确来源、获得合法授权,坚决杜绝“爬虫抓取”“私下搬运”。具体核查3点:
核查来源合法性:优先使用自有数据、授权数据(如与版权方签署授权协议)、合规公开数据(如政府公开数据、正版素材库);严禁使用爬虫抓取非授权内容,即使是“公开可浏览”的作品,也需先获得作者或平台许可。
核查授权范围:明确授权的使用场景(如是否可用于AI训练)、使用期限、地域范围,避免“超授权使用”——比如授权用于“非商用训练”,就不能用于商业产品研发。
核查第三方数据:若使用第三方提供的训练数据集,需要求第三方出具“数据合法授权证明”,并在合作协议中约定“若数据侵权,第三方承担全部责任”,降低自身风险。
第二步:数据使用“两处理”,降低侵权风险
即使数据来源合法,使用过程中也需做好两步处理,避免额外风险:
脱敏处理:若训练数据中包含个人信息(如肖像、姓名、联系方式),需进行脱敏处理(如模糊处理、删除敏感信息),避免同时侵犯个人信息权益——这也是《个人信息保护法》的明确要求。
合理引用:若需使用他人作品片段作为训练数据,尽量控制引用比例,且在模型说明中注明数据来源(如“部分训练数据来源于XX版权方授权”),降低侵权争议。
第三步:开源模型“一确认”,守住协议红线
很多企业会使用开源模型进行微调,这一步的核心是“确认开源协议”,避免踩坑:
区分授权类型:常见的开源协议(如MIT、GPL、Apache)授权范围不同,比如GPL协议要求“基于该模型修改后的作品也需开源”,MIT协议则允许商用,但需标注来源;务必根据企业需求选择合适的开源模型。
严格遵守协议:按照开源协议要求,标注模型来源、保留协议声明,不擅自修改协议条款,不超授权范围使用(如将非商用开源模型用于收费服务)。
四
四、附:AI训练数据版权合规自查清单(知识产权宣传日活动版)

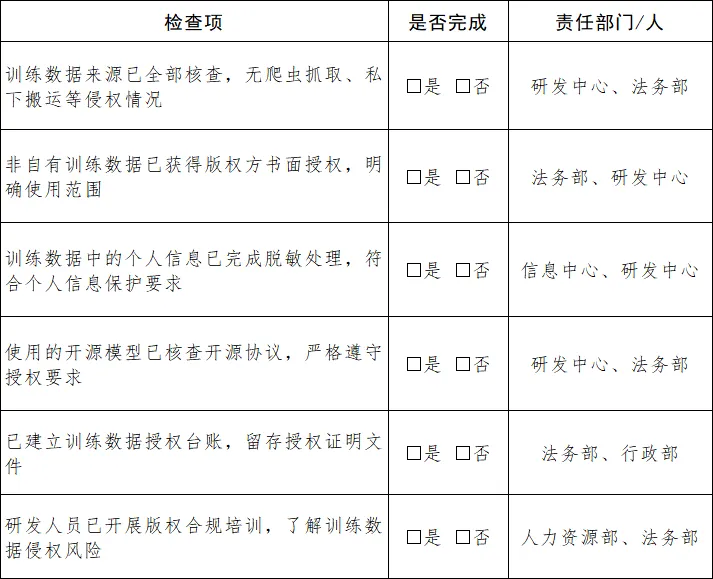
知识产权宣传日特别提醒
AI创新的核心是“合法合规”,而训练数据的版权合规,正是AI创新的“第一道防线”。在知识产权宣传日来临之际,提醒所有企业:不要为了追求研发速度而忽视版权风险,不要让辛苦研发的AI产品,因为“数据侵权”而功亏一篑。
供稿:法律风控部
编辑:冯新博
审核:赵 雪
责编:李隆宇
