 夜雨聆风
夜雨聆风





AI 编程代理正在悄悄破坏你的 monorepo 架构

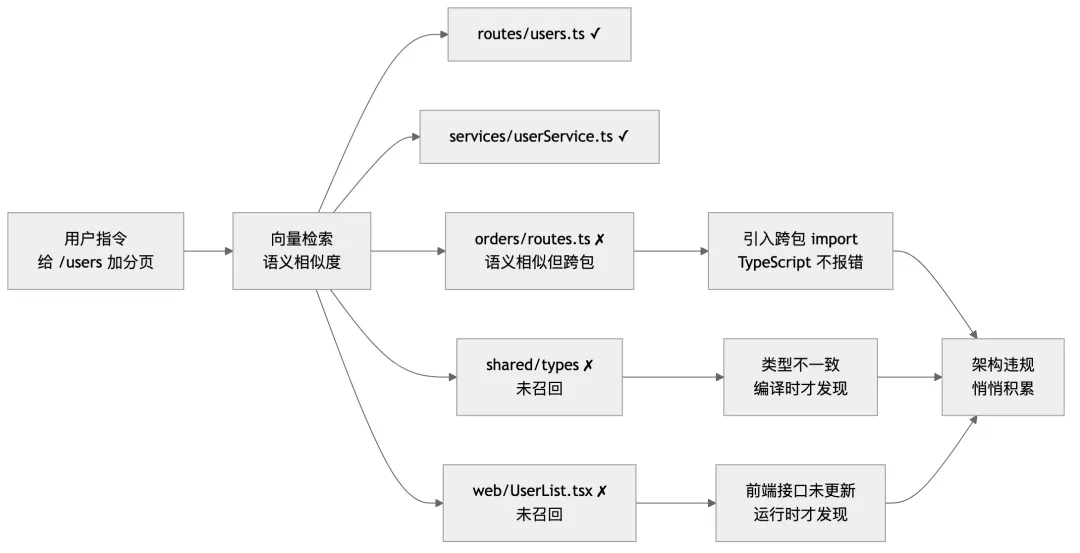
向量检索找”最像的”,不知道”能不能依赖”。找到了 orders/routes.ts,语义高度相似,但它属于另一个包——直接 import 进来,构建图被污染了。TypeScript 只管类型是否匹配,不管架构边界是否合理,所以编译通过,CI 通过,架构违规悄悄落地。这一跳的代价不是今天,而是三个月后你试图拆分部署的那一天。
① 架构边界被悄悄侵蚀
一个具体场景
你有一个用 Turborepo 管理的 full-stack monorepo,大致结构是这样:
apps/ api/ # Node.js + Fastify 后端 web/ # Next.js 前端packages/ db/ # Prisma schema + 查询层 shared/ # 跨端共享类型与工具 ui/ # 设计系统组件这个结构有隐含的分层规则:apps/api 可以依赖 packages/db 和 packages/shared,apps/web 可以依赖 packages/shared 和 packages/ui,但 apps/api 和 apps/web 之间不能直接互相依赖,packages/db 也不能依赖 packages/shared。
规则是隐含的,因为它存在于团队认知和 Nx 的 enforce-module-boundaries 规则里,不存在于 TypeScript 的类型系统里。
代理是怎么打破这些规则的
给 /users 接口加分页。你告诉代理”在用户列表接口加上分页支持”。代理需要找到并同步修改:
apps/api/routes/users.ts
(路由层,加 query 参数解析) apps/api/services/userService.ts
(服务层,加分页逻辑) packages/db/queries/users.ts
(查询层,加 LIMIT和OFFSET)packages/shared/types/pagination.ts
(共享类型,定义 PaginatedResponse<T>)apps/web/api/users.ts
(前端 API client,传分页参数) apps/web/components/UserList.tsx
(前端组件,加翻页 UI)
六个文件,横跨四个目录,有严格的分层依赖约束。代理凭向量检索,找到了 apps/api/routes/users.ts 和 apps/api/services/userService.ts,这两个很容易找,语义直接命中。
然后代理在找”分页的实现方式”时,发现 apps/api/routes/orders.ts 里已经有一个完整的分页实现——offset-based,有 cursor 字段,有 totalCount,写得不错。语义相似度极高。代理参考过来,顺手把 orders 路由里的一个私有工具函数 buildPaginationMeta() import 进了 apps/api/routes/users.ts。
同时代理没有找到 packages/shared/types/pagination.ts——因为这个文件名字不够”分页”,它叫 pagination.ts 但里面的类型名是 PageResult,代理描述的是 PaginatedResponse,相似度不够高。代理自己在 apps/api/routes/users.ts 里定义了一个新的 PaginatedUsersResponse 接口。
然后代理没有找到 apps/web/api/users.ts 和 apps/web/components/UserList.tsx——前端文件路径距离太远,检索优先级低。
结果:
- 后端
users直接依赖了orders的内部工具
:一条不该存在的跨包依赖链 packages/shared里的PageResult和新增的PaginatedUsersResponse并存
:类型重复,下一个开发者不知道用哪个 - 前端 API client 没有更新
:分页参数没传,分页接口对前端不工作,但这个问题只有运行时才能发现
TypeScript 编译没有报错,因为类型结构是兼容的。Turborepo 的 build 流程通过了,因为 import 的路径是合法的。CI 的测试通过了,因为测试没有覆盖到这条路径。
为什么你没发现
架构违规之所以难发现,是因为它从来不以错误的形式出现,而是以”可以运行的次优选择”的形式积累。
一个 import 不会触发警报。下一次有人需要在 users 功能里加东西,他们会发现 buildPaginationMeta 已经在这里了,直接用。下一次有人需要在 orders 功能里修改这个函数,他们没意识到 users 也在用它,改了签名,users 编译出错了,他们修了,但这次修改没有经过 orders 团队的 review。
三个月后 orders 团队想把自己的包独立部署,发现 users 依赖了自己的内部函数。这时候你才知道你有一个问题。但这时候修的成本已经是当初引入成本的十倍。
dependency-cruiser、Nx 的 module-boundary enforce、ESLint import 规则可以发现这类违规。但这些工具需要人主动配置、主动在 CI 里跑。代理不会主动运行架构检查,不会在生成 import 之前查询构建图,不知道 orders 和 users 之间的边界应该是隔离的。
② 根本原因:检索是平的,仓库是立体的
上面①里的所有问题,根源是同一个:代理的检索层没有结构感知。
向量检索找的是”像什么”,不是”是什么”
当前主流实现用向量相似度 + BM25 + grep/LSP 的组合构建检索。这个组合能高效解答”找所有和用户认证相关的代码”,但无法回答:
apps/orders/routes.ts
和 apps/api/routes/users.ts之间有没有依赖边界buildPaginationMeta
是 orders包的 internal helper 还是 public API-
修改 packages/shared/types/pagination.ts之后,还有哪些文件必须同步修改 -
当前正在修改的任务属于哪个 Turborepo workspace,该 workspace 的 package.json声明了哪些 peer dependencies
仓库里的结构信息——目录树、构建图(Bazel BUILD 文件、Turborepo turbo.json、Nx project.json)、CODEOWNERS、tsconfig.json 里的 paths 别名、接口契约——全部是可读的文本,但对检索层不可见。索引不读这些,只读代码内容。
LSP 补不了这个洞
有人会说:代理有 LSP(Language Server Protocol)集成,可以跳转到定义、找所有引用。这是真的,但 LSP 解决的是”这个符号在哪里被用”,不是”这个符号是否应该被用在这里”。
LSP 知道 buildPaginationMeta 定义在 apps/orders/utils/pagination.ts。LSP 不知道 apps/orders 和 apps/api 之间有架构边界,不知道这个 import 违反了模块边界规则。架构约束是领域知识,不是语法知识,LSP 不编码这层含义。
上下文越大,噪声越多
2025 年到 2026 年,所有主流代理的核心竞争叙事之一是”更大的上下文窗口”——从 100K 到 200K 到 1M tokens。背后的隐含假设是:上下文越大,代理看到的信息越多,效果越好。
对于单文件的问答,这个假设成立。对于 monorepo 的架构感知任务,这个假设失效,甚至反转:检索层不感知结构,召回的内容就是未经过滤的混合体。窗口越大,召回的无关跨包代码越多,代理越可能把不相干的实现当成参考。一个只读了 3 个文件的代理,可能比一个读了 30 个文件的代理犯更少的架构错误——如果那 27 个文件都来自错误的包。
这不是说更长的上下文没有价值,而是说:在上下文增长之前,检索质量必须先提升。否则更大的窗口只是给错误提供了更多展示空间。
③ 复杂任务:session 断了就是重来
full-stack feature 的真实步骤数
一个中等复杂度的 full-stack feature——比如”给用户系统加基于邮箱的登录,带邮件验证”——在 monorepo 里的完整步骤:
1. database migration — 新增 email_verifications 表2. Prisma schema 更新 — 新增 model 和 relation3. 邮件服务层 — 封装 SMTP 发送逻辑4. 验证 token 服务 — 生成和校验 token5. 用户服务层 — 修改注册流程,加触发发送逻辑6. API routes — 新增 /auth/verify-email endpoint7. 共享类型 — 新增 EmailVerificationPayload 等类型8. 前端 API client — 新增接口调用9. 前端注册页 — 修改 UI 流程10. 前端邮件验证页 — 新增页面11. 单元测试 — 覆盖服务层逻辑12. E2E 测试 — 覆盖完整流程十二步。任何一步出错,后面的步骤可能部分失效。任何一步之后 session 中断,你处于一个不一致的中间状态。
session 中断意味着什么
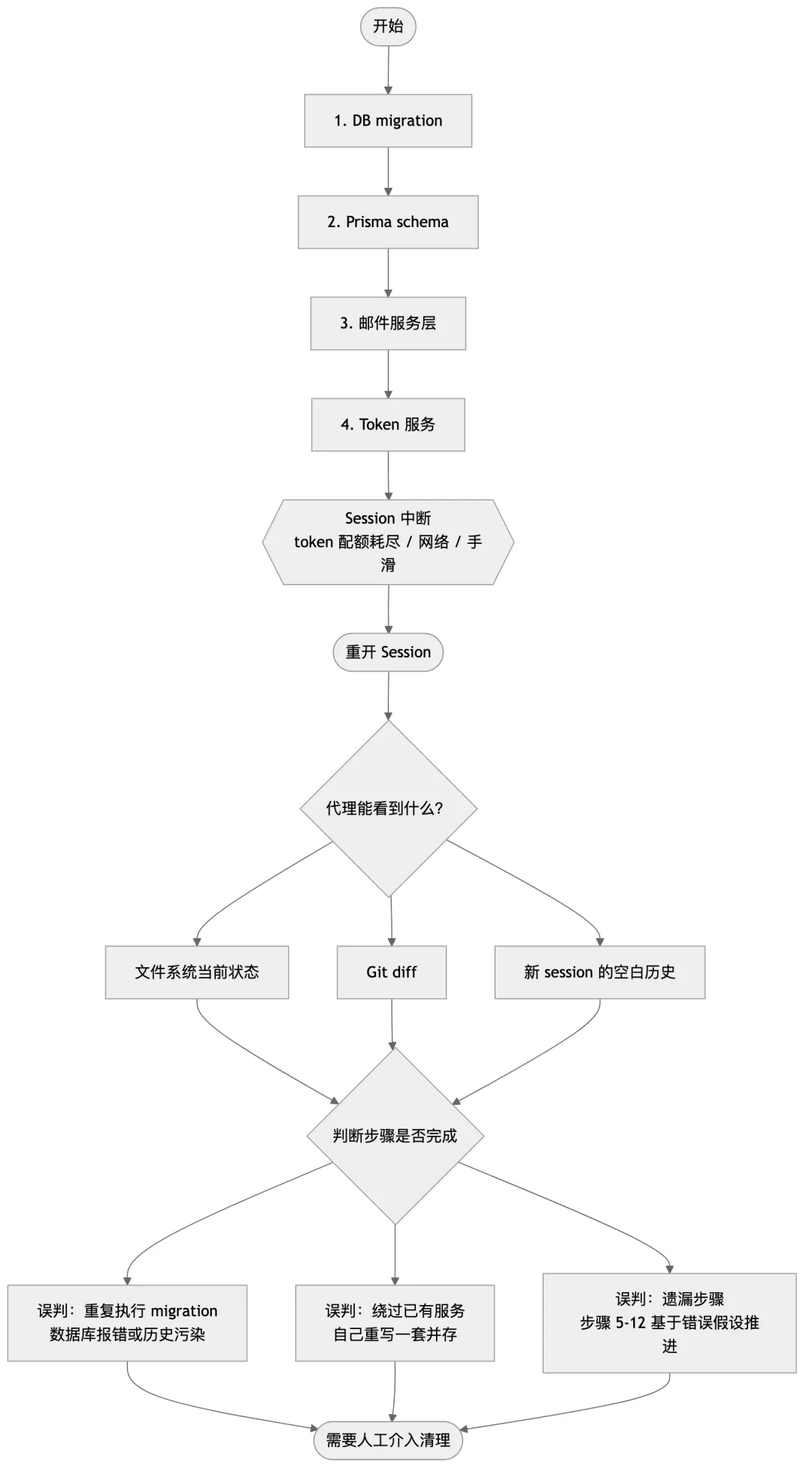
代理做完了步骤 1 到 4——migration 已执行,schema 已更新,邮件服务和 token 服务已写好。然后 session 因为 token 配额耗尽中断了。
你重新开一个 session,告诉代理”继续实现基于邮箱的登录验证功能”。代理没有任何途径知道步骤 1 到 4 已经完成。它能看到什么?它能看到文件系统的当前状态——email_verifications 表已经在 schema 里,邮件服务文件已经存在。代理可能会:
- 判断为”未完成”并重新生成
:migration 再次执行,数据库报错”表已存在”。轻则你手动清理,重则 migration 历史记录被污染,后续 migration 的顺序出问题。 - 判断为”已完成”并跳过
:但它无法确认步骤 3 和 4 的实现是否符合自己的理解,可能在步骤 5 里绕过已有实现,自己重新写一套逻辑。两套并存,互相干扰。 - 不一致地判断
:认为 schema 已更新(因为文件存在),但认为服务层未实现(因为函数签名不符合它的预期),在服务层写了新实现,然后在路由层同时调用两套。
这三种情况都是真实会发生的,而且很难在 code review 里发现,因为代码本身看起来是”完整的”。
为什么更长的 context 不解决这个问题
有人的直觉反应是:把上一个 session 的历史加进新 session 的 context 里不就行了?这个做法在工具层面是可行的,部分代理也支持”恢复历史 session”。但它解决的不是同一个问题。
历史 context 告诉代理”我们讨论了什么”,不告诉代理”文件系统现在处于什么状态、哪些步骤产生了真实的副作用”。Migration 是否真正执行了,是数据库状态,不是 context 历史。测试是否跑过,是 CI 状态,不是对话历史。
真正解决这个问题需要的是任务编排层:把每个步骤定义为一个有输入、输出、副作用、补偿动作的原子操作,有状态持久化,有断点恢复,有”回滚到步骤 N 之前”的能力。这是数据库事务解决的那类问题,不是更长 context 能解决的问题。今天没有主流代理实现了这一层。
④ 上下文是快照,不是持续感知
session 启动时发生了什么
当你启动一个代理 session,底层发生了这些事:Git 当前状态被采样一次(最近几条 commit、当前 diff),项目规则文件(AGENTS.md 之类)被加载一次,记忆文件被读取一次,然后这些信息被缓存进系统提示,整个会话期间不再更新。
这是合理的工程取舍。重新采样一次完整的项目上下文需要读文件、跑 git 命令、重新组装提示词——每一轮对话都做这些,成本高、延迟长。所以设计选择是:启动时采样一次,缓存用全场。
快照过期的场景
你们是一个三人团队,在同一个 monorepo 上并行工作。
你早上 9 点启动 session,开始做用户模块的 API 改动。同事甲在 10 点把 packages/shared/types/dto.ts 里的 UserDTO 改了——把 name: string 拆成了 firstName: string 和 lastName: string,merge 进了主干,因为她负责的国际化需求要求这个拆分。同事乙在 11 点更新了 packages/shared/validators/user.ts 里对应的 Zod schema。
你的 session 是 9 点启动的。你的代理看到的 UserDTO 还是 name: string 的版本。你继续用这个结构生成代码,写了新的 route handler,写了测试,一切看起来都很好。你做完推到 PR,CI 跑了,编译报错了。
这个错误发现得还算早——有 CI 托底。更坏的情况:如果你生成的代码不直接 import UserDTO,而是手写了一个兼容的接口,类型结构一致,TypeScript 用结构类型兼容通过了编译,但运行时 user.name 是 undefined,因为字段已经不存在了。这种问题在集成测试覆盖不全的情况下,可能直接进生产。
谁受影响最大
快照过期问题的严重程度和以下变量正相关:
- 团队人数
:三人团队每天有多少次 merge?十人团队呢? - Session 时长
:一个 30 分钟的快速改动受影响小,一个工作半天的长任务受影响大 - 共享包的改动频率
: packages/shared每天被修改一次,还是每小时? - 类型系统宽松程度
:TypeScript 的结构类型加上 any的滥用,会让快照过期的错误更难被编译器发现
对于一个独立开发者在自己的小项目上用代理,这个问题几乎不存在。对于一个快速迭代的多人团队,这是日常摩擦,不是偶发事故。
⑤ 质量退化没有预警,用户先于平台知道
今年发生的事
2026 年 3 月到 4 月,Claude Code 出现了三个工程问题,在 Anthropic 4 月 23 日的事后报告公开之前没有任何官方通知:
3 月 4 日:推理努力度(reasoning effort)从 high 被静默降级为 medium,目的是降低延迟和服务成本。没有用户通知,没有版本日志。
3 月 26 日:引入新 bug,Claude Code 在多轮对话中持续丢弃推理历史(reasoning history)。模型每轮都从部分信息重新开始,而不是积累上下文。副作用是 usage limit 消耗异常加快,因为模型在重复无效计算。
4 月 16 日:系统提示里的一个字段意外地把工具调用之间的响应硬截断到 25 个词。复杂问题的分析从几百词变成了几行截断输出。
四月二十日,三个问题一起修复。四月二十三日,事后报告才公开。
六周。这六周里,TrustedSec CEO 记录了代码质量下滑约 47%,Veracode 测出安全漏洞率 52%。用户在 Reddit 和 X 上早就喊”Claude 变蠢了”,但没有触发任何内部告警。
为什么监控捕获不到这类问题
云端 API 的标准监控指标是延迟(p50/p95/p99)、吞吐量(requests/s)、错误率(4xx/5xx)。这三个指标在整个六周里都是正常的——API 照样响应,照样成功返回,延迟甚至因为推理步骤减少而降低了。
质量退化不会触发任何这些指标。”推理链更短了”、”上下文利用率更低了”、”代码里潜在漏洞增加了”——这些需要主动的输出质量评估,需要定期跑回归测试集,需要把用户反馈信号和内部质量指标关联起来。这是一套需要专门建设的评估 pipeline,不是监控系统的默认能力。Anthropic 在这一层有盲点。
这对 monorepo 开发者意味着什么
在单文件问答场景里,输出质量退化的后果是:代理给的答案不够好,你改一下或者换个 prompt 继续。影响局限在当次对话。
在 monorepo 复杂任务场景里,代理持续在多个文件上操作,输出质量退化的后果是累积的:推理能力下降 → 代理找不全需要修改的文件 → 遗漏的文件在后来引发问题 → 问题被归因于”代码写得有问题”,不被归因于”代理的推理质量退化了”。
这个归因错误本身就是一个隐蔽的成本:团队把时间花在 debug 上,而不是意识到工具退化了。甚至更坏:开发者开始调低对代理的期望,降低任务复杂度,回到手写。
本地模型是免疫的,但还没准备好
用本地模型驱动的代理从根本上不存在”平台静默降级”这个问题:模型版本是固定的,只有你自己决定要不要升级,升级的结果你可以自己测试。退化是可感知的、可控的。
但今天的本地模型——在 Apple Silicon 上跑的 32B 量化模型,或者私有部署的 70B——在代码质量上和 Claude Sonnet、GPT-4o 还有差距,特别是在复杂的多步推理和大范围代码理解上。这个差距在缩小,速度超过大多数人的预期,但现在说”完全可以替代云端模型做 monorepo 开发”还为时过早。
这是一个暂时的约束,不是永久的结论。
为什么你现在可能没发现
如果你在用 AI 代理开发 monorepo,以上五个问题你不一定都遇到了,或者遇到了但没意识到是代理引起的。
原因是:这些问题的暴露需要时间和规模。
架构违规需要积累一段时间才会让你感到痛——第一个非法 import 不会炸,第十个才会让你开始疑惑依赖图为什么这么乱。复杂任务中断的问题,只有当你的任务步骤数超过 5 个、session 长度超过半天才会变成系统性风险。上下文快照过期,只有团队达到一定规模、共享包改动频率够高才会成为日常摩擦。质量退化,只有你有了之前的基线才能发现退化。
如果你现在用代理做的主要是:修一个 bug、写一个工具函数、解释一段代码、改个配置文件——这些场景下这五个问题都不显著。代理在这些场景里确实好用。
问题在于,工具的易用性会推着你把越来越复杂的任务交给它。从修 bug 到加 feature,从加 feature 到做重构,从单人使用到团队协作。在这个推进过程里,你会逐渐进入这五个问题的高发区,而不自知。
我的判断
这五个问题的性质不同,解法方向也不同:
①②(检索无结构感知 → 架构违规) 是设计层的结构性问题,不会因为模型更聪明而消失。只要检索层不感知包边界、构建图、接口契约,召回的内容就天然是”语义相关但架构无关”的混合体。上下文窗口越大,这个问题越严重,因为能召回更多无关内容。这两个问题需要在检索层解决,不是在模型层解决。
③(任务无事务语义) 是执行层的工程空白。今天的代理有工具框架、有权限系统,缺的是任务级的步骤依赖、补偿动作、断点恢复。这不是上下文大小的问题,是执行层是否有状态机和事务保证的问题。
④(上下文快照) 是成本驱动的设计取舍,有局部缓解手段:手动刷新、缩短 session 时长、高频关键文件的主动推送。但根本上,全量实时感知的成本问题需要更高效的增量同步机制。
⑤(质量退化无预警) 是可观测性问题。本地模型可以彻底规避,云端 API 需要用方自建质量评估 pipeline——定期跑回归集、把社区反馈信号结构化处理。这是需要团队主动投入的,不会由平台自动解决。
2026 年编程工具的竞争正在从”谁更聪明”转向”谁更像一套可靠的软件工程系统”。上下文窗口的军备竞赛对 monorepo 开发的帮助是边际递减的——召回更多无关代码、噪声更大、架构违规更多。下一代工具需要回答的问题不是”能不能理解这段代码”,而是”能不能在整个仓库的约束体系里可靠地完成跨文件、跨层的工程任务”。这个问题今天没有主流工具给出满意的答案。
延伸阅读
-
Anthropic 工程事后报告(2026-04-23) — 三个静默 bug 的完整复盘,⑤节的第一手来源 -
Anthropic 的算力危机与 Google $400 亿 — 这次工程事故的背景脉络:算力压力如何影响产品决策 -
AI 编程的五个范式 — 从补全工具到自主代理的演进路线,以及每个范式的边界 -
AI 编程的上下文管理 — 深入解析代理如何构建和管理上下文,②④节的背景知识