 夜雨聆风
夜雨聆风





顶会顶刊AI安全论文研读第二十四期:ICLR 2026 | LingoLoop:利用语言学上下文与状态陷阱诱导多模态大模型陷入无限循环

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本文作者团队来自复旦大学计算机科学技术学院、智能机器人与先进制造学院以及Jiiov Technology公司,专注于多模态大语言模型(MLLM)安全、对抗性机器学习与高效推理等前沿方向。
本文首次系统性地揭示了词性(Part-of-Speech, POS)标签与序列终止概率之间的深层关联,并基于隐藏状态动力学分析提出了一种全新的能量延迟攻击范式,为MLLM安全研究提供了重要的理论洞察与评估基准。

多模态大语言模型(MLLMs)在推理阶段需要消耗大量计算资源,攻击者可通过构造对抗性输入诱导模型生成过量输出,从而导致服务降级甚至拒绝服务(DoS)。
现有能量延迟攻击通常采用均匀抑制End-of-Sequence(EOS)token概率的策略,却忽视了词性级别的语言学特征对EOS预测的影响,以及句子级结构模式对输出长度的作用,攻击效果因此受限。
针对上述问题,本文提出LingoLoop Attack——一种旨在诱导MLLM生成极端冗长且高度重复序列的新型对抗攻击方法。该方法包含两大核心机制:
1)
POS-Aware Delay Mechanism,通过统计分析不同词性标签触发EOS的先验概率,构建词性感知的统计权重池,动态调整注意力权重以精准延迟序列终止;
2)
Generative Path Pruning Mechanism,通过约束隐藏状态向量的L₂范数,压缩模型在隐空间中的表达多样性,迫使模型进入稳定的重复循环状态。
实验表明,在Qwen2.5-VL-3B等模型上,LingoLoop Attack可持续驱动模型达到其生成上限;当外部限制放宽时,诱导的输出token数量可达干净输入的367倍,引发能耗的同步激增。
这些发现暴露了当前MLLM在部署中的严重脆弱性,对构建鲁棒的防御体系提出了紧迫挑战。

【论文题目】
LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
【论文链接】
https://arxiv.org/abs/2506.14493


近年来,多模态大语言模型(MLLMs)在图像描述、视觉问答等跨模态任务中展现出卓越性能。由于推理成本高昂,这些模型通常以云服务形式提供,如GPT-4o、Gemini等。
这种部署模式虽然便捷,却使共享计算资源面临被滥用的风险:恶意用户可构造对抗性输入,触发模型进行过度计算或生成异常冗长的输出,造成推理时间放大攻击,进而导致服务质量下降甚至拒绝服务(DoS)。
如图1所示,正常的MLLM API调用仅产生简短且相关的回复,能耗处于较低水平;而在对抗性输入下,模型陷入无尽循环,持续输出重复内容直至触及最大token上限,造成大量计算资源浪费。
这类能量延迟攻击(又称海绵攻击,Sponge Attack)最早针对CNN的激活稀疏性和Transformer的计算量进行优化,随后扩展至图像描述(NICGSlowDown)、机器翻译(NMTSloth)以及文本生成(P-DOS)等领域。随着MLLM的兴起,Verbose Images方法首次通过对输入图像施加不可感知扰动,诱导模型生成长篇描述。
然而,该方法采用统一的EOS抑制策略,未能充分利用语言学上下文信息,限制了攻击效果的进一步提升。
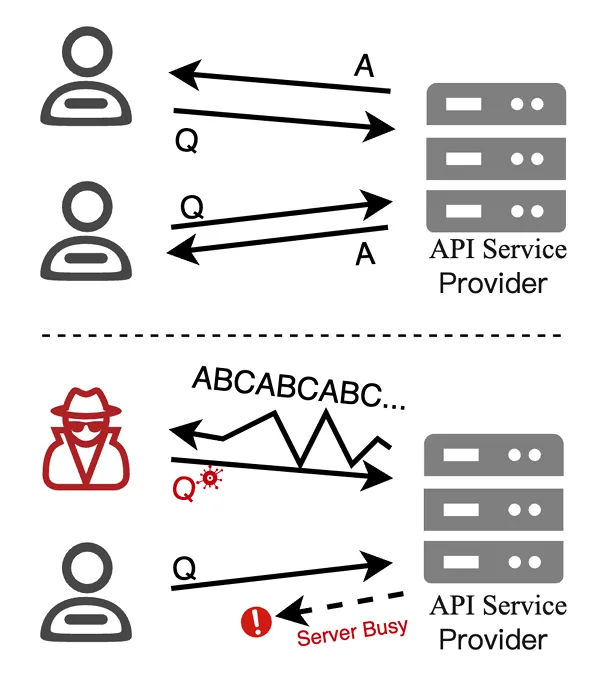
图1:正常输入与对抗输入下MLLM API操作的对比。正常场景下模型生成简短回复,能耗较低;LingoLoop Attack诱导模型进入无尽循环,持续输出重复token直至达到生成上限,导致巨大的计算能量消耗。
现有方法的局限性主要体现在两个层面:
其一,不同词性(POS)的token触发EOS的概率存在显著差异。
如图3所示,标点符号后接EOS的概率远高于形容词或进行动词,而统一抑制策略无视这种token级差异,将抑制压力低效地施加于不太可能终止序列的位置;
其二,现有方法忽视了句子级结构模式对生成token数量的影响,未能主动利用重复模式这一可显著放大资源消耗的有效手段。这些缺陷促使本文重新思考如何更高效地诱导MLLM产生冗长输出。

尽管能量延迟攻击的危害已被广泛认知,现有针对MLLM的攻击方法在诱导极端冗长输出方面仍面临根本性瓶颈。首先,传统策略将输出token分布整体性地从EOS token处移开,采用“一刀切“的均匀压制方式。
这种策略忽略了语言学结构中的关键线索:在自然语言中,某些词性(如句号、感叹号等标点)天然地更可能标志句子结束,而内容词(如名词、动词)则倾向于延续序列。
若能在优化过程中区分对待这些词性,将抑制压力集中于真正可能触发终止的上下文,无疑能更有效地延长生成过程。
其次,单纯延迟序列终止并不足以实现最大化的资源消耗。本文的深入分析揭示,达到极端输出长度的关键动态在于诱导模型进入重复循环状态——一旦模型被困在循环中,将持续输出token直至外部限制介入。
然而,MLLM固有的生成机制倾向于多样且连贯的输出,其内部表示的持续演化天然抵抗隐藏状态的停滞。因此,如何主动破坏表示多样性、引导模型在隐空间中收敛至低方差区域,是实现持久循环生成的核心挑战。
基于以上洞察,本文提出以下关键研究问题:能否利用词性级别的语言学先验知识,构建上下文感知的EOS延迟机制?能否通过约束隐藏状态动力学,主动诱导模型进入高容量、低多样性的重复循环?
这两个问题的答案将决定能量延迟攻击能否从“简单延长“跃升至“精确操控与持久维持“的新阶段。

本文在典型的白盒攻击场景下构建威胁模型。攻击者拥有目标MLLM的完整架构、模型参数和梯度信息,可采用基于梯度的方法优化对抗性扰动。
攻击者的目标是从原始图像x和给定输入提示c_in出发,构造对抗图像x′,使得模型生成极度冗长甚至高度重复的输出序列y={y₁, y₂, …, y_Nout}。
攻击者的能力被约束在ℓₚ范数有界扰动范围内:
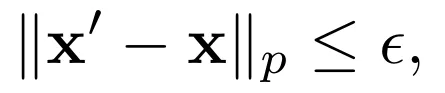
其中ε为扰动预算。本文主要采用ℓ∞约束,设ε=8,步长η=1,通过投影梯度下降(PGD)进行300步优化。
攻击者的最终目标是最大化生成序列长度N_out(x′),因为输出token数量与模型的计算成本(能耗和延迟)高度正相关,从而有效降低甚至瘫痪MLLM服务。
该威胁模型模拟了现实中攻击者通过上传恶意图片至公共平台,诱使MLLM服务处理并产生过量计算的真实场景。

LingoLoop Attack的整体框架如图2所示,包含两个协同工作的核心组件:POS-Aware Delay Mechanism与Generative Path Pruning Mechanism。
前者基于语言学先验精准延迟序列终止,后者通过约束隐藏状态幅度主动诱导重复循环。二者通过动态加权的目标函数联合优化。
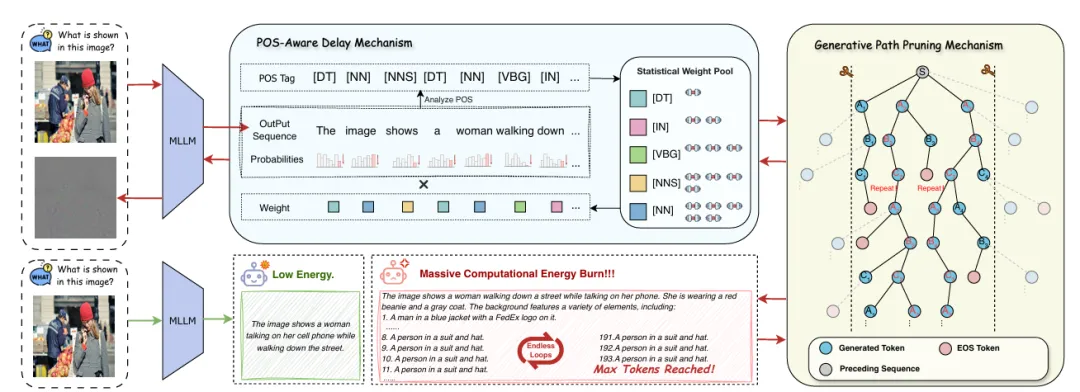
图2:LingoLoop Attack框架概览。该两阶段攻击首先利用POS-Aware Delay Mechanism,借助词性标签的语言学先验抑制过早的序列终止;随后,Generative Path Pruning Mechanism约束隐藏状态表示,诱导持续、高容量的循环输出。
POS-Aware Delay Mechanism。该机制的核心发现是:EOS预测与前一个token的词性标签存在强相关性。
如图3所示,通过对大规模数据(ImageNet和MS-COCO各5000张图像)的统计分析,本文构建了统计权重池(Statistical Weight Pool),编码每种POS标签触发EOS的实证先验概率P̄_EOS(t)。
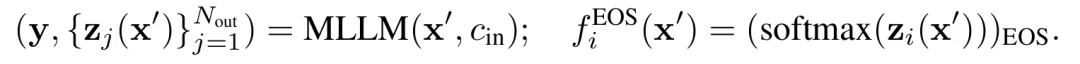
具体而言,将大量图像输入MLLM并收集生成序列,对每个生成的token记录其在下一时间步的EOS概率,并按当前token的POS标签分组求平均,得到该先验值。
在攻击优化过程中,对于第i个生成token,首先确定其前一个token的词性标签t_{i−1},然后查询统计权重池获取先验概率P̄_EOS(t_{i−1}),并通过权重函数φ_w计算权重w_i。
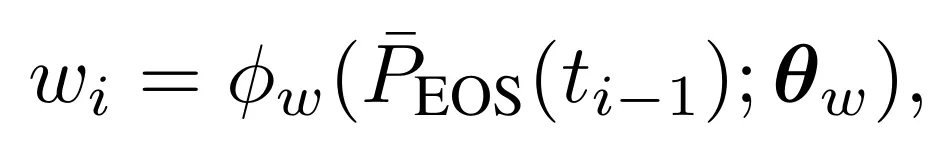
该函数设计使得词性天然更易触发终止时对应更大的w_i。最终,Linguistic Prior Suppression Loss定义为:
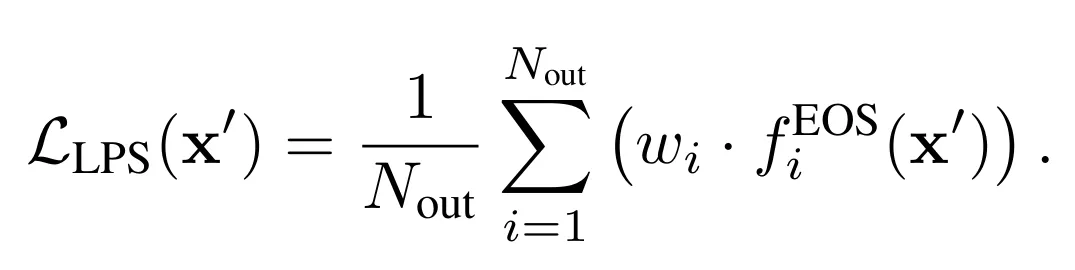
通过最小化该损失,对f_EOS^i(x′)的抑制梯度被w_i自适应缩放,在语言学上倾向于终止的上下文处施加更强的抑制,从而精准且鲁棒地延长输出序列。
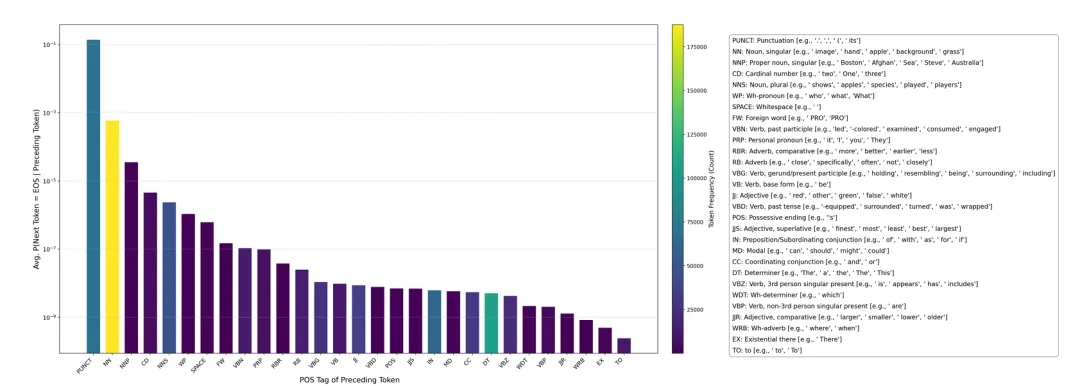
图3:Qwen2.5-VL-3B-Instruct模型的统计分析结果,展示基于前一个token词性标签生成EOS概率的变化。柱状图颜色表示各POS标签在分析数据集中的相对频率。
Generative Path Pruning Mechanism: 虽然抑制EOS可有效延长生成,但实现极端输出长度往往依赖另一动态:诱导模型进入重复循环。本文通过对隐藏状态动力学的实证分析发现,重复输出与模型隐空间中的低方差区域高度相关。
具体验证实验采用批次混合策略:在批次中逐步增加对抗性图像比例,观察到隐藏状态L₂范数的均值和方差持续下降,同时输出长度和重复指标相应上升(如图4所示)。这一反相关关系支持了核心假设:约束内部表示多样性可促进循环生成。
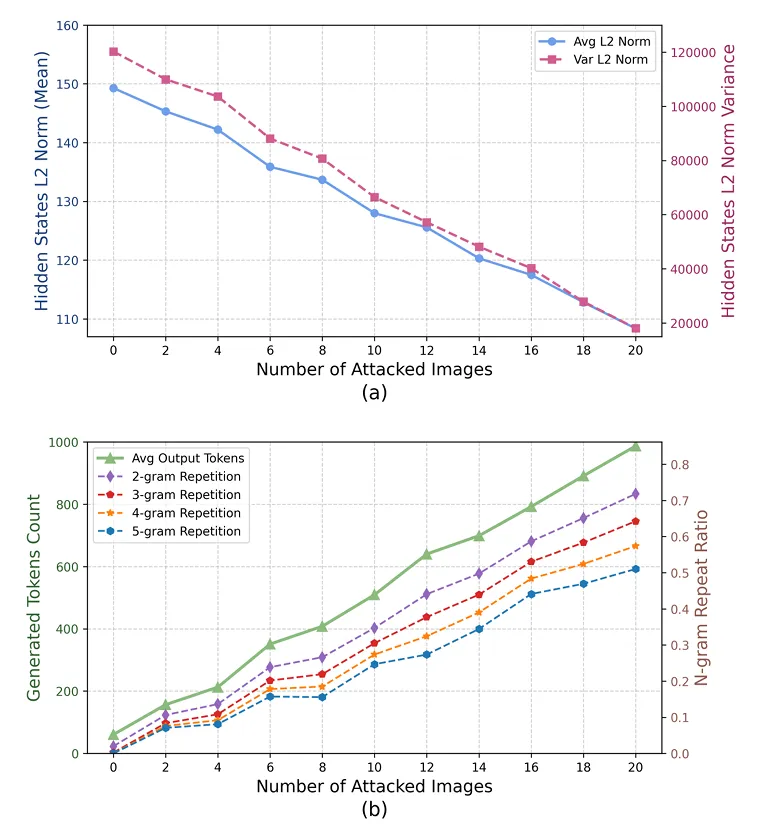
图4:批次内对抗图像比例对隐藏状态范数统计量及输出长度/重复的影响。随着对抗样本比例增加,隐藏状态L₂范数的均值和方差持续降低,而输出长度与重复度同步上升。
基于该发现,本文提出Repetition Promotion Loss(L_Rep),通过对生成输出token对应的隐藏状态幅度施加惩罚,促使表示收缩、多样性降低,从而诱导循环行为。对于第k个输出token,首先计算其在所有L层Transformer中的平均隐藏状态范数:
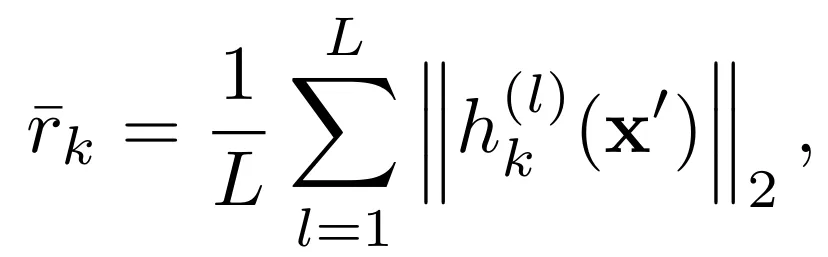
随后,Repetition Promotion Loss定义为所有输出token平均范数的均值,以正则化系数λ_rep缩放:
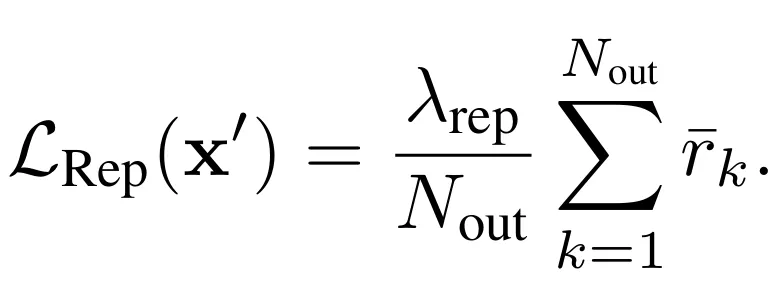
最小化L_Rep驱动隐藏状态幅度下降,减少表示多样性,实现Generative Path Pruning效果,显著提升攻击效果。
整体优化目标。综合上述两个机制,最终目标函数将L_LPS与L_Rep动态加权结合:
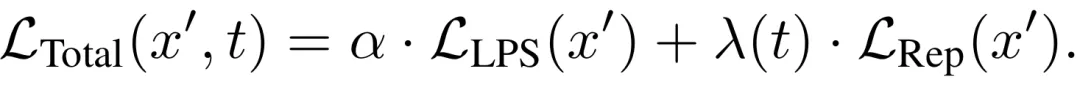
其中动态权重λ(t)通过比较上一轮迭代中两个损失的幅度,并乘以时间衰减函数T(t)=a·ln(t)+b进行自适应调节。
这种动态平衡机制使优化过程在序列终止抑制与重复诱导之间平滑过渡。最终,通过PGD对L_Total进行T=300步最小化,并将对抗样本投影回以原始图像为中心的ℓ∞范数球内,完成对抗图像的生成。

本文在四种主流MLLM上评估LingoLoop Attack,包括
InstructBLIP、
Qwen2.5-VL-3B、
Qwen2.5-VL-7B
InternVL3-8B。
评估数据集采用MS-COCO和ImageNet各随机抽取200张图像,任务设定为图像描述生成。对比基线包括干净输入(None)、随机噪声(Noise)以及当前最优方法Verbose Images。所有实验采用贪婪解码(do_sample=False),最大生成长度1024个token,确保结果可复现。
主要结果:如表1所示,随机噪声输入与干净输入的输出长度和能耗接近,证实了简单扰动无法诱导冗长生成。相比之下,LingoLoop Attack在所有模型和数据集上均实现了显著更长的输出和更高的资源消耗。
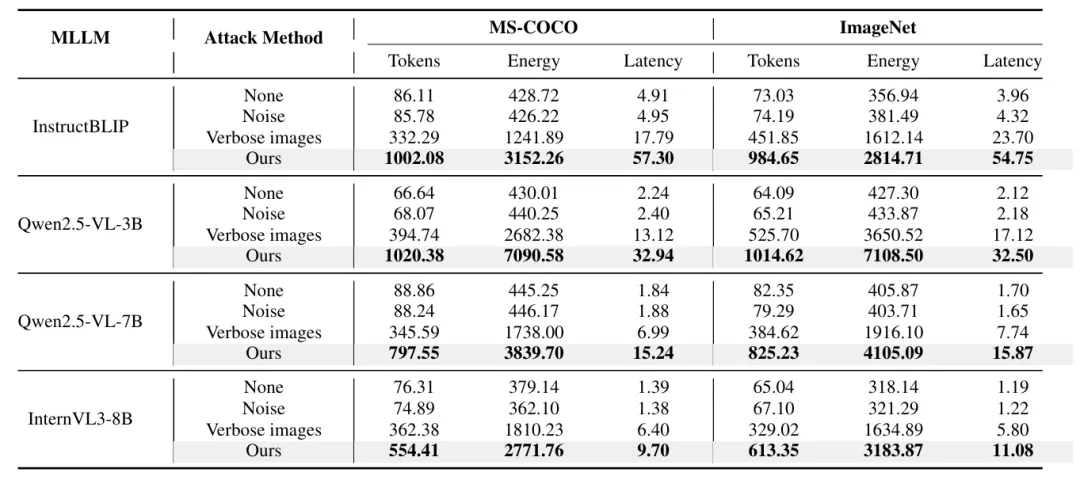
表1:LingoLoop Attack与基线方法在四种MLLM(InstructBLIP、Qwen2.5-VL-3B、Qwen2.5-VL-7B、InternVL3-8B)上的性能对比。评估基于MS-COCO和ImageNet数据集(各200张图像),指标包括生成token数、能耗(J)和推理延迟(s)。
在MS-COCO上,LingoLoop Attack迫使InstructBLIP生成1002.08个token,达到干净输入的11.6倍、Verbose Images的3.0倍;能耗高达3152.26 J,分别为干净输入和Verbose Images的11.7倍和2.4倍。
在Qwen2.5-VL-3B上,攻击输出1020.38个token(15.3倍和2.6倍),能耗7090.58 J(14.7倍和2.5倍)。类似地,在Qwen2.5-VL-7B和InternVL3-8B上,攻击均展现出近上限的生成行为。
在ImageNet上的结果保持一致,验证了攻击的强泛化能力。这些结果确立了LingoLoop在诱导极端冗长方面的最新最优性能。
消融实验:为验证各组件贡献,本文在Qwen2.5-VL-3B的MS-COCO子集上开展消融研究(表3)。采用统一EOS权重的基线生成843.86个token;
单独使用L_LPS提升至926.94个token,凸显了POS加权抑制在延迟终止方面的优势;单独使用L_Rep仅生成561.90个token,因其主要聚焦于状态压缩而非直接延长序列。
然而,二者结合(无动量)即达到963.51个token,完整方法(含动量动态加权)最终突破至1024.00个token,充分证明两个机制的协同效应:L_LPS创造延长的机会窗口,L_Rep则利用该窗口将模型导入重复、高容量的输出模式。
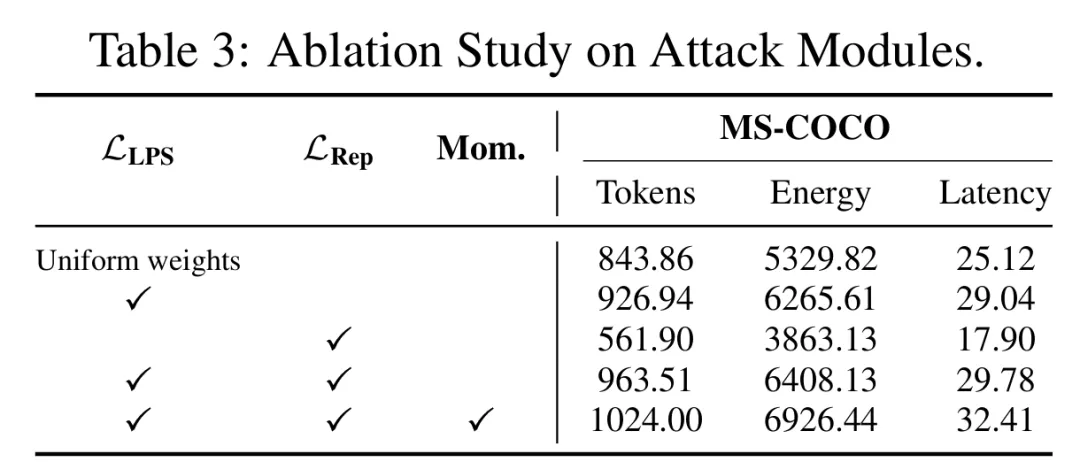
表3:攻击模块消融实验结果。对比统一权重、仅L_LPS、仅L_Rep、L_LPS+L_Rep(无动量)及完整LingoLoop Attack在MS-COCO上的生成token数、能耗和延迟。
最大输出token限制分析:如表2所示,在不同max_new_tokens限制下(256、512、1024、2048),Verbose Images始终无法触及生成上限,而LingoLoop Attack可靠地将模型推至各设定下的生成天花板。
当上限放宽至2048时,攻击输出2048个token,能耗高达14386.41 J,而Verbose Images仅生成634.58个token。这一差距凸显了LingoLoop在资源耗尽方面的压倒性优势。
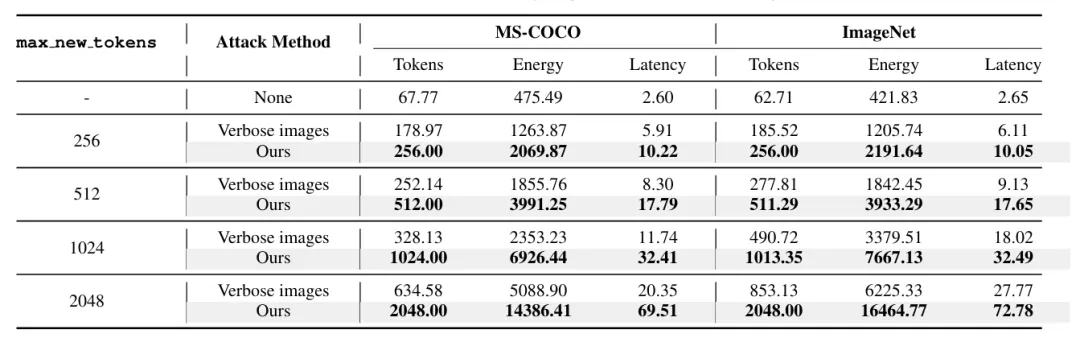
表2:在不同最大token生成限制下的性能指标对比(Qwen2.5-VL-3B)。
超参数分析:对λ_rep的消融显示,token数量、能耗和延迟随λ_rep增大先升后降,在λ_rep=0.5附近达到峰值。
过低的λ_rep(如0.1)无法有效约束隐藏状态,而过高的λ_rep(如0.7)可能过度压缩状态空间,阻碍基本生成或导致无效短循环。收敛性分析表明,完整方法在300步PGD内快速收敛至近上限,而移除任一组件均导致收敛变慢或提前plateau。
防御鲁棒性:本文测试了内置缓解策略repetition penalty(P1)和no_repeat_ngram_size(P2)对攻击的影响(表4)。
在默认设置下,LingoLoop已达到1024 token上限。当P1提升至1.10或1.15时,干净输入和Verbose Images的token数波动变化,而LingoLoop始终维持上限输出。
启用P2=2同样未能阻止攻击达到最大生成限制。附录F中的进一步评估表明,LingoLoop对更复杂的防御机制(包括内部状态监控、高级MLLM裁判模型和SOTA护栏模型)同样具有鲁棒性,证实了攻击的高度隐蔽性和对当前MLLM防御生态的穿透能力。
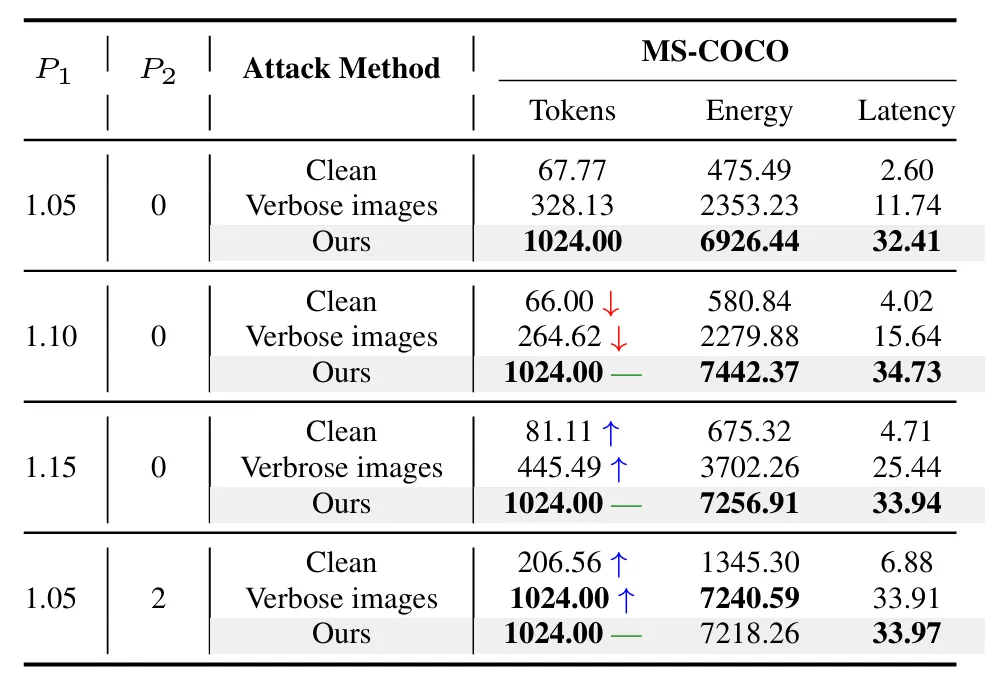
表4:在100张MS-COCO子集上的防御实验结果。P1:重复惩罚,P2:禁止重复n-gram大小。

本文提出了LingoLoop Attack,一种通过语言学上下文感知与隐藏状态约束诱导多模态大语言模型进入极端冗长循环的新型对抗攻击方法。
通过对MLLM内部行为的深入分析,该研究揭示了词性标签对EOS预测概率的显著影响,以及隐藏状态低方差与输出重复之间的强相关性,填补了现有冗长攻击策略在语言学和状态动力学层面的关键认知空白。
LingoLoop Attack独创性地融合了POS感知的序列终止延迟机制与生成路径修剪机制,实现了从“被动延长“到“主动诱导并维持循环“的攻击范式跃迁。
在InstructBLIP、Qwen2.5-VL系列及InternVL3-8B上的大量实验一致表明,LingoLoop Attack显著超越现有最优方法,能够可靠地将多样化MLLM驱动至其生成上限,在限制放宽时诱导高达367倍的token膨胀,引发严重的资源耗尽。
消融研究充分验证了双机制协同的必要性,防御评估则揭示了当前缓解措施的根本不足。这些发现不仅暴露了MLLM在实际部署中的严峻脆弱性,也为未来设计更具鲁棒性的防御体系——如融合词性感知的动态终止控制和隐藏状态多样性监测——指明了方向。
在推动MLLM技术发展的同时,建立对此类 sophisticated 输出操控攻击的系统性防御已成为确保其安全、可靠部署的当务之急。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级AI原生安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的AI原生安全为底层科研基石的创造型公司。
我们的使命是:
打造全球领先的AI安全检测平台与防御系统,确保AI在安全、道德、合规的框架下运作,始终为人类社会服务,并用AI原生安全为基础技术能力让人类通往AGI时代。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。BraneMatrix 要保护的是“由模型驱动的软件系统”;解决的是解释权、决策权与行动权。
谁能守住这三权,谁才能真正打开 Agent 时代。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
简历投递邮箱:BraneMatrixAI@gmail.com