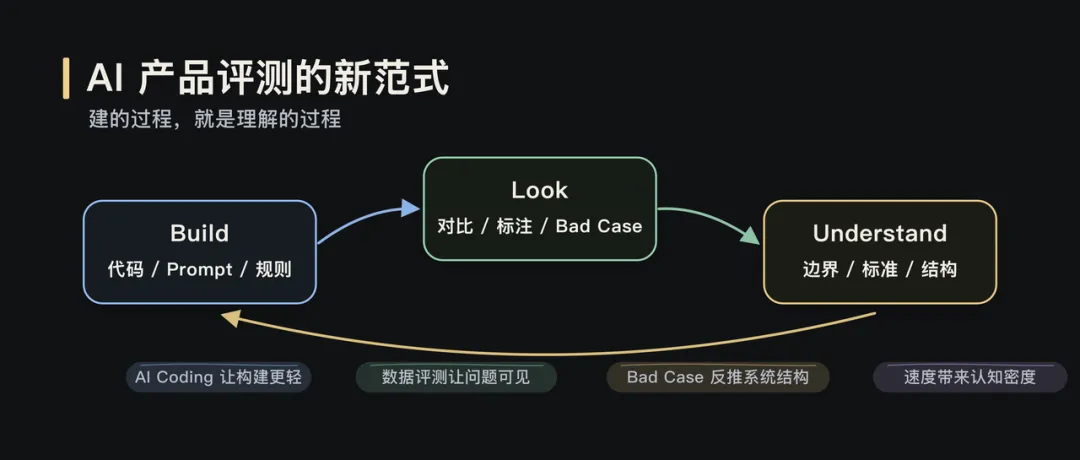
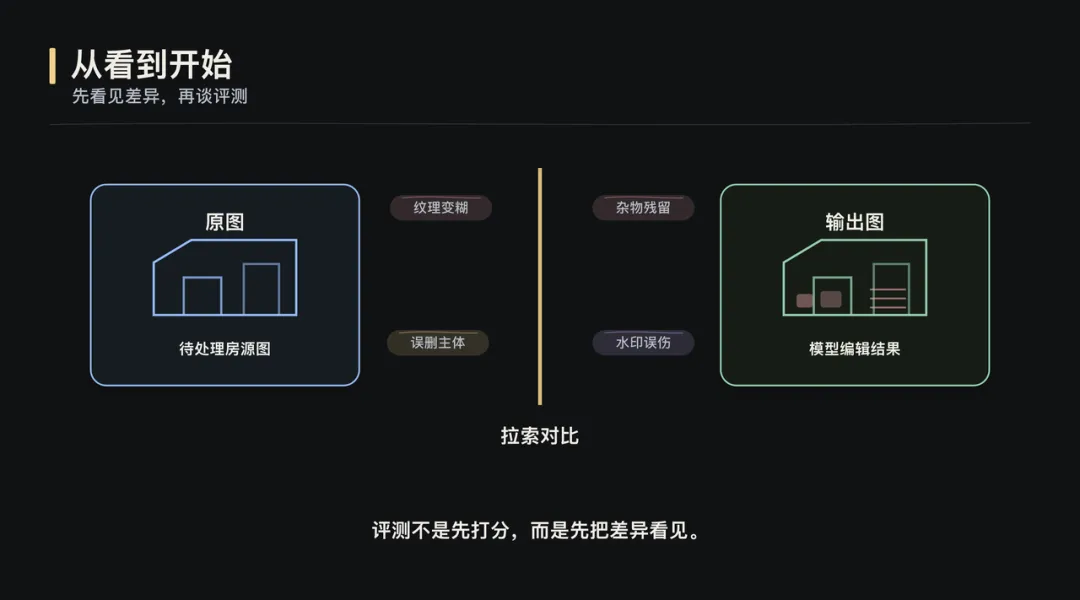
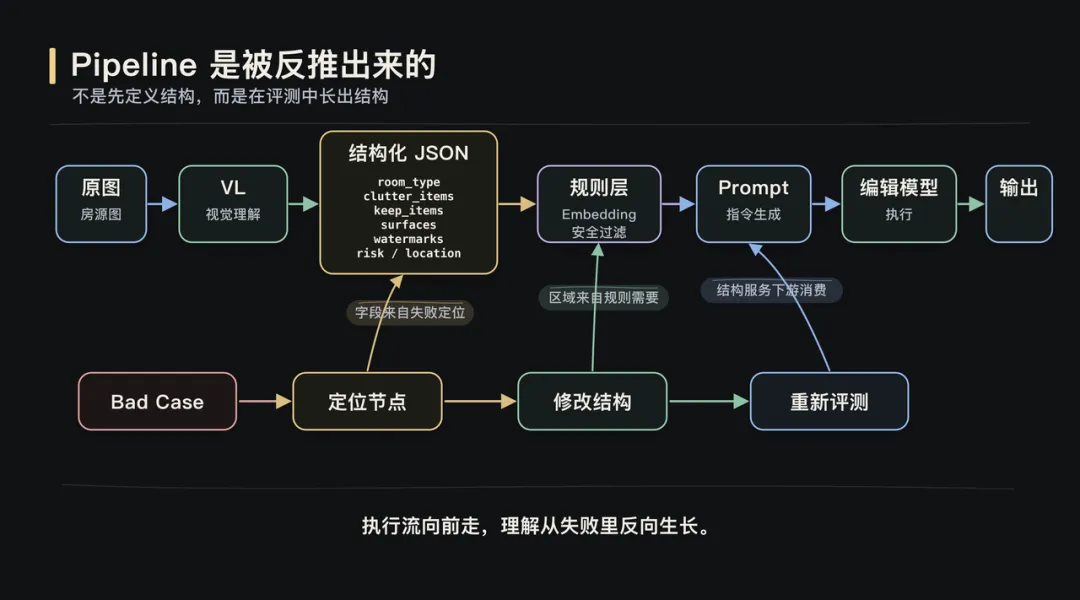
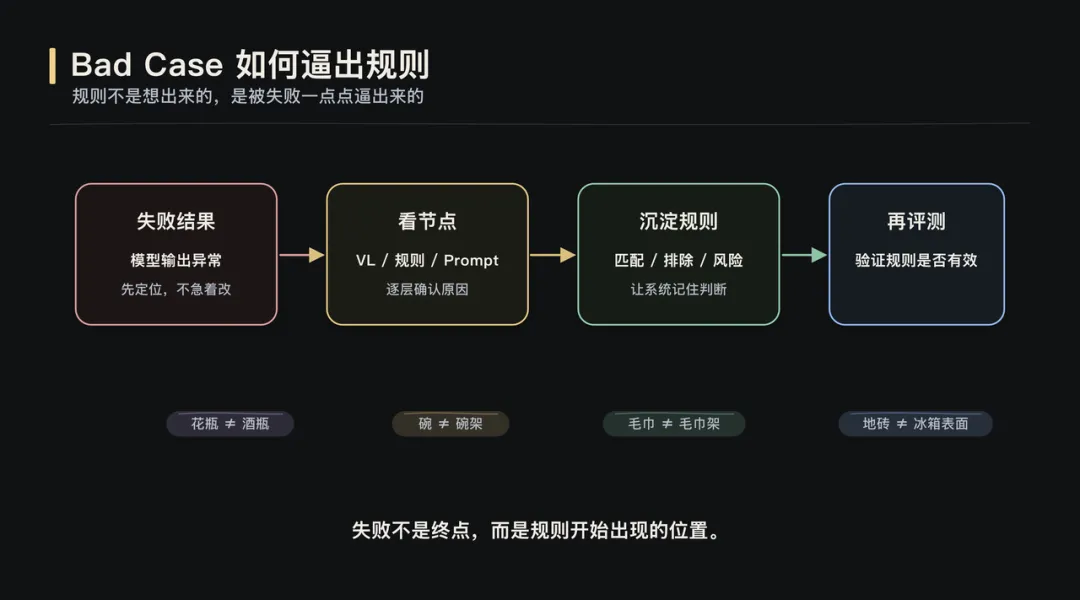
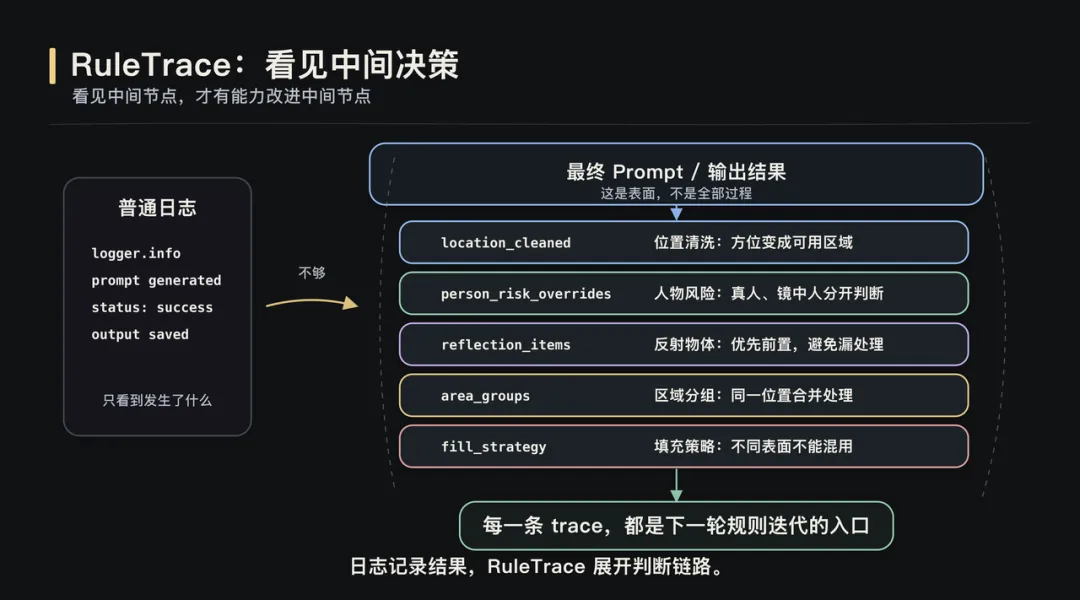
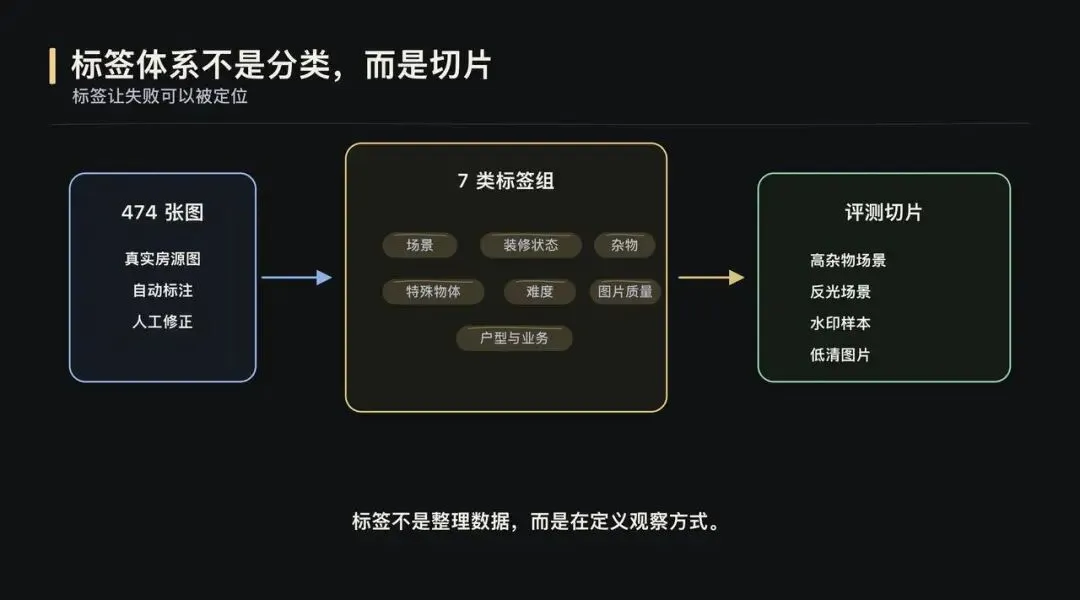
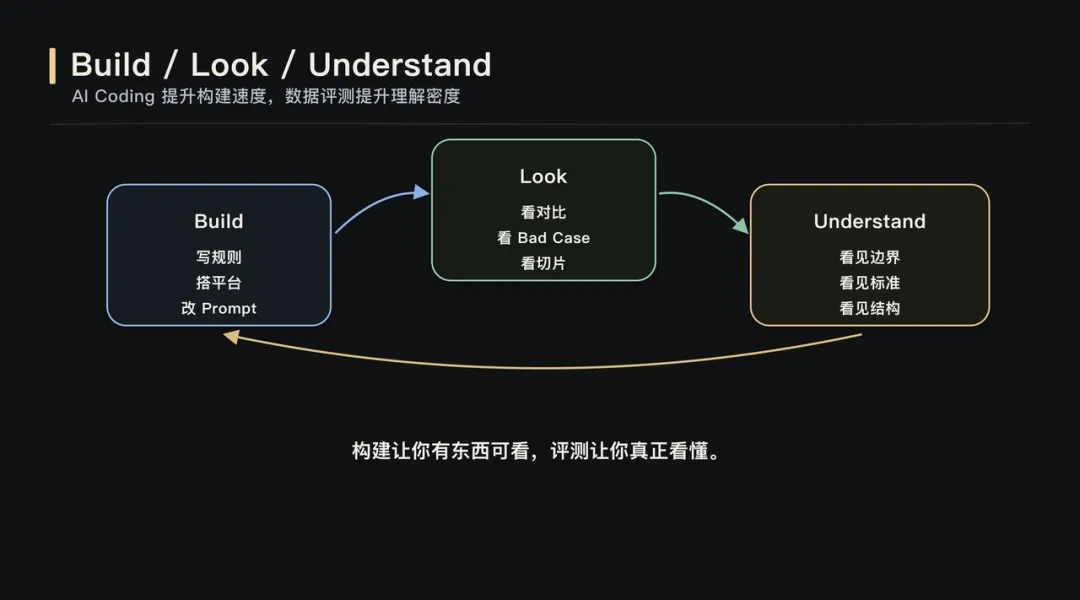
全文约 2800 字,阅读约 6 分钟当 AI Coding 让构建更轻、评测更快,理解问题的方式也变了。▎从「看到」开始数据评测是 AI 产品落地的核心能力。但这次实践真正改变我的,不是“评测很重要”这个结论。这次更具体的感受是:当 AI Coding 让构建更轻、评测更快,评测会从一个验证环节,变成理解问题的方式。过去很多评测能力需要排期、需要工程资源、需要完整系统设计。产品经理更多是在提出需求、等待结果。但 AI Coding 改变了这个节奏,它让产品经理可以更早、更深地进入构建过程。过去我们常说,做 AI 要 look at your data。但我最近发现,这句话少说了一半。在 AI 产品开发里,你没法直接 look at your data。你得先 build something,才能真正看见它。这篇文章想聊的,不是某个平台,也不是某个房源图片项目本身。项目只是载体。真正值得讨论的是:当数据评测和 AI Coding 结合之后,产品经理理解问题、验证判断、推进迭代的方式,正在发生变化。最开始的问题很朴素:模型输出一张图,效果好不好?要回答这个问题,首先得有个地方能把原图和处理后的图放在一起看。听起来简单,但“放在一起看”这个动作本身就有讲究:两张图并排摆放,视线要来回跳;分两个屏幕对比,细节又对不齐。所以我先做了一个拉索对比页面:一条竖线左右分割,拖动竖线就能看到同一像素位置的前后差异。这个页面本身,就是第一次 build。有了逐像素级的对比能力之后,下一个问题浮出来了:人眼到底能发现多少问题?我自己看的时候,注意力更容易落在最明显的变化上,比如颜色偏了,某个物体变形了。但那些微妙的退化,比如纹理细节丢失、光影自然感消失,经常只是觉得“哪里怪怪的”,却不一定能定位到具体原因。于是我又加了一层:把原图和处理后的图一起发给 Gemini,让它逐项比对差异。它带来的增强不是替代人的判断,而是扩展观察覆盖面。比如有一版提示词让木地板的纹理从实木质感变成了塑料贴皮效果。还有一些图,窗帘网纱纹理、被子褶皱、墙面光影都被处理得更“干净”了,但其实是信息被抹掉了。单看一张图,你知道这张图“纹理模糊了”。但当一批图跑完评审,你会发现:纹理退化不是个案,而是这一版提示词的系统性问题。这是第一次 build to look。▎拆解 Pipeline图片美化这条线,提示词迭代加上 Gemini 的评审反馈,路是走得通的。但去除杂物是另一类问题。美化只需要让照片更好看,模型对“好看”的理解虽然粗糙,但大方向不会错。去除杂物则不同,它需要三步能力:先理解图里有什么,再判断哪些该保留、哪些该去掉,最后才是执行去除。理解、判断、执行,三步全压在一个模型身上,对模型的要求高了一个量级。所以思路开始变化:不再指望一个模型同时完成所有事情,而是拆成 pipeline。VL 视觉理解模型负责分析图里有什么,Embedding 和规则引擎负责做语义判断、安全过滤和指令翻译,图片编辑模型负责执行去除。拆开之后,一张图效果不好,我至少能看到:VL 说了什么,中间决策层做了什么判断,最后给编辑模型的指令是什么。▎标准是长出来的Pipeline 拆开只是第一步。真正有意思的是,判断标准怎么来。比如规则引擎要判断:哪些东西该保留,哪些东西该去除。最初我用关键词子串匹配。白名单里有“凳”,VL 输出“塑料凳”,包含“凳”字,就保留。简单、直接、判断明确。但它覆盖不了同义词。VL 有时候把电磁炉叫“灶具”,把置物架叫“铁架”。于是我引入 Embedding 语义匹配,用向量距离判断它们是不是同一类东西。问题也随之出现。“毛巾”和“毛巾架”很像,“碗”和“碗架”很像,“盆”和“盆架”很像。可在房源照片里,毛巾是杂物,毛巾架是固定设施。一开始的本能反应是继续修补语义匹配:加反向校验、扩展白名单、调阈值。但每批新图都会冒出新的误匹配对。后来我意识到,问题不在“语义不够准”,而在判断层级错了。“毛巾”和“毛巾架”的区别,不在语义,而在结构,后者多了一个“架”字。类似的还有“碗架”“鞋柜”“收纳箱”。于是后缀规则出现了:如果一个词以“架、筐、箱、柜、桌、杆”等结尾,它大概率是家具或固定设施,不是杂物。还有一个典型 case 是花瓶和酒瓶。Embedding 认为它们相似度很高,这从语义和视觉上都说得通。但在房源照片去杂物场景里,花瓶可能是装饰品,酒瓶更可能是生活痕迹。这个判断,任何通用评测平台都没法直接替你定义。这也是我这次实践里很深的感受:需求不是预先定义的,是从数据里长出来的。▎看见决策规则引擎迭代到后面,我每加一条规则都会写 logger.info。我以为这就是可观测了。直到有一天评审时发现,我只能看到最终 prompt 和粗粒度的保留/清除决策,中间很多关键步骤仍然是黑盒:哪些位置被清洗了,人物风险为什么被覆写,区域是怎么分组的,填充策略为什么这么选。后来加了 rule_trace 结构化输出,把每一步中间决策都记录下来,才真正“看见了”。Logging 不等于 observability。你以为自己能看到系统,其实可能只是在看日志。▎标签体系为了做场景化批量测试,我需要知道这些图到底是什么图。于是我不是简单建了一个图片文件夹,而是让模型给 474 张房源图打标签。最后标签体系长成了 33 个 key、7 个标签组:场景、装修状态、杂物、特殊物体、难度、图片质量、户型与业务。这些标签后来变成了评测切片。我可以按房间类型看效果,可以按杂物密度看效果,也可以单独筛有水印、有反射面、有人影、有纸箱、有遮挡的 case。这件事看起来像是在整理数据,但本质不是。标签不是为了把数据收拾整齐,而是为了让问题能够被分组、被比较、被反复追问。没有这个标签体系,就没有真正的场景化评测;没有场景化评测,就很难知道问题到底发生在哪类数据上。▎数据重塑判断图片美化那条线,最开始目标很简单:让照片更好看。但跑着跑着发现,“好看”这个词太粗了。某个版本暴露出光影是独立问题,再往后发现清晰度才是核心瓶颈,更后面发现水印比画质问题更影响观感。每一次方向调整,都不是因为提示词写得更漂亮了,而是因为看到数据后,重新定义了“好”是什么意思。去除杂物也是一样。电磁炉是杂物吗?脏衣篓是杂物吗?玻璃反射里的人影要去掉吗?花瓶和酒瓶在房源照片里应该怎么区分?这些判断不是一开始就想清楚的,它们是在 bad case 面前,和数据反复碰撞后逐渐清晰的。你以为你知道自己要什么,但数据会给你一个更精确的版本。▎循环与速度这个循环本身并不新鲜。真正变化的是,AI Coding 同时改变了两个变量:构建更轻,评测更快。以前一个评测工具、一个数据标注模块、一个规则追踪面板,都可能排进需求池里等排期。等它做出来,问题理解已经换了一轮。但现在,一个产品经理可以在很短时间内,把这些观察能力一层层搭出来。构建速度追上了认知速度,评测速度也开始反过来推动认知。这意味着,评测不再是研发之后的独立环节。它开始嵌入产品、研发、测试的共同过程中。产品经理可以更深入地参与构建,工程同学可以更直接地看到业务判断,测试不再只是验证结果,而是在帮助定义问题本身。边界没有消失,但边界变软了。所以这次实践对我最大的改变,不是让我更相信数据评测,而是让我意识到:当 AI Coding 让构建更轻、评测更快,产品理解本身也可以被更高频地迭代。评测不再只是“做完之后看看效果怎么样”。它开始变成一种工作方式:为了看见而构建,在构建中理解,再用新的理解推动下一轮构建。而理解,才是 AI 产品开发中真正稀缺的东西。
 夜雨聆风
夜雨聆风